Esta página fornece orientações sobre a migração de uma base de dados PostgreSQL de código aberto para o Spanner.
A migração envolve as seguintes tarefas:
- Mapear um esquema do PostgreSQL para um esquema do Spanner.
- Criar uma instância, uma base de dados e um esquema do Spanner.
- Refatorar a aplicação para funcionar com a sua base de dados do Spanner.
- Migrar os seus dados.
- Validar o novo sistema e movê-lo para o estado de produção.
Esta página também fornece alguns esquemas de exemplo com tabelas da base de dados PostgreSQL MusicBrainz.
Mapeie o seu esquema do PostgreSQL para o Spanner
O primeiro passo para mover uma base de dados do PostgreSQL para o Spanner é determinar que alterações ao esquema tem de fazer. Use
pg_dump
para criar declarações de linguagem de definição de dados (LDD) que definem os objetos na sua base de dados PostgreSQL e, em seguida, modifique as declarações conforme descrito nas secções seguintes. Depois de atualizar as declarações DDL, use-as para criar a sua base de dados numa instância do Spanner.
Tipos de dados
A tabela seguinte descreve como os tipos de dados do PostgreSQL são mapeados para os tipos de dados do Spanner. Atualize os tipos de dados nas suas declarações DDL de tipos de dados do PostgreSQL para tipos de dados do Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, usando a notação CIDR padrão. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 se armazenar o valor em milissegundos ou STRING se armazenar o valor num formato de intervalo definido pela aplicação. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, usando a notação de endereço MAC padrão. |
money |
INT64 ou STRING para números de precisão arbitrária. |
numeric [ (p, s) ]
|
No PostgreSQL, os tipos de dados NUMERIC e DECIMAL suportam até 217 dígitos de precisão e 214-1 de escala, conforme definido na declaração da coluna.O tipo de dados NUMERIC do Spanner suporta até 38 dígitos de precisão e 9 dígitos decimais de escala.Se precisar de maior precisão, consulte o artigo Armazenar dados numéricos de precisão arbitrária para ver mecanismos alternativos. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Este tipo de dados é específico do PostgreSQL, pelo que não existe um equivalente no Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, usando a notação HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, usando a notação HH:MM:SS.sss+ZZZZ. Em alternativa, pode dividir isto em duas colunas, uma do tipo TIMESTAMP e outra com o fuso horário. |
timestamp [ (p) ] [ without time zone ] |
Sem equivalente. Pode armazenar como STRING ou TIMESTAMP à sua discrição. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Sem equivalente. Em alternativa, defina um mecanismo de armazenamento na sua aplicação. |
tsvector |
Sem equivalente. Em alternativa, defina um mecanismo de armazenamento na sua aplicação. |
txid_snapshot |
Sem equivalente. Em alternativa, defina um mecanismo de armazenamento na sua aplicação. |
uuid |
STRING ou BYTES |
xml |
STRING |
Chaves principais
Para tabelas na sua base de dados do Spanner às quais adiciona dados com frequência, evite usar chaves primárias que aumentem ou diminuam monotonicamente, uma vez que esta abordagem causa pontos críticos durante as gravações. Em vez disso, modifique as declarações de LDD CREATE TABLE para que usem estratégias de chave primária suportadas. Se estiver a usar uma funcionalidade do PostgreSQL, como um tipo de dados UUID ou uma função, tipos de dados SERIAL, uma coluna IDENTITY ou uma sequência, pode usar as estratégias de migração de chaves geradas automaticamente que recomendamos.
Tenha em atenção que, depois de designar a chave principal, não pode adicionar nem remover uma coluna de chave principal, nem alterar um valor de chave principal posteriormente sem eliminar e recriar a tabela. Para mais informações sobre como designar a chave principal, consulte o artigo Esquema e modelo de dados – chaves principais.
Durante a migração, pode ter de manter algumas chaves de números inteiros existentes que aumentam monotonicamente. Se precisar de manter este tipo de chaves numa tabela atualizada com frequência com muitas operações nestas chaves, pode evitar a criação de pontos críticos prefixando a chave existente com um número pseudaleatório. Esta técnica faz com que o Spanner redistribua as linhas. Consulte o artigo O que os DBAs precisam de saber sobre o Spanner, parte 1: chaves e índices para mais informações sobre a utilização desta abordagem.
