Questo articolo spiega come eseguire la migrazione del tuo database dai sistemi Oracle® Online Transaction Processing (OLTP) a Spanner.
Spanner utilizza alcuni concetti in modo diverso rispetto ad altri strumenti di gestione di database aziendali, quindi potresti dover modificare l'applicazione per sfruttare appieno le sue funzionalità. Potresti anche dover integrare Spanner con altri servizi di Google Cloud per soddisfare le tue esigenze.
Vincoli di migrazione
Quando esegui la migrazione dell'applicazione a Spanner, devi tenere conto delle diverse funzionalità disponibili. Probabilmente devi riprogettare l'architettura dell'applicazione per adattarla al set di funzionalità di Spanner e per integrarla con servizi Google Cloud aggiuntivi.
Stored procedure e trigger
Spanner non supporta l'esecuzione di codice utente a livello di database, quindi, nell'ambito della migrazione, devi spostare la logica di business implementata da procedure e trigger archiviati a livello di database nell'applicazione.
Sequenze
Ti consigliamo di utilizzare l'UUID versione 4 come metodo predefinito per generare valori della chiave primaria.
La funzione GENERATE_UUID() (GoogleSQL,
PostgreSQL)
restituisce i valori UUID versione 4 come tipo STRING.
Se devi generare valori interi a 64 bit, Spanner supporta sequenze con inversione dei bit positive (GoogleSQL, PostgreSQL), che producono valori distribuiti uniformemente nello spazio numerico positivo a 64 bit. Puoi utilizzare questi numeri per evitare problemi di hotspotting.
Per ulteriori informazioni, consulta le strategie per i valori predefiniti delle chiavi primarie.
Controlli di accesso
Identity and Access Management (IAM) ti consente di controllare l'accesso di utenti e gruppi alle risorse Spanner a livello di progetto, istanza Spanner e database Spanner. Per saperne di più, consulta la panoramica di IAM.
Esamina e implementa le policy IAM seguendo il principio del privilegio minimo per tutti gli utenti e gli account di servizio che accedono al tuo database. Se l'applicazione richiede l'accesso limitato a tabelle, colonne, viste o modifiche in tempo reale specifici, implementa controllo dell'accesso granulare (FGAC). Per saperne di più, consulta la panoramica del controllo dell'accesso granulare.
Vincoli di convalida dei dati
Spanner può supportare un insieme limitato di vincoli di convalida dei dati nel livello del database.
Se hai bisogno di vincoli dei dati più complessi, implementali nel livello applicativo.
La tabella seguente illustra i tipi di vincoli comunemente presenti nei database Oracle® e come implementarli con Spanner.
| Vincolo | Implementazione con Spanner |
|---|---|
| Non null | NOT NULLvincolo della colonna |
| Univoco | Indice secondario con vincolo UNIQUE |
| Chiave esterna (per le tabelle normali) | Consulta l'articolo Creazione e gestione di relazioni con le chiave esterna esterne. |
Azioni della chiave esterna ON DELETE/ON UPDATE |
Possibile solo per le tabelle interleaved, altrimenti implementato nel livello applicazione |
Controlli e convalida dei valori tramite vincoli o trigger CHECK
|
Implementato nel livello di applicazione |
Tipi di dati supportati
I database Oracle® e Spanner supportano diversi set di tipi di dati. La tabella seguente elenca i tipi di dati Oracle e i relativi equivalenti in Spanner. Per le definizioni dettagliate di ogni tipo di dati Spanner, vedi Tipi di dati.
Potresti anche dover eseguire trasformazioni aggiuntive sui dati come descritto nella colonna Note per adattare i dati Oracle al tuo database Spanner.
