本页面提供了有关如何将开源 PostgreSQL 数据库迁移到 Spanner 的指导。
迁移涉及以下任务:
- 将 PostgreSQL 架构映射到 Spanner 架构。
- 创建 Spanner 实例、数据库和架构。
- 重构应用以使用 Spanner 数据库。
- 迁移数据。
- 验证新系统并将其切换到生产状态。
本页面还使用 MusicBrainz PostgreSQL 数据库中的表格提供了一些示例架构。
将 PostgreSQL 架构映射到 Spanner
如需将数据库从 PostgreSQL 迁移到 Spanner,您首先要确定必须进行哪些架构更改。使用 pg_dump 创建数据定义语言 (DDL) 语句,以定义 PostgreSQL 数据库中的对象,然后按照以下部分中的说明修改相应语句。更新 DDL 语句后,使用这些语句在 Spanner 实例中创建数据库。
数据类型
下表说明了 PostgreSQL 数据类型与 Spanner 数据类型的映射关系。将 DDL 语句中的数据类型从 PostgreSQL 数据类型更新为 Spanner 数据类型。
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING,使用标准的 CIDR 表示法。 |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
如果以毫秒为单位存储值,则对应 INT64,如果以应用定义的间隔格式存储值,则对应 STRING。 |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING,使用标准的 MAC 地址表示法。 |
money |
INT64,或者用 STRING 表示任意精度数值。 |
numeric [ (p, s) ]
|
在 PostgreSQL 中,NUMERIC 和 DECIMAL 数据类型最多支持 217 位的精度和 214-1 的标度(如列声明中所定义)。Spanner NUMERIC 数据类型最多支持 38 位的精度和 9 位小数的标度。如果您需要提升精度,请参阅存储任意精度数值数据以了解替代机制。 |
path |
ARRAY<FLOAT64> |
pg_lsn |
此数据类型为 PostgreSQL 所特有,因此没有 Spanner 对等项。 |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING,使用 HH:MM:SS.sss 表示法。 |
time [ (p) ] with time zone
|
STRING,使用 HH:MM:SS.sss+ZZZZ 表示法。或者,可以分为两列,一列的类型为 TIMESTAMP,另一列用于保存时区。 |
timestamp [ (p) ] [ without time zone ] |
无对等项。您可以自行决定存储为 STRING 或 TIMESTAMP。 |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
无对等项。需要在应用中定义存储机制。 |
tsvector |
无对等项。需要在应用中定义存储机制。 |
txid_snapshot |
无对等项。需要在应用中定义存储机制。 |
uuid |
STRING 或 BYTES |
xml |
STRING |
主键
对于 Spanner 数据库中您经常需要附加数据的表,请避免使用单调递增或递减的主键,因为此方法会在写入时生成热点。请修改 DDL CREATE TABLE 语句,让这些语句使用受支持的主键策略。 如果您使用的是 PostgreSQL 功能(例如 UUID 数据类型或函数、SERIAL 数据类型、IDENTITY 列或序列),则可以使用我们推荐的自动生成的键迁移策略。
请注意,指定主键后,如果不删除并重新创建表,则不能添加或移除主键列,也不能更改主键值。如需详细了解如何指定主键,请参阅架构和数据模型 - 主键。
在迁移期间,您可能需要保留一些现有的单调递增整数键。如果您需要将这些类型的键保存在频繁更新的表中,并且会对这些键执行大量操作,可以通过为现有键前加上伪随机数前缀来避免形成热点。此方法可使 Spanner 对行的位置进行重新分布。如需详细了解如何使用此方法,请参阅有关 Spanner 的 DBA 须知事项,第 1 部分:键和索引。
外键和参照完整性
了解 Spanner 中的外键支持。
索引
PostgreSQL b-tree 索引类似于 Spanner 中的二级索引。在 Spanner 数据库中,您可以使用二级索引为常用搜索列编制索引,以获得更好的性能,并替换表中指定的任何 UNIQUE 限制条件。例如,如果您的 PostgreSQL DDL 具有以下语句:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
您可以在 Spanner DDL 中使用此语句:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
您可以通过在 psql 中运行 \di 元命令来查找任何 PostgreSQL 表的索引。
