Esta página descreve como criar e gerir bases de dados do Spanner:
- Vários métodos para criar uma base de dados
- Modifique as opções da base de dados
- Elimine uma base de dados
Esta página tem informações para bases de dados com dialeto GoogleSQL e bases de dados com dialeto PostgreSQL. Para saber como atualizar um esquema da base de dados, consulte o artigo Faça atualizações do esquema. Para mais informações sobre como criar uma instância, consulte o artigo Crie e faça a gestão de instâncias. Pode criar uma base de dados numa instância existente de qualquer uma das seguintes formas:
- Criar uma base de dados: pode criar uma nova base de dados selecionando o dialeto SQL e definindo o seu esquema.
- Importe os seus próprios dados: pode importar um ficheiro CSV, de despejo do MySQL ou de despejo do PostgreSQL para uma base de dados nova ou existente.
- Criar uma base de dados com dados de amostra: pode preencher uma base de dados com um dos conjuntos de dados de amostra disponíveis para experimentar as capacidades do Spanner.
Crie uma base de dados
Pode criar uma nova base de dados numa instância existente. Para bases de dados com dialeto GoogleSQL, pode definir o esquema da base de dados no momento da criação da base de dados ou após a criação da mesma. Para bases de dados com dialeto PostgreSQL, tem de definir o esquema após a criação.
Os esquemas são definidos através da linguagem de definição de base de dados, que está documentada para GoogleSQL e PostgreSQL. Consulte os seguintes links para mais informações sobre como criar e atualizar esquemas:
Depois de criar a base de dados, pode proteger as bases de dados importantes para as suas aplicações e serviços ativando a proteção contra eliminação de bases de dados. Para mais informações, consulte o artigo Impeça a eliminação acidental de bases de dados.
Google Cloud consola
Na Google Cloud consola, aceda à página Instâncias do Spanner.
Selecione a instância na qual quer criar a base de dados.
Clique em Criar base de dados.
Introduza os seguintes valores:
- Um nome da base de dados a apresentar na Google Cloud consola.
- O dialeto a usar para esta base de dados.
- Para bases de dados com dialeto GoogleSQL, forneça opcionalmente um conjunto de declarações DDL que definam o seu esquema. Use os modelos DDL para pré-preencher elementos comuns. Se existirem erros nas suas declarações DDL, a consola devolve um erro quando tenta criar a base de dados. Google Cloud
- Opcionalmente, selecione uma chave de encriptação gerida pelo cliente para usar nesta base de dados.
Clique em Criar para criar a base de dados.
gcloud
Use o comando gcloud spanner databases create.
```sh
gcloud spanner databases create DATABASE \
--instance=INSTANCE \
[--async] \
[--database-dialect=DATABASE_DIALECT] \
[--ddl=DDL] \
[--ddl-file=DDL_FILE] \
[--kms-key=KMS_KEY : --kms-keyring=KMS_KEYRING --kms-location=KMS_LOCATION --kms-project=KMS_PROJECT] \
[GCLOUD_WIDE_FLAG …]
```
As seguintes opções são obrigatórias:
DATABASE- ID da base de dados ou identificador totalmente qualificado da base de dados. Se especificar o identificador totalmente qualificado, pode omitir a flag
--instance. --instance=INSTANCE- A instância do Spanner para a base de dados.
As seguintes opções são opcionais:
--async- Retorne imediatamente, sem aguardar a conclusão da operação em curso.
--database-dialect=DATABASE_DIALECT- O dialeto de SQL da base de dados do Spanner. Tem de ser um dos seguintes:
POSTGRESQL,GOOGLE_STANDARD_SQL. --ddl=DDL- Declarações DDL (linguagem de definição de dados) separadas por ponto e vírgula a executar
na base de dados recém-criada. Se existir um erro em qualquer declaração, a base de dados não é criada. Este sinalizador é ignorado se
--ddl_fileestiver definido. Não suportado por bases de dados de dialeto PostgreSQL. --ddl-file=DDL_FILE- Caminho de um ficheiro que contém declarações DDL (linguagem de definição de dados) separadas por ponto e vírgula para executar na base de dados recém-criada. Se existir um erro em qualquer declaração, a base de dados não é criada. Se
--ddl_fileestiver definido,--ddlé ignorado. Não suportado por bases de dados de dialeto PostgreSQL.
Se estiver a especificar uma chave do Cloud Key Management Service para usar quando criar a base de dados, inclua as seguintes opções:
--kms-key=KMS_KEY- ID da chave ou identificador totalmente qualificado da chave.
