O Data Boost do Spanner é um serviço sem servidor totalmente gerenciado que fornece recursos de computação independentes para as cargas de trabalho do Spanner compatíveis. O Data Boost permite executar consultas de análise e exportações de dados com impacto quase zero nas cargas de trabalho atuais na instância provisionada do Spanner. O serviço consiste em clusters do Spanner que o Google gerencia no nível da região. Para consultas qualificadas que solicitam o Data Boost, o Spanner encaminha a carga de trabalho para esses servidores de forma transparente. As consultas qualificadas são aquelas em que o primeiro operador no plano de execução da consulta é uma união distribuída. Essas consultas não precisam ser alteradas para aproveitar o Data Boost.
O Data Boost tem mais impacto nos seguintes cenários em que você quer evitar impactos negativos no sistema transacional atual devido à contenção de recursos:
- Consultas ad hoc ou pouco frequentes que envolvem o processamento de grandes quantidades de dados. Um exemplo típico é uma consulta federada do BigQuery para o Spanner.
- Jobs de exportação de dados ou relatórios. Um exemplo é um job do Dataflow para exportar dados do Spanner para o Cloud Storage.
O diagrama a seguir ilustra como o Data Boost se coordena com a instância do Spanner para fornecer recursos de computação independentes.
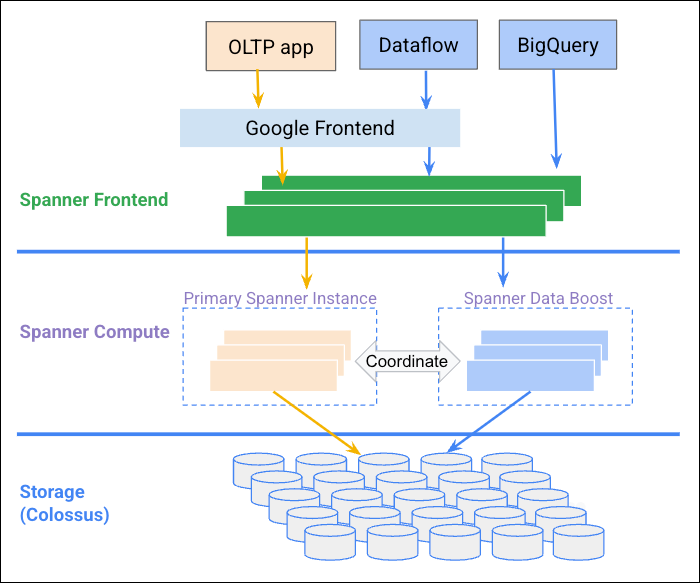
Vantagens
O Data Boost oferece os seguintes benefícios:
- Oferece isolamento da carga de trabalho. É possível executar consultas com suporte nos dados mais recentes com impacto quase zero nas cargas de trabalho transacionais atuais, independentemente da complexidade da consulta ou da quantidade de dados processados.
- Oferece latência igual ou melhor.
- Evita o provisionamento excessivo de instâncias do Spanner apenas para oferecer suporte a consultas de análise ocasionais.
- Oferece um alto grau de escalonamento com maior paralelismo de consulta que é escalonado de forma elástica com cargas de pico.
- Fornece métricas abrangentes, que permitem que os administradores identifiquem as consultas mais caras e determinem o componente de custo a ser otimizado. Os administradores podem verificar o impacto das otimizações monitorando o consumo de unidade de processamento sem servidor da consulta na próxima execução.
- Não exige overhead operacional adicional. Não há serviço extra a gerenciar, nenhum planejamento ou provisionamento de capacidade, não é necessário esperar pela escalabilidade e não há manutenção.
Permissões
Qualquer principal que execute uma consulta ou exportação que solicite o Data Boost
precisa ter a permissão spanner.databases.useDataBoost do Identity and Access Management (IAM). Recomendamos que você use o papel do IAM
Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Faturamento e cotas
Você paga apenas pelas unidades de processamento reais usadas pelas consultas executadas no Data Boost. Os administradores podem definir limites de uso para evitar custos excessivos.
A seguir
- Executar consultas federadas com o Data Boost
- Exportar dados com o Data Boost
- Usar o Data Boost nos seus aplicativos
- Monitorar o uso do Data Boost
- Monitorar e gerenciar o uso da cota do Data Boost