Questa pagina fornisce indicazioni per eseguire la migrazione di un database PostgreSQL open source in Spanner.
La migrazione prevede le seguenti attività:
- Mappazione di uno schema PostgreSQL a uno schema Spanner.
- Creazione di un'istanza, un database e uno schema Spanner.
- Rifacimento dell'applicazione per il funzionamento con il database Spanner.
- Migrazione dei dati.
- Verifica del nuovo sistema e passaggio allo stato di produzione.
Questa pagina fornisce anche alcuni schemi di esempio che utilizzano le tabelle del database PostgreSQL di MusicBrainz.
Mappa lo schema PostgreSQL a Spanner
Il primo passaggio per spostare un database da PostgreSQL a Spanner consiste nel
determinare le modifiche dello schema da apportare. Utilizza
pg_dump
per creare istruzioni Data Definition Language (DDL) che definiscono gli oggetti nel
database PostgreSQL, quindi modifica le istruzioni come descritto nelle
sezioni seguenti. Dopo aver aggiornato le istruzioni DDL, utilizzale per creare il database in un'istanza Spanner.
Tipi di dati
La tabella seguente descrive la mappatura dei tipi di dati PostgreSQL ai tipi di dati Spanner. Aggiorna i tipi di dati nelle istruzioni DDL dai tipi di dati PostgreSQL ai tipi di dati Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, utilizzando la notazione CIDR standard. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 se il valore viene memorizzato in millisecondi o STRING se viene memorizzato in un formato di intervallo definito dall'applicazione. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, utilizzando la notazione standard dell'indirizzo MAC. |
money |
INT64 o STRING per numeri con precisione arbitraria. |
numeric [ (p, s) ]
|
In PostgreSQL, i tipi di dati NUMERIC e DECIMAL supportano fino a 217 cifre di precisione e 214-1 di scala, come definito nella dichiarazione della colonna.Il tipo di dati NUMERIC di Spanner supporta fino a 38 cifre di precisione e 9 cifre decimali di scala.Se hai bisogno di una maggiore precisione, consulta la sezione Memorizzazione di dati numerici di precisione arbitraria per conoscere i meccanismi alternativi. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Questo tipo di dati è specifico di PostgreSQL, pertanto non esiste un equivalente in Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, utilizzando la notazione HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, utilizzando la notazione HH:MM:SS.sss+ZZZZ. In alternativa, può essere suddiviso in due colonne, una di tipo TIMESTAMP e un'altra contenente il fuso orario. |
timestamp [ (p) ] [ without time zone ] |
Nessun equivalente. Puoi archiviare come STRING o TIMESTAMP a tua discrezione. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Nessun equivalente. Definisci un meccanismo di archiviazione nella tua applicazione. |
tsvector |
Nessun equivalente. Definisci un meccanismo di archiviazione nella tua applicazione. |
txid_snapshot |
Nessun equivalente. Definisci un meccanismo di archiviazione nella tua applicazione. |
uuid |
STRING o BYTES |
xml |
STRING |
Chiavi primarie
Per le tabelle del database Spanner a cui aggiungi spesso dati, evita di utilizzare chiavi primarie che aumentano o diminuiscono in modo monotonico, in quanto questo approccio causa hotspot durante le scritture. Modifica invece le istruzioni CREATE TABLE DDL in modo che utilizzino le strategie di chiave primaria supportate. Se utilizzi una funzionalità PostgreSQL, ad esempio un tipo di dati o una funzione UUID, tipi di dati SERIAL, una colonna o una sequenza IDENTITY, puoi utilizzare le strategie di migrazione delle chiavi generate automaticamente che consigliamo.
Tieni presente che, dopo aver designato la chiave primaria, non puoi aggiungere o rimuovere una colonna della chiave primaria né modificare un valore della chiave primaria in un secondo momento senza eliminare e ricreare la tabella. Per ulteriori informazioni su come designare la chiave primaria, consulta Schema e modello di dati - chiavi principali.
Durante la migrazione, potrebbe essere necessario mantenere alcune chiavi intere monotonicamente crescenti esistenti. Se devi conservare questi tipi di chiavi in una tabella aggiornata di frequente con molte operazioni su queste chiavi, puoi evitare di creare hotspot anteponendo alla chiave esistente un numero pseudo-casuale. Questa tecnica consente a Spanner di ridistribuire le righe. Per ulteriori informazioni sull'utilizzo di questo approccio, consulta Che cosa devono sapere i DBA su Spanner, parte 1: chiavi e indici.
