Tutorial ini menjelaskan cara bermigrasi dari Amazon DynamoDB ke Spanner. Panduan ini terutama ditujukan untuk pemilik aplikasi yang ingin berpindah dari sistem NoSQL ke Spanner, sistem database SQL yang sangat skalabel, toleran terhadap kesalahan, dan relasional sepenuhnya yang mendukung transaksi. Jika Anda memiliki penggunaan tabel Amazon DynamoDB yang konsisten, dalam hal jenis dan tata letak, pemetaan ke Spanner sangat mudah. Jika tabel Amazon DynamoDB Anda berisi jenis dan nilai data arbitrer, mungkin lebih mudah untuk beralih ke layanan NoSQL lain, seperti Datastore atau Firestore.
Tutorial ini mengasumsikan bahwa Anda sudah memahami skema database, jenis data, dasar-dasar NoSQL, dan sistem database relasional. Tutorial ini bergantung pada cara menjalankan tugas yang telah ditetapkan untuk melakukan contoh migrasi. Setelah tutorial, Anda dapat mengubah kode dan langkah yang diberikan agar sesuai dengan lingkungan Anda.
Diagram arsitektur berikut menguraikan komponen yang digunakan dalam tutorial untuk memigrasikan data:

Tujuan
- Memigrasikan data dari Amazon DynamoDB ke Spanner.
- Buat database Spanner dan tabel migrasi.
- Memetakan skema NoSQL ke skema relasional.
- Buat dan ekspor contoh set data yang menggunakan Amazon DynamoDB.
- Transfer data antara Amazon S3 dan Cloud Storage.
- Gunakan Dataflow untuk memuat data ke Spanner.
Biaya
Tutorial ini menggunakan komponen Google Cloud yang dapat ditagih berikut: Google Cloud
Biaya Spanner didasarkan pada jumlah kapasitas komputasi di instance Anda dan jumlah data yang disimpan selama siklus penagihan bulanan. Selama tutorial, Anda menggunakan konfigurasi minimal untuk resource ini, yang akan dibersihkan di akhir. Untuk skenario dunia nyata, perkirakan persyaratan throughput dan penyimpanan Anda, lalu gunakan dokumentasi instance Spanner untuk menentukan jumlah kapasitas komputasi yang Anda butuhkan.
Selain resource Google Cloud , tutorial ini menggunakan resource Amazon Web Services (AWS) berikut:
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
Layanan ini hanya diperlukan selama proses migrasi. Di akhir tutorial, ikuti petunjuk untuk membersihkan semua resource guna mencegah biaya yang tidak perlu. Gunakan kalkulator harga AWS untuk memperkirakan biaya ini.
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda, gunakan kalkulator harga.
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Tetapkan zona Compute Engine default. Misalnya,
us-central1-b. gcloud config set compute/zone us-central1-b - Clone repositori GitHub yang berisi kode contoh. git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- Buka direktori yang telah di-clone. cd dynamodb-spanner-migration
- Buat lingkungan virtual Python. pip3 install virtualenv virtualenv env
- Aktifkan lingkungan virtual. source env/bin/activate
- Instal modul Python yang diperlukan. pip3 install -r requirements.txt
- Di konsol AWS, buka bagian IAM, klik Roles, lalu pilih Create role.
- Di bagian Jenis entitas tepercaya, pastikan Layanan AWS dipilih.
- Di bagian Kasus penggunaan, pilih Lambda, lalu klik Berikutnya.
- Di kotak filter Kebijakan izin, masukkan
AWSLambdaDynamoDBExecutionRoledan tekanReturnuntuk menelusuri. - Centang kotak AWSLambdaDynamoDBExecutionRole, lalu klik Next.
- Di kotak Role name, masukkan
dynamodb-spanner-lambda-role, lalu klik Create role. - Saat Anda masih berada di bagian IAM pada konsol AWS, klik Users, lalu pilih Add users.
- Di kotak Nama pengguna, masukkan
dynamodb-spanner-migration. Di bagian Jenis akses, centang kotak di sebelah kiri Kunci akses - Akses terprogram.
Klik Berikutnya: Izin.
