이 페이지에서는 Spanner 컴퓨팅 용량과 이를 정량화하는 데 사용되는 두 가지 측정 단위인 노드와 처리 단위를 설명합니다.
컴퓨팅 용량
인스턴스를 만들 때 인스턴스 구성과 인스턴스의 컴퓨팅 용량을 선택합니다. 인스턴스의 컴퓨팅 용량에는 다음과 같은 특징이 있습니다.
- 디스크 로드를 비롯해 인스턴스의 데이터베이스에서 사용할 수 있는 서버 및 스토리지 리소스의 양을 결정합니다. 디스크 로드는 HDD 스토리지에 저장된 데이터에 액세스하는 워크로드에만 적용됩니다. 자세한 내용은 계층형 스토리지 개요를 참조하세요.
처리 단위(PU) 또는 노드로 측정되며, 1,000PU는 1노드와 같습니다.
- 노드 또는 1,000PU는 컴퓨팅 용량의 논리적 단위이며 단일 물리적 서버를 나타내지 않습니다. 각 노드의 컴퓨팅 리소스는 여러 기본 물리적 머신 또는 서버에 분산됩니다. 노드당 서버 수는 인스턴스 구성에 따라 다릅니다. 예를 들어 리전 인스턴스는 노드당 서버를 3개 이상 사용하는 반면 멀티 리전 인스턴스는 5개 이상 사용합니다. 자세한 내용은 컴퓨팅 용량 및 인스턴스 구성을 참조하세요.
- 인스턴스에서 컴퓨팅 용량을 정의하거나 변경할 때는 PU를 100의 배수(예: 100, 200, 300)로 지정해야 합니다. PU 수가 1,000에 도달하면 더 많은 수량을 1,000PU의 배수(예: 1000, 2000, 3000) 또는 노드(예: 1, 2, 3)로 지정할 수 있습니다.
Spanner는 데이터 복제본을 호스팅하는 각 영역 내에서 지정된 컴퓨팅 용량을 전체적으로 사용할 수 있도록 합니다(복제됨). 예를 들어 일반적으로 3개 영역에 복제본이 있는 리전 인스턴스에 1,000개의 PU를 프로비저닝하면 각 영역에 복제본을 제공하는 데 사용할 수 있는 컴퓨팅 성능이 1,000PU가 됩니다. Spanner는 영역 간에 총 PU를 나누거나 분산하지 않습니다. 컴퓨팅 용량이 1,000PU(노드 1개)보다 작은 인스턴스를 만들지 않는 한 사용하는 측정 단위는 중요하지 않습니다. 이 경우 PU를 사용하여 인스턴스의 컴퓨팅 용량을 지정해야 합니다.
1,000PU 미만인 인스턴스는 더 작은 데이터 크기, 쿼리, 워크로드를 대상으로 합니다. 이러한 인스턴스는 컴퓨팅 리소스가 제한되므로 일부 워크로드의 경우 비선형 확장 및 성능 문제가 발생할 수 있습니다. 이러한 인스턴스에서 지연 시간이 간헐적으로 증가할 수도 있습니다.
Spanner 사용 가능 여부
Spanner는 고가용성을 위해 설계되었습니다. 각 인스턴스의 컴퓨팅 용량은 서로 다른 영역의 여러 서버에 분산되므로 Spanner는 하나의 서버 오류에 탄력적입니다. 개별 서버의 손실은 노드 장애를 구성하지 않습니다. Spanner는 인스턴스의 지속적인 가용성을 제공하기 위해 기본 리소스를 자동으로 관리합니다.
데이터 스토리지 한도
할당량 및 한도에 설명된 대로 데이터베이스에 액세스할 때 고가용성과 짧은 지연 시간을 제공하기 위해 Spanner는 다음 가이드라인을 따라 인스턴스의 컴퓨팅 용량을 기준으로 저장용량 한도를 결정합니다.
- 노드가 1개(1,000PU) 미만인 인스턴스의 경우 Spanner는 데이터베이스에 있는 100PU마다 1024.0GiB 데이터를 할당합니다.
