Spanner Data Boost è un servizio serverless completamente gestito che fornisce risorse di calcolo indipendenti per i carichi di lavoro Spanner supportati. Data Boost ti consente di eseguire query di analisi ed esportazioni di dati con un impatto quasi nullo sui carichi di lavoro esistenti nell'istanza Spanner di cui è stato eseguito il provisioning. Il servizio è costituito da cluster Spanner gestiti da Google a livello di regione. Per le query idonee che richiedi Data Boost, Spanner inoltra il carico di lavoro a questi server in modo trasparente. Le query idonee sono quelle per le quali il primo operatore nel piano di esecuzione della query è un'unione distribuita. Per usufruire di Data Boost, queste query non devono essere modificate.
Data Boost ha il maggiore impatto nei seguenti scenari in cui vuoi evitare impatti negativi sul sistema transazionale esistente a causa della concorrenza delle risorse:
- Query ad hoc o infrequenti che richiedono l'elaborazione di grandi quantità di dati. Un esempio tipico è una query federata da BigQuery a Spanner.
- Job di generazione di report o esportazione di dati. Un esempio è un job Dataflow per esportare i dati di Spanner in Cloud Storage.
Il seguente diagramma illustra come Data Boost si coordina con l'istanza Spanner per fornire risorse di calcolo indipendenti.
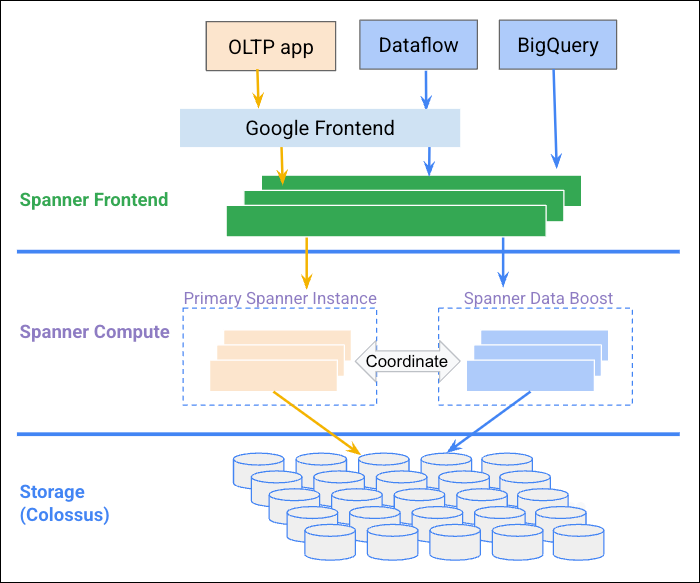
Vantaggi
Data Boost offre i seguenti vantaggi:
- Fornisce isolamento del carico di lavoro. Puoi eseguire query supportate sui dati più recenti con un impatto quasi nullo sui carichi di lavoro transazionali esistenti indipendentemente dalla complessità delle query o dalla quantità di dati elaborati.
- Offre una latenza uguale o migliore.
- Impedisce il provisioning eccessivo di istanze Spanner solo per supportare query di analisi occasionali.
- Offre un elevato grado di scalabilità con un maggiore parallelismo delle query che si adatta in modo elastico ai picchi di carico.
- Fornisce metriche complete che consentono agli amministratori di identificare le query più costose e di determinare il componente di costo da ottimizzare. Gli amministratori possono quindi verificare l'impatto delle ottimizzazioni monitorando il consumo delle unità di elaborazione serverless della query nella successiva esecuzione.
- Non richiede alcun sovraccarico operativo aggiuntivo. Non è necessario gestire alcun servizio aggiuntivo, né eseguire la pianificazione delle capacità o il provisioning, né attendere la scalabilità e non è necessaria alcuna manutenzione.
Autorizzazioni
Qualsiasi entità che esegue una query o un'esportazione che richiede il potenziamento dei dati deve disporre dell'autorizzazione spanner.databases.useDataBoostGestione di identità e accessi (IAM). Ti consigliamo di utilizzare il ruolo IAM
Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Fatturazione e quote
Paghi solo per le unità di elaborazione effettive utilizzate dalle query eseguite su Data Boost. Gli amministratori possono impostare limiti di utilizzo per evitare costi eccessivi.
Passaggi successivi
- Eseguire query federate con Data Boost
- Esportare i dati con Data Boost
- Utilizzare Data Boost nelle applicazioni
- Monitorare l'utilizzo di Data Boost
- Monitorare e gestire l'utilizzo della quota di Data Boost