Halaman ini memberikan panduan tentang cara memigrasikan database PostgreSQL open source ke Spanner.
Migrasi melibatkan tugas berikut:
- Memetakan skema PostgreSQL ke skema Spanner.
- Membuat instance, database, dan skema Spanner.
- Memfaktorkan ulang aplikasi agar berfungsi dengan database Spanner Anda.
- Memigrasikan data Anda.
- Memverifikasi sistem baru dan memindahkannya ke status produksi.
Halaman ini juga memberikan beberapa contoh skema menggunakan tabel dari database PostgreSQL MusicBrainz.
Memetakan skema PostgreSQL ke Spanner
Langkah pertama Anda dalam memindahkan database dari PostgreSQL ke Spanner adalah
menentukan perubahan skema yang harus Anda buat. Gunakan
pg_dump
untuk membuat pernyataan Data Definition Language (DDL) yang menentukan objek di database PostgreSQL Anda, lalu ubah pernyataan seperti yang dijelaskan di bagian berikut. Setelah memperbarui pernyataan DDL, gunakan pernyataan tersebut untuk membuat database di instance Spanner.
Jenis data
Tabel berikut menjelaskan cara pemetaan jenis data PostgreSQL ke jenis data Spanner. Perbarui jenis data dalam pernyataan DDL Anda dari jenis data PostgreSQL ke jenis data Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, menggunakan notasi CIDR standar. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 jika menyimpan nilai dalam milidetik, atau STRING jika menyimpan nilai dalam format interval yang ditentukan aplikasi. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, menggunakan notasi alamat MAC standar. |
money |
INT64, atau STRING untuk angka presisi arbitrer. |
numeric [ (p, s) ]
|
Di PostgreSQL, jenis data NUMERIC dan DECIMAL mendukung presisi hingga 217 digit dan skala 214-1, seperti yang ditentukan dalam deklarasi kolom.Jenis data NUMERIC Spanner mendukung presisi hingga 38 digit dan skala 9 digit desimal.Jika Anda memerlukan presisi yang lebih tinggi, lihat Menyimpan data numerik presisi arbitrer untuk mekanisme alternatif. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Jenis data ini khusus PostgreSQL, sehingga tidak ada padanan Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, menggunakan notasi HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, menggunakan notasi HH:MM:SS.sss+ZZZZ. Atau, ini dapat dibagi menjadi dua kolom, satu kolom dengan jenis TIMESTAMP dan satu kolom lagi yang menyimpan zona waktu. |
timestamp [ (p) ] [ without time zone ] |
Tidak ada ekuivalen. Anda dapat menyimpannya sebagai STRING atau TIMESTAMP sesuai keinginan Anda. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Tidak ada ekuivalen. Sebagai gantinya, tentukan mekanisme penyimpanan di aplikasi Anda. |
tsvector |
Tidak ada ekuivalen. Sebagai gantinya, tentukan mekanisme penyimpanan di aplikasi Anda. |
txid_snapshot |
Tidak ada ekuivalen. Sebagai gantinya, tentukan mekanisme penyimpanan di aplikasi Anda. |
uuid |
STRING atau BYTES |
xml |
STRING |
Kunci utama
Untuk tabel di database Spanner yang sering Anda tambahkan, hindari
menggunakan kunci utama yang meningkat atau menurun secara monoton, karena pendekatan ini
menyebabkan hotspot selama penulisan. Sebagai gantinya, ubah pernyataan CREATE TABLE DDL
agar menggunakan
strategi kunci utama yang didukung. Jika menggunakan fitur PostgreSQL seperti jenis data atau fungsi UUID, jenis data SERIAL, kolom IDENTITY, atau urutan, Anda dapat menggunakan strategi migrasi kunci yang dibuat otomatis yang kami rekomendasikan.
Perhatikan bahwa setelah menetapkan kunci utama, Anda tidak dapat menambahkan atau menghapus kolom kunci utama, atau mengubah nilai kunci utama nanti tanpa menghapus dan membuat ulang tabel. Untuk mengetahui informasi selengkapnya tentang cara menetapkan kunci utama, lihat Skema dan model data - kunci utama.
Selama migrasi, Anda mungkin perlu menyimpan beberapa kunci bilangan bulat yang meningkat secara monoton yang ada. Jika Anda perlu menyimpan jenis kunci ini di tabel yang sering diperbarui dengan banyak operasi pada kunci ini, Anda dapat menghindari pembuatan hotspot dengan menambahkan awalan pada kunci yang ada dengan angka pseudo-acak. Teknik ini menyebabkan Spanner mendistribusikan ulang baris. Lihat Yang perlu diketahui DBA tentang Spanner, bagian 1: Kunci dan indeks untuk mengetahui informasi selengkapnya tentang penggunaan pendekatan ini.