确定所需的索引后,添加 CREATE INDEX 语句进行创建。遵循创建索引中的指导。
Spanner 以表的形式来实现索引,因此对单调递增列(例如包含 TIMESTAMP 数据的列)编制索引可能会生成热点。如需详细了解避免热点的方法,请参阅有关 Spanner 的 DBA 须知事项,第 1 部分:键和索引。
检查限制条件
其他数据库对象
您必须在应用逻辑中创建以下对象的功能:
- 视图
- 触发器
- 存储过程
- 用户定义的函数 (UDF)
- 使用
serial数据类型作为序列生成器的列
将这些功能迁移到应用逻辑时,请谨记以下提示:
- 您必须将自己使用的任何 SQL 语句从 PostgreSQL SQL 方言迁移到 GoogleSQL 方言。
- 如果使用游标,可以重新编写查询以使用偏移量和上限。
创建 Spanner 实例
更新 DDL 语句以符合 Spanner 架构要求后,使用这些语句在 Spanner 中创建数据库。
创建 Spanner 实例。 遵循实例中的指导,确定正确的区域配置和计算容量,以支持您的性能目标。
使用 Google Cloud 控制台或
gcloud命令行工具创建数据库:
控制台
- 转到实例页面
- 点击要在其中创建示例数据库的实例的名称,以打开实例详情页面。
- 点击创建数据库。
- 键入数据库的名称,然后点击继续。
- 在定义数据库架构部分中,切换修改为文本控件。
- 将 DDL 语句复制并粘贴到 DDL 语句字段中。
- 点击创建。
gcloud
- 安装 gcloud CLI。
- 使用
gcloud spanner databases create命令创建数据库:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME 是数据库的名称。
- INSTANCE_NAME 是您创建的 Spanner 实例。
- DDLn 是修改后的 DDL 语句。
创建数据库后,请按照应用 IAM 角色中的说明创建用户账号,并为 Spanner 实例和数据库授予权限。
重构应用和数据访问层
除了替换前面的数据库对象所需的代码之外,还必须添加应用逻辑来处理以下功能:
- 对于具有高写入速率顺序键的表,在写入时对主键进行哈希处理。
- 验证
CHECK限制条件尚未涵盖的数据。 - 外键、表交错或应用逻辑尚未涵盖的参照完整性检查,包括 PostgreSQL 架构中的触发器处理的功能。
我们建议在重构时使用以下流程:
- 找到访问数据库的所有应用代码,并将其重构为单个模块或库。这样,您就可以确切地知道哪些代码访问了数据库,从而明确需要修改哪些代码。
- 编写在 Spanner 实例上执行读写操作的代码,以提供与读取和写入 PostgreSQL 的原始代码并行的功能。在写入期间更新整行,而不仅仅是发生更改的列,以确保 Spanner 中的数据与 PostgreSQL 中的数据一致。
- 编写代码,以替换 Spanner 中不可用的数据库对象和函数的功能。
迁移数据
创建 Spanner 数据库并重构应用代码后,您可以将数据迁移到 Spanner。
- 使用 PostgreSQL
COPY命令将数据转储到 .csv 文件。 将 .csv 文件上传到 Cloud Storage。
- 创建 Cloud Storage 存储桶。
- 在 Cloud Storage 控制台中,点击存储桶名称以打开存储桶浏览器。
- 点击上传文件。
- 导航到包含 .csv 文件的目录并选中它们。
- 点击打开。
创建一个应用以将数据导入 Spanner。此应用可以使用 Dataflow,也可以直接使用客户端库。请务必遵循批量数据加载最佳做法中的指导,以获得最佳性能。
测试
针对 Spanner 实例测试所有应用功能,以验证其是否按预期工作。运行生产级工作负载以确保性能满足您的需求。 根据需要更新计算容量以实现性能目标。
迁移到新系统
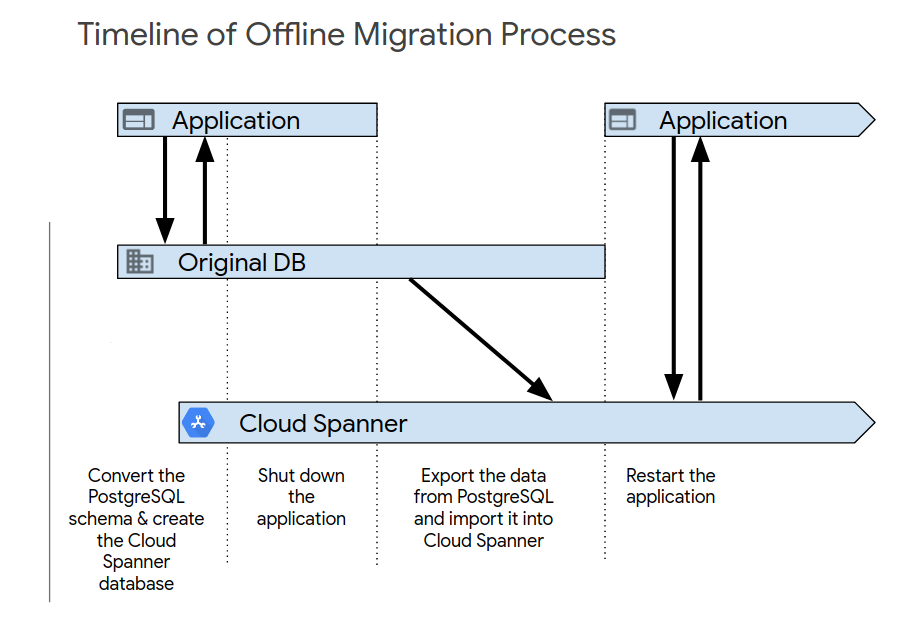
完成初始应用测试后,使用以下流程之一启动新系统。最简单的迁移方法是离线迁移。但是,此方法会使您的应用在一段时间内不可用,并且如果您稍后发现数据问题,此方法无法提供回滚路径。如需执行离线迁移,请执行以下操作:
- 删除 Spanner 数据库中的所有数据。
- 关闭以 PostgreSQL 数据库为目标的应用。
- 按照迁移概览中的说明导出 PostgreSQL 数据库中的所有数据,并将其导入 Spanner 数据库。
启动以 Spanner 数据库为目标的应用。
可以进行实时迁移,并且需要对应用进行大量更改以支持迁移。
架构迁移示例
这些示例显示了 MusicBrainz PostgreSQL 数据库架构中几个表的 CREATE TABLE 语句。每个示例都包含 PostgreSQL 架构和 Spanner 架构。
artist_credit 表
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
录制内容表
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
recording-alias 表
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);