Chiavi esterne e integrità referenziale
Scopri di più sul supporto delle chiavi esterne in Spanner.
Indici
Gli indici b-tree di PostgreSQL sono simili agli indici secondari in Spanner. In un database Spanner utilizzi gli indici secondari per indicizzare le colonne più cercate per migliorare le prestazioni e per sostituire eventuali vincoli UNIQUE specificati nelle tabelle. Ad esempio, se il tuo DDL PostgreSQL contiene questa dichiarazione:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Dovresti utilizzare questa istruzione nel DDL di Spanner:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Puoi trovare gli indici di qualsiasi tabella PostgreSQL eseguendo il metacomando \di in psql.
Dopo aver determinato gli indici di cui hai bisogno, aggiungi le istruzioni CREATE INDEX per crearli. Segui le indicazioni riportate in Creare gli indici.
Spanner implementa gli indici come tabelle, pertanto l'indicizzazione delle colonne con incrementi monotonici (come quelle contenenti dati TIMESTAMP) può causare un hotspot.
Per ulteriori informazioni sui metodi per evitare gli hotspot, consulta
Informazioni per i DBA su Spanner, parte 1: chiavi e indici.
Controlla i vincoli
Scopri di più sul supporto dei vincoli CHECK in Spanner.
Altri oggetti di database
Devi creare la funzionalità dei seguenti oggetti nella logica dell'applicazione:
- Visualizzazioni
- Trigger
- Stored procedure
- Funzioni definite dall'utente
- Colonne che utilizzano tipi di dati
serialcome generatori di sequenze
Tieni presente i seguenti suggerimenti durante la migrazione di questa funzionalità nella logica dell'applicazione:
- Devi eseguire la migrazione di tutte le istruzioni SQL che utilizzi dal dialetto SQL di PostgreSQL al dialetto GoogleSQL.
- Se utilizzi cursori, puoi rielaborare la query in modo da utilizzare offset e limiti.
Creare l'istanza Spanner
Dopo aver aggiornato le istruzioni DDL in modo che siano conformi ai requisiti dello schema di Spanner, utilizzale per creare il database in Spanner.
Crea un'istanza Spanner. Segui le indicazioni riportate in Istanze per determinare la configurazione regionale e la capacità di calcolo corretta per supportare i tuoi obiettivi di rendimento.
Crea il database utilizzando la Google Cloud console o lo strumento a riga di comando
gcloud:
Console
- Vai alla pagina delle istanze
- Fai clic sul nome dell'istanza in cui vuoi creare il database di esempio per aprire la pagina Dettagli istanza.
- Fai clic su Crea database.
- Digita un nome per il database e fai clic su Continua.
- Nella sezione Definire lo schema del database, attiva/disattiva il controllo Modifica come testo.
- Copia e incolla le istruzioni DDL nel campo Istruzioni DDL.
- Fai clic su Crea.
gcloud
- Installa la gcloud CLI.
- Utilizza il comando
gcloud spanner databases createper creare il database:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME è il nome del database.
- INSTANCE_NAME è l'istanza Spanner che hai creato.
- DDLn sono le istruzioni DDL modificate.
Dopo aver creato il database, segui le istruzioni riportate in Applicare i ruoli IAM per creare account utente e concedere le autorizzazioni all'istanza e al database Spanner.
Esegui il refactoring dei livelli di accesso ai dati e alle applicazioni
Oltre al codice necessario per sostituire gli oggetti del database precedenti, devi aggiungere la logica dell'applicazione per gestire le seguenti funzionalità:
- Hashing delle chiavi primarie per le scritture, per le tabelle con tassi di scrittura elevati per chiavi sequenziali.
- Convalida dei dati non già coperti dai vincoli
CHECK. - Controlli di integrità referenziale non già coperti dalle chiavi esterne, dall'interlacciamento delle tabelle o dalla logica di applicazione, incluse le funzionalità gestite dagli attivatori nello schema PostgreSQL.
Ti consigliamo di utilizzare la seguente procedura durante il refactoring:
- Trova tutto il codice dell'applicazione che accede al database e ristrutturalo in un unico modulo o libreria. In questo modo, sai esattamente quale codice accede al database e, di conseguenza, quale codice deve essere modificato.
- Scrivi codice che esegue letture e scritture sull'istanza Spanner, fornendo funzionalità parallele al codice originale che legge e scrive in PostgreSQL. Durante le scritture, aggiorna l'intera riga, non solo le colonne che sono state modificate, per assicurarti che i dati in Spanner siano identici a quelli in PostgreSQL.