Kunci asing dan integritas referensial
Pelajari dukungan kunci asing di Spanner.
Indeks
Indeks b-tree PostgreSQL mirip dengan indeks sekunder di Spanner. Di database Spanner, Anda menggunakan indeks sekunder untuk
mengindeks kolom yang sering ditelusuri untuk performa yang lebih baik, dan untuk mengganti
batasan UNIQUE yang ditentukan dalam tabel. Misalnya, jika DDL PostgreSQL Anda
memiliki pernyataan ini:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Anda akan menggunakan pernyataan ini di DDL Spanner:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Anda dapat menemukan indeks untuk tabel PostgreSQL apa pun dengan menjalankan
meta-perintah \di
di psql.
Setelah menentukan indeks yang diperlukan, tambahkan pernyataan CREATE INDEX untuk membuatnya. Ikuti panduan di
Membuat indeks.
Spanner menerapkan indeks sebagai tabel, sehingga mengindeks kolom yang meningkat secara monoton (seperti yang berisi data TIMESTAMP) dapat menyebabkan hotspot.
Lihat
Yang perlu diketahui DBA tentang Spanner, bagian 1: Kunci dan indeks
untuk mengetahui informasi selengkapnya tentang metode untuk menghindari hotspot.
Memeriksa batasan
Pelajari dukungan batasan CHECK di Spanner.
Objek database lainnya
Anda harus membuat fungsi objek berikut dalam logika aplikasi:
- Dilihat
- Pemicu
- Prosedur tersimpan
- Fungsi yang ditentukan pengguna (UDF)
- Kolom yang menggunakan jenis data
serialsebagai generator urutan
Perhatikan tips berikut saat memigrasikan fungsi ini ke dalam logika aplikasi:
- Anda harus memigrasikan pernyataan SQL yang digunakan dari dialek SQL PostgreSQL ke dialek GoogleSQL.
- Jika menggunakan kursor, Anda dapat mengerjakan ulang kueri untuk menggunakan offset dan batas.
Membuat instance Spanner
Setelah Anda memperbarui pernyataan DDL agar sesuai dengan persyaratan skema Spanner, gunakan pernyataan tersebut untuk membuat database di Spanner.
Buat instance Spanner. Ikuti panduan di Instance untuk menentukan konfigurasi regional dan kapasitas komputasi yang benar untuk mendukung sasaran performa Anda.
Buat database menggunakan konsol Google Cloud atau alat command line
gcloud:
Konsol
- Buka halaman instance
- Klik nama instance tempat Anda ingin membuat database contoh untuk membuka halaman Detail instance.
- Klik Create database.
- Ketik nama untuk database, lalu klik Lanjutkan.
- Di bagian Define your database schema, alihkan kontrol Edit as text.
- Salin dan tempel pernyataan DDL Anda ke kolom DDL statements.
- Klik Create.
gcloud
- Instal gcloud CLI.
- Gunakan perintah
gcloud spanner databases createuntuk membuat database:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME adalah nama database Anda.
- INSTANCE_NAME adalah instance Spanner yang Anda buat.
- DDLn adalah pernyataan DDL yang diubah.
Setelah membuat database, ikuti petunjuk di bagian Menerapkan peran IAM untuk membuat akun pengguna dan memberikan izin ke instance dan database Spanner.
Memfaktorkan ulang aplikasi dan lapisan akses data
Selain kode yang diperlukan untuk mengganti objek database sebelumnya, Anda harus menambahkan logika aplikasi untuk menangani fungsi berikut:
- Meng-hash kunci utama untuk operasi tulis, untuk tabel yang memiliki tingkat operasi tulis yang tinggi ke kunci berurutan.
- Memvalidasi data, yang belum tercakup oleh batasan
CHECK. - Pemeriksaan integritas referensial yang belum dicakup oleh kunci asing, interleaving tabel, atau logika aplikasi, termasuk fungsi yang ditangani oleh pemicu dalam skema PostgreSQL.
Sebaiknya gunakan proses berikut saat memfaktorkan ulang:
- Temukan semua kode aplikasi yang mengakses database, dan faktorkan ulang menjadi satu modul atau library. Dengan begitu, Anda tahu persis kode apa yang mengakses database, sehingga Anda tahu persis kode apa yang perlu diubah.
- Tulis kode yang melakukan operasi baca dan tulis pada instance Spanner, yang menyediakan fungsi paralel ke kode asli yang membaca dan menulis ke PostgreSQL. Selama operasi tulis, perbarui seluruh baris, bukan hanya kolom yang telah diubah, untuk memastikan bahwa data di Spanner identik dengan data di PostgreSQL.
