En esta página se describe la capacidad de computación de Spanner y las dos unidades de medida que se usan para cuantificarla: nodos y unidades de procesamiento.
Capacidad de computación
Cuando creas una instancia, eliges una configuración de instancia y una cantidad de capacidad de computación para tu instancia. La capacidad de computación de tu instancia tiene las siguientes características:
- Determina la cantidad de recursos de servidor y almacenamiento que están disponibles para las bases de datos de tu instancia, incluida la carga de disco. La carga de disco solo se aplica a las cargas de trabajo que acceden a datos almacenados en almacenamiento HDD. Para obtener más información, consulta el artículo Introducción al almacenamiento por niveles.
Se mide en unidades de procesamiento (PUs) o nodos, donde 1000 PUs equivalen a 1 nodo.
- Un nodo o 1000 PUs es una unidad lógica de capacidad de computación y no representa un único servidor físico. Los recursos de computación de cada nodo se distribuyen entre varias máquinas físicas subyacentes o servidores. El número de servidores por nodo depende de la configuración de tu instancia. Por ejemplo, una instancia regional usa al menos tres servidores por nodo, mientras que una instancia multirregional usa al menos cinco. Para obtener más información, consulta Capacidad de computación y configuraciones de instancias.
- Cuando definas o cambies la capacidad de computación de una instancia, debes especificar las unidades de procesamiento en múltiplos de 100 (por ejemplo, 100, 200 o 300). Cuando el número de PUs llegue a 1000, podrá especificar cantidades mayores como múltiplos de 1000 PUs (por ejemplo, 1000, 2000 o 3000) o como nodos (por ejemplo, 1, 2 o 3).
Spanner pone a tu disposición la capacidad de computación especificada (replicada) en su totalidad en cada zona que aloja una réplica de tus datos. Por ejemplo, si aprovisionas 1000 UPs para una instancia regional, que normalmente tiene réplicas en tres zonas, cada una de esas tres zonas tiene las 1000 UPs completas de potencia de computación disponibles para dar servicio a su réplica. Spanner no divide ni distribuye el total de PUs entre las zonas. La unidad de medida que uses no importa, a menos que crees una instancia cuya capacidad de computación sea inferior a 1000 PUs (1 nodo). En este caso, debes usar PUs para especificar la capacidad de computación de la instancia.
Las instancias con menos de 1000 PUs se han creado para tamaños de datos, consultas y cargas de trabajo más pequeños. Tienen recursos de computación limitados, lo que puede provocar un escalado no lineal y problemas de rendimiento en algunas cargas de trabajo. Estas instancias también pueden experimentar aumentos intermitentes de la latencia.
Disponibilidad de Spanner
Spanner se ha diseñado para ofrecer una alta disponibilidad. Como la capacidad de computación de cada instancia se distribuye entre varios servidores de diferentes zonas, Spanner es resistente a los fallos de cualquier servidor. La pérdida de un servidor individual no constituye un fallo de nodo. Spanner gestiona sus recursos subyacentes automáticamente para proporcionar disponibilidad continua a tu instancia.
Límites de almacenamiento de datos
Como se detalla en Cuotas y límites, para ofrecer alta disponibilidad y baja latencia al acceder a una base de datos, Spanner usa la capacidad de computación de una instancia como base para determinar los límites de almacenamiento, siguiendo estas directrices:
- En las instancias de menos de 1 nodo (1000 UPs), Spanner asigna 1024,0 GiB de datos por cada 100 UPs de la base de datos.
- En las instancias de 1 nodo o más, Spanner asigna 10 TiB de datos por cada nodo.
Por ejemplo, para crear una instancia de una base de datos de 300 GB, puedes definir su capacidad de computación en 100 PUs. Esta cantidad de capacidad de computación mantiene la instancia por debajo del límite hasta que la base de datos supera los 1024,0 GiB. Cuando la base de datos alcance este tamaño, tendrás que añadir otras 100 UPs para permitir que la base de datos crezca. De lo contrario, Spanner podría rechazar las operaciones de escritura en la base de datos. Para obtener más información, consulta las recomendaciones para el uso del almacenamiento de bases de datos.
Spanner factura el almacenamiento que utilizan las instancias, no el total asignado.
Rendimiento
Los valores máximos de lectura y escritura que puede proporcionar una cantidad determinada de capacidad de computación dependen de la configuración de la instancia, así como del diseño del esquema y de las características del conjunto de datos. Para obtener más información, consulta el artículo Vista general del rendimiento.
Utiliza instancias con menos de 1000 UPs para tamaños de datos, consultas y cargas de trabajo más pequeños. En el caso de cargas de trabajo más grandes, sus recursos de computación limitados pueden provocar un escalado y un rendimiento no lineales, con aumentos intermitentes de la latencia.
Capacidad de computación y configuraciones de instancias
Tal como se describe en Configuraciones en una sola región, dos regiones y varias regiones, Spanner distribuye una instancia en las zonas de una o varias regiones para ofrecer un alto rendimiento y una alta disponibilidad. Por lo tanto, Spanner también distribuye los recursos del servidor proporcionados por la capacidad de computación de la instancia.
En este diagrama se muestra la distribución de los recursos del servidor.