Ad esempio, puoi archiviare un grande BLOB come oggetto in un bucket Cloud Storage anziché nel database, quindi archiviare il riferimento URI all'oggetto Cloud Storage nel database come STRING.
| Tipo di dati Oracle | Equivalente Spanner | Note |
|---|---|---|
Tipi di caratteri (CHAR, VARCHAR, NCHAR,
NVARCHAR)
|
STRING
|
Nota: Spanner utilizza stringhe Unicode. Oracle supporta una lunghezza massima di 32.000 byte o caratteri (a seconda del tipo), mentre Spanner supporta fino a 2.621.440 caratteri. |
BLOB, LONG RAW, BFILE
|
BYTES o STRING contenente l'URI dell'oggetto.
|
Gli oggetti di piccole dimensioni (meno di 10 MiB) possono essere archiviati come BYTES.Prendi in considerazione l'utilizzo di offerte Google Cloud alternative come Cloud Storage per archiviare oggetti più grandi. |
CLOB, NCLOB, LONG
|
STRING (contenente dati o URI all'oggetto esterno)
|
Gli oggetti di piccole dimensioni (meno di 2.621.440 caratteri) possono essere archiviati come
STRING. Prendi in considerazione l'utilizzo di offerte Google Cloud alternative come
Cloud Storage per archiviare oggetti più grandi.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
Il tipo di dati Oracle NUMBER è equivalente al tipo di dati GoogleSQL
NUMERIC. Ciascuno supporta 38 cifre di precisione e
9 cifre di scala: (P,S) = (38,9). Il tipo di dati PostgreSQL
NUMERIC memorizza
dati numerici di precisione arbitraria.
Il tipo di dati GoogleSQL FLOAT64 supporta fino a 16 cifre
di precisione. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
La rappresentazione STRING predefinita del tipo Spanner
DATE è yyyy-mm-dd, che è diversa da quella di Oracle, quindi fai attenzione quando esegui la conversione automatica da e verso le rappresentazioni STRING delle date. Vengono fornite funzioni SQL per
convertire le date in una stringa formattata.
|
DATETIME
|
TIMESTAMP
|
Spanner archivia l'ora indipendentemente dal fuso orario. Se devi
memorizzare un fuso orario, devi utilizzare una colonna STRING separata.
Vengono fornite funzioni SQL per convertire i timestamp in una stringa formattata utilizzando i fusi orari.
|
XML
|
STRING (contenente dati o URI all'oggetto esterno)
|
I piccoli oggetti XML (meno di 2.621.440 caratteri) possono essere archiviati come
STRING. Prendi in considerazione l'utilizzo di offerte Google Cloud alternative
come Cloud Storage per archiviare oggetti più grandi. |
URI, DBURI, XDBURI,
HTTPURI
|
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner utilizza la chiave primaria della tabella per ordinare e fare riferimento
internamente alle righe, quindi in Spanner è effettivamente uguale al
tipo di dati ROWID. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
Spanner non supporta i tipi di dati geospaziali. Dovrai memorizzare questi dati utilizzando tipi di dati standard e implementare qualsiasi logica di ricerca e filtraggio nel livello applicazione. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
Spanner non supporta i tipi di dati multimediali. Prendi in considerazione l'utilizzo di Cloud Storage per archiviare i dati multimediali. |
Processo di migrazione
Una cronologia generale del processo di migrazione potrebbe essere la seguente:
- Converti lo schema e il modello dei dati.
- Tradurre le query SQL.
- Esegui la migrazione dell'applicazione per utilizzare Spanner oltre a Oracle.
- Esporta in blocco i dati da Oracle e importali in Spanner utilizzando Dataflow.
- Mantieni la coerenza tra entrambi i database durante la migrazione.
- Esegui la migrazione della tua applicazione da Oracle.
Passaggio 1: converti il database e lo schema
Converti lo schema esistente in uno schema Spanner per archiviare i dati. Questo deve corrispondere il più possibile allo schema Oracle esistente per semplificare le modifiche all'applicazione. Tuttavia, a causa delle differenze nelle funzionalità, saranno necessarie alcune modifiche.
L'utilizzo delle best practice nella progettazione dello schema può aiutarti ad aumentare la velocità effettiva e a ridurre i punti critici nel tuo database Spanner.
