Esta página apresenta a ferramenta de escalonamento automático para Spanner (escalonador automático), uma ferramenta de código aberto que você pode usar como complemento do Spanner. Essa ferramenta permite aumentar ou reduzir automaticamente a capacidade de computação em uma ou mais instâncias do Spanner com base na capacidade em uso.
Para mais informações sobre o escalonamento no Spanner, consulte Escalonamento automático do Spanner. Para informações sobre como implantar a ferramenta de escalonador automático, consulte o seguinte:
- Implante a ferramenta de escalonador automático para Spanner nas funções do Cloud Run.
- Implante a ferramenta de escalonamento automático do Spanner no Google Kubernetes Engine (GKE).
Nesta página, apresentamos os recursos, a arquitetura e a configuração de alto nível do escalonador automático. Esses tópicos orientam você na implantação do escalonador automático em um dos ambientes de execução compatíveis em cada uma das diferentes topologias.
Escalonador automático
A ferramenta de escalonador automático é útil para gerenciar o uso e o desempenho das implantações do Spanner. Para ajudar você a equilibrar o controle de custos com necessidades de desempenho, o escalonador automático monitora suas instâncias e adiciona ou remove nós ou unidades de processamento automaticamente para garantir que eles permaneçam nos seguintes parâmetros:
Mais ou menos uma margem configurável.
O escalonamento automático das implantações do Spanner permite que a infraestrutura se adapte e dimensione automaticamente para atender aos requisitos de carga com pouca ou nenhuma intervenção. O escalonamento automático também dimensiona a infraestrutura provisionada, o que pode ajudar a minimizar os custos incorridos.
Arquitetura
O escalonador automático tem dois componentes principais: o Poller e o Scaler. Embora seja possível implantar o escalonador automático com configurações variadas em vários runtimes e topologias, a funcionalidade desses componentes principais é a mesma.
Nesta seção, descrevemos esses dois componentes e as respectivas finalidades em mais detalhes.
Aplicativo de pesquisa
O Poller coleta e processa as métricas de séries temporais de uma ou mais instâncias do Spanner. A função de pesquisa pré-processa os dados das métricas para cada instância do Spanner. Assim, somente os pontos de dados mais relevantes são avaliados e enviados para o escalonador. O pré-processamento feito pelo Poller também simplifica o processo de avaliação de limites para instâncias regionais, birregionais e multirregionais do Spanner.
Scaler
O escalonador avalia os pontos de dados recebidos do componente de pesquisa e determina se você precisa ajustar o número de nós ou unidades de processamento e, em caso afirmativo, até que ponto. A compara os valores da métrica com o limite, com a adição de uma margem permitida ou menos, e ajusta o número de nós ou unidades de processamento com base no método de escalonamento configurado. Para mais detalhes, consulte Métodos de escalonamento.
Durante o fluxo, a ferramenta de escalonamento automático cria um resumo das recomendações e ações no Cloud Logging para rastreamento e auditoria.
Recursos do escalonador automático
Esta seção descreve os principais recursos da ferramenta de escalonador automático.
Gerenciar várias instâncias
A ferramenta de escalonamento automático gerencia várias instâncias do Spanner em vários projetos. As instâncias multirregionais, birregionais e regionais têm limites de utilização diferentes que são usados no escalonamento. Por exemplo, implantações multirregionais e birregionais são escalonadas a 45% de uso de CPU de alta prioridade. Já as implantações regionais têm escalonamento em 65% de utilização de CPU de alta prioridade, mais ou menos uma margem permitida. Para mais informações sobre os diferentes limites de escalonamento, consulte Alertas para alta utilização da CPU.
Parâmetros de configuração independentes
Cada instância do Spanner com escalonamento automático pode ter uma ou mais programações de pesquisa. Cada programação de pesquisa tem o próprio conjunto de parâmetros de configuração.
Esses parâmetros determinam os seguintes fatores:
- Os números mínimo e máximo de nós ou unidades de processamento que controlam o quanto a instância pode ser pequena ou grande são, ajudando você a controlar os custos.
- O método de escalonamento usado para ajustar a instância do Spanner específica da carga de trabalho.
- Os períodos de espera para permitir que o Spanner gerencie divisões de dados.
Métodos de escalonamento
A ferramenta Autoscaler oferece três métodos diferentes para aumentar e diminuir o escalonamento das instâncias do Spanner: em etapas, linear e direto. Cada método é projetado para aceitar diferentes tipos de cargas de trabalho. Ao criar programações de pesquisa independentes, é possível aplicar um ou mais métodos a cada instância do Spanner com escalonamento automático.
As seções a seguir contêm mais informações sobre esses métodos de escalonamento.
