MySQL 的性能优化提示
性能优化是管理任何数据库的一个重要方面。您可以在数据库管理的每一步都执行性能优化,从选择用于托管数据库服务器的硬件和软件组件,到数据模型设计和架构配置。本文档介绍了有关云端 MySQL 数据库(具体而言,即 Cloud SQL for MySQL)的性能优化提示,包括实例化新数据库和优化现有数据库的最佳实践。
硬件注意事项
硬件配置是数据库性能的重要考虑因素。在定义硬件配置之前,请务必充分了解应用的活跃用户数和并发用户数、数据库和索引的大小,以及应用或服务的预期延迟时间。以下是一些重要的硬件注意事项:
中央处理器 (CPU)
处理能力是高性能数据库系统中最重要的因素之一。并发连接数/用户数/线程数决定了处理数据库请求所需的核心数。分配给数据库的 CPU 需要能够处理正常工作负载和峰值(极端)工作负载,以便应用以最佳水平运行。
使用 Google Cloud 的全托管式 MySQL 产品 Cloud SQL 时,CPU 以虚拟 CPU (vCPU) 的形式分配。分配给数据库的 vCPU 的数量最终决定了数据库实例的内存容量和网络吞吐量,因为每个 vCPU 拥有分配给它的最大内存量,甚至网络吞吐量也取决于 vCPU 的数量。Cloud SQL 可让您灵活地调整实例的 vCPU 数量,从而轻松满足应用的内存和网络吞吐量要求。
内存
在确定要为数据库分配的内存量时,一个重要的考虑因素是确保工作集适合缓冲区池。工作集是指数据库在任意时刻主动使用的数据。分配的内存应足以容纳此工作集或频繁访问的数据,其中通常包含数据库数据、索引、会话缓冲区、字典缓存和哈希表。检查是否已分配足够内存的一种方法是检查数据库中的磁盘读取状态。理想情况下,在正常工作负载条件下,磁盘读取次数应较少或极少。
如果分配给实例的内存不足,则实例可能会遇到“内存不足”问题,这些问题会导致数据库实例重启以及数据库或应用停机。
存储空间
数据库存储是在性能优化方面发挥重要作用的另一个组件。Cloud SQL 提供 2 种存储空间
- SSD(默认)
- HDD
SSD 提供比 HDD 更好的性能和吞吐量。因此,始终选择 SSD 以获得更好的性能,尤其是用于生产工作负载。
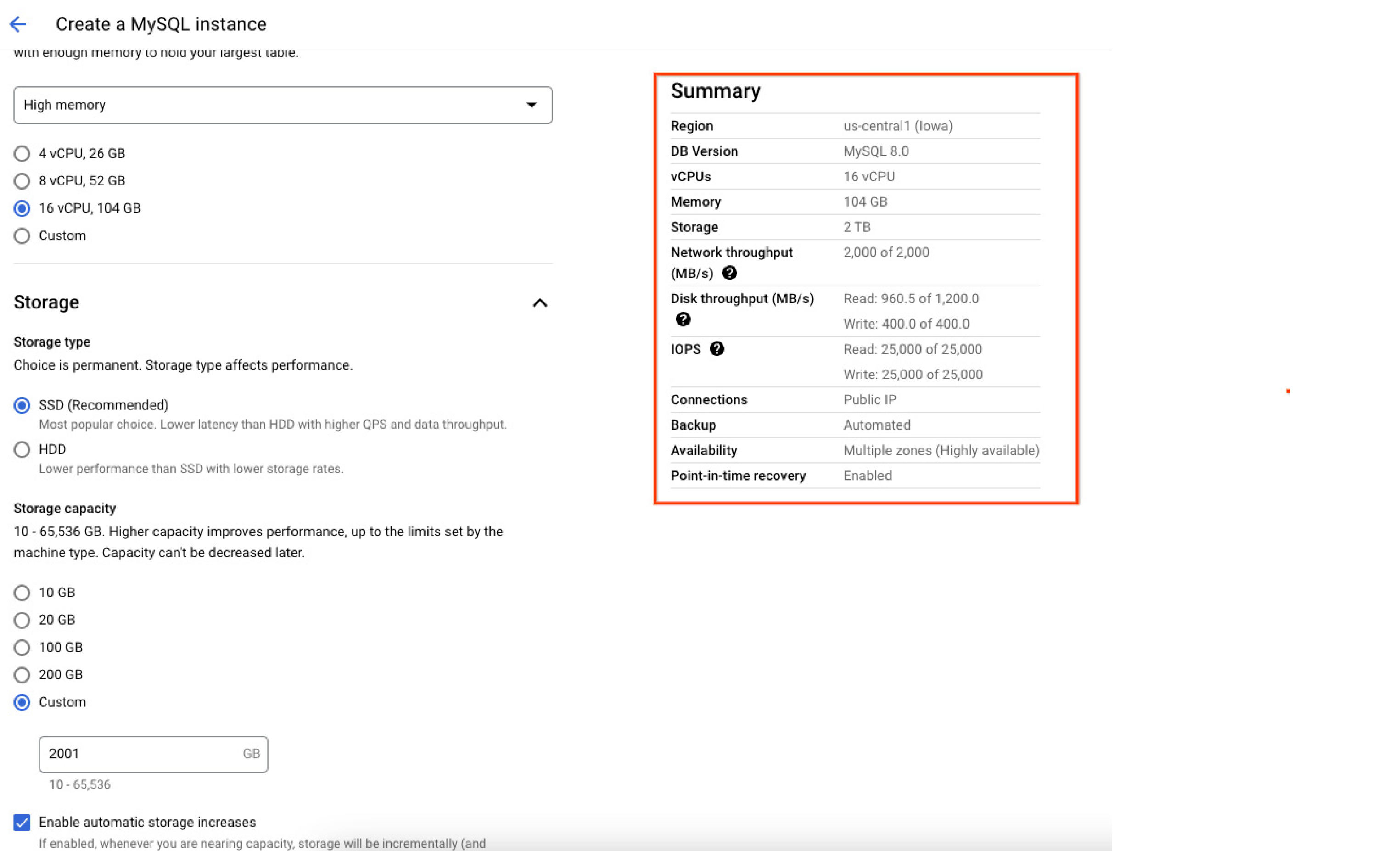
分配给实例的每秒读写输入/输出操作数 (IOP) 取决于创建实例时分配的存储空间大小。磁盘大小越大,读写 IOPS 就越高。因此,建议您创建数据大小更大的实例,以获得更好的 IOPS 性能。以下 Google Cloud 控制台屏幕截图显示了创建数据库实例时分配给数据库实例的资源(包括最大容量)摘要,可帮助用户确认并准确了解在数据库实例化后,将如何配置数据库。
区域
减少网络延迟的方法之一是选择距离应用或服务最近的实例区域。所有 Google Cloud 区域都提供 Cloud SQL for MySQL,这使得用户可以在尽可能靠近最终用户的位置更轻松地实例化数据库。
弹性扩缩
