Cette page présente les composants de haut niveau impliqués dans une requête Spanner et explique comment chacun d'eux peut affecter la latence.
Requêtes de l'API Spanner
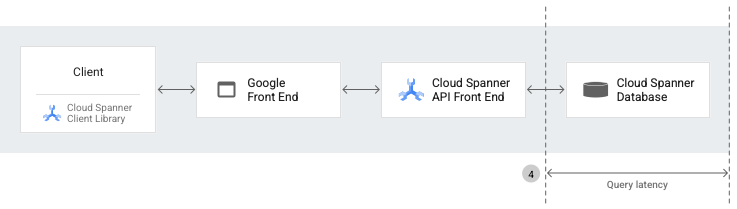
Les composants de haut niveau utilisés pour effectuer une requête dans l'API Spanner sont les suivants :
Les bibliothèques clientes Spanner fournissent une couche d'abstraction au-dessus de gRPC et gèrent les détails de la communication avec le serveur, tels que la gestion des sessions, les transactions et les nouvelles tentatives.
Google Front End (GFE), un service d'infrastructure commun à tous les services Google Cloud , y compris Spanner. Le GFE vérifie que toutes les connexions TLS (Transport Layer Security) sont arrêtées et applique des protections contre les attaques par déni de service. Pour en savoir plus sur GFE, consultez la page Service Google Front End.
L'interface utilisateur de l'API Spanner (AFE), qui effectue diverses vérifications de la requête API (y compris les vérifications d'authentification, d'autorisation et de quota), et gère les sessions et les états de transaction.
La base de données Spanner, qui exécute les lectures et les écritures dans la base de données.
Lorsque vous effectuez un appel de procédure à distance vers Spanner, les bibliothèques clientes Spanner préparent la requête API. La requête API passe ensuite par le GFE et l'AFE Spanner avant d'atteindre la base de données Spanner.
En mesurant et en comparant les latences des requêtes entre différents composants et la base de données, vous pouvez déterminer quel composant pose problème. Ces latences incluent les latences d'aller-retour client, de requête GFE, de requête API Spanner et de requête en général.
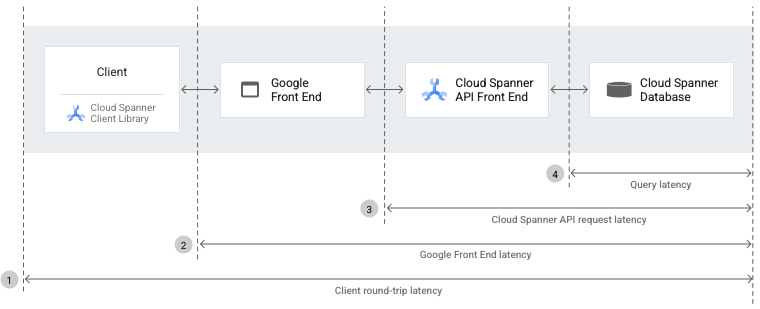
Les sections suivantes expliquent chaque type de latence que vous voyez dans le diagramme précédent.
Latence aller-retour du client
La latence aller-retour client correspond à la durée (en millisecondes) entre le premier octet de la requête API Spanner que le client envoie à la base de données (via le GFE et l'interface de l'API Spanner) et le dernier octet de la réponse que le client reçoit de la base de données.
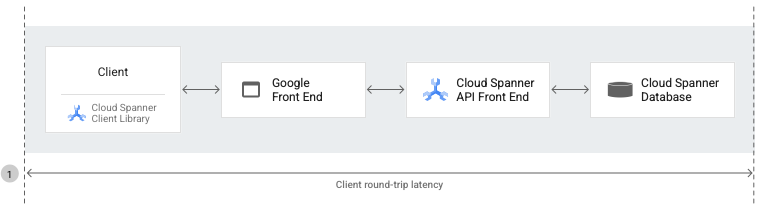
La métrique grpc.io/client/roundtrip_latency fournit le temps écoulé entre le premier octet de la requête API envoyée et le dernier octet de la réponse reçue.
Pour capturer et visualiser la latence de ce composant, consultez Capturer la latence aller-retour du client avec OpenTelemetry ou avec OpenCensus.
Latence des GFE
La latence Google Front End (GFE) correspond à la durée (en millisecondes) entre le moment où le réseau Google reçoit un appel de procédure à distance du client et le moment où le GFE reçoit le premier octet de la réponse. Cette latence n'inclut pas le handshake TCP/SSL.
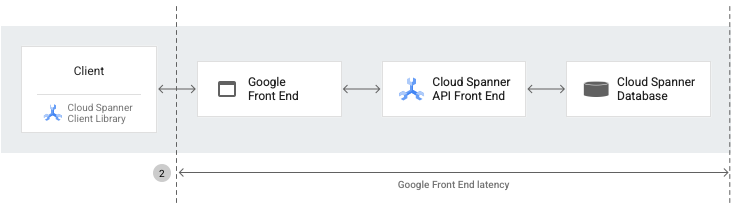
Chaque réponse de Spanner, qu'il s'agisse de REST ou de gRPC, inclut un en-tête contenant le temps total entre le GFE et le backend (le service Spanner), pour la requête et la réponse. Cela permet de mieux distinguer la source de la latence entre le client et le réseau Google.
La métrique spanner/gfe_latency capture et expose la latence GFE pour les requêtes Spanner.
Pour capturer et visualiser la latence de ce composant, consultez Capturer la latence GFE avec OpenTelemetry ou avec OpenCensus.
Latence des requêtes de l'API Spanner
La latence des requêtes de l'API Spanner correspond à la durée (en secondes) entre le premier octet de requête envoyé par l'AFE Spanner et le dernier octet de réponse envoyé par l'interface de l'API Spanner. La latence inclut le temps nécessaire au traitement des requêtes API, à la fois dans le backend Spanner et dans la couche d'API. Toutefois, cette latence n'inclut pas la surcharge réseau ni celle du proxy inverse entre les clients et les serveurs Spanner.
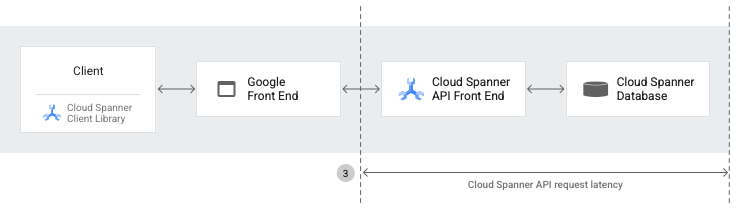
La métrique spanner.googleapis.com/api/request_latencies capture et expose la latence de l'AFE Spanner pour les requêtes Spanner.
Pour capturer et visualiser la latence de ce composant, consultez Capturer la latence des requêtes de l'API Spanner avec OpenTelemetry ou avec OpenCensus.
Latence des requêtes
La latence des requêtes correspond à la durée (en millisecondes) d'exécution des requêtes SQL dans la base de données Spanner.
La latence des requêtes est disponible pour l'API executeSql.
Si le paramètre QueryMode est défini sur WITH_STATS ou WITH_PLAN_AND_STATS, l'attribut ResultSetStats de Spanner est disponible dans les réponses. ResultSetStats inclut le temps écoulé pour l'exécution de requêtes dans la base de données Spanner.
Pour capturer et visualiser la latence de ce composant, consultez Capturer la latence des requêtes avec OpenTelemetry ou avec OpenCensus.
Étapes suivantes
- Découvrez comment identifier les points de latence dans les composants Spanner.