Etapas
O escalonamento em etapas é útil para cargas de trabalho com picos pequenos ou múltiplos. Ele provisiona a capacidade para suavizar todos com um único evento de escalonamento automático.
O gráfico a seguir mostra um padrão de carga com vários platôs ou etapas de carga, em que cada um tem vários picos pequenos. Esse padrão é adequado para o método por etapas.
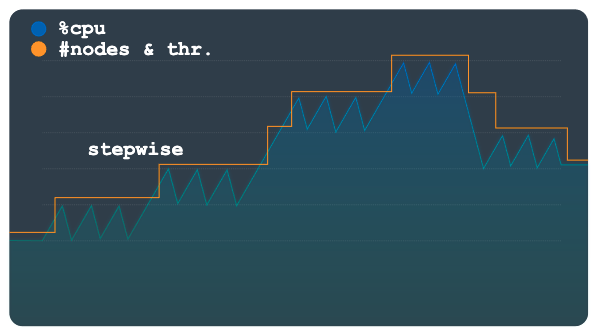
Quando o limite de carga é ultrapassado, esse método provisiona e remove nós ou unidades de processamento usando um número fixo, mas configurável. Por exemplo, três nós são adicionados ou removidos para cada ação de escalonamento. Ao mudar a configuração, é possível permitir que incrementos de capacidade maiores sejam adicionados ou removidos a qualquer momento.
Linear
O escalonamento linear é melhor usado com padrões de carga que mudam mais gradualmente ou têm alguns picos grandes. O método calcula o número mínimo de nós ou unidades de processamento necessárias para manter a utilização abaixo do limite de escalonamento. O número de nós ou unidades de processamento adicionados ou removidos em cada evento de escalonamento não é limitado a um valor fixo de etapas.
O padrão de carga de amostra no gráfico a seguir mostra aumentos e quedas repentinas grandes na carga. Essas flutuações não são agrupadas em etapas compreensíveis como estão no gráfico anterior. Esse padrão pode ser melhor processado usando o escalonamento linear.
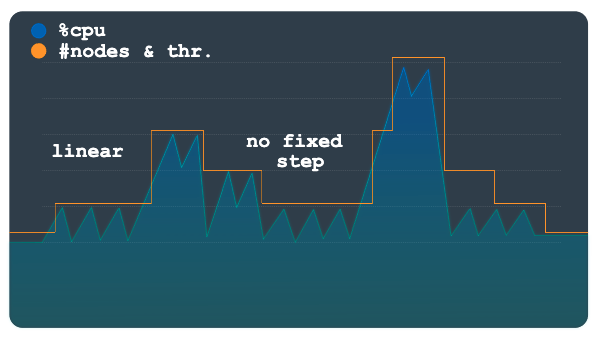
A ferramenta de escalonador automático usa a proporção da utilização observada acima do limite de utilização para calcular se é preciso adicionar ou subtrair nós ou unidades de processamento do número total atual.
A fórmula para calcular o novo número de nós ou unidades de processamento é a seguinte:
newSize = currentSize * currentUtilization / utilizationThreshold
Direta
O escalonamento direto aumenta a capacidade imediatamente. Esse método destina-se a aceitar cargas de trabalho em lote em que uma contagem de nós maior predeterminada é necessária periodicamente em uma programação com um horário de início conhecido. Esse método escalona a instância até o número máximo de nós ou unidades de processamento especificado na programação e se destina a ser usado além de um método linear ou de etapa.
O gráfico a seguir mostra o grande aumento planejado na carga, que o escalonador automático pré-provisionado para usar o método direto.
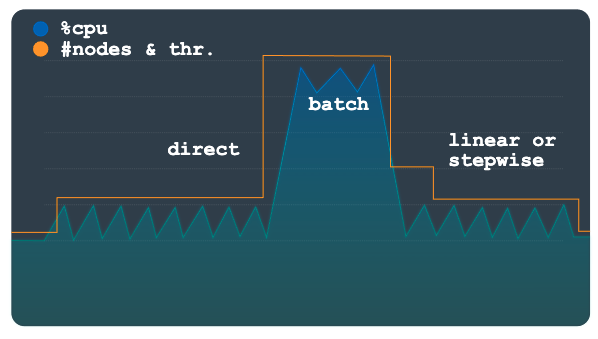
Depois que a carga de trabalho em lote for concluída e a utilização retornar aos níveis normais, dependendo da configuração, o escalonamento linear ou em etapa será aplicado para reduzir a instância automaticamente.
Configuração
A ferramenta de escalonamento automático tem diferentes opções de configuração que podem ser usadas para gerenciar o escalonamento das implantações do Spanner. Embora os parâmetros do Cloud Run functions e do GKE sejam semelhantes, eles são fornecidos de maneira diferente. Para mais informações sobre como configurar a ferramenta de escalonamento automático, consulte Como configurar uma implantação do Cloud Run functions e Como configurar uma implantação do GKE.