Chaves externas e integridade referencial
Saiba mais sobre o suporte de chaves externas no Spanner.
Índices
Os índices b-tree do PostgreSQL são semelhantes aos índices secundários no Spanner. Numa base de dados do Spanner, usa índices secundários para indexar colunas pesquisadas com frequência para um melhor desempenho e para substituir quaisquer restrições UNIQUE especificadas nas suas tabelas. Por exemplo, se o DDL do PostgreSQL tiver esta declaração:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Usaria esta declaração no seu DDL do Spanner:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Pode encontrar os índices de qualquer uma das suas tabelas PostgreSQL executando o
\di comando meta em psql.
Depois de determinar os índices de que precisa, adicione instruções CREATE INDEX para os criar. Siga as orientações em Criar índices.
O Spanner implementa índices como tabelas, pelo que a indexação de colunas com aumento monotónico (como as que contêm dados TIMESTAMP) pode causar um ponto crítico.
Consulte o artigo
O que os DBAs precisam de saber sobre o Spanner, parte 1: chaves e índices
para mais informações sobre métodos para evitar pontos ativos.
Verifique as restrições
Saiba mais acerca do CHECKsuporte de restrições no Spanner.
Outros objetos da base de dados
Tem de criar a funcionalidade dos seguintes objetos na lógica da sua aplicação:
- Visualizações
- Acionadores
- Procedimentos armazenados
- Funções definidas pelo utilizador (FDUs)
- Colunas que usam tipos de dados
serialcomo geradores de sequências
Tenha em atenção as seguintes dicas quando migrar esta funcionalidade para a lógica da aplicação:
- Tem de migrar todas as declarações SQL que usa do dialeto SQL do PostgreSQL para o dialeto GoogleSQL.
- Se usar cursores, pode reformular a consulta para usar desvios e limites.
Crie a sua instância do Spanner
Depois de atualizar as declarações DDL para estarem em conformidade com os requisitos do esquema do Spanner, use-as para criar a sua base de dados no Spanner.
Crie uma instância do Spanner. Siga as orientações em Instâncias para determinar a configuração regional correta e a capacidade de computação para suportar os seus objetivos de desempenho.
Crie a base de dados através da Google Cloud consola ou da ferramenta de linha de comandos
gcloud:
Consola
- Aceda à página de instâncias
- Clique no nome da instância na qual quer criar a base de dados de exemplo para abrir a página Detalhes da instância.
- Clique em Criar base de dados.
- Escreva um nome para a base de dados e clique em Continuar.
- Na secção Defina o esquema da base de dados, ative/desative o controlo Editar como texto.
- Copie e cole as suas declarações DDL no campo Declarações DDL.
- Clique em Criar.
gcloud
- Instale a CLI gcloud.
- Use o comando
gcloud spanner databases createpara criar a base de dados:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME é o nome da sua base de dados.
- INSTANCE_NAME é a instância do Spanner que criou.
- DDLn são as suas declarações DDL modificadas.
Depois de criar a base de dados, siga as instruções em Aplique funções da IAM para criar contas de utilizador e conceder autorizações à instância e à base de dados do Spanner.
Refatore as aplicações e as camadas de acesso aos dados
Além do código necessário para substituir os objetos da base de dados anteriores, tem de adicionar lógica de aplicação para processar a seguinte funcionalidade:
- Aplicar hash às chaves primárias para escritas, para tabelas com taxas de escrita elevadas em chaves sequenciais.
- Validar dados que ainda não estão abrangidos pelas restrições
CHECK. - Verificações de integridade referencial não abrangidas por chaves externas, intercalação de tabelas ou lógica de aplicação, incluindo a funcionalidade processada por acionadores no esquema PostgreSQL.
Recomendamos que use o seguinte processo ao refatorar:
- Encontre todo o código da sua aplicação que acede à base de dados e refatore-o num único módulo ou biblioteca. Desta forma, sabe exatamente que código acede à base de dados e, por conseguinte, que código tem de ser modificado.
- Escrever código que execute leituras e escritas na instância do Spanner, oferecendo funcionalidade paralela ao código original que lê e escreve no PostgreSQL. Durante as escritas, atualize toda a linha e não apenas as colunas que foram alteradas para garantir que os dados no Spanner são idênticos aos do PostgreSQL.
