ポジティブな各映画評価(評価 4 以上)は、商品ページビュー イベントとして処理されます。データセット内のユーザーまたはシードの映画に基づいて映画のレコメンデーションを作成する「関連商品のおすすめ」タイプのレコメンデーション モデルをトレーニングします。
推定所要時間:
- モデルのトレーニングを開始するための最初の手順: 約 1.5 時間。
- モデルのトレーニングを待機時間: 約 2 日。
- モデル予測の評価とクリーンアップ: 約 30 分。
目標
- 商品とユーザー イベントのデータを BigQuery から小売業向け Vertex AI Search にインポートする方法を学習します。
- レコメンデーション モデルをトレーニングして評価します。
費用
このチュートリアルでは、Google Cloud の課金対象となる以下のコンポーネントを使用します。- Cloud Storage
- BigQuery
- Vertex AI Search for Retail
Cloud Storage の費用の詳細については、Cloud Storage の料金ページをご覧ください。
BigQuery の費用の詳細については、BigQuery の料金ページをご覧ください。
Vertex AI Search for Retail の小売費用の詳細については、Vertex AI Search for Retail の料金のページをご覧ください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
データセットを準備する
Google Cloud コンソールを開き、Google Cloud プロジェクトを選択します。ダッシュボード ページの [プロジェクト情報] カードのプロジェクト ID をメモします。以降の手順では、このプロジェクト ID が必要です。次に、コンソールの上部にある [Cloud Shell をアクティブにする] ボタンをクリックします。

Google Cloud コンソールの一番下にある新しいフレームの中で Cloud Shell セッションが開き、コマンドライン プロンプトが表示されます。
データセットのインポート
Cloud Shell を使用して、ソース データセットをダウンロードして展開します。
wget https://files.grouplens.org/datasets/movielens/ml-latest.zip unzip ml-latest.zipCloud Storage バケットを作成してデータをバケットにアップロードします。
gcloud storage buckets create gs://PROJECT_ID-movielens-data gcloud storage cp ml-latest/movies.csv ml-latest/ratings.csv \ gs://PROJECT_ID-movielens-dataBigQuery データセットを作成します。
bq mk movielens新しい映画 BigQuery テーブルに
movies.csvを読み込む:bq load --skip_leading_rows=1 movielens.movies \ gs://PROJECT_ID-movielens-data/movies.csv \ movieId:integer,title,genres新しい評価 BigQuery テーブルに
ratings.csvを読み込む:bq load --skip_leading_rows=1 movielens.ratings \ gs://PROJECT_ID-movielens-data/ratings.csv \ userId:integer,movieId:integer,rating:float,time:timestamp
BigQuery ビューを作成する
ムービーテーブルを小売商品カタログ スキーマに変換するビューを作成します。
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' SELECT CAST(movieId AS string) AS id, SUBSTR(title, 0, 128) AS title, SPLIT(genres, "|") AS categories FROM `PROJECT_ID.movielens.movies`' \ movielens.productsこれで、新しいビューには小売業向け Vertex AI Search で想定されるスキーマが含まれるようになりました。次に、左側のサイドバーで [
BIG DATA -> BigQuery] を選択します。次に、左側のエクスプローラ バーでプロジェクト名を展開し、movielens -> productsを選択してこのビューのクエリページを開きます。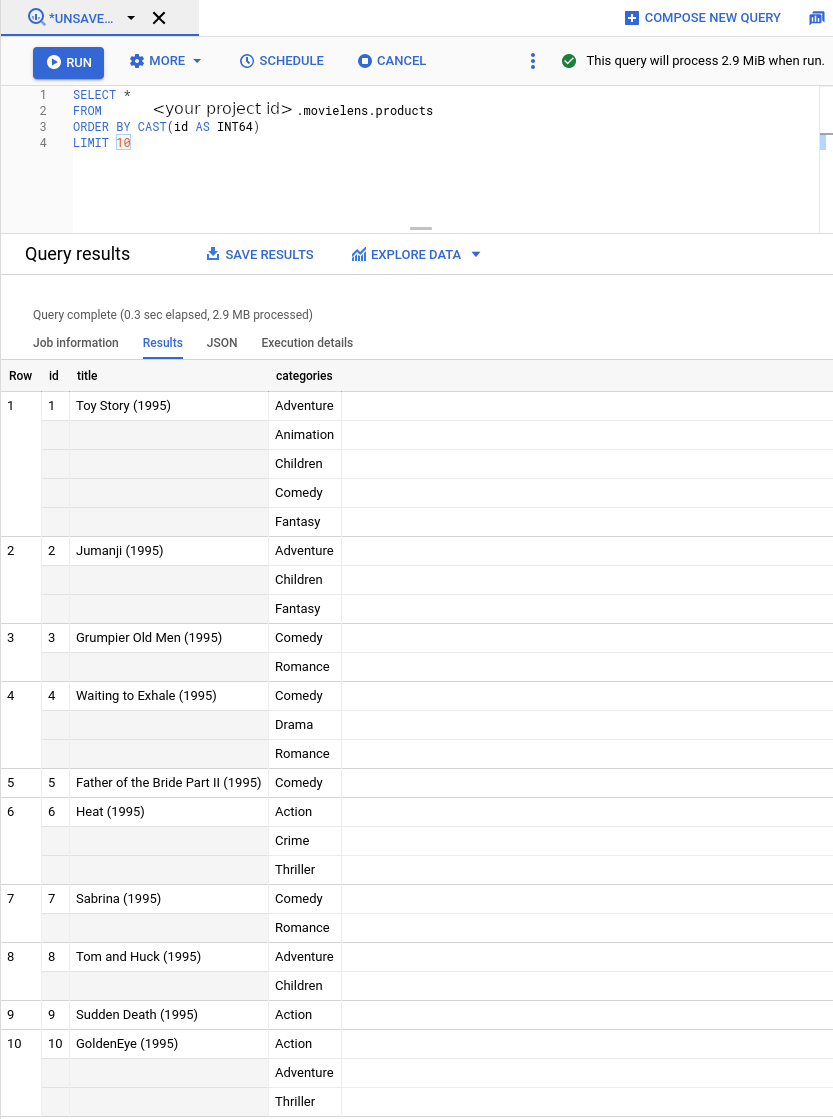
次に、映画の評価をユーザー イベントに変換します。以下を実施します。
- 除外映画の評価を無視する(4 以上)
- すべてのポジティブな評価を商品ページビュー イベントとして処理(
detail-page-view) - Movielens のタイムラインを過去 90 日間に再スケーリングします。これには 2 つの理由があります。
- 小売業向け Vertex AI Search では、ユーザー イベントが 2015 年以降のものであることが必要です。Movielens の評価付けは 1995 年までさかのぼります。
- 小売業向け Vertex AI Search では、ユーザーの予測リクエストを処理する際に、過去 90 日間のユーザー イベントを使用します。後でユーザーに対して予測を行う際に、すべてのユーザーに最近のイベントが存在するものとして表示されます。
BigQuery ビューを作成します。次のコマンドは、上記の変換要件を満たす SQL クエリを使用します。
bq mk --project_id=PROJECT_ID \ --use_legacy_sql=false \ --view ' WITH t AS ( SELECT MIN(UNIX_SECONDS(time)) AS old_start, MAX(UNIX_SECONDS(time)) AS old_end, UNIX_SECONDS(TIMESTAMP_SUB( CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) AS new_start, UNIX_SECONDS(CURRENT_TIMESTAMP()) AS new_end FROM `PROJECT_ID.movielens.ratings`) SELECT CAST(userId AS STRING) AS visitorId, "detail-page-view" AS eventType, FORMAT_TIMESTAMP( "%Y-%m-%dT%X%Ez", TIMESTAMP_SECONDS(CAST( (t.new_start + (UNIX_SECONDS(time) - t.old_start) * (t.new_end - t.new_start) / (t.old_end - t.old_start)) AS int64))) AS eventTime, [STRUCT(STRUCT(movieId AS id) AS product)] AS productDetails, FROM `PROJECT_ID.movielens.ratings`, t WHERE rating >= 4' \ movielens.user_events
商品カタログとユーザー イベントをインポートする
これで、商品カタログとユーザー イベントデータを小売業向け Vertex AI Search にインポートする準備が整いました。
Google Cloud プロジェクトで 小売業向け Vertex AI Search API を有効にします。
[Get started] をクリックします。
Search for Retail コンソールの [データ] ページに移動します。
[データ] ページに移動[インポート] をクリックします。
商品カタログをインポートする
上で作成した BigQuery ビューから商品をインポートするには、次のようにフォームに入力します。
- インポート タイプとして [商品カタログ] を選択します。
- デフォルトのブランチ名を選択します。
- データのソースとして [BigQuery] を選択します。
- データのスキーマとして [小売商品スキーマ] を選択します。
上記(
PROJECT_ID.movielens.products)で作成した商品 BigQuery ビューの名前を入力します。
[インポート] をクリックします。
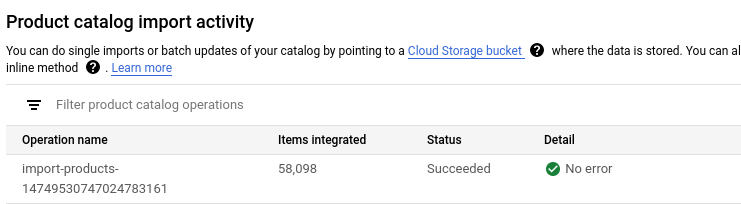
すべての商品がインポートされるまで待ちます。(所要時間 5~10 分)
インポート オペレーションのステータスは、インポート アクティビティで確認できます。インポートが完了すると、インポート オペレーションのステータスが [Succeeded] に変わります。
ユーザー イベントのインポート
user_events BigQuery ビューをインポートします。
- インポートのタイプとして [User Events] を選択します。
- データのソースとして [BigQuery] を選択します。
- データのスキーマとして [小売ユーザー イベント スキーマ] を選択します。
- 上で作成した
user_eventsBigQuery ビューの名前を入力します。
[インポート] をクリックします。
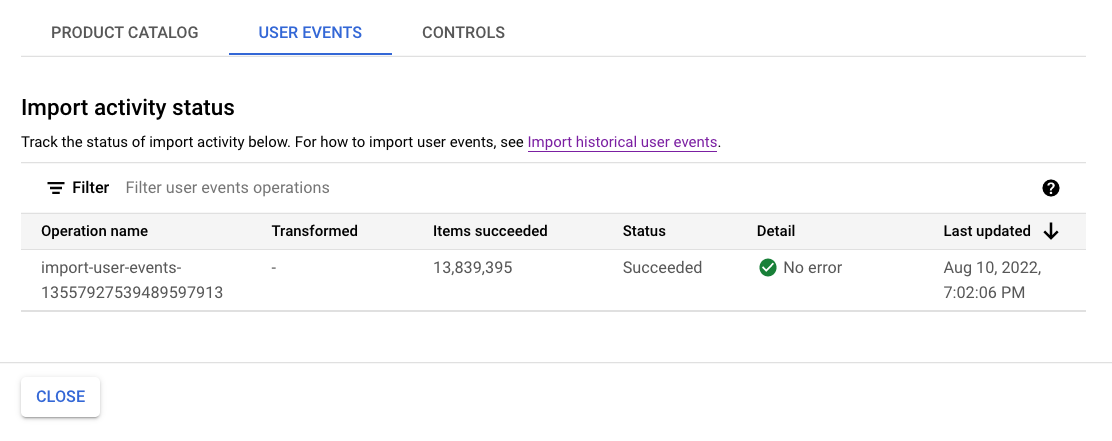
新しいモデルのトレーニングに対するデータ要件を満たすには、少なくとも 100 万件のイベントがインポートされるのを待ってから次の手順に進んでください。
オペレーションのステータスは、インポート アクティビティで確認できます。プロセスが完了するまでに約 1 時間を要します。
レコメンデーション モデルをトレーニングして評価します
レコメンデーション モデルを作成する
Search for Retail コンソールの [モデル] ページに移動します。
[モデル] ページに移動[モデルを作成] をクリックします。
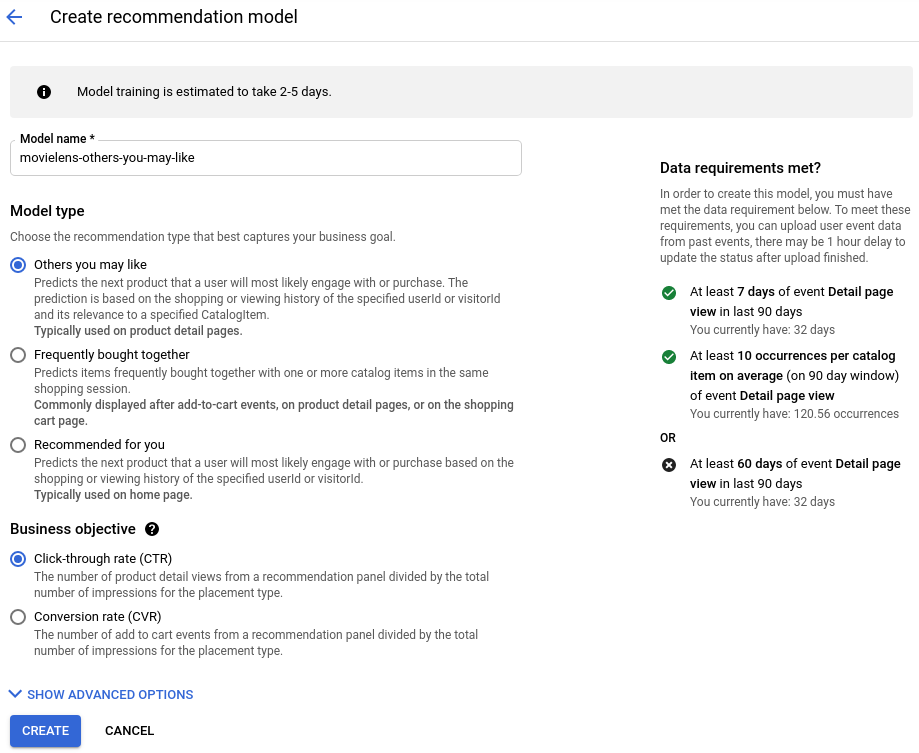
- モデルに名前を付けます。
- モデルタイプとして [関連商品のおすすめ] を選択します。
- ビジネス目標として [Click-through rate (CTR)] を選択します。
[作成] をクリックします。
新しいモデルのトレーニングを開始します。
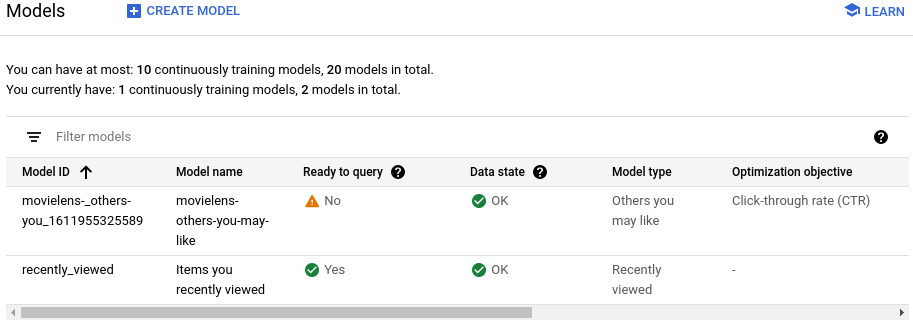
サービス構成を作成する
Search for Retail コンソールの[サービス構成]ページに移動します。
[サービス構成] ページに移動[Create serving config] をクリックします。
- [Recommendation] を選択します。
- サービス提供構成に名前を付けます。
- 作成したモデルを選択します。
[作成] をクリックします。
モデルが「クエリの準備完了」になるのを待つ
モデルがトレーニングを行いクエリの準備が完了するまでに約 2 日間を要します。
ステータスを表示するには、[サービス構成] ページで作成されたサービス構成をクリックします。
[Model ready to query] フィールドには、プロセスが完了している場合には [Yes] と表示されます。
レコメンデーションをプレビューする
モデルでクエリの準備が完了したら、次の手順を行います。
-
Search for Retail コンソールの[サービス構成]ページに移動します。
[サービス構成] ページに移動 - サービス提供構成名をクリックして詳細ページに移動します。
- [Evaluate] タブをクリックします。
シードの映画 ID を入力してください。たとえば、「ロード・オブ・ザ・リング: 旅の仲間(2001)」の場合は、
4993になります。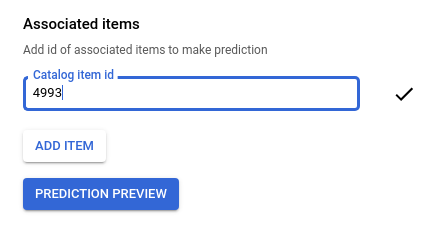
[予測のプレビュー] をクリックすると、ページの右側におすすめのアイテムのリストが表示されます。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトを削除する
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
リソースを個別に削除する
[サービス構成] ページに移動し、作成したサービス提供構成を削除します。
[Models] ページに移動し、モデルを削除します。
Cloud Shell で BigQuery データセットを削除します。
bq rm --recursive --dataset movielensCloud Storage バケットとその内容を削除します。
gcloud storage rm gs://PROJECT_ID-movielens-data --recursive