Klik Lampirkan kebijakan yang ada secara langsung, dan gunakan kotak Penelusuran untuk memfilter, pilih kotak centang di samping masing-masing dari tiga kebijakan berikut:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
Klik Berikutnya: Tag dan Berikutnya: Tinjau, lalu klik Buat pengguna.
Klik Tampilkan untuk melihat kredensial. ID kunci akses dan kunci akses rahasia ditampilkan untuk pengguna yang baru dibuat. Biarkan jendela ini terbuka untuk saat ini karena kredensial diperlukan di bagian berikutnya. Simpan kredensial ini dengan aman karena dengan kredensial tersebut, Anda dapat membuat perubahan pada akun dan memengaruhi lingkungan Anda. Di akhir tutorial ini, Anda dapat menghapus pengguna IAM.
Di Cloud Shell, konfigurasi AWS Command Line Interface (CLI).
aws configure
Output berikut akan muncul:
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- Masukkan
ACCESS KEY IDdanSECRET ACCESS KEYdari akun AWS IAM yang Anda buat. - Di kolom Default region name, masukkan
us-west-2. Biarkan kolom lain tetap pada nilai defaultnya.
- Masukkan
Tutup jendela konsol AWS IAM.
Di Cloud Shell, buat tabel Amazon DynamoDB yang menggunakan atribut tabel contoh.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75Verifikasi bahwa status tabel adalah
ACTIVE.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'Isi tabel dengan data sampel.
python3 make-fake-data.py --table Migration --items 25000
Buat instance Spanner di region yang sama dengan tempat Anda menetapkan zona Compute Engine default. Misalnya,
us-central1.gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Buat database di instance Spanner bersama dengan tabel contoh.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"Di Cloud Shell, aktifkan streaming Amazon DynamoDB di tabel sumber Anda.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGESSiapkan topik Pub/Sub untuk menerima perubahan.
gcloud pubsub topics create spanner-migration
Output berikut akan muncul:
Created topic [projects/your-project/topics/spanner-migration].
Buat akun layanan IAM untuk mengirimkan update tabel ke topik Pub/Sub.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"Output berikut akan muncul:
Created service account [spanner-migration].
Buat binding kebijakan IAM agar akun layanan memiliki izin untuk memublikasikan ke Pub/Sub. Ganti
GOOGLE_CLOUD_PROJECTdengan nama project Google Cloud Anda.gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comOutput berikut akan muncul:
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
Buat kredensial untuk akun layanan.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comOutput berikut akan muncul:
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
Siapkan dan kemas fungsi AWS Lambda untuk mengirim perubahan tabel Amazon DynamoDB ke topik Pub/Sub.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
Buat variabel untuk mengambil Amazon Resource Name (ARN) peran eksekusi Lambda yang Anda buat sebelumnya.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)Gunakan paket
pubsub-lambda.zipuntuk membuat fungsi AWS Lambda.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"Output berikut akan muncul:
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Buat variabel untuk mengambil ARN aliran Amazon DynamoDB untuk tabel Anda.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Lampirkan fungsi Lambda ke tabel Amazon DynamoDB.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONUntuk mengoptimalkan responsivitas selama pengujian, tambahkan
--batch-size 1di akhir perintah sebelumnya, yang akan memicu fungsi setiap kali Anda membuat, memperbarui, atau menghapus item.Anda akan melihat output yang mirip dengan berikut ini:
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...Di Cloud Shell, buat variabel untuk nama bucket yang Anda gunakan di beberapa bagian berikut.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportBuat bucket Amazon S3 untuk menerima ekspor DynamoDB.
aws s3 mb s3://${BUCKET}Di AWS Management Console, buka DynamoDB, lalu klik Tables.
Klik tabel
Migration.Di tab Ekspor dan streaming, klik Ekspor ke S3.
Aktifkan
point-in-time-recovery(PITR) jika diminta.Klik Browse S3 untuk memilih bucket S3 yang Anda buat sebelumnya.
Klik Ekspor.
Klik ikon Muat ulang untuk memperbarui status tugas ekspor. Tugas ini memerlukan waktu beberapa menit untuk menyelesaikan ekspor.