Chiavi primarie
In Spanner, ogni tabella che deve memorizzare più di una riga deve avere una chiave primaria composta da una o più colonne della tabella. La chiave primaria della tabella identifica in modo univoco ogni riga di una tabella e le righe della tabella sono ordinate in base alla chiave primaria. Poiché Spanner è altamente distribuito, è importante scegliere una tecnica di generazione della chiave primaria che si adatti bene alla crescita dei dati. Per maggiori informazioni, consulta le strategie di migrazione delle chiavi primarie consigliate.
Tieni presente che dopo aver designato la chiave primaria, non puoi aggiungere o rimuovere una colonna della chiave primaria o modificare un valore della chiave primaria in un secondo momento senza eliminare e ricreare la tabella. Per ulteriori informazioni su come designare la chiave primaria, consulta Schema e modello dei dati - chiavi primarie.
Alternare le tabelle
Spanner ha una funzionalità che consente di definire due tabelle con una relazione padre-figlio uno-a-molti. In questo modo, le righe di dati secondari vengono alternate alla riga principale nell'archiviazione, unendo in modo efficace la tabella e migliorando l'efficienza del recupero dei dati quando la riga principale e le righe secondarie vengono interrogate insieme.
La chiave primaria della tabella figlio deve iniziare con la colonna o le colonne di chiave primaria della tabella padre. Dal punto di vista della riga figlio, la chiave primaria della riga padre è denominata chiave esterna. Puoi definire fino a 6 livelli di relazioni padre-figlio.
Puoi definire azioni di eliminazione per le tabelle secondarie per determinare cosa succede quando viene eliminata la riga principale: vengono eliminate tutte le righe secondarie oppure l'eliminazione della riga principale viene bloccata finché esistono righe secondarie.
Ecco un esempio di creazione di una tabella Albums intercalata nella tabella Singers padre definita in precedenza:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Crea indici secondari
Puoi anche creare indici secondari per indicizzare i dati all'interno della tabella al di fuori della chiave primaria.
Spanner implementa gli indici secondari nello stesso modo delle tabelle, quindi i valori delle colonne da utilizzare come chiavi di indice hanno gli stessi vincoli delle chiavi primarie delle tabelle. Ciò significa anche che gli indici hanno le stesse garanzie di coerenza delle tabelle Spanner.
Le ricerche di valori che utilizzano indici secondari sono effettivamente uguali a una query con un
join di tabelle. Puoi migliorare il rendimento delle query utilizzando gli indici memorizzando
copie dei valori delle colonne della tabella originale nell'indice secondario utilizzando la
clausola STORING, rendendolo un
indice di copertura.
L'ottimizzatore di query di Spanner utilizza automaticamente gli indici secondari solo quando l'indice stesso memorizza tutte le colonne sottoposte a query (una query coperta). Per forzare l'utilizzo di un indice durante l'esecuzione di query sulle colonne della tabella originale, devi utilizzare un'istruzione FORCE INDEX nell'istruzione SQL, ad esempio:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Gli indici possono essere utilizzati per applicare valori univoci all'interno di una colonna della tabella definendo
un
UNIQUEindice
in quella colonna. L'aggiunta di valori duplicati verrà impedita dall'indice.
Di seguito è riportato un esempio di istruzione DDL che crea un indice secondario per la tabella Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Tieni presente che se crei indici aggiuntivi dopo il caricamento dei dati, il popolamento dell'indice potrebbe richiedere un po' di tempo. Dovresti limitare la frequenza con cui li aggiungi a una media di tre al giorno. Per ulteriori indicazioni sulla creazione di indici secondari, consulta la sezione Indici secondari. Per ulteriori informazioni sulle limitazioni alla creazione di indici, consulta la sezione Aggiornamenti dello schema.
Passaggio 2: traduci le query SQL
Spanner utilizza il dialetto ANSI 2011 di SQL con estensioni e dispone di molte funzioni e operatori per facilitare la traduzione e l'aggregazione dei dati. Devi convertire tutte le query SQL che utilizzano sintassi, funzioni e tipi specifici di Oracle per renderli compatibili con Spanner.
