Questa pagina descrive come esportare i database Spanner con la consoleGoogle Cloud .
Per esportare un database Spanner utilizzando l'API REST o Google Cloud CLI, completa i passaggi descritti nella sezione Prima di iniziare di questa pagina, quindi consulta le istruzioni dettagliate in Spanner to Cloud Storage Avro nella documentazione di Dataflow. Il processo di esportazione utilizza Dataflow e scrive i dati in una cartella di un bucket Cloud Storage. La cartella risultante contiene un insieme di file Avro e file manifest JSON.
Prima di iniziare
Per esportare un database Spanner, devi prima attivare le API Spanner, Cloud Storage, Compute Engine e Dataflow:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Devi anche disporre di una quota sufficiente e delle autorizzazioni IAM richieste.
Requisiti di quota
I requisiti di quota per i job di esportazione sono i seguenti:
- Spanner: non è necessaria capacità di calcolo aggiuntiva per esportare un database, anche se potrebbe essere necessario aggiungerne altra per consentire al job di terminare in un periodo di tempo ragionevole. Per ulteriori dettagli, consulta la sezione Ottimizzare i job.
- Cloud Storage: per l'esportazione, devi creare un bucket per i file esportati se non ne hai già uno. Puoi farlo nella console Google Cloud , tramite la pagina Cloud Storage o durante la creazione dell'esportazione tramite la pagina Spanner. Non devi impostare una dimensione per il bucket.
- Dataflow: i job di esportazione sono soggetti alle stesse quote di CPU, utilizzo del disco e indirizzo IP di Compute Engine degli altri job Dataflow.
Compute Engine: prima di eseguire il job di esportazione, devi configurare le quote iniziali per Compute Engine, che viene utilizzato da Dataflow. Queste quote rappresentano il numero massimo di risorse che consenti a Dataflow di utilizzare per il tuo job. I valori iniziali consigliati sono:
- CPU: 200
- Indirizzi IP in uso: 200
- Disco permanente standard: 50 TB
In genere, non devi apportare altre modifiche. Dataflow fornisce la scalabilità automatica in modo da pagare solo le risorse effettivamente utilizzate durante l'esportazione. Se il tuo job può utilizzare più risorse, l'interfaccia utente di Dataflow mostra un'icona di avviso. Il job deve terminare anche se è presente un'icona di avviso.
Ruoli obbligatori
Per ottenere le autorizzazioni necessarie per esportare un database, chiedi all'amministratore di concederti i seguenti ruoli IAM sul account di servizio worker Dataflow:
-
Visualizzatore Cloud Spanner (
roles/spanner.viewer) -
Dataflow Worker (
roles/dataflow.worker) -
Amministratore spazio di archiviazione (
roles/storage.admin) -
Lettore database Spanner (
roles/spanner.databaseReader) -
Database Admin (
roles/spanner.databaseAdmin)
Per utilizzare le risorse di computing indipendenti di Spanner Data Boost durante un'esportazione,
devi disporre anche dell'autorizzazione IAM spanner.databases.useDataBoost. Per maggiori informazioni, consulta la panoramica di Data Boost.
Esportare un database
Dopo aver soddisfatto i requisiti di quota e IAM descritti in precedenza, puoi esportare un database Spanner esistente.
Per esportare il database Spanner in un bucket Cloud Storage:
Vai alla pagina Istanze di Spanner.
Fai clic sul nome dell'istanza che contiene il database.
Fai clic sulla voce di menu Importa/Esporta nel riquadro a sinistra e poi sul pulsante Esporta.
Nella sezione Scegli dove archiviare l'esportazione, fai clic su Sfoglia.
Se non hai già un bucket Cloud Storage per l'esportazione:
- Fai clic su Nuovo bucket
 .
. - Inserisci un nome per il bucket. I nomi dei bucket devono essere univoci in Cloud Storage.
- Seleziona una classe di archiviazione e una posizione predefinite, quindi fai clic su Crea.
- Fai clic sul bucket per selezionarlo.