Setelah proses selesai, lihat bucket output.
aws s3 ls --recursive s3://${BUCKET}Langkah ini diperkirakan akan memakan waktu sekitar 5 menit. Setelah selesai, Anda akan melihat output seperti berikut:
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
Di Cloud Shell, buat bucket Cloud Storage untuk menerima file yang diekspor dari Amazon S3.
gcloud storage buckets create gs://${BUCKET}Sinkronkan file dari Amazon S3 ke Cloud Storage. Untuk sebagian besar operasi penyalinan, perintah
rsyncefektif. Jika file ekspor Anda berukuran besar (beberapa GB atau lebih), gunakan layanan transfer Cloud Storage untuk mengelola transfer di latar belakang.gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objectsUntuk menulis data dari file yang diekspor ke tabel Spanner, jalankan tugas Dataflow dengan contoh kode Apache Beam.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Untuk memantau progres tugas impor, di konsol Google Cloud , buka Dataflow.
Saat tugas berjalan, Anda dapat melihat grafik eksekusi untuk memeriksa log. Klik tugas yang menampilkan Status Running.
Klik setiap tahap untuk melihat jumlah elemen yang telah diproses. Impor selesai jika semua tahap menampilkan Berhasil. Jumlah elemen yang sama yang dibuat di tabel Amazon DynamoDB Anda ditampilkan sebagai diproses di setiap tahap.
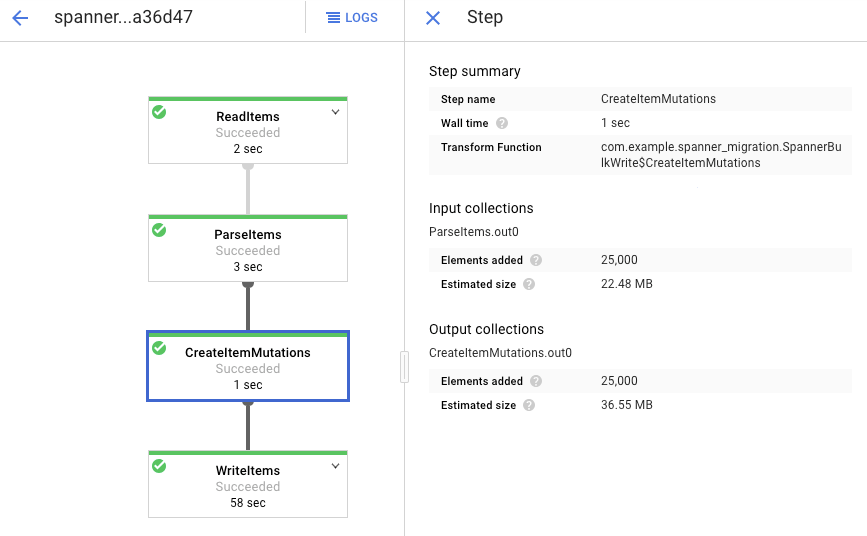
Verifikasi bahwa jumlah data dalam tabel Spanner tujuan cocok dengan jumlah item dalam tabel Amazon DynamoDB.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
Output berikut akan muncul:
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
Ambil sampel entri acak di setiap tabel untuk memastikan data konsisten.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"Output berikut akan muncul:
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
Kueri tabel Amazon DynamoDB dengan
Usernameyang sama yang ditampilkan dari kueri Spanner pada langkah sebelumnya. Contoh,aallen2538. Nilai ini khusus untuk data sampel di database Anda.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'Nilai kolom lainnya harus cocok dengan nilai dari output Spanner. Output berikut akan muncul:
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }Buat langganan ke topik Pub/Sub yang digunakan AWS Lambda untuk mengirim peristiwa.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migrationOutput berikut akan muncul:
Created subscription [projects/your-project/subscriptions/spanner-migration].
Untuk melakukan streaming perubahan yang masuk ke Pub/Sub untuk ditulis ke tabel Spanner, jalankan tugas Dataflow dari Cloud Shell.
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"Mirip dengan langkah pemuatan batch, untuk melihat progres tugas, di konsol Google Cloud , buka Dataflow.
Klik tugas yang memiliki Status Berjalan.