Anche se Spanner non supporta i dati strutturati come definizioni di colonne, i dati strutturati possono essere utilizzati nelle query SQL utilizzando i tipi ARRAY e STRUCT.
Ad esempio, una query potrebbe essere scritta per restituire tutti gli album di un artista utilizzando
un ARRAY di STRUCTs in una singola query (sfruttando i dati pre-uniti).
Per saperne di più, consulta la sezione
Note sulle sottoquery
della documentazione.
È possibile profilare le query SQL utilizzando la pagina Spanner Studio nella console Google Cloud per eseguire la query. In generale, le query che eseguono scansioni complete delle tabelle di grandi dimensioni sono molto costose e devono essere utilizzate con parsimonia.
Per saperne di più sull'ottimizzazione delle query SQL, consulta la documentazione sulle best practice per SQL.
Passaggio 3: esegui la migrazione dell'applicazione per utilizzare Spanner
Spanner fornisce un insieme di librerie client per vari linguaggi e la possibilità di leggere e scrivere dati utilizzando chiamate API specifiche di Spanner, nonché utilizzando query SQL e istruzioni DML (Data Manipulation Language). L'utilizzo di chiamate API potrebbe essere più veloce per alcune query, ad esempio le letture dirette di righe per chiave, perché l'istruzione SQL non deve essere tradotta.
Puoi anche utilizzare il driver Java Database Connectivity (JDBC) per connetterti a Spanner, sfruttando l'infrastruttura e gli strumenti esistenti che non dispongono di un'integrazione nativa.
Nell'ambito del processo di migrazione, le funzionalità non disponibili in Spanner devono essere implementate nell'applicazione. Ad esempio, un trigger per verificare i valori dei dati e aggiornare una tabella correlata dovrebbe essere implementato nell'applicazione utilizzando una transazione di lettura/scrittura per leggere la riga esistente, verificare il vincolo e poi scrivere le righe aggiornate in entrambe le tabelle.
Spanner offre transazioni di lettura/scrittura e di sola lettura, che garantiscono la coerenza esterna dei dati. Inoltre, alle transazioni di lettura possono essere applicati limiti temporali, in cui viene letta una versione coerente dei dati specificati nei seguenti modi:
- In un momento esatto del passato (fino a un'ora fa).
- In futuro (la lettura verrà bloccata fino a quel momento).
- Con una quantità accettabile di non aggiornamento vincolato, che restituirà una visualizzazione coerente fino a un certo momento nel passato senza dover verificare che i dati successivi siano disponibili su un'altra replica. Ciò può offrire vantaggi in termini di prestazioni a discapito di dati potenzialmente obsoleti.
Passaggio 4: trasferisci i dati da Oracle a Spanner
Per trasferire i dati da Oracle a Spanner, devi esportare il database Oracle in un formato di file portatile, ad esempio CSV, quindi importare i dati in Spanner utilizzando Dataflow.
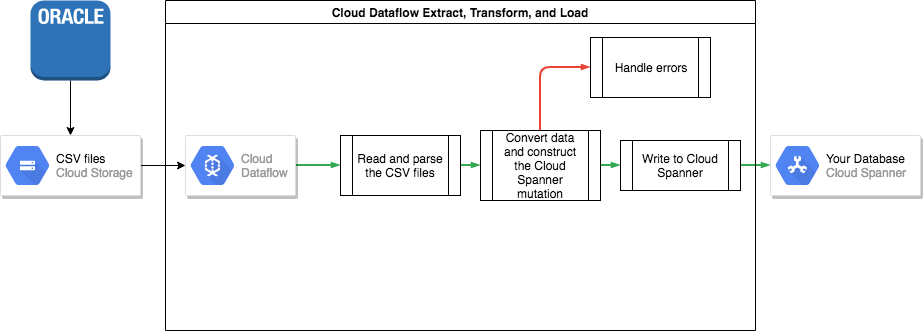
Esportazione collettiva da Oracle
Oracle non fornisce utilità integrate per esportare o scaricare l'intero database in un formato di file portatile.