Se hai già un bucket, selezionalo dall'elenco iniziale o fai clic su Cerca
 per filtrare l'elenco, poi fai clic sul bucket per selezionarlo.
per filtrare l'elenco, poi fai clic sul bucket per selezionarlo.- Fai clic su Nuovo bucket
Fai clic su Seleziona.
Seleziona il database che vuoi esportare nel menu a discesa Scegli un database da esportare.
(Facoltativo) Per esportare il database da un point-in-time precedente, seleziona la casella e inserisci un timestamp.
Seleziona una regione nel menu a discesa Scegli una regione per il job di esportazione.
(Facoltativo) Per criptare lo stato della pipeline Dataflow con una chiave di crittografia gestita dal cliente:
- Fai clic su Mostra opzioni di crittografia.
- Seleziona Utilizza una chiave di crittografia gestita dal cliente (CMEK).
- Seleziona la chiave dall'elenco a discesa.
Questa opzione non influisce sulla crittografia a livello di bucket Cloud Storage di destinazione. Per abilitare CMEK per il bucket Cloud Storage, consulta Utilizzare CMEK con Cloud Storage.
(Facoltativo) Per esportare utilizzando Spanner Data Boost, seleziona la casella di controllo Utilizza Spanner Data Boost. Per maggiori informazioni, consulta la panoramica di Data Boost.
Seleziona la casella di controllo in Conferma addebiti per confermare che sono presenti addebiti aggiuntivi rispetto a quelli sostenuti dalla tua istanza Spanner esistente.
Fai clic su Esporta.
La console Google Cloud mostra la pagina Importazione/Esportazione database, che ora mostra una voce per il job di esportazione nell'elenco Importazione/Esportazione job, incluso il tempo trascorso del job:
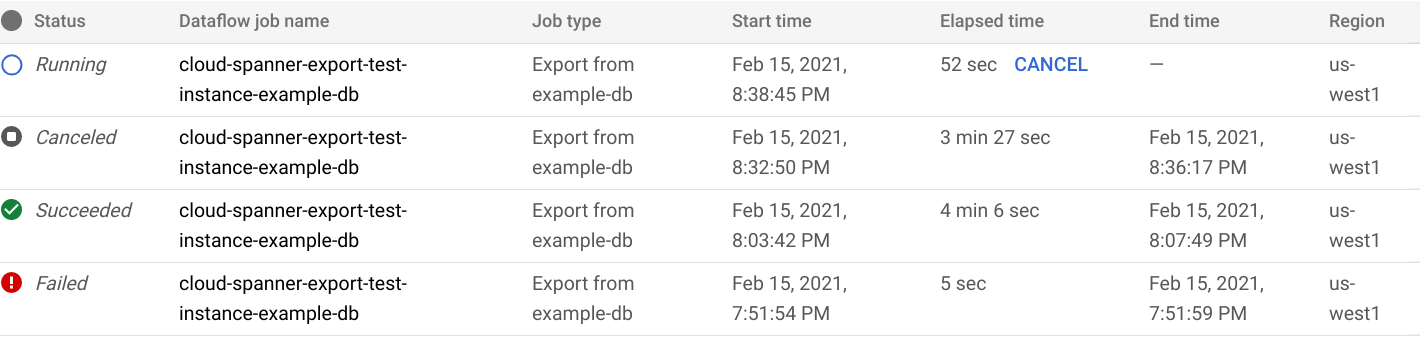
Al termine o all'interruzione del job, lo stato viene aggiornato nell'elenco Importa/Esporta. Se il job è stato completato correttamente, viene visualizzato lo stato Riuscito:

Se il job non è andato a buon fine, viene visualizzato lo stato Non riuscito:

Per visualizzare i dettagli dell'operazione Dataflow per il tuo job, fai clic sul nome del job nella colonna Nome job Dataflow.
Se il job non va a buon fine, controlla i log di Dataflow del job per visualizzare i dettagli dell'errore.
Per evitare addebiti per Cloud Storage per i file creati dal job di esportazione non riuscito, elimina la cartella e i relativi file. Per informazioni su come trovare la cartella, vedi Visualizzare l'esportazione.
Nota sull'esportazione di colonne generate e modifiche in tempo reale
I valori di una colonna generata archiviata non vengono esportati. La definizione della colonna viene esportata nello schema Avro come campo di record di tipo null, con la definizione della colonna come proprietà personalizzate del campo. Finché non viene completata l'operazione di backfill di una colonna generata appena aggiunta, la colonna generata viene ignorata come se non esistesse nello schema.
I flussi di modifiche esportati come file Avro contengono solo lo schema dei modifiche in tempo reale e non i record di modifica dei dati.
Una nota sull'esportazione delle sequenze
Le sequenze (GoogleSQL,
PostgreSQL) sono oggetti schema che utilizzi per generare valori interi univoci.
Spanner esporta ciascun oggetto schema nello schema Avro come
campo record, con il tipo di sequenza, l'intervallo ignorato e il contatore come proprietà
del campo. Tieni presente che, per impedire il ripristino di una sequenza e la generazione di valori duplicati dopo l'importazione, durante l'esportazione dello schema, la funzione GET_INTERNAL_SEQUENCE_STATE() (GoogleSQL, PostgreSQL) acquisisce il contatore della sequenza. Spanner aggiunge un buffer di
1000 al contatore e scrive il nuovo valore del contatore nel campo del record. Questo
approccio evita errori di valori duplicati che potrebbero verificarsi dopo l'importazione.
Se vengono eseguite più scritture nel database di origine durante l'esportazione dei dati, devi
modificare il contatore di sequenza effettivo utilizzando l'istruzione ALTER SEQUENCE
(GoogleSQL,
PostgreSQL).
Al momento dell'importazione, la sequenza inizia da questo nuovo contatore anziché da quello
trovato nello schema. In alternativa, puoi utilizzare l'istruzione ALTER SEQUENCE
(GoogleSQL,
PostgreSQL)
per aggiornare la sequenza con un nuovo contatore.
Visualizzare l'esportazione in Cloud Storage
Per visualizzare la cartella che contiene il database esportato nella consoleGoogle Cloud , vai al browser Cloud Storage e scegli il bucket selezionato in precedenza:
Vai al browser di archiviazione
Il bucket ora contiene una cartella con il database esportato. Il nome della cartella inizia con l'ID dell'istanza, il nome del database e il timestamp del job di esportazione. La cartella contiene:
- Un file
spanner-export.json - Un file
TableName-manifest.jsonper ogni tabella nel database che hai esportato. Uno o più file
TableName.avro-#####-of-#####. Il primo numero nell'estensione.avro-#####-of-#####rappresenta l'indice del file Avro, a partire da zero, mentre il secondo rappresenta il numero di file Avro generati per ogni tabella.Ad esempio,
Songs.avro-00001-of-00002è il secondo di due file che contengono i dati per la tabellaSongs.Un file
ChangeStreamName-manifest.jsonper ogni stream di modifiche nel database che hai esportato.Un file
ChangeStreamName.avro-00000-of-00001per ogni stream di modifiche. Questo file contiene dati vuoti con solo lo schema Avro dello stream di modifiche.
Scegli una regione per il job di importazione
Potresti voler scegliere un'altra regione in base alla posizione del tuo bucket Cloud Storage. Per evitare addebiti per il trasferimento di dati in uscita, scegli una regione che corrisponda alla località del bucket Cloud Storage.
Se la posizione del bucket Cloud Storage è una regione, puoi usufruire dell'utilizzo gratuito della rete scegliendo la stessa regione per il job di importazione, se disponibile.
Se la posizione del bucket Cloud Storage è una doppia regione, puoi usufruire dell'utilizzo gratuito della rete scegliendo una delle due regioni che compongono la doppia regione per il job di importazione, supponendo che una delle regioni sia disponibile.
- Se una regione colocalizzata non è disponibile per il tuo job di importazione o se la località del bucket Cloud Storage è una multiregione, si applicano addebiti per il trasferimento di dati in uscita. Consulta i prezzi del trasferimento di dati di Cloud Storage per scegliere una regione che comporti gli addebiti per il trasferimento di dati più bassi.
Esportare un sottoinsieme di tabelle
Se vuoi esportare solo i dati di determinate tabelle e non l'intero database, puoi specificare queste tabelle durante l'esportazione. In questo caso, Spanner esporta l'intero schema del database, inclusi i dati delle tabelle specificate, lasciando tutte le altre tabelle presenti ma vuote nel file esportato.
Puoi specificare un sottoinsieme di tabelle da esportare utilizzando la pagina Dataflow nella console Google Cloud o gcloud CLI. (La pagina Spanner non fornisce questa azione.)
Se esporti i dati di una tabella figlio di un'altra tabella, devi esportare anche i dati della tabella padre. Se i genitori non vengono esportati, il job di esportazione non riesce.
Per esportare un sottoinsieme di tabelle, avvia l'esportazione utilizzando il modello da Spanner ad Avro di Cloud Storage e specifica le tabelle utilizzando la pagina Dataflow nella console Google Cloud o gcloud CLI, come descritto:
Console
Se utilizzi la pagina Dataflow nella console Google Cloud , il parametro Nome o nomi della tabella Cloud Spanner si trova nella sezione Parametri facoltativi della pagina Crea job dal modello. È possibile specificare più tabelle in un formato separato da virgole.
gcloud
Esegui il comando gcloud dataflow jobs run e specifica l'argomento tableNames. Ad esempio:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=table1,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
La specifica di più tabelle in gcloud richiede l'escape degli argomenti di tipo dizionario.
L'esempio seguente utilizza "|" come carattere di escape:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='^|^instanceId=test-instance|databaseId=example-db|tableNames=table1,table2|outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Il parametro shouldExportRelatedTables è un'opzione pratica per
esportare automaticamente tutte le tabelle principali
delle tabelle scelte. Ad esempio, in questa gerarchia dello schema
con le tabelle Singers, Albums e Songs, devi specificare solo
Songs. L'opzione shouldExportRelatedTables esporterà anche Singers
e Albums perché Songs è un discendente di entrambi.
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=Songs,shouldExportRelatedTables=true,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Visualizzare o risolvere i problemi relativi ai job nell'interfaccia utente di Dataflow
Dopo aver avviato un job di esportazione, puoi visualizzare i dettagli del job, inclusi i log, nella sezione Dataflow della console Google Cloud .
Visualizza i dettagli del job Dataflow
Per visualizzare i dettagli di tutti i job di importazione o esportazione eseguiti nell'ultima settimana, inclusi quelli in esecuzione:
- Vai alla pagina Panoramica del database per il database.
- Fai clic sulla voce di menu Importa/Esporta nel riquadro a sinistra. La pagina Importa/Esporta del database mostra un elenco dei job recenti.
Nella pagina Importa/Esporta del database, fai clic sul nome del job nella colonna Nome job Dataflow:
La console Google Cloud mostra i dettagli del job Dataflow.
Per visualizzare un job eseguito più di una settimana fa:
Vai alla pagina Job Dataflow nella console Google Cloud .
Trova il tuo lavoro nell'elenco e fai clic sul suo nome.
La console Google Cloud mostra i dettagli del job Dataflow.
Visualizzare i log Dataflow per il job
Per visualizzare i log di un job Dataflow, vai alla pagina dei dettagli del job, quindi fai clic su Log a destra del nome del job.
Se un job non va a buon fine, cerca gli errori nei log. Se si verificano errori, il conteggio degli errori viene visualizzato accanto a Log:

Per visualizzare gli errori del job:
Fai clic sul conteggio degli errori accanto a Log.
La console Google Cloud mostra i log del job. Potresti dover scorrere per visualizzare gli errori.
Individua le voci con l'icona di errore
 .
.Fai clic su una singola voce di log per espandere i relativi contenuti.
Per saperne di più sulla risoluzione dei problemi relativi ai job Dataflow, vedi Risolvere i problemi della pipeline.
Risolvere i problemi relativi ai job di esportazione non riusciti
Se visualizzi i seguenti errori nei log dei job:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Controlla la latenza di lettura del 99% nella scheda Monitoraggio del tuo database Spanner nella consoleGoogle Cloud . Se mostra valori elevati (più secondi), significa che l'istanza è sovraccarica, causando timeout e errori di lettura.
Una delle cause dell'elevata latenza è che il job Dataflow viene eseguito utilizzando troppi worker, il che comporta un carico eccessivo sull'istanza Spanner.
Per specificare un limite al numero di worker Dataflow, anziché utilizzare la scheda Importa/Esporta nella pagina dei dettagli dell'istanza del database Spanner nella console Google Cloud , devi avviare l'esportazione utilizzando il modello Spanner to Cloud Storage Avro e specificare il numero massimo di worker come descritto di seguito:Console
Se utilizzi la console Dataflow, il parametro Numero massimo di worker si trova nella sezione Parametri facoltativi della pagina Crea job da modello.
gcloud
Esegui il comando gcloud dataflow jobs run
e specifica l'argomento max-workers. Ad esempio:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Risolvere l'errore di rete
Quando esporti i database Spanner, potrebbe verificarsi il seguente errore:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
Questo errore si verifica perché Spanner presuppone che tu voglia utilizzare
una rete VPC in modalità automatica denominata default nello stesso progetto del
job Dataflow. Se non hai una rete VPC predefinita nel progetto o se la tua rete VPC è in modalità personalizzata, devi creare un job Dataflow e specificare una rete o una subnet alternativa.
Ottimizzare i job di esportazione a esecuzione lenta
Se hai seguito i suggerimenti nelle impostazioni iniziali, in genere non dovresti apportare altre modifiche. Se il job viene eseguito lentamente, puoi provare alcune altre ottimizzazioni:
Ottimizza la posizione del job e dei dati: esegui il job Dataflow nella stessa regione in cui si trovano l'istanza Spanner e il bucket Cloud Storage.
Assicurati che le risorse Dataflow siano sufficienti: se le quote di Compute Engine pertinenti limitano le risorse del job Dataflow, la pagina Dataflow nella console Google Cloud mostra un'icona di avviso
 e messaggi
di log:
e messaggi
di log: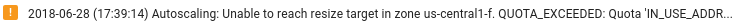
In questa situazione, aumentare le quote per CPU, indirizzi IP in uso e disco permanente standard potrebbe ridurre il tempo di esecuzione del job, ma potresti incorrere in costi maggiori di Compute Engine.
Controlla l'utilizzo della CPU di Spanner: se noti che l'utilizzo della CPU per l'istanza è superiore al 65%, puoi aumentare la capacità di calcolo in quell'istanza. La capacità aggiunge più risorse Spanner e il job dovrebbe accelerare, ma si verificano più addebiti Spanner.
Fattori che influiscono sul rendimento del job di esportazione
Diversi fattori influiscono sul tempo necessario per completare un job di esportazione.
Dimensioni del database Spanner: l'elaborazione di più dati richiede più tempo e risorse.
Schema del database Spanner, tra cui:
- Il numero di tavoli
- La dimensione delle righe
- Numero di indici secondari
- Il numero di chiavi esterne
- Numero di modifiche in tempo reale
Posizione dei dati: i dati vengono trasferiti tra Spanner e Cloud Storage utilizzando Dataflow. Idealmente, tutti e tre i componenti si trovano nella stessa regione. Se i componenti non si trovano nella stessa regione, lo spostamento dei dati tra le regioni rallenta il job.
Numero di worker Dataflow: per ottenere buone prestazioni sono necessari worker Dataflow ottimali. Utilizzando la scalabilità automatica, Dataflow sceglie il numero di worker per il job in base alla quantità di lavoro da svolgere. Il numero di worker sarà comunque limitato dalle quote per CPU, indirizzi IP in uso e disco permanente standard. L'interfaccia utente Dataflow mostra un'icona di avviso se rileva limiti di quota. In questa situazione, l'avanzamento è più lento, ma il lavoro dovrebbe comunque essere completato.
Carico esistente su Spanner: un job di esportazione in genere aggiunge un carico leggero a un'istanza Spanner. Se l'istanza ha già un carico esistente sostanziale, il job viene eseguito più lentamente.
Quantità di capacità di calcolo di Spanner: se l'utilizzo della CPU per l'istanza è superiore al 65%, il job viene eseguito più lentamente.