- Scrivi codice che sostituisca la funzionalità degli oggetti e delle funzioni del database non disponibili in Spanner.
Migrazione dei dati
Dopo aver creato il database Spanner e aver sottoposto a refactoring il codice dell'applicazione, puoi eseguire la migrazione dei dati a Spanner.
- Utilizza il comando PostgreSQL
COPYper eseguire il dump dei dati in file .csv. Carica i file .csv su Cloud Storage.
- Crea un bucket Cloud Storage.
- Nella console Cloud Storage, fai clic sul nome del bucket per aprire il browser del bucket.
- Fai clic su Carica file.
- Vai alla directory contenente i file .csv e selezionali.
- Fai clic su Apri.
Crea un'applicazione per importare i dati in Spanner. Questa applicazione potrebbe utilizzare Dataflow o le librerie client direttamente. Assicurati di seguire le indicazioni riportate nelle best practice per il caricamento collettivo dei dati per ottenere il rendimento migliore.
Test
Testa tutte le funzioni dell'applicazione sull'istanza Spanner per verificare che funzionino come previsto. Esegui carichi di lavoro a livello di produzione per assicurarti che le prestazioni soddisfino le tue esigenze. Aggiorna la capacità di calcolo in base alle tue esigenze per raggiungere i tuoi obiettivi di rendimento.
Passare al nuovo sistema
Dopo aver completato i test iniziali dell'applicazione, configura il nuovo sistema utilizzando una delle seguenti procedure. La migrazione offline è il modo più semplice per eseguire la migrazione. Tuttavia, questo approccio rende l'applicazione non disponibile per un determinato periodo di tempo e non fornisce un percorso di rollback se in un secondo momento riscontri problemi con i dati. Per eseguire una migrazione offline:
- Elimina tutti i dati nel database Spanner.
- Arresta l'applicazione che ha come target il database PostgreSQL.
- Esporta tutti i dati dal database PostgreSQL e importali nel database Spanner come descritto nella Panoramica della migrazione.
Avvia l'applicazione che ha come target il database Spanner.
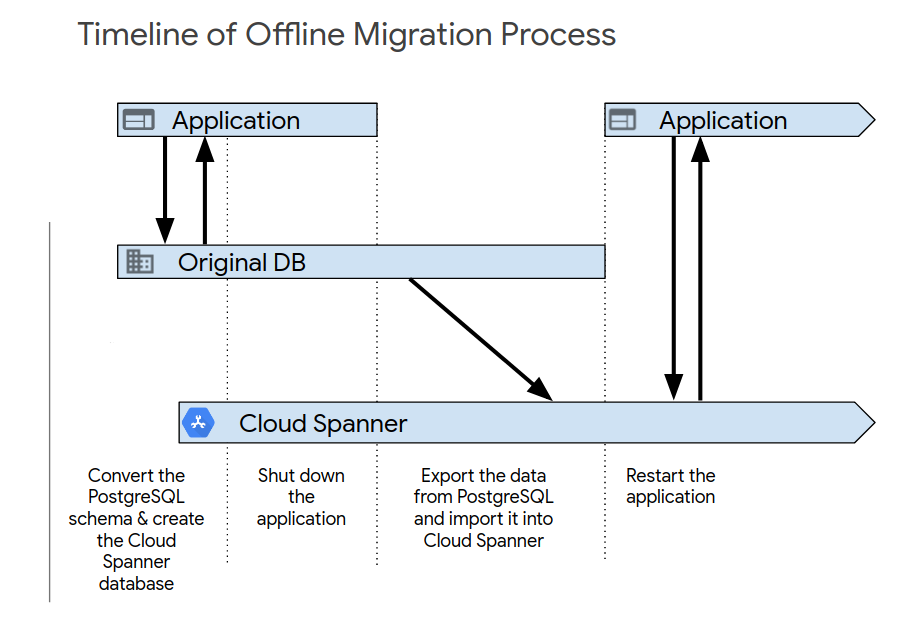
La migrazione live è possibile e richiede modifiche sostanziali all'applicazione per supportarla.
Esempi di migrazione dello schema
Questi esempi mostrano le istruzioni CREATE TABLE per diverse tabelle nello
schema del database PostgreSQL
MusicBrainz.
Ogni esempio include sia lo schema PostgreSQL sia lo schema Spanner.
Tabella artist_credit
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
tabella registrazione
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
Tabella recording-alias
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);