Questa pagina descrive la capacità di calcolo di Spanner e le due unità di misura utilizzate per quantificarla: nodi e unità di elaborazione.
Capacità di calcolo
Quando crei un'istanza, scegli una configurazione dell'istanza e una quantità di capacità di calcolo per l'istanza. La capacità di calcolo della tua istanza presenta le seguenti caratteristiche:
- Determina la quantità di risorse di server e spazio di archiviazione disponibili per i database nella tua istanza, incluso il carico del disco. Il carico del disco si applica solo ai carichi di lavoro che accedono ai dati archiviati nell'archiviazione HDD. Per maggiori informazioni, vedi Panoramica dell'archiviazione a livelli.
Viene misurata in unità di elaborazione (PU) o nodi, con 1000 PU equivalenti a 1 nodo.
- Un nodo o 1000 PU è un'unità logica di capacità di calcolo e non rappresenta un singolo server fisico. Le risorse di calcolo per ogni nodo sono distribuite su più macchine fisiche sottostanti o server. Il numero di server per nodo dipende dalla configurazione dell'istanza. Ad esempio, un'istanza regionale utilizza almeno tre server per nodo, mentre un'istanza multiregionale ne utilizza almeno cinque. Per ulteriori informazioni, consulta Capacità di calcolo e configurazioni delle istanze.
- Quando definisci o modifichi la capacità di calcolo di un'istanza, devi specificare le PU in multipli di 100 (ad esempio 100, 200, 300). Quando il numero di PU raggiunge 1000, puoi specificare quantità maggiori come multipli di 1000 PU (ad esempio 1000, 2000, 3000) o come nodi (ad esempio 1, 2, 3).
Spanner rende disponibile la capacità di calcolo specificata (replicata) nella sua interezza all'interno di ogni zona che ospita una replica dei tuoi dati. Ad esempio, se esegui il provisioning di 1000 unità di elaborazione per un'istanza regionale, che in genere ha repliche in tre zone, ciascuna di queste tre zone dispone di tutte le 1000 unità di elaborazione di potenza di calcolo disponibili per gestire la replica. Spanner non divide né distribuisce le PU totali tra le zone. L'unità di misura che utilizzi non ha importanza, a meno che tu non stia creando un'istanza la cui capacità di calcolo è inferiore a 1000 PU (1 nodo). In questo caso, devi utilizzare le PU per specificare la capacità di calcolo dell'istanza.
Le istanze con meno di 1000 PU sono create per dimensioni, query e carichi di lavoro più piccoli. Hanno risorse di calcolo limitate, il che può comportare problemi di scalabilità non lineare e di prestazioni per alcuni carichi di lavoro. Queste istanze potrebbero anche registrare aumenti intermittenti delle latenze.
Disponibilità di Spanner
Spanner è progettato per l'alta disponibilità. Poiché la capacità di calcolo di ogni istanza è distribuita su più server in zone diverse, Spanner è resiliente all'errore di un singolo server. La perdita di un singolo server non costituisce un errore del nodo. Spanner gestisce automaticamente le risorse sottostanti per fornire disponibilità continua per la tua istanza.
Limiti di archiviazione dei dati
Come descritto in Quote e limiti, per fornire alta disponibilità e bassa latenza durante l'accesso a un database, Spanner utilizza la capacità di calcolo di un'istanza come base per determinare i limiti di archiviazione, seguendo le seguenti linee guida:
- Per le istanze più piccole di un nodo (1000 PU), Spanner assegna 1024 GB di dati per ogni 100 PU nel database.
- Per le istanze con 1 nodo o più, Spanner assegna 10 TiB di dati per ogni nodo.
Ad esempio, per creare un'istanza per un database da 300 GB, puoi impostare la capacità di calcolo su 100 PU. Questa quantità di capacità di calcolo mantiene l'istanza al di sotto del limite finché il database non supera i 1024 GB. Dopo che il database raggiunge questa dimensione, devi aggiungere altre 100 PU per consentire l'espansione del database. In caso contrario, Spanner potrebbe rifiutare le scritture sul database. Per maggiori informazioni, consulta Consigli per l'utilizzo dello spazio di archiviazione del database.
Spanner fattura lo spazio di archiviazione effettivamente utilizzato dalle istanze e non la loro allocazione totale dello spazio di archiviazione.
Prestazioni
I valori di velocità effettiva di lettura e scrittura di picco che una determinata quantità di capacità di calcolo può fornire dipendono dalla configurazione dell'istanza, nonché dalla progettazione dello schema e dalle caratteristiche del set di dati. Per ulteriori informazioni, consulta la panoramica del rendimento.
Utilizzi istanze con meno di 1000 PU per dimensioni dei dati, query e carichi di lavoro più piccoli. Per i carichi di lavoro più grandi, le risorse di calcolo limitate potrebbero comportare scalabilità e prestazioni non lineari, con aumenti intermittenti delle latenze.
Capacità di calcolo e configurazioni delle istanze
Come descritto in Configurazioni regionali, a due regioni e multiregionali, Spanner distribuisce un'istanza tra le zone di una o più regioni per fornire prestazioni e disponibilità elevate. Di conseguenza, Spanner distribuisce anche le risorse del server fornite dalla capacità di calcolo dell'istanza.
Ecco un diagramma che illustra questa distribuzione delle risorse del server.
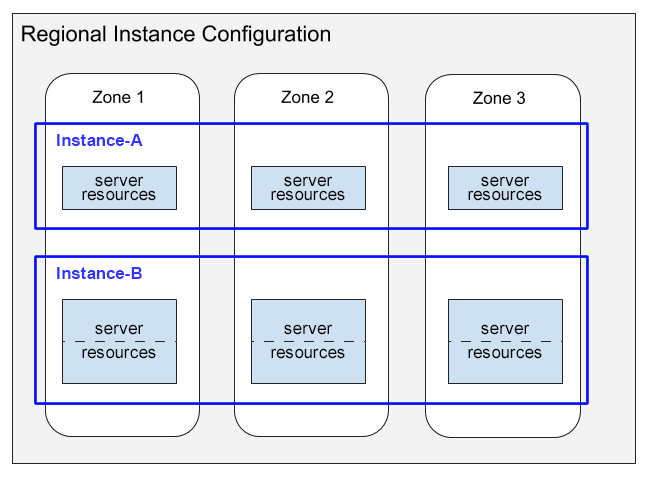
Questo diagramma mostra due istanze con configurazioni regionali:
- Instance-A mostra un'istanza di 1000 PU (1 nodo) con la relativa distribuzione della capacità di calcolo che consuma risorse del server in ciascuna delle tre zone.
- Instance-B mostra un'istanza di 2000 PU (2 nodi) con la relativa distribuzione della capacità di calcolo che consuma risorse del server in ciascuna delle tre zone.
Nota quanto segue in questo diagramma:
Per ogni istanza, Spanner alloca risorse server in ogni zona della configurazione regionale. Ogni risorsa server per zona utilizza la replica dei dati nella propria zona. Per informazioni sulle repliche dei dati nelle configurazioni delle istanze, consulta Configurazioni regionali, a due regioni e multiregionali. Per informazioni su come Spanner mantiene sincronizzate queste repliche dei dati, consulta Replica.
Le risorse del server per l'istanza A vengono mostrate in singole caselle, mentre le risorse per l'istanza B vengono mostrate in caselle suddivise in due parti. Questa differenza dimostra che Spanner alloca le risorse del server in modo diverso per le istanze di dimensioni diverse:
- Per le istanze di 1000 PU (1 nodo) e più piccole, Spanner alloca le risorse del server in un'unica attività del server per zona.
- Per le istanze più grandi di 1000 PU (1 nodo), Spanner alloca le risorse del server in più attività del server per zona, con un'attività per ogni 1000 PU. L'utilizzo di più attività del server per zona offre prestazioni migliori e consente a Spanner di creare divisioni del database e fornire prestazioni ancora migliori.
Modificare la capacità di calcolo
Dopo aver creato un'istanza, puoi aumentarne la capacità di calcolo in un secondo momento. Nella maggior parte dei casi, le richieste vengono completate in pochi minuti. In rari casi, uno scale up potrebbe richiedere fino a un'ora.
Puoi ridurre la capacità di calcolo di un'istanza Spanner, tranne nei seguenti scenari:
Non puoi archiviare più di 10 TiB di dati per nodo (1000 unità di elaborazione).
Esiste un numero elevato di divisioni per i dati della tua istanza. In questo scenario, Spanner potrebbe non essere in grado di gestire le suddivisioni dopo la riduzione della capacità di calcolo. Puoi provare a ridurre la capacità di calcolo di quantità progressivamente più piccole finché non trovi la capacità minima necessaria a Spanner per gestire tutte le divisioni dell'istanza.
Spanner può creare un numero elevato di suddivisioni per adattarsi ai tuoi pattern di utilizzo. Se i tuoi pattern di utilizzo cambiano, dopo una o due settimane, Spanner potrebbe unire alcune suddivisioni e puoi provare a ridurre la capacità di calcolo dell'istanza.
Quando rimuovi la capacità di calcolo, monitora l'utilizzo della CPU e le latenze delle richieste in Cloud Monitoring per assicurarti che l'utilizzo della CPU rimanga inferiore al 65% per le istanze regionali e al 45% per ogni regione nelle istanze multiregionali. Potresti riscontrare un aumento temporaneo delle latenze delle richieste durante la rimozione della capacità di calcolo.
Spanner non ha una modalità di sospensione. La capacità di calcolo di Spanner è una risorsa dedicata e, anche quando non esegui un carico di lavoro, Spanner esegue spesso operazioni in background per ottimizzare e proteggere i tuoi dati.
Puoi utilizzare la consoleGoogle Cloud , Google Cloud CLI o le librerie client Spanner per modificare la capacità di calcolo. Per ulteriori informazioni, vedi Modificare la capacità di calcolo.
Capacità di calcolo e repliche
Se devi scalare le risorse di server e archiviazione nella tua istanza, aumenta la capacità di calcolo dell'istanza. Tieni presente che l'aumento della capacità di calcolo non aumenta il numero di repliche (che sono fisse per una determinata configurazione dell'istanza), ma aumenta le risorse di ogni replica nell'istanza. L'aumento della capacità di calcolo fornisce a ogni replica più CPU e RAM, il che aumenta il throughput della replica (ovvero, possono verificarsi più letture e scritture al secondo).
Passaggi successivi
- Scopri come creare e gestire le istanze.