Spanner Data Boost est un service sans serveur entièrement géré qui fournit des ressources de calcul indépendantes pour les charges de travail Spanner compatibles. Data Boost vous permet d'exécuter des requêtes d'analyse et des exportations de données avec un impact quasiment nul sur les charges de travail existantes sur l'instance Spanner provisionnée. Le service se compose de clusters Spanner gérés par Google au niveau régional. Pour les requêtes éligibles qui demandent Data Boost, Spanner achemine de manière transparente la charge de travail vers ces serveurs. Les requêtes éligibles sont celles pour lesquelles le premier opérateur du plan d'exécution de la requête est une union distribuée. Ces requêtes ne doivent pas être modifiées pour profiter de Data Boost.
Data Boost est le plus efficace dans les scénarios suivants, où vous souhaitez éviter les impacts négatifs sur le système transactionnel existant en raison d'un conflit de ressources:
- Requêtes ad hoc ou peu fréquentes impliquant le traitement de grandes quantités de données Un exemple typique est une requête fédérée de BigQuery vers Spanner.
- Tâches de création de rapports ou d'exportation de données Par exemple, une tâche Dataflow pour exporter des données Spanner vers Cloud Storage.
Le schéma suivant illustre comment Data Boost se coordonne avec l'instance Spanner pour fournir des ressources de calcul indépendantes.
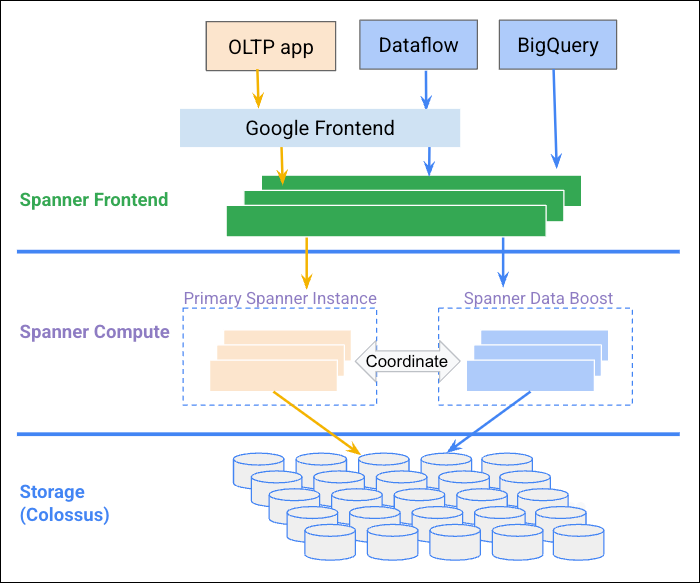
Avantages
Data Boost offre les avantages suivants:
- Fournit une isolation des charges de travail. Vous pouvez exécuter des requêtes compatibles sur les dernières données avec un impact quasi nul sur les charges de travail transactionnelles existantes, quelle que soit la complexité de la requête ou la quantité de données traitées.
- Fournit une latence égale ou meilleure.
- Empêche le surprovisionnement d'instances Spanner uniquement pour prendre en charge des requêtes d'analyse occasionnelles.
- Offre un haut niveau d'évolutivité avec un parallélisme de requêtes plus important qui s'adapte de manière élastique aux charges par rafales.
- Fournit des métriques complètes qui permettent aux administrateurs d'identifier les requêtes les plus coûteuses et de déterminer le composant de coût à optimiser. Les administrateurs peuvent ensuite vérifier l'impact de leurs optimisations en surveillant la consommation de l'unité de traitement sans serveur de la requête lors de son prochain exécution.
- Ne nécessite aucun frais de fonctionnement supplémentaires. Il n'y a pas de service supplémentaire à gérer, pas de planification ni de provisionnement des capacités, pas besoin d'attendre la mise à l'échelle et pas de maintenance.
Autorisations
Tout compte principal qui exécute une requête ou une exportation qui demande l'option Data Boost doit disposer de l'autorisation IAM (Identity and Access Management) spanner.databases.useDataBoost. Nous vous recommandons d'utiliser le rôle IAM Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Facturation et quotas
Vous ne payez que pour les unités de traitement réelles utilisées par les requêtes exécutées sur Data Boost. Les administrateurs peuvent définir des limites d'utilisation pour éviter les dépassements de coûts.
Étape suivante
- Exécuter des requêtes fédérées avec Data Boost
- Exporter des données avec Data Boost
- Utiliser Data Boost dans vos applications
- Surveiller l'utilisation de Data Boost
- Surveiller et gérer l'utilisation du quota de Data Boost