En esta página, se proporciona una descripción general de los componentes de alto nivel que participan en una solicitud de Spanner y cómo cada componente puede afectar la latencia.
Solicitudes a la API de Spanner
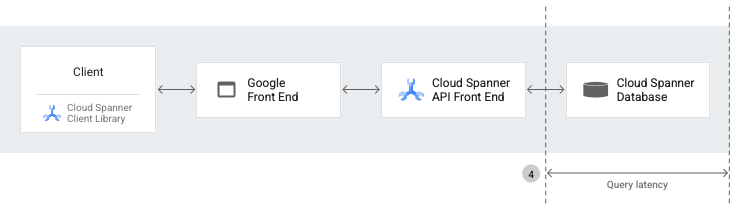
Entre los componentes de alto nivel que se usan para realizar una solicitud a la API de Spanner, se incluyen los siguientes:
Bibliotecas cliente de Spanner, que proporcionan una capa de abstracción sobre gRPC y controlan los detalles de comunicación del servidor, como la administración de sesiones, las transacciones y los reintentos.
Google Front End (GFE), que es un servicio de infraestructura común para todos los servicios de Google Cloud , incluido Spanner. El GFE verifica que todas las conexiones de seguridad de la capa de transporte (TLS) se detengan y aplica protecciones contra ataques de denegación del servicio. Para obtener más información sobre el GFE, consulta Servicio de Google Front End.
El frontend de la API de Spanner (AFE), que realiza varias verificaciones en la solicitud a la API (incluidas la autenticación, la autorización y las verificaciones de cuota), y mantiene los estados de las sesiones y las transacciones.
La base de datos de Spanner, que ejecuta lecturas y escrituras en la base de datos.
Cuando realizas una llamada de procedimiento remoto a Spanner, las bibliotecas cliente de Spanner preparan la solicitud a la API. Luego, la solicitud de API pasa por el GFE y el AFE de Spanner antes de llegar a la base de datos de Spanner.
Si mides y comparas las latencias de las solicitudes entre los diferentes componentes y la base de datos, puedes determinar qué componente está causando el problema. Estas latencias incluyen la latencia de ida y vuelta del cliente, la del GFE, la de la solicitud a la API de Spanner y la de la consulta.
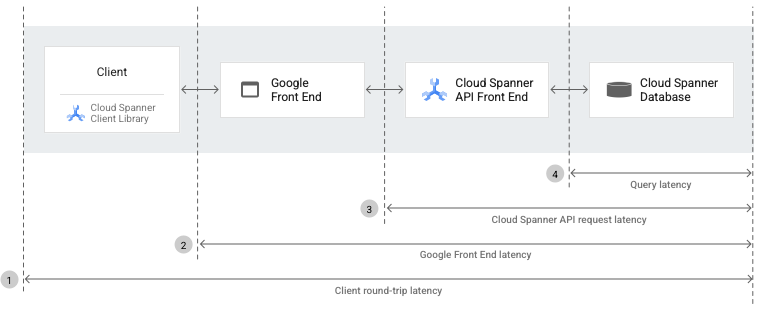
En las siguientes secciones, se explica cada tipo de latencia que se muestra en el diagrama anterior.
Latencia de ida y vuelta del cliente
La latencia de ida y vuelta del cliente es el período (en milisegundos) entre el primer byte de la solicitud de la API de Spanner que el cliente envía a la base de datos (a través del GFE y el frontend de la API de Spanner) y el último byte de respuesta que el cliente recibe de la base de datos.
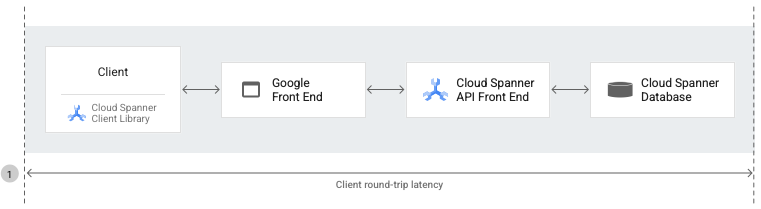
La métrica grpc.io/client/roundtrip_latency proporciona el tiempo entre el primer byte de la solicitud de API enviada y el último byte de la respuesta recibida.
