本頁面說明 Spanner 運算資源,以及用於量化運算資源的兩種測量單位:節點和處理單元。
運算能力
建立執行個體時,請選擇「執行個體設定」,並為執行個體分配運算資源。您執行個體的運算容量具有下列特徵:
- 這會決定執行個體中資料庫可用的伺服器和儲存空間資源量,包括磁碟負載。磁碟負載僅適用於存取 HDD 儲存空間所儲存資料的工作負載。詳情請參閱「分層儲存空間總覽」。
運算資源是以處理單元 (PU) 或節點計算,1000 個 PU 等於 1 個節點。
- 節點或 1,000 個處理單元是運算能力的邏輯單元,不代表單一實體伺服器。每個節點的運算資源會分散在多部底層實體機器或伺服器上。每個節點的伺服器數量取決於執行個體設定。舉例來說,區域執行個體每個節點至少使用三部伺服器,而多區域執行個體則至少使用五部。詳情請參閱「運算容量和執行個體設定」。
- 定義或變更執行個體的運算容量時,您必須以 100 的倍數指定 PU (例如 100、200、300)。當處理單元數量達到 1000 時,您可以指定較大的數量,例如 1000 個處理單元的倍數 (例如 1000、2000、3000),或是節點 (例如 1、2、3)。
Spanner 會在每個代管資料副本的區域中,提供完整的指定運算容量 (複製)。舉例來說,如果您為地區執行個體佈建 1000 個 PU,而這類執行個體通常有三個區域的副本,則這三個區域的副本都可使用完整的 1000 個 PU 計算能力。Spanner 不會將 PU 總數劃分或分配到各個可用區。除非您要建立運算能力小於 1,000 個 PU (1 個節點) 的執行個體,否則使用哪種測量單位都沒關係。在這種情況下,您必須使用 PU 指定執行個體的運算容量。
PU 數量少於 1,000 個的執行個體適用於較小的資料大小、查詢和工作負載。運算資源有限,因此部分工作負載可能會出現非線性擴充和效能問題。這些執行個體也可能會間歇性地增加延遲時間。
Spanner 適用情形
Spanner 專為高可用性而設計。 由於每個執行個體的運算容量分散在不同區域的多部伺服器上,因此 Spanner 能夠抵禦任何一部伺服器的故障。個別伺服器故障不算是節點故障。Spanner 會自動管理基礎資源,確保執行個體持續可用。
資料儲存空間上限
如「配額和限制」一文所述,為確保存取資料庫時能兼顧高可用性及低延遲優勢,Spanner 會根據執行個體的運算資源,按照下列準則決定儲存空間限制:
- 如果執行個體的節點少於 1 個 (1,000 個 PU),Spanner 會為資料庫中每 100 個 PU 分配 1024.0 GiB 的資料。
- 如果執行個體有 1 個以上的節點,Spanner 會為每個節點分配 10 TiB 的資料。
舉例來說,如要為 300 GB 的資料庫建立執行個體,您可以將運算容量設為 100 PU。在資料庫大小超過 1024.0 GiB 前,這個運算容量可確保執行個體不超過限制。資料庫達到這個大小後,您必須再新增 100 個 PU,資料庫才能繼續成長。否則 Spanner 可能會拒絕寫入資料庫。詳情請參閱資料庫儲存空間用量建議。
Spanner 會根據執行個體實際使用的儲存空間計費,而非總儲存空間配額。
成效
特定運算容量可提供的最高讀取和寫入總處理量,取決於執行個體設定、結構定義設計和資料集特性。詳情請參閱「成效總覽」。
如果資料大小、查詢和工作負載較小,可以使用 PU 少於 1,000 個的執行個體。對於較大的工作負載,有限的運算資源可能會導致非線性資源調度和效能,延遲時間也會間歇性增加。
運算能力和執行個體設定