- Tulis kode yang menggantikan fungsi objek database dan fungsi yang tidak tersedia di Spanner.
Migrasikan data
Setelah membuat database Spanner dan memfaktorkan ulang kode aplikasi, Anda dapat memigrasikan data ke Spanner.
- Gunakan perintah
COPYPostgreSQL untuk membuang data ke file .csv. Upload file .csv ke Cloud Storage.
- Buat bucket Cloud Storage.
- Di konsol Cloud Storage, klik nama bucket untuk membuka browser bucket.
- Klik Upload File.
- Buka direktori yang berisi file .csv, lalu pilih file tersebut.
- Klik Buka.
Buat aplikasi untuk mengimpor data ke Spanner. Aplikasi ini dapat menggunakan Dataflow atau dapat menggunakan library klien secara langsung. Pastikan untuk mengikuti panduan dalam Praktik terbaik pemuatan data massal untuk mendapatkan performa terbaik.
Pengujian
Uji semua fungsi aplikasi terhadap instance Spanner untuk memverifikasi bahwa fungsi tersebut berfungsi seperti yang diharapkan. Jalankan beban kerja tingkat produksi untuk memastikan performa memenuhi kebutuhan Anda. Perbarui kapasitas komputasi sesuai kebutuhan untuk memenuhi sasaran performa Anda.
Berpindah ke sistem baru
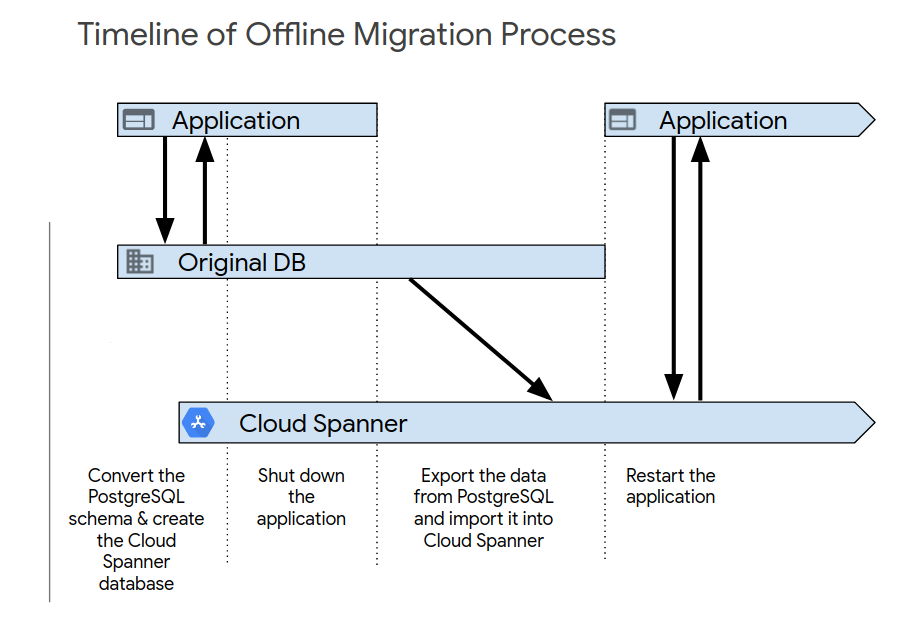
Setelah Anda menyelesaikan pengujian aplikasi awal, aktifkan sistem baru menggunakan salah satu proses berikut. Migrasi offline adalah cara paling sederhana untuk memigrasikan. Namun, pendekatan ini membuat aplikasi Anda tidak tersedia selama periode waktu tertentu, dan tidak memberikan jalur rollback jika Anda menemukan masalah data nanti. Untuk melakukan migrasi offline:
- Menghapus semua data di database Spanner.
- Matikan aplikasi yang menargetkan database PostgreSQL.
- Ekspor semua data dari database PostgreSQL dan impor ke database Spanner seperti yang dijelaskan dalam Ringkasan migrasi.
Mulai aplikasi yang menargetkan database Spanner.
Migrasi langsung dapat dilakukan dan memerlukan perubahan ekstensif pada aplikasi Anda untuk mendukung migrasi.
Contoh migrasi skema
Contoh ini menunjukkan pernyataan CREATE TABLE untuk beberapa tabel dalam
skema database PostgreSQL
MusicBrainz.
Setiap contoh menyertakan skema PostgreSQL dan skema Spanner.
Tabel artist_credit
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
tabel perekaman
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
tabel alias rekaman
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);