Alcune opzioni per eseguire un'esportazione sono elencate nelle domande frequenti di Oracle.
Questi includono:
- Utilizzo di SQL*plus o SQLcl per salvare una query in un file di testo.
- Scrittura di una funzione PL/SQL utilizzando UTL_FILE per scaricare una tabella in parallelo in file di testo.
- Utilizzando le funzionalità di Oracle APEX o Oracle SQL Developer per scaricare una tabella in un file CSV o XML.
Ognuno di questi metodi presenta lo svantaggio di poter esportare una sola tabella alla volta, il che significa che devi mettere in pausa l'applicazione o rendere inattivo il database in modo che rimanga in uno stato coerente per l'esportazione.
Altre opzioni includono strumenti di terze parti elencati nella pagina Domande frequenti su Oracle, alcuni dei quali possono scaricare una visualizzazione coerente dell'intero database.
Una volta scaricati, devi caricare questi file di dati in un bucket Cloud Storage in modo che siano accessibili per l'importazione.
Importazione collettiva in Spanner
Poiché gli schemi di database probabilmente differiscono tra Oracle e Spanner, potresti dover eseguire alcune conversioni dei dati nell'ambito del processo di importazione.
Il modo più semplice per eseguire queste conversioni dei dati e importarli in Spanner è utilizzare Dataflow.
Dataflow è il servizio ETL (Extract, Transform and Load) distribuito. Google Cloud Fornisce una piattaforma per l'esecuzione di pipeline di dati scritte utilizzando l'SDK Apache Beam per leggere ed elaborare grandi quantità di dati in parallelo su più macchine.
L'SDK Apache Beam richiede di scrivere un semplice programma Java per impostare la lettura, la trasformazione e la scrittura dei dati. Esistono connettori Beam per Cloud Storage e Spanner, quindi l'unico codice da scrivere è la trasformazione dei dati.
Consulta un esempio di una semplice pipeline che legge da file CSV e scrive in Spanner nel repository di codice di esempio che accompagna questo articolo.
Se nel tuo schema Spanner vengono utilizzate tabelle interleaved padre-figlio, è necessario prestare attenzione al processo di importazione in modo che la riga padre venga creata prima della riga figlio. Il codice della pipeline di importazione Spanner gestisce questa operazione importando prima tutti i dati per le tabelle di livello radice, poi tutte le tabelle secondarie di livello 1, poi tutte le tabelle secondarie di livello 2 e così via.
La pipeline di importazione di Spanner può essere utilizzata direttamente per importare i dati in blocco,ma ciò richiede che i dati esistano in file Avro utilizzando lo schema corretto.
Passaggio 5: mantieni la coerenza tra entrambi i database
Molte applicazioni hanno requisiti di disponibilità che rendono impossibile mantenere l'applicazione offline per il tempo necessario per esportare e importare i dati. Durante il trasferimento dei dati a Spanner, la tua applicazione continua a modificare il database esistente. Devi duplicare gli aggiornamenti al database Spanner mentre l'applicazione è in esecuzione.
Esistono vari metodi per mantenere sincronizzate le due banche dati, tra cui l'acquisizione delle modifiche ai dati e l'implementazione di aggiornamenti simultanei nell'applicazione.
Change Data Capture (CDC)
Oracle GoldenGate può fornire uno stream di Change Data Capture (CDC) per il tuo database Oracle. LogMiner o Oracle XStream Out sono interfacce alternative per il database Oracle per ottenere un flusso CDC che non coinvolge Oracle GoldenGate.
Puoi scrivere un'applicazione che si iscriva a uno di questi stream e che applichi le stesse modifiche (dopo la conversione dei dati, ovviamente) al tuo database Spanner. Un'applicazione di elaborazione dei flussi deve implementare diverse funzionalità:
- Connessione al database Oracle (database di origine).
- Connessione a Spanner (database di destinazione).
- Eseguendo ripetutamente le seguenti operazioni:
- Ricezione dei dati prodotti da uno degli stream CDC del database Oracle.