Configuração avançada
A ferramenta de escalonador automático tem opções avançadas de configuração para você controlar melhor quando e como as instâncias do Spanner são gerenciadas. As seções a seguir apresentam uma seleção desses controles.
Limites personalizados
A ferramenta de escalonador automático determina o número de nós ou unidades de processamento a serem adicionados ou subtraídos de uma instância usando os limites recomendados do Spanner para as seguintes métricas de carga:
- CPU de alta prioridade
- CPU em média contínua de 24 horas
- Uso do armazenamento
Recomendamos que você use os limites padrão conforme descrito em Como criar alertas para métricas do Spanner. No entanto, em alguns casos, talvez você queira modificar os limites usados pela ferramenta de escalonador automático. Por exemplo, use limites menores para fazer o escalonador automático reagir mais rapidamente do que para os limites mais altos. Essa modificação ajuda a evitar que os alertas sejam acionados em limites mais altos.
Métricas personalizadas
As métricas padrão na ferramenta de escalonador automático abordam a maioria dos cenários de desempenho e
escalonamento. No entanto, em alguns casos, talvez seja necessário especificar as próprias
métricas usadas para determinar quando fazer reduzir escalonamento horizontal e horizontal. Para esses cenários,
defina métricas personalizadas na configuração usando a
propriedade metrics.
Margens
Uma margem define um limite superior e um limite menor em torno do limite. A ferramenta de escalonamento automático só aciona um evento de escalonamento automático se o valor da métrica for maior que o limite máximo ou menor que o limite mínimo.
O objetivo desse parâmetro é evitar que eventos de escalonamento automático sejam acionados por pequenas flutuações de carga de trabalho ao redor do limite, reduzindo a quantidade de flutuação nas ações do escalonador automático. O limite e a margem juntos definem o seguinte intervalo, de acordo com o valor desejado para o valor da métrica:
[threshold - margin, threshold + margin]
Quanto menor for a margem, menor será o intervalo, resultando em uma probabilidade maior de que um evento de escalonamento automático seja acionado.
Especificar um parâmetro de margem para uma métrica é opcional e o padrão é cinco pontos percentuais antes e abaixo do parâmetro.
Divisão de dados
O Spanner atribui intervalos de dados chamados divisões a nós ou subdivisões de um nó chamados de unidades de processamento. As unidades de processamento ou nós gerenciam e exibem os dados nas divisões divididas de maneira independente. As divisões de dados são criadas com base em vários fatores, incluindo o volume de dados e os padrões de acesso. Para mais detalhes, consulte Spanner - esquema e modelo de dados.
Os dados são organizados em divisões, e o Spanner gerencia automaticamente as divisões. Dessa forma, quando a ferramenta de escalonamento automático adiciona ou remove nós ou unidades de processamento, ela precisa permitir que o back-end do Spanner tenha tempo suficiente para reatribuir e reorganizar as divisões conforme a nova capacidade é adicionada ou removida das instâncias.
A ferramenta de escalonamento automático usa períodos de espera em eventos de escalonamento vertical e horizontal para controlar a rapidez com que é possível adicionar ou remover nós ou unidades de processamento de uma instância. Com esse método, a instância tem o tempo necessário para reorganizar as relações entre as notas de computação ou unidades de processamento e divisões de dados. Por padrão, os períodos de redução e aumento de escala são definidos com os seguintes valores mínimos:
- Valor de escalonamento vertical: 5 minutos
- Valor de redução: 30 minutos
Para mais informações sobre recomendações de escalonamento e períodos de resfriamento, consulte Como escalonar instâncias do Spanner.
Preços
O consumo de recursos da ferramenta de escalonamento automático é pequeno em termos de computação, memória e armazenamento. Dependendo da configuração do escalonador automático, quando implantado nas funções do Cloud Run, o uso de recursos do escalonador automático geralmente está no nível gratuito dos serviços dependentes (funções do Cloud Run, Cloud Scheduler, Pub/Sub e Firestore).
Use a calculadora de preços para gerar uma estimativa de custo dos seus ambientes com base no uso previsto.
A seguir
- Saiba como implantar a ferramenta de escalonamento automático em funções do Cloud Run.
- Saiba como implantar a ferramenta de escalonamento automático no GKE.
- Leia mais sobre os limites recomendados do Spanner.
- Saiba mais sobre as métricas de uso de CPU e as métricas de latência do Spanner.
- Conheça as práticas recomendadas para o design de esquemas do Spanner para evitar pontos de acesso e carregar dados no Spanner.
- Confira arquiteturas de referência, diagramas, tutoriais e práticas recomendadas do Google Cloud. Confira o Centro de arquitetura do Cloud.