如「地區、雙區域和多區域設定」一文所述,Spanner 會將執行個體分散到一或多個區域的各個區域,以提供高效能和高可用性。因此,Spanner 也會分配執行個體運算容量提供的伺服器資源。
下圖說明伺服器資源的分配情形。
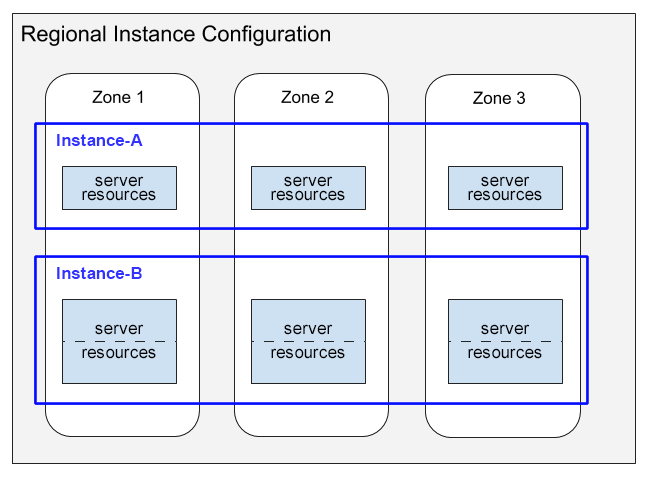
下圖顯示兩個具有區域設定的執行個體:
- 執行個體 A 顯示 1000 個 PU (1 個節點) 的執行個體,其運算容量分配會消耗三個區域中每個區域的伺服器資源。
- 執行個體 B 顯示 2000 個 PU (2 個節點) 的執行個體,其運算容量分配會消耗三個區域中每個區域的伺服器資源。
請注意此圖中的下列事項:
Spanner 會為每個執行個體,在區域設定的每個區域中分配伺服器資源。每個區域伺服器資源都會使用所在區域的資料副本。如要瞭解執行個體設定中的資料副本,請參閱區域、雙區域和多區域設定。 如要瞭解 Spanner 如何讓這些資料副本保持同步,請參閱「複製」。
Instance-A 的伺服器資源顯示在單一方塊中,而 Instance-B 的資源則顯示在分成兩部分的方塊中。這項差異說明 Spanner 會為不同大小的執行個體分配不同的伺服器資源:
- 對於 1000 個處理單元 (1 個節點) 以下的執行個體,Spanner 會在每個區域中,為單一伺服器工作分配伺服器資源。
- 如果執行個體大於 1,000 個 PU (1 個節點),Spanner 會在每個區域的多個伺服器工作中分配伺服器資源,每 1, 000 個 PU 對應一項工作。每個區域使用多個伺服器工作可提升效能,並讓 Spanner 建立資料庫分割,進一步提升效能。
變更運算能力
建立執行個體後,您可以在日後提高運算容量。在大多數情況下,要求會在幾分鐘內完成。在極少數情況下,擴大作業最多可能需要一小時才能完成。
您可以減少 Spanner 執行個體的運算能力,但下列情況除外:
每個節點 (1,000 個處理單元) 最多只能儲存 10 TiB 的資料。
執行個體資料的分割數量過多。在這種情況下,減少運算資源後,Spanner 可能無法管理分割。您可以嘗試逐步減少運算容量,直到找出 Spanner 管理所有執行個體分割所需的最低容量為止。
Spanner 可以建立大量資料分組,以配合您的使用模式。如果使用模式改變,Spanner 可能會在幾週後合併部分分割,屆時您可以嘗試減少執行個體的運算容量。
移除運算容量時,請在 Cloud Monitoring 中監控 CPU 使用率和要求延遲時間,確保區域執行個體的 CPU 使用率維持在 65% 以下,多區域執行個體中每個區域的 CPU 使用率維持在 45% 以下。移除運算容量時,要求延遲時間可能會暫時增加。
Spanner 沒有暫停模式。Spanner 運算資源是專屬資源,即使您沒有執行工作負載,Spanner 也會頻繁執行背景工作,以最佳化及保護您的資料。
您可以透過 Google Cloud 控制台、Google Cloud CLI 或 Spanner 用戶端程式庫變更運算容量。詳情請參閱「變更運算容量」。
運算能力與副本
如要擴充執行個體的伺服器和儲存空間資源,請提高執行個體的運算能力。請注意,增加運算容量並不會增加備用資源的數量 (該數量在指定的執行個體設定中為固定值),而是增加執行個體中每個備用資源所擁有的資源。增加運算資源可為每個副本提供更多 CPU 和 RAM,進而增加副本的總處理量,也就是每秒可以執行更多的讀取和寫入作業。
後續步驟
- 瞭解如何建立及管理執行個體。