Esta página apresenta a ferramenta de redimensionamento automático para o Spanner (redimensionador automático), uma ferramenta de código aberto que pode usar como uma ferramenta complementar ao Spanner. Esta ferramenta permite-lhe aumentar ou reduzir automaticamente a capacidade de computação numa ou mais instâncias do Spanner com base na capacidade em utilização.
Para mais informações sobre o dimensionamento no Spanner, consulte o artigo Dimensionamento automático do Spanner. Para informações sobre a implementação da ferramenta de escalabilidade automática, consulte o seguinte:
- Implemente a ferramenta de redimensionamento automático para o Spanner nas funções do Cloud Run.
- Implemente a ferramenta de redimensionador automático para o Spanner no Google Kubernetes Engine (GKE).
Esta página apresenta as funcionalidades, a arquitetura e a configuração de alto nível do escalador automático. Estes tópicos explicam a implementação do Autoscaler num dos tempos de execução suportados em cada uma das diferentes topologias.
Redimensionador automático
A ferramenta de dimensionamento automático é útil para gerir a utilização e o desempenho das suas implementações do Spanner. Para ajudar a equilibrar o controlo de custos com as necessidades de desempenho, a ferramenta de escalamento automático monitoriza as suas instâncias e adiciona ou remove automaticamente nós ou unidades de processamento para ajudar a garantir que permanecem dentro dos seguintes parâmetros:
Mais ou menos uma margem configurável.
O dimensionamento automático das implementações do Spanner permite que a sua infraestrutura se adapte e seja dimensionada automaticamente para satisfazer os requisitos de carga com pouca ou nenhuma intervenção. O dimensionamento automático também dimensiona corretamente a infraestrutura aprovisionada, o que pode ajudar a minimizar os custos incorridos.
Arquitetura
O Autoscaler tem dois componentes principais: o Poller e o Scaler. Embora possa implementar o dimensionador automático com várias configurações em vários tempos de execução em várias topologias com várias configurações, a funcionalidade destes componentes principais é a mesma.
Esta secção descreve estes dois componentes e as respetivas finalidades mais detalhadamente.
Poller
O Poller recolhe e processa as métricas de séries cronológicas para uma ou mais instâncias do Spanner. O Poller pré-processa os dados das métricas para cada instância do Spanner, de modo que apenas os pontos de dados mais relevantes sejam avaliados e enviados para o Scaler. O pré-processamento feito pelo Poller também simplifica o processo de avaliação dos limites para instâncias do Spanner regionais, de dupla região e multirregionais.
Scaler
O Scaler avalia os pontos de dados recebidos do componente Poller e determina se tem de ajustar o número de nós ou unidades de processamento e, se for o caso, em que medida. O compara os valores das métricas com o limite, mais ou menos uma margem permitida, e ajusta o número de nós ou unidades de processamento com base no método de escalabilidade configurado. Para mais detalhes, consulte o artigo Métodos de dimensionamento.
Ao longo do fluxo, a ferramenta de escalamento automático escreve um resumo das respetivas recomendações e ações no Cloud Logging para monitorização e auditoria.
Funcionalidades do redimensionador automático
Esta secção descreve as principais funcionalidades da ferramenta de dimensionamento automático.
Faça a gestão de várias instâncias
A ferramenta de escalamento automático consegue gerir várias instâncias do Spanner em vários projetos. As instâncias multirregionais, de região dupla e regionais têm limiares de utilização diferentes que são usados durante o dimensionamento. Por exemplo, as implementações multirregionais e de duas regiões são dimensionadas com uma utilização de CPU de alta prioridade de 45%, enquanto as implementações regionais são dimensionadas com uma utilização de CPU de alta prioridade de 65%, ambas com uma margem permitida. Para mais informações sobre os diferentes limites para o dimensionamento, consulte o artigo Alertas para utilização elevada da CPU.
Parâmetros de configuração independentes
Cada instância do Spanner com escalamento automático pode ter um ou mais agendamentos de sondagem. Cada programação de sondagem tem o seu próprio conjunto de parâmetros de configuração.
Estes parâmetros determinam os seguintes fatores:
- O número mínimo e máximo de nós ou unidades de processamento que controlam o tamanho da sua instância, o que ajuda a controlar os custos incorridos.
- O método de escalabilidade usado para ajustar a sua instância do Spanner específica para a sua carga de trabalho.
- Os períodos de repouso para permitir que o Spanner faça a gestão das divisões de dados.
Métodos de dimensionamento
A ferramenta de escalabilidade automática oferece três métodos de escalabilidade diferentes para aumentar e diminuir a escala das suas instâncias do Spanner: passo a passo, linear e direta. Cada método foi concebido para suportar diferentes tipos de cargas de trabalho. Pode aplicar um ou mais métodos a cada instância do Spanner com escalamento automático quando cria horários de sondagem independentes.
As secções seguintes contêm mais informações sobre estes métodos de dimensionamento.
Passo a passo
O escalonamento gradual é útil para cargas de trabalho com picos pequenos ou múltiplos. Aprovisiona capacidade para suavizar todos os picos com um único evento de dimensionamento automático.
O gráfico seguinte mostra um padrão de carga com vários patamares ou etapas de carga, em que cada etapa tem vários picos pequenos. Este padrão é adequado para o método passo a passo.
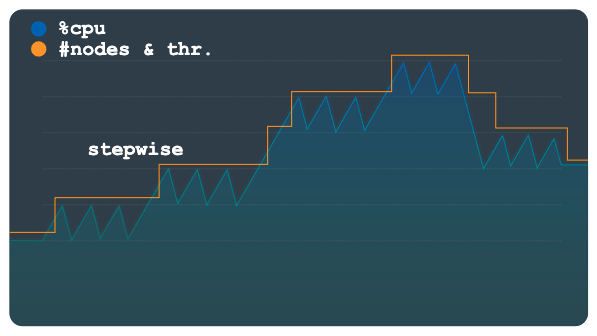
Quando o limite de carga é ultrapassado, este método aprovisiona e remove nós ou unidades de processamento através de um número fixo, mas configurável. Por exemplo, são adicionados ou removidos três nós para cada ação de escalabilidade. Ao alterar a configuração, pode permitir que sejam adicionados ou removidos incrementos maiores de capacidade em qualquer altura.
Linear
O dimensionamento linear é mais adequado para padrões de carga que mudam mais gradualmente ou têm alguns picos grandes. O método calcula o número mínimo de nós ou unidades de processamento necessárias para manter a utilização abaixo do limite de escalabilidade. O número de nós ou unidades de processamento adicionados ou removidos em cada evento de escalabilidade não está limitado a um valor de passo fixo.
O padrão de carga de exemplo no gráfico seguinte mostra aumentos e diminuições grandes e súbitos na carga. Estas flutuações não estão agrupadas em passos discerníveis, como no gráfico anterior. Este padrão pode ser melhor processado através da dimensionamento linear.

A ferramenta de escalamento automático usa a proporção da utilização observada em relação ao limite de utilização para calcular se deve adicionar ou subtrair nós ou unidades de processamento ao número total atual.
A fórmula para calcular o novo número de nós ou unidades de processamento é a seguinte:
newSize = currentSize * currentUtilization / utilizationThreshold
Direto
O escalamento direto oferece um aumento imediato da capacidade. Este método destina-se a suportar cargas de trabalho em lote em que é necessário periodicamente um número de nós superior predeterminado num agendamento com uma hora de início conhecida. Este método aumenta a escala da instância até ao número máximo de nós ou unidades de processamento especificado na programação e destina-se a ser usado além de um método linear ou passo a passo.
O gráfico seguinte representa o grande aumento planeado na carga, para o qual o escalador automático preparou previamente a capacidade para usar o método direto.
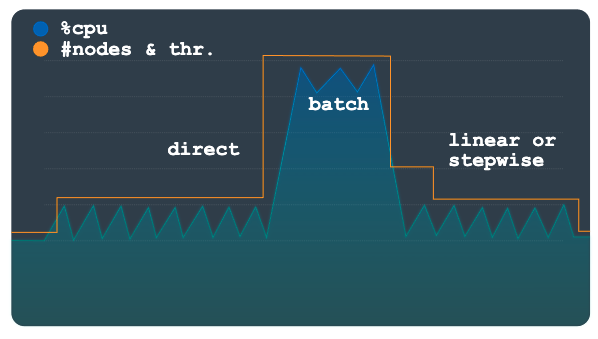
Quando a carga de trabalho em lote estiver concluída e a utilização regressar aos níveis normais, dependendo da sua configuração, é aplicada uma escalabilidade linear ou gradual para reduzir automaticamente a escala da instância.
Configuração
A ferramenta de dimensionamento automático tem diferentes opções de configuração que pode usar para gerir o dimensionamento das suas implementações do Spanner. Embora as funções do Cloud Run e os parâmetros do GKE sejam semelhantes, são fornecidos de forma diferente. Para mais informações sobre como configurar a ferramenta de dimensionamento automático, consulte os artigos Configurar uma implementação de funções do Cloud Run e Configurar uma implementação do GKE.
Configuração avançada
A ferramenta de dimensionamento automático tem opções de configuração avançadas que lhe permitem controlar com maior precisão quando e como as suas instâncias do Spanner são geridas. As secções seguintes apresentam uma seleção destes controlos.
Limites personalizados
A ferramenta de escalamento automático determina o número de nós ou unidades de processamento a adicionar ou subtrair a uma instância através dos limites recomendados do Spanner para as seguintes métricas de carga:
- CPU de prioridade elevada
- Média móvel de 24 horas da CPU
- Utilização do armazenamento
Recomendamos que use os limites predefinidos, conforme descrito no artigo Criar alertas para métricas do Spanner. No entanto, em alguns casos, pode querer modificar os limites usados pela ferramenta de ajuste automático de escala. Por exemplo, pode usar limiares mais baixos para fazer com que a ferramenta de ajuste automático reaja mais rapidamente do que para limiares mais altos. Esta modificação ajuda a evitar que os alertas sejam acionados em limites superiores.
Métricas personalizadas
Embora as métricas predefinidas na ferramenta de dimensionamento automático abordem a maioria dos cenários de desempenho e
dimensionamento, existem algumas instâncias em que pode ter de especificar as suas
próprias métricas usadas para determinar quando aumentar e diminuir a escala. Para estes cenários,
define métricas personalizadas na configuração através da propriedade
metrics.
Margens
Uma margem define um limite superior e um limite inferior em torno do limite. A ferramenta de ajuste automático só aciona um evento de ajuste automático se o valor da métrica for superior ao limite superior ou inferior ao limite inferior.
O objetivo deste parâmetro é evitar que os eventos de escalabilidade automática sejam acionados para pequenas flutuações da carga de trabalho em torno do limite, reduzindo a quantidade de flutuações nas ações do redimensionador automático. O limite e a margem definem em conjunto o seguinte intervalo, de acordo com o valor da métrica pretendido:
[threshold - margin, threshold + margin]
Quanto menor for a margem, mais estreito é o intervalo, o que resulta numa maior probabilidade de ser acionado um evento de dimensionamento automático.
A especificação de um parâmetro de margem para uma métrica é opcional e é predefinida para cinco pontos percentuais antes e abaixo do parâmetro.
Divisões de dados
O Spanner atribui intervalos de dados denominados divisões a nós ou subdivisões de um nó denominadas unidades de processamento. O nó ou as unidades de processamento gerem e publicam os dados de forma independente nas divisões atribuídas. As divisões de dados são criadas com base em vários fatores, incluindo o volume de dados e os padrões de acesso. Para mais detalhes, consulte Spanner – esquema e modelo de dados.
Os dados são organizados em divisões e o Spanner gere automaticamente as divisões. Assim, quando a ferramenta de escalamento automático adiciona ou remove nós ou unidades de processamento, precisa de dar ao back-end do Spanner tempo suficiente para reatribuir e reorganizar as divisões à medida que a nova capacidade é adicionada ou removida das instâncias.
A ferramenta de escalabilidade automática usa períodos de repouso em eventos de aumento e diminuição da escala para controlar a rapidez com que pode adicionar ou remover nós ou unidades de processamento de uma instância. Este método permite à instância o tempo necessário para reorganizar as relações entre os nós de computação ou as unidades de processamento e as divisões de dados. Por predefinição, os períodos de repouso de aumento e diminuição da escala são definidos para os seguintes valores mínimos:
- Valor de aumento: 5 minutos
- Valor de redução: 30 minutos
Para mais informações sobre as recomendações de escalabilidade e os períodos de repouso, consulte o artigo Escalar instâncias do Spanner.
Preços
O consumo de recursos da ferramenta de escalamento automático é menor em termos de computação, memória e armazenamento. Consoante a sua configuração do Autoscaler, quando implementado em funções do Cloud Run, a utilização de recursos do Autoscaler é normalmente no nível gratuito dos respetivos serviços dependentes (funções do Cloud Run, Cloud Scheduler, Pub/Sub e Firestore).
Use a Calculadora de preços para gerar uma estimativa de custo dos seus ambientes com base na utilização prevista.
O que se segue?
- Saiba como implementar a ferramenta de escalabilidade automática nas funções do Cloud Run.
- Saiba como implementar a ferramenta de redimensionamento automático no GKE.
- Leia mais acerca dos limites recomendados do Spanner.
- Leia mais acerca das métricas de utilização da CPU do Spanner e das métricas de latência.
- Saiba mais acerca das práticas recomendadas para a criação de esquemas do Spanner para evitar pontos ativos e carregar dados no Spanner.
- Explore arquiteturas de referência, diagramas e práticas recomendadas sobre o Google Cloud. Consulte o nosso Centro de arquitetura na nuvem.