AI インフラストラクチャの未来
AI インフラストラクチャの未来
AI Hypercomputer は、専用ハードウェア、オープン ソフトウェア、柔軟な使用量モデルを組み合わせたアーキテクチャです。各コンポーネントは、互いに連携して円滑に動作するよう綿密に統合されており、パフォーマンス、費用、デベロッパーの生産性を向上させます。

よりスマートで高速なトレーニング
よりスマートで高速なトレーニング
モデルを数か月ではなく数週間で構築できます。Google のトレーニング スタックを使用することで、パフォーマンスを犠牲にすることなく開発やテストを迅速化できます。

LLM のトレーニングとチューニングを高速化
Google DeepMind と共同設計されたソフトウェアと TPU 8t を組み合わせることで、LLM の開発を 36% 高速化でき、各アクセラレータから最大 97% の生産性(Goodput)を引き出すことができます。このソフトウェアは、オープンソース フレームワーク(トレーニング用の Pathways や Pallas、チューニング用の Ray や Agent Sandbox)と統合されています。また、万能なソリューションは存在しないことから、NVIDIA と緊密に連携して最新の GPU を提供しています。Google Cloud は、今年後半に提供される次世代の NVIDIA Vera Rubin NVL72 をベースにしたインスタンスをいち早く提供する予定です。
独自データを使用して軽量モデルをよりスマートにトレーニング
Gemini Enterprise Agent Platform を BigQuery と組み合わせて使用すると、データ エステート、ML 開発、アクセラレータを 1 か所にまとめることができ、独自データのモデルを 16 倍高速にトレーニングできます。G4 VM と Ironwood TPU のどちらを使用する場合でも、AI Hypercomputer が活用されます。
MuJoCo-Warp を使用して適応型の物理エージェントを構築
DeepMind の MuJoCo-Warp で GPU ベースのシミュレーションを実行すると、標準の MuJoCo より最大 100 倍高速になります。Veo、Genie、Nano Banana の合成メディアを使用して、さまざまなエッジケース(実現不可能、高リスク、高費用)をシミュレートしたり、ペタバイト規模の実世界のセンサーデータを BigQuery に取り込んだりできます。Google Cloud での物理エージェントの構築について詳しくは、こちらをご覧ください。
応答性と効率に優れた推論
応答性と効率に優れた推論
検証済みのモデル プロファイルと、完全に統合された Google およびオープン ソフトウェアを利用して、複雑さや無駄を減らしながらアプリケーションの応答性を高めます。
ほぼゼロのレイテンシで LLM をサービング
統合された推論テクノロジーを使用して、有用かつ応答性の高いサービスを顧客に提供します。GKE Inference Gateway を使用することで、最初のトークン生成までの時間を 71% 短縮できるほか、llm-d による分散型サービングで 1 秒あたり最大 12 万トークンを処理できます。また、Rapid Cache と TPU 8i を活用することでモデルの読み込み速度を 5 倍高速化でき、ワーキングメモリを必要な場所に正確に配置できます。
事前構築済みのビジュアル、知覚、メディアモデルをサービング
Gemini Enterprise Agent Platform で利用可能な 200 以上のモデルを使用することで、従来の ML モデルのデプロイを 70% 高速化できます。TPU と GPU を選択できるほか、今年後半に提供予定の A5X VM(NVIDIA Vera Rubin)や TPU 8i も利用できます。
安全かつ費用対効果の高い方法でエージェントを提供