- 노드가 1개 이상인 인스턴스의 경우 Spanner는 노드마다 10TiB 데이터를 할당합니다.
예를 들어 300GB 데이터베이스의 인스턴스를 만들려면 컴퓨팅 용량을 100PU로 설정하면 됩니다. 이렇게 하면 데이터베이스 크기가 1024.0GiB를 초과할 때까지 인스턴스를 한도 이하로 유지할 수 있습니다. 데이터베이스가 이 크기에 도달하면 데이터베이스 확장을 허용하도록 또 다른 100PU를 추가해야 합니다. 그렇지 않으면 Spanner에서 데이터베이스 쓰기를 거부할 수 있습니다. 자세한 내용은 데이터베이스 스토리지 사용률 권장사항을 참조하세요.
Spanner는 총 스토리지 할당량이 아니라 인스턴스에서 실제로 사용되는 스토리지에 대해 비용을 청구합니다.
성능
지정된 컴퓨팅 용량으로 제공할 수 있는 최대 읽기 및 쓰기 처리량 값은 스키마 디자인과 데이터 세트 특성뿐 아니라 인스턴스 구성에 따라 다릅니다. 자세한 내용은 성능 개요를 참조하세요.
1,000PU 미만인 인스턴스는 더 작은 데이터 크기, 쿼리, 워크로드를 대상으로 합니다. 대규모 워크로드의 경우 제한된 컴퓨팅 리소스로 인해 비선형 확장 및 성능 문제가 발생하고 지연 시간이 간헐적으로 증가할 수 있습니다.
컴퓨팅 용량 및 인스턴스 구성
리전, 이중 리전, 멀티 리전 구성에 설명된 대로 Spanner는 하나 이상의 리전 영역에 인스턴스를 분산하여 높은 성능과 고가용성을 제공합니다. 따라서 Spanner는 인스턴스의 컴퓨팅 용량에서 제공하는 서버 리소스도 배포합니다.
다음은 이러한 서버 리소스 분포를 보여주는 다이어그램입니다.
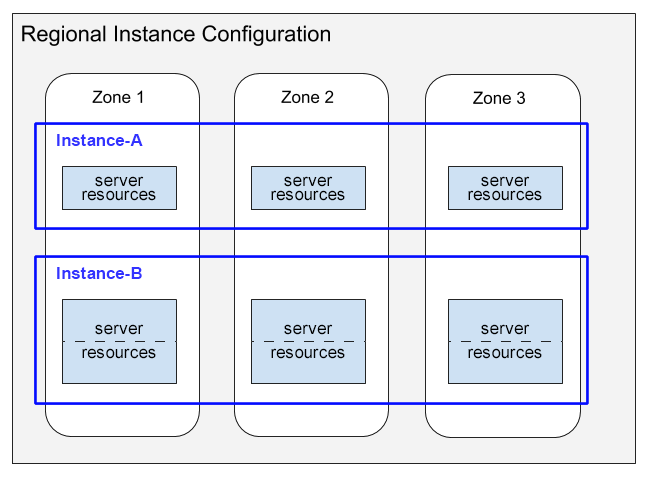
이 다이어그램은 리전 구성이 있는 두 인스턴스를 보여줍니다.
- Instance-A는 3개의 영역 각각에서 서버 리소스를 소비하는 컴퓨팅 용량 분산이 있는 1,000PU(노드 1개)의 인스턴스를 보여줍니다.
- Instance-B는 3개의 영역 각각에서 서버 리소스를 소비하는 컴퓨팅 용량 분산이 있는 2,000PU(노드 2개)의 인스턴스를 보여줍니다.
이 다이어그램에서 다음 사항에 주목하세요.
각 인스턴스에 대해 Spanner는 리전 구성의 각 영역에 서버 리소스를 할당합니다. 각 영역별 서버 리소스는 해당 영역의 데이터 복제본을 사용합니다. 인스턴스 구성의 데이터 복제본에 대한 자세한 내용은 리전, 이중 리전, 멀티 리전 구성을 참조하세요. Spanner가 이러한 데이터 복제본을 동기화 상태로 유지하는 방법에 대한 자세한 내용은 복제를 참조하세요.