Esta flag tem de ser especificada se algum dos outros argumentos neste grupo for especificado. Os outros argumentos podem ser omitidos se o identificador totalmente qualificado for fornecido.
--kms-keyring=KMS_KEYRING- ID do conjunto de chaves do Cloud KMS da chave.
--kms-location=KMS_LOCATION- Google Cloud localização da chave.
--kms-project=KMS_PROJECT- Google Cloud ID do projeto da chave.
Cliente (GoogleSQL)
C++
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Go
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Java
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Node.js
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
PHP
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Python
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Ruby
Para saber como instalar e usar a biblioteca cliente do Spanner, consulte o artigo Bibliotecas cliente do Spanner.
Para se autenticar no Spanner, configure as Credenciais padrão da aplicação. Para mais informações, consulte o artigo Configure a autenticação para um ambiente de desenvolvimento local.
Importe os seus próprios dados
Pode importar os seus próprios dados para uma base de dados do Spanner através de um ficheiro CSV, um ficheiro de despejo do MySQL ou um ficheiro de despejo do PostgreSQL. Pode carregar um ficheiro local através do Cloud Storage ou diretamente a partir de um contentor do Cloud Storage. O carregamento de um ficheiro local através do Cloud Storage pode incorrer em custos.
Se optar por usar um ficheiro CSV, também tem de carregar um ficheiro JSON separado que contenha o esquema da base de dados.
Google Cloud consola
Na Google Cloud consola, aceda à página Instâncias do Spanner.
Selecione a instância na qual quer criar a base de dados.
Clique em Importar os meus próprios dados.
Introduza os seguintes valores:
Selecione o Tipo de ficheiro.
Carregue o ficheiro a partir do computador ou selecione um caminho do bucket do Cloud Storage para o ficheiro.
(Opcional) Se optar por usar um ficheiro CSV, também tem de carregar um ficheiro JSON separado que contenha o esquema da base de dados. O ficheiro JSON tem de usar a seguinte estrutura para definir o esquema:
{ "name": "COLUMN_NAME", "type": "TYPE", "notNull": NOT_NULL_VALUE, "primaryKeyOrder": PRIMARY_KEY_ORDER }
Substitua o seguinte:
COLUMN_NAME: o nome da coluna na tabela.
TYPE: o tipo de dados da coluna.
(Opcional) NOT_NULL_VALUE: indica se a coluna pode ou não armazenar valores nulos. As entradas válidas são
trueoufalse. A predefinição éfalse.(Opcional): PRIMARY_KEY_ORDER: determina a ordem da chave principal. O valor é definido como
0para uma coluna de chave não principal. Defina o valor como um número inteiro, por exemplo,1para uma coluna de chave principal. As colunas com números mais baixos aparecem mais cedo numa chave principal composta.
Por predefinição, o ficheiro CSV espera uma vírgula para o delimitador de campo e uma nova linha para o delimitador de linha. Para mais informações sobre a utilização de delimitadores personalizados, consulte a referência
gcloud alpha spanner databases import.Selecione uma base de dados nova ou existente como destino.
Clique em Importar.
O Spanner abre o Cloud Shell e preenche um comando que instala a ferramenta de migração do Spanner e executa o comando
gcloud alpha spanner databases import. Prima a teclaENTERpara importar dados para a sua base de dados.
Use um conjunto de dados de exemplo
Pode preencher novas bases de dados numa instância existente a partir de conjuntos de dados de exemplo que ajudam a explorar as capacidades do Spanner, como o respetivo modelo relacional, a pesquisa de texto completo ou a pesquisa vetorial.
Google Cloud consola
Na Google Cloud consola, aceda à página Instâncias do Spanner.
Selecione a instância na qual quer criar a base de dados.
Clique em Explorar conjuntos de dados.
Selecione um dos seguintes conjuntos de dados:
- Gráfico de finanças: use este conjunto de dados para explorar as funcionalidades de grafos do Spanner.
- Serviços bancários online: use este conjunto de dados para explorar as funcionalidades de pesquisa de texto completo do Spanner.
- Jogos online: use este conjunto de dados para explorar as funcionalidades da base de dados relacional do Spanner.
- Retalho: use este conjunto de dados para explorar as funcionalidades de grafos e de pesquisa de texto completo do Spanner.
Clique em Criar base de dados.
Atualize o esquema ou as opções da base de dados
Pode atualizar o esquema e as opções da base de dados através de declarações DDL.
