This page describes how to export data from Spanner to CSV files or import data from CSV files into Spanner GoogleSQL-dialect databases or PostgreSQL-dialect databases.
- If you want to import a Spanner database that you previously exported to Avro files in Cloud Storage, see Import Spanner Avro files.
- If you want to import Avro files from a non-Spanner database, see Import data from non-Spanner databases.
The process uses Dataflow. You can export data from Spanner to a Cloud Storage bucket, or you can import data into Spanner from a Cloud Storage bucket that contains a JSON manifest file and a set of CSV files.
Before you begin
To import or export a Spanner database, first you need to enable the Spanner, Cloud Storage, Compute Engine, and Dataflow APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
You also need enough quota and the required IAM permissions.
Quota requirements
The quota requirements for import or export jobs are as follows:
- Spanner: You must have enough compute capacity to support the amount of data that you are importing. No additional compute capacity is required to import or export a database, though you might need to add more compute capacity so that your job finishes in a reasonable amount of time. See Optimize jobs for more details.
- Cloud Storage: To import, you must have a bucket containing your previously exported files. To export, you must create a bucket for your exported files if you don't already have one. You can do this in the Google Cloud console, either through the Cloud Storage page or while creating your export through the Spanner page. You don't need to set a size for your bucket.
- Dataflow: Import or export jobs are subject to the same CPU, disk usage, and IP address Compute Engine quotas as other Dataflow jobs.
Compute Engine: Before running your import or export job, you must set up initial quotas for Compute Engine, which Dataflow uses. These quotas represent the maximum number of resources that you allow Dataflow to use for your job. Recommended starting values are:
- CPUs: 200
- In-use IP addresses: 200
- Standard persistent disk: 50 TB
Generally, you don't have to make any other adjustments. Dataflow provides autoscaling so that you only pay for the actual resources used during the import or export. If your job can make use of more resources, the Dataflow UI displays a warning icon. The job should finish even if there is a warning icon.
Required roles
To get the permissions that you need to export a database, ask your administrator to grant you the following IAM roles on Dataflow worker service account:
-
Cloud Spanner Viewer (
roles/spanner.viewer) -
Dataflow Worker (
roles/dataflow.worker) -
Storage Admin (
roles/storage.admin) -
Spanner Database Reader (
roles/spanner.databaseReader) -
Database Admin (
roles/spanner.databaseAdmin)
Export Spanner data to CSV files
To export data from Spanner to CSV files in Cloud Storage, follow the instructions for using the Google Cloud CLI to run a job with the Spanner to Cloud Storage Text template.
You can also refer to the information in this page about optimizing slow jobs, and factors affecting job performance.
Import data from CSV files into Spanner
The process to import data from CSV files includes the following steps:
- Export your data to CSV files and store those files in Cloud Storage. Don't include a header line.
- Create a JSON manifest file and store the file along with your CSV files.
- Create empty target tables in your Spanner database or ensure that the data types for columns in your CSV files match any corresponding columns in your existing tables.
- Run your import job.
Step 1: Export data from a non-Spanner database to CSV files
The import process brings data in from CSV files located in a Cloud Storage bucket. You can export data in CSV format from any source.
Keep the following things in mind when exporting your data:
- Text files to be imported must be in CSV format.
Data must match one of the following types:
GoogleSQL
BOOL INT64 FLOAT64 NUMERIC STRING DATE TIMESTAMP BYTES JSON
PostgreSQL
boolean bigint double precision numeric character varying, text date timestamp with time zone bytea
You don't have to include or generate any metadata when you export the CSV files.
You don't have to follow any particular naming convention for your files.
If you don't export your files directly to Cloud Storage, you must upload the CSV files to a Cloud Storage bucket.
Step 2: Create a JSON manifest file
You must also create a manifest file with a JSON description of files to import
and place it in the same Cloud Storage bucket where you stored your CSV
files. This manifest file contains a tables array that lists the name and data
file locations for each table. The file also specifies the receiving database dialect.
If the dialect is omitted, it defaults to GoogleSQL.
The format of the manifest file corresponds to the following message type, shown here in protocol buffer format:
message ImportManifest {
// The per-table import manifest.
message TableManifest {
// Required. The name of the destination table.
string table_name = 1;
// Required. The CSV files to import. This value can be either a filepath or a glob pattern.
repeated string file_patterns = 2;
// The schema for a table column.
message Column {
// Required for each Column that you specify. The name of the column in the
// destination table.
string column_name = 1;
// Required for each Column that you specify. The type of the column.
string type_name = 2;
}
// Optional. The schema for the table columns.
repeated Column columns = 3;
}
// Required. The TableManifest of the tables to be imported.
repeated TableManifest tables = 1;
enum ProtoDialect {
GOOGLE_STANDARD_SQL = 0;
POSTGRESQL = 1;
}
// Optional. The dialect of the receiving database. Defaults to GOOGLE_STANDARD_SQL.