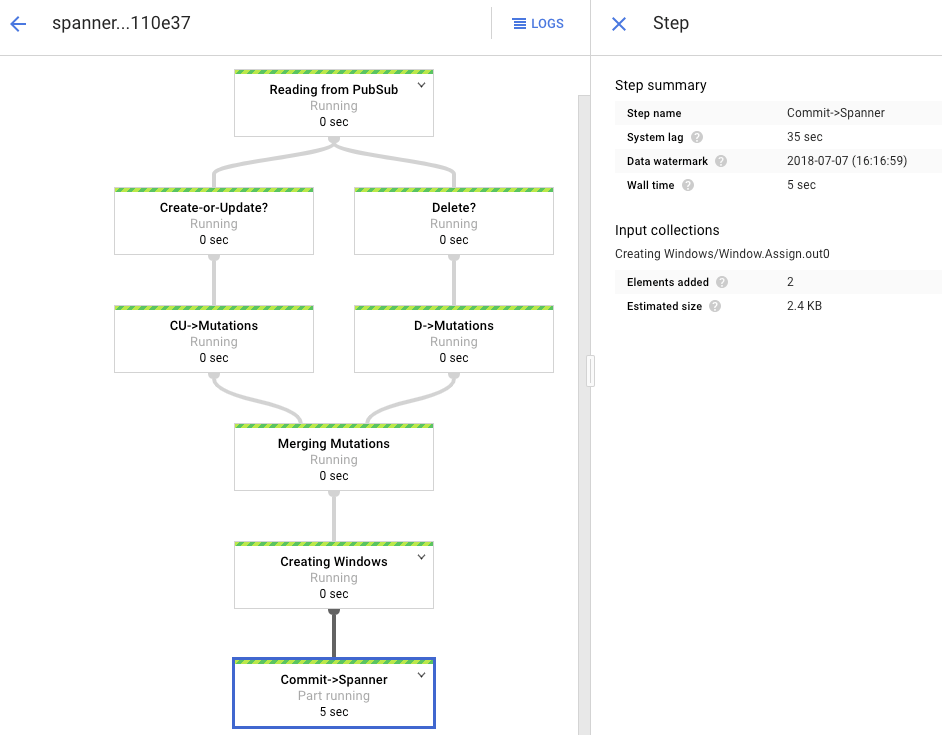
Grafik pemrosesan menunjukkan output yang serupa seperti sebelumnya, tetapi setiap item yang diproses dihitung di jendela status. Waktu jeda sistem adalah perkiraan kasar tentang seberapa besar penundaan yang akan terjadi sebelum perubahan muncul di tabel Spanner.
Buat kueri baris yang tidak ada di Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Operasi tidak akan menampilkan hasil apa pun.
Buat data di Amazon DynamoDB dengan kunci yang sama yang Anda gunakan dalam kueri Spanner. Jika perintah berhasil dijalankan, tidak ada output.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'Jalankan kueri yang sama lagi untuk memverifikasi bahwa baris tersebut kini ada di Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Output menampilkan baris yang disisipkan:
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
Ubah beberapa atribut pada item asli dan perbarui tabel Amazon DynamoDB.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEWAnda akan melihat output yang mirip dengan berikut ini:
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }Verifikasi bahwa perubahan disebarkan ke tabel Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Output-nya akan muncul seperti berikut:
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Hapus item pengujian dari tabel sumber Amazon DynamoDB.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'Pastikan baris yang sesuai dihapus dari tabel Spanner. Saat perubahan disebarkan, perintah berikut akan menampilkan nol baris:
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Buka Spanner.
Klik Spanner Studio.
Di kolom Query, masukkan kueri berikut, lalu klik Run query.
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
Setelah kueri berjalan, klik Penjelasan dan perhatikan Baris yang dipindai versus Baris yang ditampilkan. Tanpa indeks, Spanner memindai seluruh tabel untuk menampilkan sebagian kecil data yang cocok dengan kueri.