- Escrever código que substitua a funcionalidade dos objetos e das funções da base de dados que não estão disponíveis no Spanner.
Migre dados
Depois de criar a base de dados do Spanner e refatorar o código da aplicação, pode migrar os seus dados para o Spanner.
- Use o comando
COPYdo PostgreSQL para transferir dados para ficheiros .csv. Carregue os ficheiros .csv para o Cloud Storage.
- Crie um contentor do Cloud Storage.
- Na consola do Cloud Storage, clique no nome do contentor para abrir o navegador de contentores.
- Clique em Carregar ficheiros.
- Navegue para o diretório que contém os ficheiros .csv e selecione-os.
- Clique em Abrir.
Crie uma aplicação para importar dados para o Spanner. Esta aplicação pode usar o Dataflow ou as bibliotecas de cliente diretamente. Certifique-se de que segue as orientações nas práticas recomendadas para o carregamento de dados em massa para obter o melhor desempenho.
Testes
Teste todas as funções da aplicação na instância do Spanner para verificar se funcionam conforme esperado. Execute cargas de trabalho ao nível da produção para garantir que o desempenho cumpre as suas necessidades. Atualize a capacidade de computação conforme necessário para atingir os seus objetivos de desempenho.
Mova-se para o novo sistema
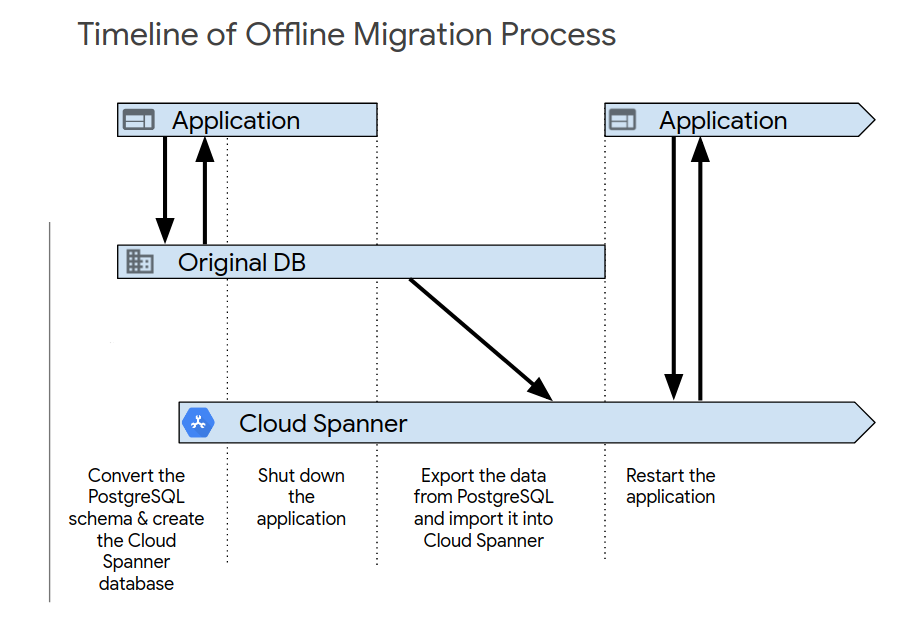
Depois de concluir os testes iniciais da aplicação, ative o novo sistema através de um dos seguintes processos. A migração offline é a forma mais simples de migrar. No entanto, esta abordagem torna a sua aplicação indisponível durante um período e não oferece um caminho de reversão se encontrar problemas de dados mais tarde. Para fazer uma migração offline:
- Eliminar todos os dados na base de dados do Spanner.
- Encerre a aplicação que tem como destino a base de dados PostgreSQL.
- Exporte todos os dados da base de dados PostgreSQL e importe-os para a base de dados Spanner, conforme descrito no Resumo da migração.
Inicie a aplicação que tem como destino a base de dados do Spanner.
A migração em direto é possível e requer alterações extensas à sua aplicação para suportar a migração.
Exemplos de migração de esquemas
Estes exemplos mostram as declarações CREATE TABLE para várias tabelas no
MusicBrainz da base de dados PostgreSQL
MusicBrainz.
Cada exemplo inclui o esquema do PostgreSQL e o esquema do Spanner.
tabela artist_credit
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
tabela de registo
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
recording-alias table
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);