Por exemplo, para adicionar uma coluna a uma tabela, use a seguinte declaração LDD:
GoogleSQL
ALTER TABLE Songwriters ADD COLUMN Publisher STRING(10);
PostgreSQL
ALTER TABLE Songwriters ADD COLUMN Publisher VARCHAR(10);
Para atualizar a versão do otimizador de consultas, use a seguinte declaração LDD:
GoogleSQL
ALTER DATABASE Music SET OPTIONS(optimizer_version=null);
PostgreSQL
ALTER DATABASE DB-NAME SET spanner.optimizer_version TO DEFAULT;
Para mais informações sobre as opções suportadas, consulte a referência ALTER DATABASEDDL
para o GoogleSQL ou o
PostgreSQL.
Para obter informações sobre atualizações de esquemas, consulte o artigo Faça atualizações de esquemas.
Google Cloud consola
Na Google Cloud consola, aceda à página Instâncias do Spanner.
Selecione a instância que contém a base de dados a alterar.
Selecione a base de dados.
Clique em Spanner Studio.
Clique em Novo separador ou use o separador do editor vazio. Em seguida, introduza as declarações DDL a aplicar.
Clique em Executar para aplicar as atualizações. Se existirem erros no DDL, a Google Cloud consola devolve um erro e a base de dados não é alterada.
gcloud
Para alterar uma base de dados com a ferramenta de linha de comandos gcloud, use
gcloud spanner databases ddl update.
gcloud spanner databases ddl update \ (DATABASE : --instance=INSTANCE) \ [--async] \ [--ddl=DDL] \ [--ddl-file=DDL_FILE] \
Consulte a
referência gcloud para ver detalhes sobre as opções disponíveis.
Transmita as atualizações da base de dados para o comando com a flag --ddl ou a flag --ddl-file. Se for especificado um ficheiro DDL, a flag --ddl é ignorada.
Consulte a ALTER DATABASEreferência DDL
para GoogleSQL ou
PostgreSQL para as declarações DDL a incluir.
LDD
Consulte a ALTER DATABASEreferência DDL
para GoogleSQL ou
PostgreSQL para obter detalhes.
Verifique o progresso das operações de atualização do esquema
Google Cloud consola
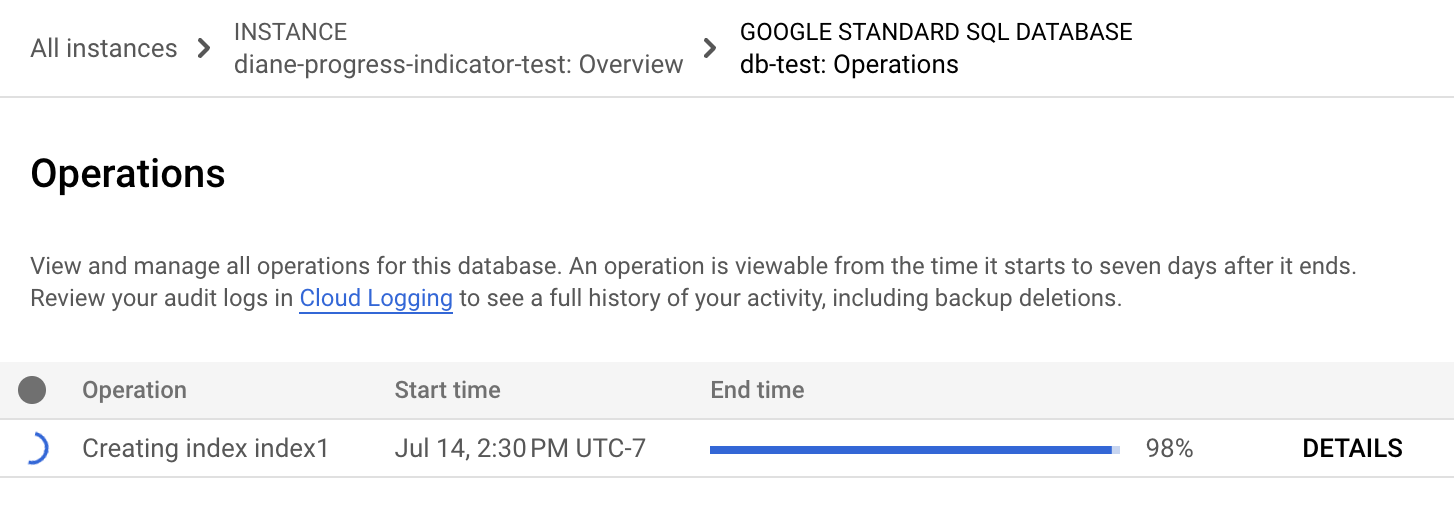
No menu de navegação do Spanner, selecione o separador Operações. A página Operações mostra uma lista de operações em execução ativas.