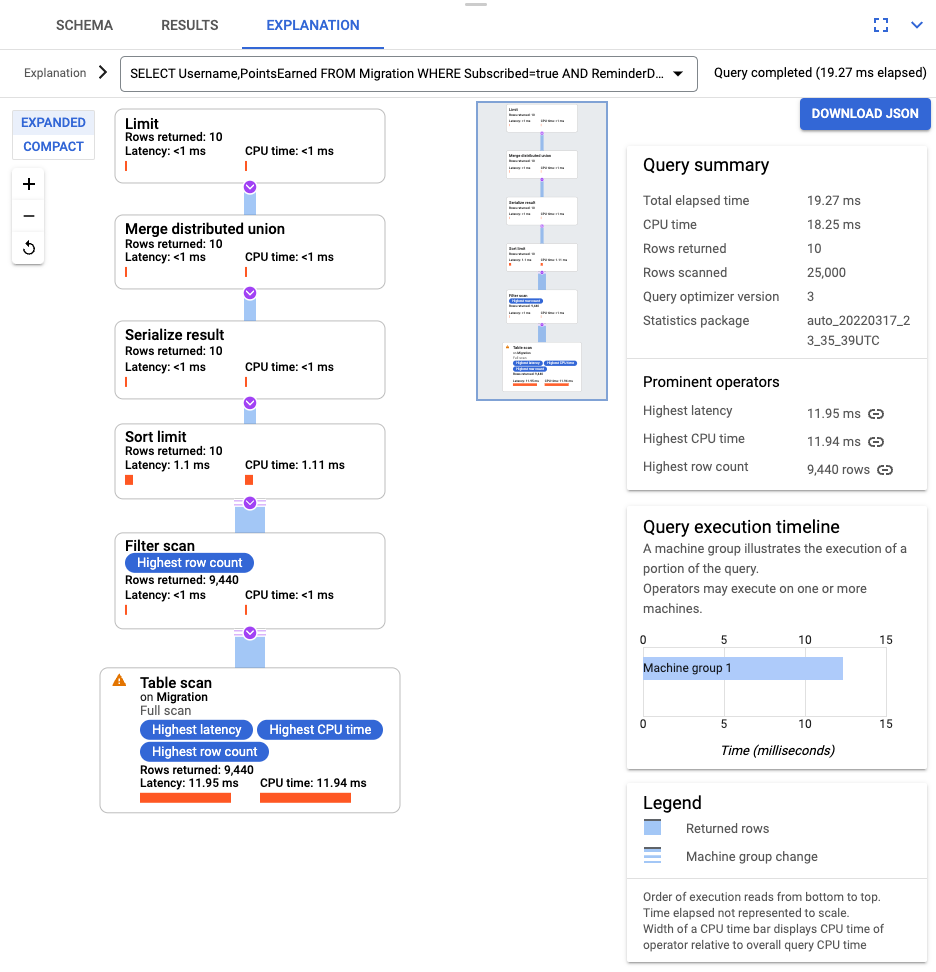
Jika kueri ini sering terjadi, buat indeks gabungan pada kolom Subscribed dan ReminderDate. Di konsol Spanner, pilih panel navigasi kiri Indexes, lalu klik Create Index.
Di kotak teks, masukkan definisi indeks.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
Untuk mulai membuat database di latar belakang, klik Buat.
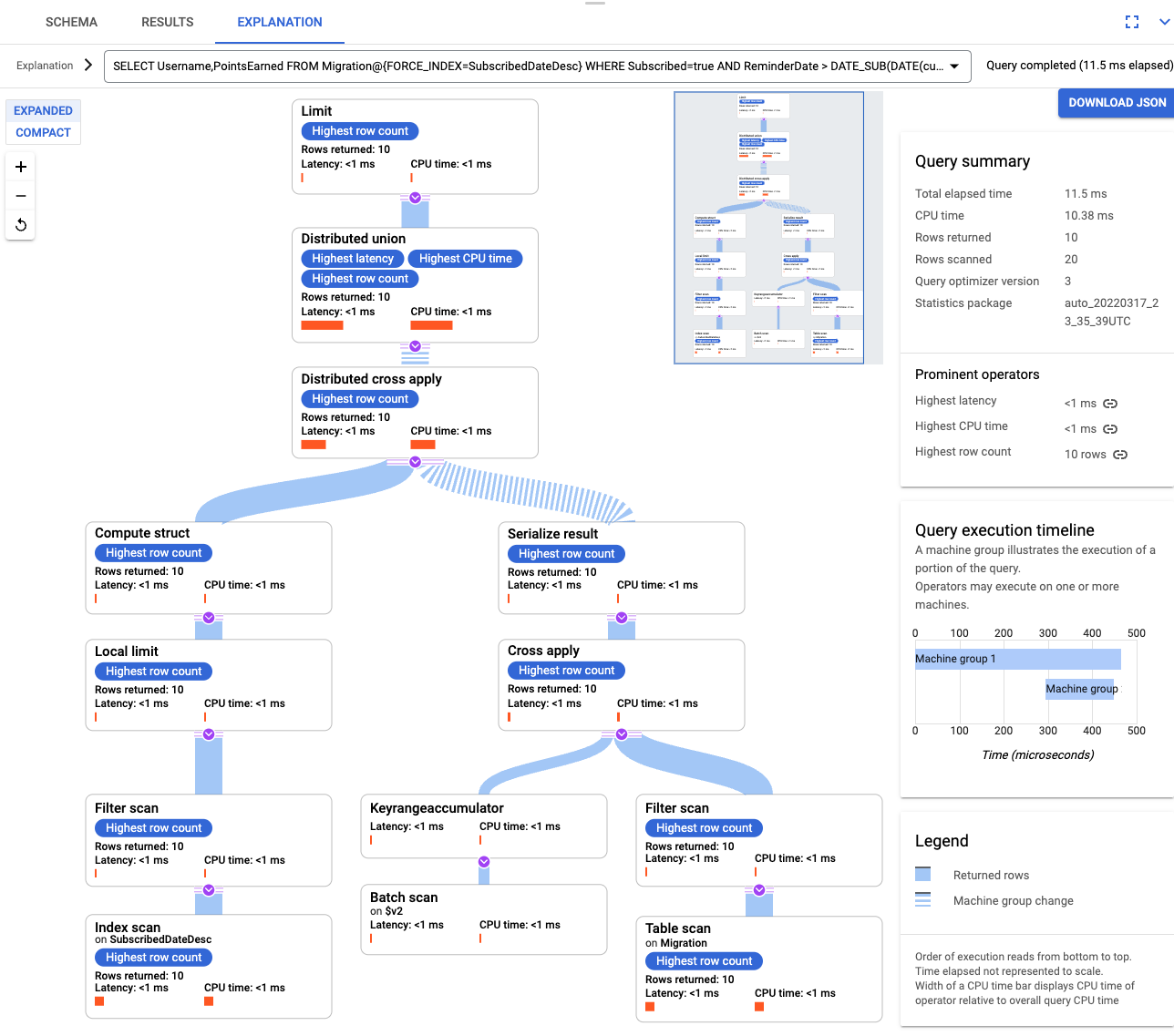
Setelah indeks dibuat, jalankan kueri lagi dan tambahkan indeks.
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10Periksa kembali penjelasan kueri. Perhatikan bahwa jumlah Baris yang dipindai telah berkurang. Baris yang ditampilkan di setiap langkah cocok dengan jumlah yang ditampilkan oleh kueri.
Untuk mengurai JSON masuk dan membuat mutasi, gunakan GSON. Sesuaikan definisi JSON agar sesuai dengan data Anda.
Sesuaikan pemetaan JSON yang sesuai.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Hapus tabel DynamoDB yang disebut Migration.
- Hapus bucket Amazon S3 dan fungsi Lambda yang Anda buat selama langkah-langkah migrasi.
- Terakhir, hapus pengguna AWS IAM yang Anda buat selama tutorial ini.
- Baca cara mengoptimalkan skema Spanner.
- Pelajari cara menggunakan Dataflow untuk situasi yang lebih kompleks.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, lihat Pembersihan.
Menyiapkan lingkungan Anda
Dalam tutorial ini, Anda akan menjalankan perintah di Cloud Shell. Cloud Shell memberi Anda akses ke command line di Google Cloud, dan mencakup Google Cloud CLI serta alat lain yang Anda perlukan untuk pengembangan Google Cloud . Cloud Shell dapat memerlukan waktu beberapa menit untuk diinisialisasi.
Mengonfigurasi akses AWS
Dalam tutorial ini, Anda akan membuat dan menghapus tabel Amazon DynamoDB, bucket Amazon S3, dan resource lainnya. Untuk mengakses resource ini, Anda harus membuat izin AWS Identity and Access Management (IAM) yang diperlukan terlebih dahulu. Anda dapat menggunakan akun AWS pengujian atau sandbox agar tidak memengaruhi resource produksi di akun yang sama.