ProtoDialect dialect = 2;
}
The following example shows a manifest file for importing tables called Albums and
Singers into a GoogleSQL-dialect database. The Albums table uses the column schema that the job retrieves
from the database, and the Singers table uses the schema that the manifest file
specifies:
{
"tables": [
{
"table_name": "Albums",
"file_patterns": [
"gs://bucket1/Albums_1.csv",
"gs://bucket1/Albums_2.csv"
]
},
{
"table_name": "Singers",
"file_patterns": [
"gs://bucket1/Singers*.csv"
],
"columns": [
{"column_name": "SingerId", "type_name": "INT64"},
{"column_name": "FirstName", "type_name": "STRING"},
{"column_name": "LastName", "type_name": "STRING"}
]
}
]
}Step 3: Create the table for your Spanner database
Before you run your import, you must create the target tables in your Spanner database. If the target Spanner table already has a schema, any columns specified in the manifest file must have the same data types as the corresponding columns in the target table's schema.
We recommend that you create secondary indexes, foreign keys, and change streams after you import your data into Spanner, not when you initially create the table. If your table already contains these structures, then we recommend dropping them and re-creating them after you import your data.
Step 4: Run a Dataflow import job using gcloud
To start your import job, follow the instructions for using the Google Cloud CLI to run a job with the Cloud Storage Text to Spanner template.
After you have started an import job, you can see details about the job in the Google Cloud console.
After the import job is finished, add any necessary secondary indexes, foreign keys, and change streams.
Choose a region for your import job
You might want to choose a different region based on the location of your Cloud Storage bucket. To avoid outbound data transfer charges, choose a region that matches your Cloud Storage bucket's location.
If your Cloud Storage bucket location is a region, you can take advantage of free network usage by choosing the same region for your import job, assuming that region is available.
If your Cloud Storage bucket location is a dual-region, you can take advantage of free network usage by choosing one of the two regions that make up the dual-region for your import job, assuming one of the regions is available.
- If a co-located region is not available for your import job, or if your Cloud Storage bucket location is a multi-region, outbound data transfer charges apply. Refer to Cloud Storage data transfer pricing to choose a region that incurs the lowest data transfer charges.
View or troubleshoot jobs in the Dataflow UI
After you start an import or export job, you can view details of the job, including logs, in the Dataflow section of the Google Cloud console.
View Dataflow job details
To see details for any import or export jobs that you ran within the last week, including any jobs that are running now:
- Navigate to the Database overview page for the database.
- Click the Import/Export left pane menu item. The database Import/Export page displays a list of recent jobs.
In the database Import/Export page, click the job name in the Dataflow job name column:
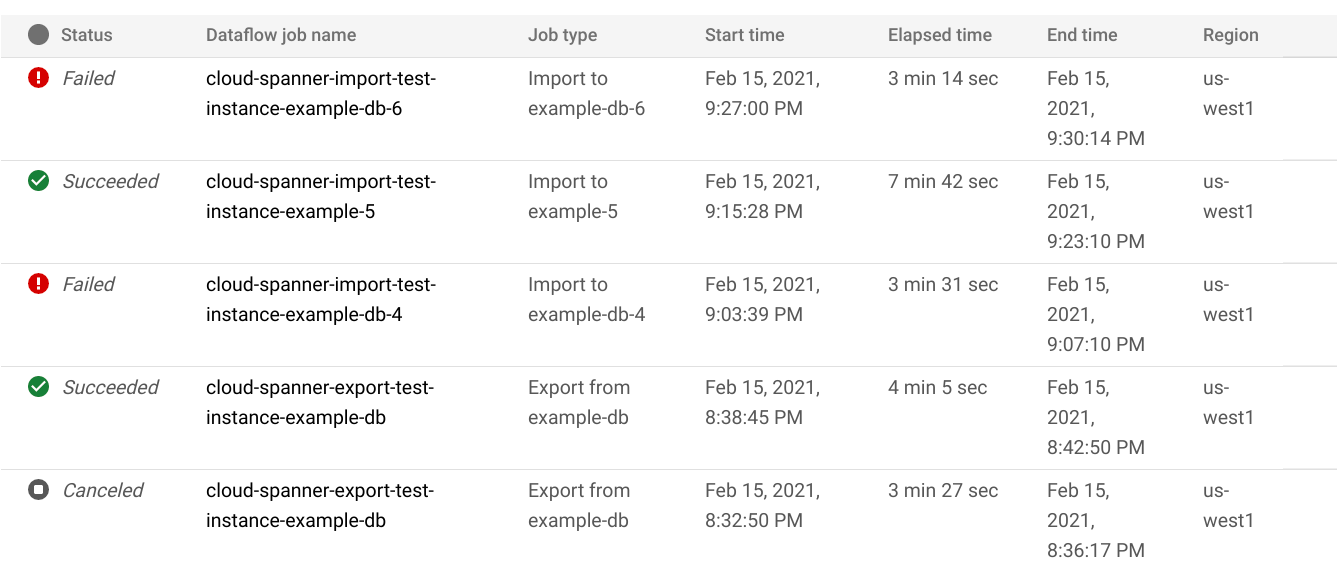
The Google Cloud console displays details of the Dataflow job.