Instance-A의 서버 리소스는 단일 상자로 표시되고 Instance-B의 리소스는 두 개의 부분으로 구분된 상자로 표시됩니다. 이러한 차이는 Spanner가 크기가 다른 인스턴스에 대해 서버 리소스를 다르게 할당한다는 것을 보여줍니다.
- 1,000PU(노드 1개) 이하의 인스턴스의 경우 Spanner는 영역당 단일 서버 태스크에 서버 리소스를 할당합니다.
- 1,000PU(노드 1개)를 초과하는 인스턴스의 경우 Spanner는 영역당 여러 서버 태스크에 서버 리소스를 할당합니다(1,000PU마다 하나의 태스크). 영역당 여러 서버 태스크를 사용하면 성능이 향상되고 Spanner가 데이터베이스 분할을 만들고 더 나은 성능을 제공합니다.
컴퓨팅 용량 변경
인스턴스를 만든 후에는 컴퓨팅 용량을 나중에 늘릴 수 있습니다. 대부분의 경우 몇 분 내에 요청이 완료됩니다. 드문 경우지만 수직 확장을 완료하는 데 최대 1시간까지 걸릴 수 있습니다.
다음 시나리오를 제외하고 Spanner 인스턴스의 컴퓨팅 용량을 줄일 수 있습니다.
노드(처리 단위 1,000개)당 10TiB를 초과하는 데이터를 저장할 수 없습니다.
인스턴스의 데이터에 대한 분할이 많습니다. 이 시나리오에서는 컴퓨팅 용량을 줄인 후 Spanner가 분할을 관리하지 못할 수 있습니다. Spanner에서 모든 인스턴스 분할을 관리하는 데 필요한 최소 용량을 확보할 때까지 컴퓨팅 용량을 점진적으로 조금씩 줄여볼 수 있습니다.
Spanner는 사용 패턴에 맞게 많은 수의 분할을 만들 수 있습니다. 사용 패턴이 변경되면 1~2주 후에 Spanner에서 일부 분할을 병합하며 사용자가 인스턴스의 컴퓨팅 용량을 줄일 수 있습니다.
컴퓨팅 용량을 삭제할 때 CPU 사용률을 모니터링하고 Cloud Monitoring에서 지연 시간을 요청하여 CPU 사용률이 리전 인스턴스의 경우 65% 미만, 멀티 리전 인스턴스의 각 리전에서 45% 미만으로 유지되도록 합니다. 컴퓨팅 용량을 삭제하는 동안 요청 지연 시간이 일시적으로 늘어날 수 있습니다.
Spanner에는 정지 모드가 없습니다. Spanner 컴퓨팅 용량은 전용 리소스이므로 워크로드를 실행하지 않는 경우에도 Spanner는 백그라운드 작업을 자주 수행하여 데이터를 최적화하고 보호합니다.
Google Cloud 콘솔, Google Cloud CLI 또는 Spanner 클라이언트 라이브러리를 사용하여 컴퓨팅 용량을 변경할 수 있습니다. 자세한 내용은 컴퓨팅 용량 변경을 참조하세요.
컴퓨팅 용량과 복제본 비교
인스턴스의 서버 및 스토리지 리소스를 수직 확장해야 하는 경우 인스턴스의 컴퓨팅 용량을 늘립니다. 컴퓨팅 용량을 늘려도 지정된 인스턴스 구성에서 일정한 복제본 수는 늘어나지 않지만 인스턴스에서 각 복제본의 리소스는 늘어납니다. 컴퓨팅 용량을 늘리면 각 복제본에 더 많은 CPU와 RAM이 제공되어 복제본의 처리량이 늘어납니다. 즉, 초당 읽기 및 쓰기 처리량이 늘어납니다.
다음 단계
- 인스턴스 만들기 및 관리 방법 알아보기