Para capturar y visualizar la latencia de este componente, consulta Cómo capturar la latencia de ida y vuelta del cliente con OpenTelemetry o con OpenCensus.
Latencia de GFE
La latencia de Google Front End (GFE) es el período (en milisegundos) entre el momento en que la red de Google recibe una llamada a procedimiento remoto del cliente y el momento en que GFE recibe el primer byte de la respuesta. Esta latencia no incluye ningún protocolo de enlace TCP/SSL.
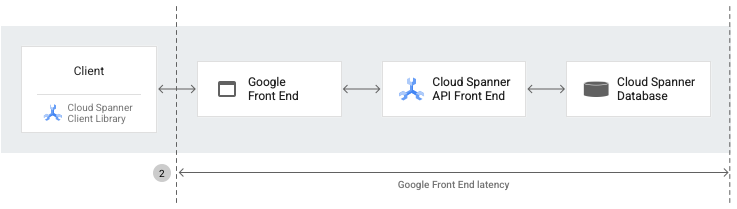
Todas las respuestas de Spanner, ya sean de REST o gRPC, incluyen un encabezado que contiene el tiempo total entre el GFE y el backend (el servicio de Spanner) tanto para la solicitud como para la respuesta. Esto ayuda a diferenciar mejor la fuente de la latencia entre el cliente y la red de Google.
La métrica spanner/gfe_latency captura y expone la latencia de GFE para las solicitudes de Spanner.
Para capturar y visualizar la latencia de este componente, consulta Cómo capturar la latencia de GFE con OpenTelemetry o con OpenCensus.
Latencia de solicitudes de la API de Spanner
La latencia de la solicitud de la API de Spanner es el período (en segundos) entre el primer byte de la solicitud que recibe el AFE de Spanner y el último byte de la respuesta que envía el frontend de la API de Spanner. La latencia incluye el tiempo necesario para procesar las solicitudes a la API tanto en el backend de Spanner como en la capa de API. Sin embargo, esta latencia no incluye la sobrecarga de red o del proxy inverso entre los clientes y los servidores de Spanner.
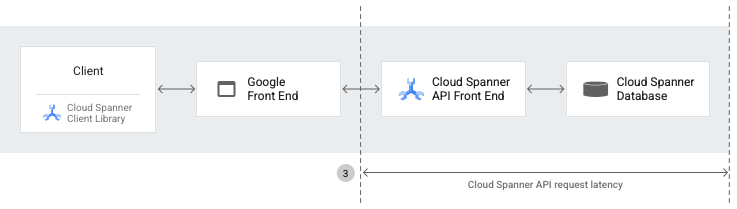
La métrica spanner.googleapis.com/api/request_latencies captura y expone la latencia de la AFE de Spanner para las solicitudes de Spanner.
Para capturar y visualizar la latencia de este componente, consulta Cómo capturar la latencia de las solicitudes a la API de Spanner con OpenTelemetry o con OpenCensus.
Latencia de las consultas
La latencia de la consulta es el tiempo (en milisegundos) que se tarda en ejecutar consultas en SQL en la base de datos de Spanner.
La latencia de las consultas está disponible para la API de executeSql.
Si el parámetro QueryMode se establece en WITH_STATS o WITH_PLAN_AND_STATS, los ResultSetStats de Spanner estarán disponibles en las respuestas. ResultSetStats incluye el tiempo transcurrido para ejecutar consultas en la base de datos de Spanner.
Para capturar y visualizar la latencia de este componente, consulta Cómo capturar la latencia de las consultas con OpenTelemetry o con OpenCensus.
¿Qué sigue?
- Aprende a identificar los puntos de latencia en los componentes de Spanner.