GKE Agent Sandbox では、多数のエージェントを安全に運用できます。1 秒あたり最大 300 のサンドボックスをプロビジョニングしつつ、必要に応じて即座に一時停止や再開ができるため、アイドル状態のエージェントに対して料金が発生することはありません。
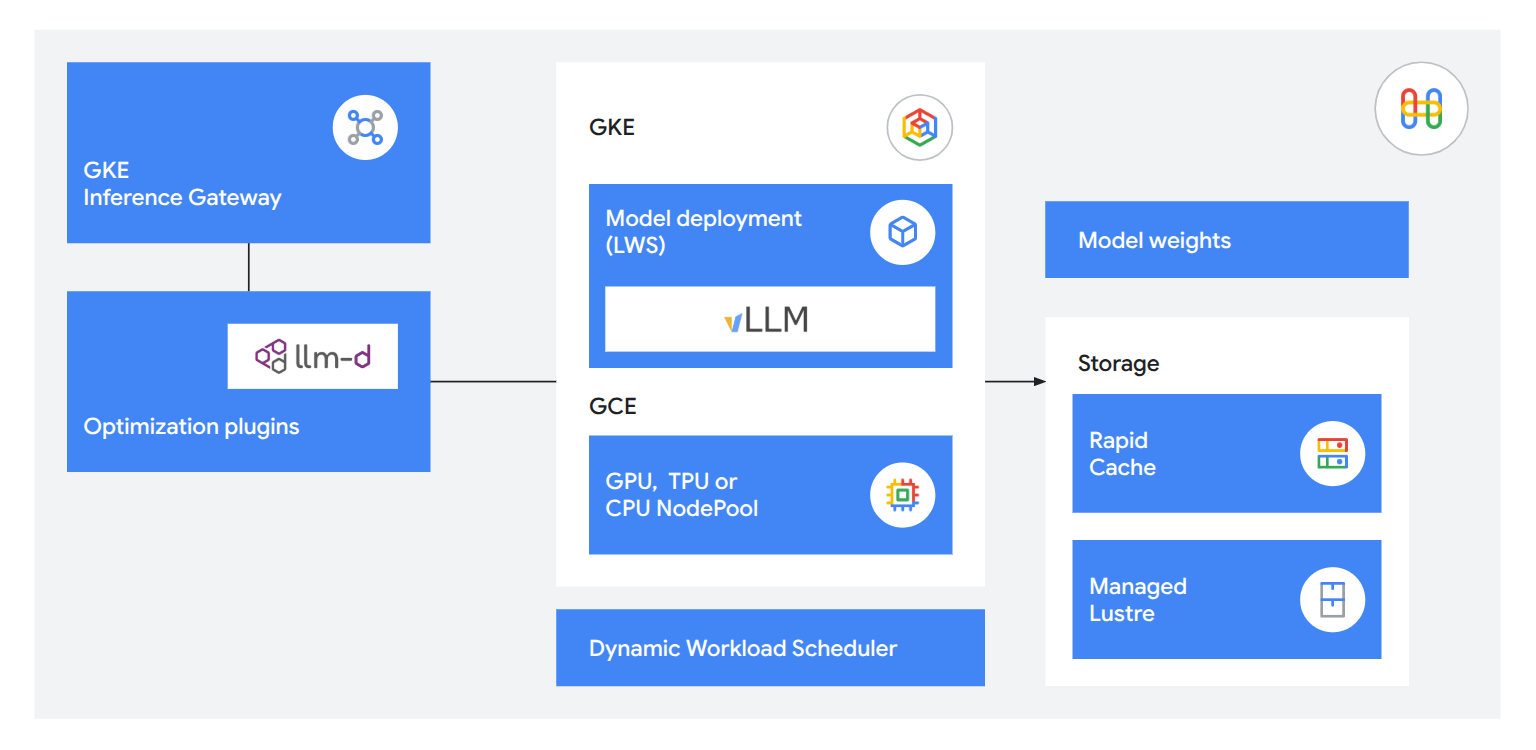
柔軟でオープン、信頼性の高い運用
柔軟でオープン、信頼性の高い運用
ハイブリッド環境とマルチクラウド環境で、あらゆるフレームワークやアクセラレータを利用できます。クラスタのメンテナンスと管理の自動化により、エクサスケールに対応します。

コードを書き換えることなく TPU と GPU を切り替え
TorchTPU はネイティブの PyTorch サポートを提供することで、TPU を短期間で理解できるようにします。デベロッパーは、複雑なコードの書き換えを行うことなく、最適なアクセラレータを利用できるようになります。
事実上あらゆる規模や環境に AI をデプロイ可能
オープンソースの Kubernetes をベースとする GKE は、エンタープライズ規模のマルチクラウド ポータビリティを実現し、最大 13 万ノードをサポートします。Agent Platform や Google Distributed Cloud とネイティブに統合されており、ハイブリッド環境へのデプロイにも対応します。
高度なクラスタ診断ツールとオブザーバビリティ ツールでクラスタ メンテナンスを自動化
AI Hypercomputer のすべてのアクセラレータは、Cluster Director 機能によってサポートされており、デプロイ前の健全性証明、360 度のオブザーバビリティ ダッシュボード、常時稼働のヘルスチェックなどを利用できます。
マルチクラウド ワークロードを数週間ではなく数分で接続
クロスクラウド ネットワークを使用すれば、接続の遅延なしにクラウド間でサービスを連携できます。クロスクラウド ネットワークは、Fortune 100 企業の 65% 以上が信頼を寄せるネットワーキング バックボーンであり、毎月 27 エクサバイト以上のデータが扱われています。
アクセラレータ容量を思いどおりに確保
Google の柔軟な使用量モデルを利用することで、アクセラレータのスケジュールを柔軟に調整し、費用を削減できます。Spot VM を使用すると、バッチジョブやフォールト トレラント ジョブで最大 91% の費用を削減できるほか、Dynamic Workload Scheduler を使用すると、開始日を柔軟に設定したジョブで最大 50% の費用を削減できます。また、確約利用割引に登録すると最大 50% の割引が適用されます。
エージェント対応システム
エージェント対応システム
Google や最先端の AI ラボが信頼するインフラストラクチャ基盤を拡張しながら、パフォーマンスの限界を押し広げつつ、責任を持ってエネルギーを利用できます。
信頼できる基盤で AI ロードマップのリスクを軽減
Google Cloud は、上位 10 の AI ラボのうち 9 つと、資金調達済みの AI スタートアップの 70% を支援しています。AI Hypercomputer にデプロイすることで、信頼性に優れたデータセンター(2025 年 12 月だけで約 350 社のお客様の 1,000 億超のトークンを確実に処理)を利用できます。
業界トップクラスのエネルギー効率を実現
AI Hypercomputer を活用した Google Cloud のデータセンターは、業界をリードするエネルギー効率を実現しており、5 年前と比較して単位電力あたりのコンピューティング能力が 6 倍になっています。これにより、第 8 世代 TPU は前世代と比較してコスト パフォーマンスが 80% 向上し、エネルギー効率が 20% 向上しています。
電力網と地域社会への影響を軽減
シリコンからエッジに至るまで、価値の高い IP を保護