Membuat peran AWS IAM untuk AWS Lambda
Di bagian ini, Anda akan membuat peran AWS IAM yang digunakan AWS Lambda pada langkah selanjutnya dalam tutorial.
Membuat pengguna AWS IAM
Ikuti langkah-langkah berikut untuk membuat pengguna AWS IAM dengan akses terprogram ke resource AWS, yang digunakan di seluruh tutorial.
Mengonfigurasi antarmuka command line AWS
Memahami model data
Bagian berikut menguraikan persamaan dan perbedaan antara jenis data, kunci, dan indeks untuk Amazon DynamoDB dan Spanner.
Jenis data
Spanner menggunakan jenis data GoogleSQL. Tabel berikut menjelaskan cara pemetaan jenis data Amazon DynamoDB ke jenis data Spanner.
| Amazon DynamoDB | Spanner |
|---|---|
| Angka | Bergantung pada presisi atau penggunaan yang dimaksudkan, dapat dipetakan ke INT64, FLOAT64, TIMESTAMP, atau DATE. |
| String | String |
| Boolean | BOOL |
| Null | Tidak ada jenis eksplisit. Kolom dapat berisi nilai null. |
| Biner | Byte |
| Setelan | Array |
| Peta dan Daftar | Struct jika strukturnya konsisten dan dapat dideskripsikan menggunakan sintaksis DDL tabel. |
Kunci utama
Kunci utama Amazon DynamoDB menetapkan keunikan dan dapat berupa kunci hash atau kombinasi kunci hash dan kunci rentang. Tutorial ini dimulai dengan menunjukkan migrasi tabel Amazon DynamoDB yang kunci utamanya adalah kunci hash. Kunci hash ini menjadi kunci utama tabel Spanner Anda. Selanjutnya, di bagian tabel yang disisipkan, Anda memodelkan situasi saat tabel Amazon DynamoDB menggunakan kunci utama yang terdiri dari kunci hash dan kunci rentang.
Indeks sekunder
Amazon DynamoDB dan Spanner mendukung pembuatan indeks pada atribut kunci non-primer. Catat indeks sekunder di tabel Amazon DynamoDB Anda agar Anda dapat membuatnya di tabel Spanner, yang dibahas di bagian selanjutnya dalam tutorial ini.
Contoh tabel
Untuk memfasilitasi tutorial ini, Anda akan memigrasikan tabel contoh berikut dari Amazon DynamoDB ke Spanner:
| Amazon DynamoDB | Spanner | |
|---|---|---|
| Nama tabel |
Migration
|
Migration
|
| Kunci utama |
"Username" : String
|
"Username" : STRING(1024)
|
| Jenis kunci | Hash | t/a |
| Kolom lainnya |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Siapkan tabel Amazon DynamoDB
Di bagian berikut, Anda akan membuat tabel sumber Amazon DynamoDB dan mengisinya dengan data.
Membuat database Spanner
Anda membuat instance Spanner dengan kapasitas komputasi terkecil: 100 unit pemrosesan. Kapasitas komputasi ini sudah cukup untuk cakupan tutorial ini. Untuk deployment produksi, lihat dokumentasi tentang instance Spanner untuk menentukan kapasitas komputasi yang sesuai guna memenuhi persyaratan performa database Anda.
Dalam contoh ini, Anda membuat skema tabel bersamaan dengan database. Pembaruan skema juga dapat dilakukan, dan sering terjadi, setelah Anda membuat database.
Mempersiapkan migrasi
Bagian berikutnya menunjukkan cara mengekspor tabel sumber Amazon DynamoDB dan menetapkan replikasi Pub/Sub untuk merekam perubahan apa pun pada database yang terjadi saat Anda mengekspornya.
Mengalirkan perubahan ke Pub/Sub
Anda menggunakan fungsi AWS Lambda untuk melakukan streaming perubahan database ke Pub/Sub.