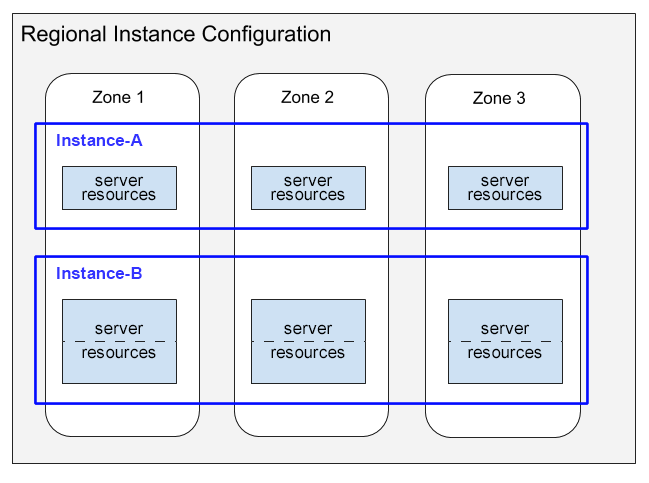
En este diagrama se muestran dos instancias que tienen configuraciones regionales:
- Instancia A muestra una instancia de 1000 PUs (1 nodo) con su distribución de capacidad de computación que consume recursos del servidor en cada una de las tres zonas.
- Instancia B: muestra una instancia de 2000 PUs (2 nodos) con su distribución de capacidad de computación, que consume recursos del servidor en cada una de las tres zonas.
En este diagrama, ten en cuenta lo siguiente:
En cada instancia, Spanner asigna recursos de servidor en cada zona de la configuración regional. Cada recurso de servidor por zona usa la réplica de datos de su zona. Para obtener información sobre las réplicas de datos en las configuraciones de instancias, consulta Configuraciones regionales, birregionales y multirregionales. Para obtener información sobre cómo mantiene Spanner sincronizadas estas réplicas de datos, consulta Replicación.
Los recursos del servidor de la instancia A se muestran en cuadros individuales, mientras que los recursos de la instancia B se muestran en cuadros divididos en dos partes. Esta diferencia muestra que Spanner asigna recursos del servidor de forma diferente a las instancias de distintos tamaños:
- En el caso de las instancias de 1000 UPs (1 nodo) o menos, Spanner asigna recursos de servidor en una sola tarea de servidor por zona.
- En el caso de las instancias de más de 1000 UPs (1 nodo), Spanner asigna recursos de servidor en varias tareas de servidor por zona, con una tarea por cada 1000 UPs. Usar varias tareas de servidor por zona proporciona un mejor rendimiento y permite que Spanner cree divisiones de bases de datos y ofrezca un rendimiento aún mejor.
Cambiar la capacidad de computación
Después de crear una instancia, puedes aumentar su capacidad de computación más adelante. En la mayoría de los casos, las solicitudes se completan en unos minutos. En contadas ocasiones, un aumento de escala puede tardar hasta una hora en completarse.
Puedes reducir la capacidad de computación de una instancia de Spanner, excepto en los siguientes casos:
No puedes almacenar más de 10 TiB de datos por nodo (1000 unidades de procesamiento).
Hay un gran número de divisiones de los datos de tu instancia. En este caso, es posible que Spanner no pueda gestionar las divisiones después de reducir la capacidad de computación. Puedes probar a reducir la capacidad de computación en cantidades cada vez menores hasta que encuentres la capacidad mínima que necesita Spanner para gestionar todas las divisiones de la instancia.
Spanner puede crear un gran número de divisiones para adaptarse a tus patrones de uso. Si tus patrones de uso cambian, después de una o dos semanas, Spanner podría combinar algunas divisiones y podrías intentar reducir la capacidad de computación de la instancia.
Cuando elimines capacidad de computación, monitoriza la utilización de la CPU y las latencias de las solicitudes en Cloud Monitoring para asegurarte de que la utilización de la CPU se mantiene por debajo del 65% en las instancias regionales y del 45% en cada región de las instancias multirregionales. Es posible que experimentes un aumento temporal de la latencia de las solicitudes mientras se elimina la capacidad de computación.
Spanner no tiene un modo de suspensión. La capacidad de computación de Spanner es un recurso dedicado y, aunque no estés ejecutando ninguna carga de trabajo, Spanner realiza con frecuencia tareas en segundo plano para optimizar y proteger tus datos.
Puedes usar la consola deGoogle Cloud , Google Cloud CLI o las bibliotecas de cliente de Spanner para cambiar la capacidad de computación. Para obtener más información, consulta Cambiar la capacidad de computación.
Capacidad de computación frente a réplicas
Si necesitas aumentar los recursos de servidor y almacenamiento de tu instancia, aumenta la capacidad de computación de la instancia. Ten en cuenta que aumentar la capacidad de computación no aumenta el número de réplicas (que es fijo para una configuración de instancia determinada), sino que aumenta los recursos que tiene cada réplica en la instancia. Al aumentar la capacidad de cálculo, cada réplica tiene más CPU y RAM, lo que incrementa el rendimiento de la réplica (es decir, se pueden realizar más lecturas y escrituras por segundo).
Siguientes pasos
- Consulta cómo crear y gestionar instancias.