Spanner Data Boost es un servicio sin servidores y completamente administrado que proporciona recursos de procesamiento independientes para las cargas de trabajo de Spanner compatibles. Data Boost te permite ejecutar consultas de estadísticas y exportaciones de datos con un impacto casi nulo en las cargas de trabajo existentes de la instancia de Spanner aprovisionada. El servicio consta de clústeres de Spanner que Google administra a nivel de la región. En el caso de las consultas aptas que solicitan Data Boost, Spanner enruta la carga de trabajo a estos servidores de forma transparente. Las consultas aptas son aquellas para las que el primer operador del plan de ejecución de consultas es una unión distribuida. Estas consultas no tienen que cambiar para aprovechar la función Data Boost.
Data Boost tiene un mayor impacto en las siguientes situaciones en las que deseas evitar impactos negativos en el sistema transaccional existente debido a la contención de recursos:
- Consultas ad hoc o poco frecuentes que implican el procesamiento de grandes cantidades de datos. Un ejemplo típico es una consulta federada de BigQuery a Spanner.
- Tareas de informes o exportación de datos Un ejemplo es un trabajo de Dataflow para exportar datos de Spanner a Cloud Storage.
En el siguiente diagrama, se ilustra cómo Data Boost se coordina con la instancia de Spanner para proporcionar recursos de procesamiento independientes.
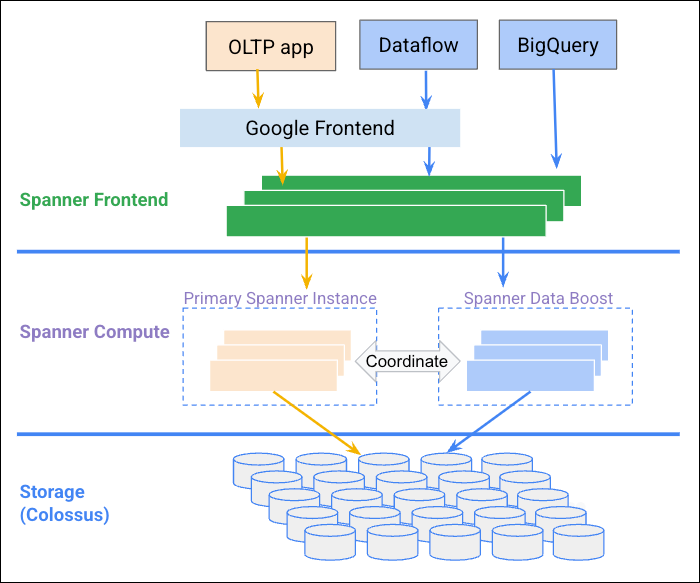
Beneficios
Data Boost ofrece los siguientes beneficios:
- Proporciona aislamiento de la carga de trabajo. Puedes ejecutar consultas compatibles con los datos más recientes con un impacto casi nulo en las cargas de trabajo transaccionales existentes, independientemente de la complejidad de la consulta o la cantidad de datos procesados.
- Proporciona una latencia igual o mejor.
- Evita el aprovisionamiento excesivo de instancias de Spanner solo para admitir consultas de estadísticas ocasionales.
- Ofrece un alto grado de escalabilidad con mayor paralelismo de consultas que se escala de forma elástica con cargas de ráfagas.
- Proporciona métricas integrales, que permiten a los administradores identificar las consultas más costosas y determinar el componente de costo que se debe optimizar. Luego, los administradores pueden verificar el impacto de sus optimizaciones supervisando el consumo de la unidad de procesamiento sin servidores de la consulta en su próxima ejecución.
- No requiere sobrecarga operativa adicional. No hay ningún servicio adicional para administrar, ni planificación ni aprovisionamiento de capacidad, ni necesidad de esperar a la escalabilidad ni mantenimiento.
Permisos
Cualquier principal que ejecute una consulta o exportación que solicite el aumento de datos debe tener el permiso de Identity and Access Management (IAM) spanner.databases.useDataBoost. Te recomendamos que uses el rol de IAM Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Facturación y cuotas
Solo pagas por las unidades de procesamiento reales que usan las consultas que se ejecutan en Data Boost. Los administradores pueden establecer límites de uso para evitar sobrecostos.
¿Qué sigue?
- Ejecuta consultas federadas con Data Boost
- Cómo exportar datos con Data Boost
- Cómo usar Data Boost en tus aplicaciones
- Supervisa el uso de Data Boost
- Supervisa y administra el uso de la cuota de Data Boost