Encontre a operação de esquema na lista. Se ainda estiver em execução, a barra de progresso na coluna Hora de fim mostra a percentagem da operação que está concluída, conforme apresentado na imagem seguinte:
gcloud
Use gcloud spanner operations describe
para verificar o progresso de uma operação.
Obtenha o ID da operação:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Substitua o seguinte:
- INSTANCE-NAME com o nome da instância do Spanner.
- DATABASE-NAME com o nome da base de dados.
Corrida
gcloud spanner operations describe:gcloud spanner operations describe OPERATION_ID\ --instance=INSTANCE-NAME \ --database=DATABASE-NAME
Substitua o seguinte:
- OPERATION-ID: o ID da operação que quer verificar.
- INSTANCE-NAME: o nome da instância do Spanner.
- DATABASE-NAME: o nome da base de dados do Spanner.
A secção
progressna saída mostra a percentagem da operação concluída. O resultado tem um aspeto semelhante ao seguinte:done: true metadata: ... progress: - endTime: '2022-03-01T00:28:06.691403Z' progressPercent: 100 startTime: '2022-03-01T00:28:04.221401Z' - endTime: '2022-03-01T00:28:17.624588Z' startTime: '2022-03-01T00:28:06.691403Z' progressPercent: 100 ...
REST v1
Obtenha o ID da operação:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Substitua o seguinte:
- INSTANCE-NAME com o nome da instância do Spanner.
- DATABASE-NAME com o nome da base de dados.
Verifique o progresso da operação.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT-ID: o ID do projeto.
- INSTANCE-ID: o ID da instância.
- DATABASE-ID: o ID da base de dados.
- OPERATION-ID: o ID da operação.
Método HTTP e URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{ ... "progress": [ { "progressPercent": 100, "startTime": "2023-05-27T00:52:27.366688Z", "endTime": "2023-05-27T00:52:30.184845Z" }, { "progressPercent": 100, "startTime": "2023-05-27T00:52:30.184845Z", "endTime": "2023-05-27T00:52:40.750959Z" } ], ... "done": true, "response": { "@type": "type.googleapis.com/google.protobuf.Empty" } }
Se a operação demorar demasiado tempo, pode cancelá-la. Para mais informações, consulte o artigo Cancele uma operação de base de dados de execução prolongada.
Elimine uma base de dados
A eliminação de uma base de dados remove permanentemente a base de dados e todos os respetivos dados. Não é possível anular a eliminação da base de dados. Se a proteção contra eliminação de bases de dados estiver ativada numa base de dados, não pode eliminar essa base de dados até desativar a respetiva proteção contra eliminação.
As cópias de segurança existentes não são eliminadas quando uma base de dados é eliminada. Para mais informações, consulte o artigo Cópia de segurança e restauro.
Google Cloud consola
Na Google Cloud consola, aceda à página Instâncias do Spanner.
Selecione a instância que contém a base de dados a eliminar.
Selecione a base de dados.
Clique em Eliminar base de dados. É apresentada uma confirmação.
Escreva o nome da base de dados e clique em Eliminar.
gcloud
Para eliminar uma base de dados com a ferramenta de linha de comandos gcloud, use gcloud spanner databases delete.
gcloud spanner databases delete \ (DATABASE : --instance=INSTANCE)
As seguintes opções são obrigatórias:
DATABASE- ID da base de dados ou identificador totalmente qualificado da base de dados. Se
o identificador totalmente qualificado for fornecido, a flag
--instancedeve ser omitida. --instance=INSTANCE- A instância do Spanner para a base de dados.
Para mais detalhes, consulte a
gcloud referência.
LDD
O DDL não suporta a sintaxe de eliminação da base de dados.
O que se segue?
- Crie uma base de dados e carregue-a com dados de amostra.
- Saiba mais acerca da referência DDL do GoogleSQL.
- Saiba mais acerca da referência DDL do PostgreSQL.
- Saiba como fazer uma cópia de segurança e restaurar uma base de dados.
- Saiba como evitar a eliminação acidental da base de dados.
- Saiba como fazer atualizações de esquemas.