Mengekspor tabel Amazon DynamoDB ke Amazon S3
Melakukan migrasi
Setelah pengiriman Pub/Sub dilakukan, Anda dapat meneruskan perubahan tabel yang terjadi setelah ekspor.
Menyalin tabel yang diekspor ke Cloud Storage
Mengimpor data secara batch
Mereplikasi perubahan baru
Setelah tugas impor batch selesai, Anda menyiapkan tugas streaming untuk menulis pembaruan berkelanjutan dari tabel sumber ke Spanner. Anda berlangganan ke peristiwa dari Pub/Sub dan menuliskannya ke Spanner
Fungsi Lambda yang Anda buat dikonfigurasi untuk merekam perubahan pada tabel Amazon DynamoDB sumber dan memublikasikannya ke Pub/Sub.
Tugas Dataflow yang Anda jalankan dalam fase pemuatan batch adalah sekumpulan input terbatas, yang juga dikenal sebagai set data terbatas. Tugas Dataflow ini menggunakan Pub/Sub sebagai sumber streaming dan dianggap tidak terbatas. Untuk mengetahui informasi selengkapnya tentang kedua jenis sumber ini, tinjau bagian tentang PCollection dalam panduan pemrograman Apache Beam. Tugas Dataflow pada langkah ini dimaksudkan agar tetap aktif, sehingga tidak berhenti saat selesai. Tugas Dataflow streaming tetap dalam status Berjalan, bukan status Berhasil.
Memverifikasi replikasi
Anda membuat beberapa perubahan pada tabel sumber untuk memverifikasi bahwa perubahan tersebut direplikasi ke tabel Spanner.
Menggunakan tabel sisipan
Spanner mendukung konsep penyisipan tabel. Ini adalah model desain di mana item tingkat atas memiliki beberapa item bertingkat yang terkait dengan item tingkat atas tersebut, seperti pelanggan dan pesanan mereka, atau pemain dan skor game mereka. Jika tabel sumber Amazon DynamoDB Anda menggunakan kunci utama yang terdiri dari kunci hash dan kunci rentang, Anda dapat memodelkan skema tabel yang disisipkan seperti yang ditunjukkan dalam diagram berikut. Struktur ini memungkinkan Anda mengkueri tabel yang disisipkan secara efisien sambil menggabungkan kolom di tabel induk.

Menerapkan indeks sekunder
Praktik terbaik adalah menerapkan indeks sekunder ke tabel Spanner setelah Anda memuat data. Setelah replikasi berfungsi, Anda menyiapkan indeks sekunder untuk mempercepat kueri. Seperti tabel Spanner, indeks sekunder Spanner sepenuhnya konsisten. Database ini tidak konsisten pada akhirnya, yang umum di banyak database NoSQL. Fitur ini dapat membantu menyederhanakan desain aplikasi Anda
Jalankan kueri yang tidak menggunakan indeks apa pun. Anda mencari N teratas kemunculan, mengingat nilai kolom tertentu. Ini adalah kueri umum di Amazon DynamoDB untuk efisiensi database.
Indeks yang disisipkan
Anda dapat menyiapkan indeks yang disisipkan di Spanner. Indeks sekunder yang dibahas di bagian sebelumnya berada di root hierarki database, dan menggunakan indeks dengan cara yang sama seperti database konvensional. Indeks yang disisipkan berada dalam konteks baris yang disisipkannya. Lihat opsi indeks untuk mengetahui detail selengkapnya tentang tempat penerapan indeks berselang-seling.
Menyesuaikan model data Anda
Untuk menyesuaikan bagian migrasi dalam tutorial ini dengan situasi Anda sendiri, ubah file sumber Apache Beam. Anda tidak boleh mengubah skema sumber selama periode migrasi yang sebenarnya, jika tidak, Anda dapat kehilangan data.
Pada langkah sebelumnya, Anda telah mengubah kode sumber Apache Beam untuk impor massal. Ubah kode sumber untuk bagian streaming pipeline dengan cara yang serupa. Terakhir, sesuaikan skrip pembuatan tabel, skema, dan indeks database target Spanner Anda.
Pembersihan
Agar tidak dikenai biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus project
Menghapus resource AWS
Jika akun AWS Anda digunakan di luar tutorial ini, berhati-hatilah saat Anda menghapus resource berikut: