Spanner Data Boost ist ein vollständig verwalteter, serverloser Dienst, der unabhängige Rechenressourcen für unterstützte Spanner-Arbeitslasten bereitstellt. Mit Data Boost können Sie Analyseabfragen und Datenexporte nahezu ohne Auswirkungen auf vorhandene Arbeitslasten auf der bereitgestellten Spanner-Instanz ausführen. Der Dienst besteht aus Spanner-Clustern, die von Google auf regionaler Ebene verwaltet werden. Bei geeigneten Abfragen, für die Data Boost angefordert wird, leitet Spanner die Arbeitslast transparent an diese Server weiter. Geeignete Abfragen sind solche, bei denen der erste Operator im Abfrageausführungsplan eine verteilte Union ist. Diese Abfragen müssen nicht geändert werden, um Data Boost zu nutzen.
Data Boost ist am wirkungsvollsten in den folgenden Fällen, in denen Sie negative Auswirkungen auf das vorhandene Transaktionssystem aufgrund von Ressourcenkonflikten vermeiden möchten:
- Ad-hoc- oder seltene Abfragen, bei denen große Datenmengen verarbeitet werden. Ein typisches Beispiel ist eine föderierte Abfrage von BigQuery nach Spanner.
- Jobs für Berichte oder Datenexporte Ein Beispiel ist ein Dataflow-Job zum Exportieren von Spanner-Daten in Cloud Storage.
Das folgende Diagramm zeigt, wie Data Boost mit der Spanner-Instanz koordiniert wird, um unabhängige Rechenressourcen bereitzustellen.
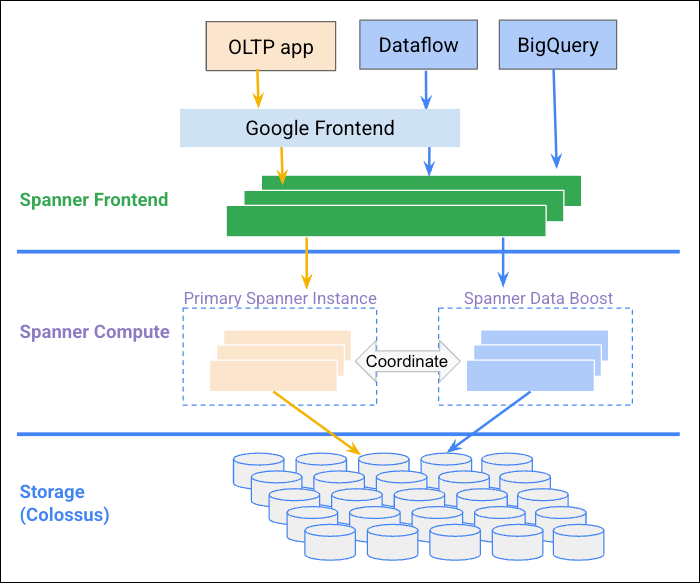
Vorteile
Data Boost bietet folgende Vorteile:
- Bietet Arbeitslastisolierung. Sie können unterstützte Abfragen auf die neuesten Daten ausführen, ohne dass sich dies auf vorhandene transaktionale Arbeitslasten auswirkt – unabhängig von der Abfragekomplexität oder der verarbeiteten Datenmenge.
- Bietet eine gleichwertige oder bessere Latenz.
- Verhindert die Überprovisionierung von Spanner-Instanzen nur zur Unterstützung gelegentlicher Analyseabfragen.
- Bietet eine hohe Skalierbarkeit mit größerer Abfrageparallelität, die sich elastisch bei Spitzenlasten skaliert.
- Bietet umfassende Messwerte, mit denen Administratoren die teuersten Abfragen ermitteln und die zu optimierende Kostenkomponente bestimmen können. Administratoren können dann die Auswirkungen ihrer Optimierungen prüfen, indem sie den Verbrauch der serverlosen Verarbeitungseinheit der Abfrage bei der nächsten Ausführung beobachten.
- Erfordert keinen zusätzlichen Betriebsaufwand. Es muss kein zusätzlicher Dienst verwaltet werden, es gibt keine Kapazitätsplanung oder Bereitstellung, Sie müssen nicht auf die Skalierung warten und es ist keine Wartung erforderlich.
Berechtigungen
Alle Hauptkonten, die eine Abfrage oder einen Export ausführen, für die der Daten-Boost angefordert wird, benötigen die IAM-Berechtigung (Identity and Access Management) spanner.databases.useDataBoost. Wir empfehlen die IAM-Rolle Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Abrechnung und Kontingente
Sie zahlen nur für die tatsächlichen Verarbeitungseinheiten, die von Abfragen verwendet werden, die mit Data Boost ausgeführt werden. Administratoren können Limits für die Nutzung festlegen, um Kostenüberschreitungen zu vermeiden.
Nächste Schritte
- Föderierte Abfragen mit Data Boost ausführen
- Daten mit Data Boost exportieren
- Data Boost in Ihren Anwendungen verwenden
- Data Boost-Nutzung im Blick behalten
- Nutzung des Daten-Boost-Kontingents im Blick behalten und verwalten