Google の Titanium アーキテクチャのカスタム Titan チップは、検証可能なハードウェアのルート オブ トラストとゼロトラスト セキュリティを実現します。cloudvulndb.org の独自分析によると、Google のシステムでは、他の主要クラウドと比較して、重大な脆弱性が最大 70% 少ないことが示されています。
世界をリードするイノベーターを支援










AI Hypercomputer の詳細
- IDC: AI Hypercomputer のビジネス価値この IDC レポートでは、AI ワークロードに対する AI Hypercomputer の実際の影響について説明しています。レポートの全文を読んで、ROI が 353% 向上し、IT チームの効率が 55% 向上し、アプリケーション / ワークロードの計画外のダウンタイムが 67% 減少したことを示す顧客データをご確認ください。
所要時間: 5 分
レポートを読む - Google、Gartner® Magic Quadrant で戦略的クラウド プラットフォーム サービス部門のリーダーに選出Gartner® は、Gartner Magic Quadrant™ 戦略的クラウド プラットフォーム サービス部門のリーダーとして Google を選出しました。これで、Google は 8 年連続で選出されたことになります。さらに、今年は Google がビジョンの完全性で最も高い評価を受けるという快挙を成し遂げました。
所要時間: 5 分
結果を確認 - 「The Forrester Wave™: AI Infrastructure Solutions, Q4 2025」で Google がリーダーにGoogle は、「現在のサービス」カテゴリにおいて全ベンダーの中で最高スコアを獲得し、ビジョン、アーキテクチャ、トレーニング、推論、効率性、セキュリティなど、19 の評価基準のうち 16 の基準で最高スコアを記録しました。
所要時間: 5 分
結果を確認
- 推論スタックの設計を開始してデプロイするGKE、Cloud TPU、TensorFlow、PyTorch、JAX、Keras など、Google Cloud の推論ソリューションを構成する重要なコンポーネントについて学びます。
2 時間のコース
コースを受講する - GKE で vLLM を使用して Gemma 3 27B 推論をサービングこのチュートリアルでは、vLLM サービング フレームワークを使用して Gemma 3 27B 大規模言語モデル(LLM)をデプロイしてサービングする方法について説明します。Google Kubernetes Engine(GKE)上の単一の A4 仮想マシン(VM)インスタンスに Gemma 3 をデプロイします。
15 分間のガイド
チュートリアルを開始 - A4 GKE クラスタで Gemma 3 をファインチューニングするこのチュートリアルでは、Google Cloud 上のマルチノード、マルチ GPU GKE クラスタで Gemma 3 大規模言語モデル(LLM)をファインチューニングする方法について説明します。このクラスタは、8 個の NVIDIA B200 GPU を搭載した A4 仮想マシン(VM)インスタンスを使用します。
15 分間のガイド
チュートリアルを開始
- A4 Slurm クラスタで Qwen2 をトレーニングするこのチュートリアルでは、Google Cloud 上のマルチノード、マルチ GPU Slurm クラスタで大規模言語モデル(LLM)をトレーニングする方法について説明します。このチュートリアルで使用するモデルは、15 億のパラメータを持つ Qwen2 モデルに基づいています。Slurm クラスタは 2 つの a4-highgpu-8g 仮想マシン(VM)を使用し、各 VM には 8 個の NVIDIA B200 GPU が搭載されています。
15 分間のガイド
チュートリアルを開始 - TPU で vLLM を使用して Qwen2-7B-Instruct をサービングするこのチュートリアルでは、v6e TPU VM で vLLM TPU サービング フレームワークを使用して Qwen/Qwen2-7B-Instruct モデルをサービングします。
15 分間のガイド
チュートリアルを開始
アナリストの分析情報
- IDC: AI Hypercomputer のビジネス価値この IDC レポートでは、AI ワークロードに対する AI Hypercomputer の実際の影響について説明しています。レポートの全文を読んで、ROI が 353% 向上し、IT チームの効率が 55% 向上し、アプリケーション / ワークロードの計画外のダウンタイムが 67% 減少したことを示す顧客データをご確認ください。
所要時間: 5 分
レポートを読む - Google、Gartner® Magic Quadrant で戦略的クラウド プラットフォーム サービス部門のリーダーに選出Gartner® は、Gartner Magic Quadrant™ 戦略的クラウド プラットフォーム サービス部門のリーダーとして Google を選出しました。これで、Google は 8 年連続で選出されたことになります。さらに、今年は Google がビジョンの完全性で最も高い評価を受けるという快挙を成し遂げました。
所要時間: 5 分
結果を確認 - 「The Forrester Wave™: AI Infrastructure Solutions, Q4 2025」で Google がリーダーにGoogle は、「現在のサービス」カテゴリにおいて全ベンダーの中で最高スコアを獲得し、ビジョン、アーキテクチャ、トレーニング、推論、効率性、セキュリティなど、19 の評価基準のうち 16 の基準で最高スコアを記録しました。
所要時間: 5 分
結果を確認
チュートリアル
- 推論スタックの設計を開始してデプロイするGKE、Cloud TPU、TensorFlow、PyTorch、JAX、Keras など、Google Cloud の推論ソリューションを構成する重要なコンポーネントについて学びます。
2 時間のコース
コースを受講する - GKE で vLLM を使用して Gemma 3 27B 推論をサービングこのチュートリアルでは、vLLM サービング フレームワークを使用して Gemma 3 27B 大規模言語モデル(LLM)をデプロイしてサービングする方法について説明します。Google Kubernetes Engine(GKE)上の単一の A4 仮想マシン(VM)インスタンスに Gemma 3 をデプロイします。
15 分間のガイド
チュートリアルを開始 - A4 GKE クラスタで Gemma 3 をファインチューニングするこのチュートリアルでは、Google Cloud 上のマルチノード、マルチ GPU GKE クラスタで Gemma 3 大規模言語モデル(LLM)をファインチューニングする方法について説明します。このクラスタは、8 個の NVIDIA B200 GPU を搭載した A4 仮想マシン(VM)インスタンスを使用します。
15 分間のガイド
チュートリアルを開始
- A4 Slurm クラスタで Qwen2 をトレーニングするこのチュートリアルでは、Google Cloud 上のマルチノード、マルチ GPU Slurm クラスタで大規模言語モデル(LLM)をトレーニングする方法について説明します。このチュートリアルで使用するモデルは、15 億のパラメータを持つ Qwen2 モデルに基づいています。Slurm クラスタは 2 つの a4-highgpu-8g 仮想マシン(VM)を使用し、各 VM には 8 個の NVIDIA B200 GPU が搭載されています。
15 分間のガイド
チュートリアルを開始 - TPU で vLLM を使用して Qwen2-7B-Instruct をサービングするこのチュートリアルでは、v6e TPU VM で vLLM TPU サービング フレームワークを使用して Qwen/Qwen2-7B-Instruct モデルをサービングします。
15 分間のガイド
チュートリアルを開始



