To view a job that you ran more than one week ago:
Go to the Dataflow jobs page in the Google Cloud console.
Find your job in the list, then click its name.
The Google Cloud console displays details of the Dataflow job.
View Dataflow logs for your job
To view a Dataflow job's logs, navigate to the job's details page, then click Logs to the right of the job's name.
If a job fails, look for errors in the logs. If there are errors, the error count displays next to Logs:

To view job errors:
Click the error count next to Logs.
The Google Cloud console displays the job's logs. You may need to scroll to see the errors.
Locate entries with the error icon
 .
.Click an individual log entry to expand its contents.
For more information about troubleshooting Dataflow jobs, see Troubleshoot your pipeline.
Troubleshoot failed import or export jobs
If you see the following errors in your job logs:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Check the 99% Read/Write latency in the Monitoring tab of your Spanner database in the Google Cloud console. If it is showing high (multiple second) values, then it indicates that the instance is overloaded, causing reads/writes to timeout and fail.
One cause of high latency is that the Dataflow job is running using too many workers, putting too much load on the Spanner instance.
To specify a limit on the number of Dataflow workers:Console
If you are using the Dataflow console, the Max workers parameter is located in the Optional parameters section of the Create job from template page.
gcloud
Run the gcloud dataflow jobs run
command, and specify the max-workers argument. For example:
gcloud dataflow jobs run my-import-job \
--gcs-location='gs://dataflow-templates/latest/GCS_Text_to_Cloud_Spanner' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Troubleshoot network error
The following error might occur when you export your Spanner databases:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
This error occurs because Spanner assumes that you intend to use
an auto mode VPC network named default in the same project as the
Dataflow job. If you don't have a default VPC network in the
project, or if your VPC network is in a custom mode VPC network, then you must
create a Dataflow job and
specify an alternate network or subnetwork.
Optimize slow running import or export jobs
If you have followed the suggestions in initial settings, you should generally not have to make any other adjustments. If your job is running slowly, there are a few other optimizations you can try:
Optimize the job and data location: Run your Dataflow job in the same region where your Spanner instance and Cloud Storage bucket are located.
Ensure sufficient Dataflow resources: If the relevant Compute Engine quotas limit your Dataflow job's resources, the job's Dataflow page in the Google Cloud console displays a warning icon
 and log
messages:
and log
messages: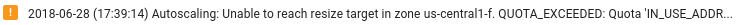
In this situation, increasing the quotas for CPUs, in-use IP addresses, and standard persistent disk might shorten the run time of the job, but you might incur more Compute Engine charges.
Check the Spanner CPU utilization: If you see that the CPU utilization for the instance is over 65%, you can increase the compute capacity in that instance. The capacity adds more Spanner resources and the job should speed up, but you incur more Spanner charges.
Factors affecting import or export job performance
Several factors influence the time it takes to complete an import or export job.
Spanner database size: Processing more data takes more time and resources.
Spanner database schema, including:
- The number of tables
- The size of the rows
- The number of secondary indexes
- The number of foreign keys
- The number of change streams
Data location: Data is transferred between Spanner and Cloud Storage using Dataflow. Ideally all three components are located in the same region. If the components are not in the same region, moving the data across regions slows the job down.
Number of Dataflow workers: Optimal Dataflow workers are necessary for good performance. By using autoscaling, Dataflow chooses the number of workers for the job depending on the amount of work that needs to be done. The number of workers will, however, be capped by the quotas for CPUs, in-use IP addresses, and standard persistent disk. The Dataflow UI displays a warning icon if it encounters quota caps. In this situation, progress is slower, but the job should still complete. Autoscaling can overload Spanner leading to errors when there is a large amount of data to import.
Existing load on Spanner: An import job adds significant CPU load on a Spanner instance. An export job typically adds a light load on a Spanner instance. If the instance already has a substantial existing load, then the job runs more slowly.
Amount of Spanner compute capacity: If the CPU utilization for the instance is over 65%, then the job runs more slowly.
Tune workers for good import performance
When starting a Spanner import job, Dataflow workers must be set to an optimal value for good performance. Too many workers overloads Spanner and too few workers results in an underwhelming import performance.
The maximum number of workers is heavily dependent on the data size, but ideally, the total Spanner CPU utilization should be between 70% to 90%. This provides a good balance between Spanner efficiency and error-free job completion.
To achieve that utilization target in the majority of schemas and scenarios, we recommend a max number of worker vCPUs between 4-6x the number of Spanner nodes.
For example, for a 10 node Spanner instance, using n1-standard-2 workers, you would set max workers to 25, giving 50 vCPUs.