- Interpretazione dei dati prodotti dallo stream CDC.
- Conversione dei dati in istruzioni
INSERTdi Spanner. - Esecuzione delle istruzioni Spanner
INSERT.
La tecnologia di migrazione del database è una tecnologia middleware che ha implementato le funzionalità richieste come parte della sua funzionalità. La piattaforma di migrazione del database viene installata come componente separato nella posizione di origine o di destinazione, in base ai requisiti del cliente. La piattaforma di migrazione del database richiede solo la configurazione della connettività dei database coinvolti per specificare e avviare il trasferimento continuo dei dati dall'origine al database di destinazione.
Striim è una piattaforma tecnologica per la migrazione dei database disponibile suGoogle Cloud. Fornisce connettività ai flussi CDC da Oracle GoldenGate, Oracle LogMiner e Oracle XStream Out. Striim fornisce uno strumento grafico che ti consente di configurare la connettività del database e le regole di trasformazione necessarie per trasferire i dati da Oracle a Spanner.
Puoi installare Striim da Google Cloud Marketplace, connetterti ai database di origine e di destinazione, implementare le regole di trasformazione e iniziare a trasferire i dati senza dover creare tu stesso un'applicazione di elaborazione dei flussi.
Aggiornamenti simultanei a entrambi i database dall'applicazione
Un metodo alternativo consiste nel modificare l'applicazione per eseguire scritture in entrambi i database. Un database (inizialmente Oracle) sarebbe considerato l'origine di riferimento e, dopo ogni scrittura del database, l'intera riga viene letta, convertita e scritta nel database Spanner.
In questo modo, l'applicazione sovrascrive costantemente le righe Spanner con i dati più recenti.
Dopo aver verificato che tutti i dati siano stati trasferiti correttamente, puoi impostare il database Spanner come origine attendibile.
Questo meccanismo fornisce un percorso di rollback se vengono rilevati problemi durante il passaggio a Spanner.
Verificare la coerenza dei dati
Man mano che i dati vengono trasmessi in streaming nel tuo database Spanner, puoi eseguire periodicamente un confronto tra i dati di Spanner e quelli di Oracle per assicurarti che siano coerenti.
Puoi convalidare la coerenza eseguendo query su entrambe le origini dati e confrontando i risultati.
Puoi utilizzare Dataflow per eseguire un confronto dettagliato su set di dati di grandi dimensioni utilizzando la trasformazione Join. Questa trasformazione accetta due set di dati con chiavi e associa i valori in base alla chiave. I valori corrispondenti possono quindi essere confrontati per verificare l'uguaglianza.
Puoi eseguire regolarmente questa verifica finché il livello di coerenza non corrisponde ai requisiti della tua attività.
Passaggio 6: passa a Spanner come origine attendibile della tua applicazione
Quando hai fiducia nella migrazione dei dati, puoi passare all'utilizzo di Spanner come fonte attendibile per la tua applicazione. Continua a scrivere le modifiche al database Oracle per mantenerlo aggiornato, in modo da avere un percorso di rollback in caso di problemi.
Infine, puoi disattivare e rimuovere il codice di aggiornamento del database Oracle e arrestare il database Oracle.
Esportare e importare database Spanner
Se vuoi, puoi esportare le tabelle da Spanner in un bucket Cloud Storage utilizzando un modello Dataflow per eseguire l'esportazione. La cartella risultante contiene un insieme di file Avro e file manifest JSON contenenti le tabelle esportate. Questi file possono servire a vari scopi, tra cui:
- Eseguire il backup del database per la conformità alle norme di conservazione dei dati o per il ripristino di emergenza.
- Importazione del file Avro in altre Google Cloud offerte come BigQuery.
Per saperne di più sulla procedura di esportazione e importazione, consulta Esportazione di database e Importazione di database.
Passaggi successivi
- Scopri come ottimizzare lo schema Spanner.
- Scopri come utilizzare Dataflow per situazioni più complesse.