Cloud SQL 提供了一种简单的方法,可用于纵向扩容或纵向缩容分配给数据库实例的资源(CPU、内存或存储空间)。这对于具有不同资源需求的工作负载非常有用。例如,用户可以在工作负载需求增加期间增加(纵向扩容)资源,然后在工作负载高峰期结束时纵向缩容资源。
MySQL 配置
本部分介绍了 MySQL 数据库配置的最佳做法,这些做法可帮助您提高性能。
版本
创建新数据库时,选择最新版本的 MySQL。最新版本包含 bug 修复和优化,与旧版本相比提高了性能。Cloud SQL 提供市场上可用的最新版 MySQL,并在创建新数据库时将其设为默认版本。详细了解 Cloud SQL 支持的 MySQL 版本。
InnoDB 缓冲区池大小
MySQL 实例仅支持一种存储引擎:InnoDB。Innodb 缓冲区池大小是用户为获得最佳性能而想要定义的第一个参数。缓冲区池是分配的内存区域,用于存储表缓存、索引缓存、刷新前修改的数据以及自适应哈希索引 (AHI) 等其他内部结构。
Cloud SQL 会根据实例大小定义要为 InnoDB 缓冲区池分配的实例内存的默认值(约为 72%),默认值因实例大小而异。如需了解详情,请参阅不同实例大小的缓冲区池设置。Cloud SQL 可让您根据应用需求使用数据库标志灵活地修改缓冲区池大小。
应调整缓冲区池大小,确保实例上有足够的可用内存供会话缓冲区、字典缓存、performance_schema 表(如果已启用)和 InnoDB 缓冲区池一起使用。
用户可以查看实例发生的磁盘读取,从而确定从磁盘读取的数据量与从缓冲区池读取的数据量。如果存在更多的磁盘读取,则增加缓冲区池大小和实例内存可以提高读取查询的性能。
重做日志/InnoDB 日志文件大小
InnoDB 日志文件或重做日志会记录表数据的数据更改。InnoDB 日志文件大小定义了单个重做日志文件的大小。
对于具有较高重做日志大小的写入繁重的工作负载,可以为写入提供更多空间,而无需执行频繁的检查点刷新活动并节省磁盘 I/O,从而提高写入性能。重做日志的总大小,可以计算为 (innodb_log_file_size * innodb_log_files_in_group),在数据库访问繁忙的时候,应该足够容纳至少 1-2 小时的写入数据。innodb_log_file_sizeinnodb_log_file_size
Cloud SQL 定义了默认值为 512 MB。Cloud SQL 还可以使用数据库标志灵活地增加 InnoDB 日志文件大小。
注意:增加 InnoDB 日志文件大小的值会增加崩溃恢复时间。
耐用性
innodb_flush_log_at_trx_commitinnodb_flush_log_at_trx_commit 标志可控制日志数据刷新到磁盘的频率,以及是否针对每次事务提交刷新。
通过将 innodb_flush_log_at_trx_commitinnodb_flush_log_at_trx_commit 的值更改为 0 或 2,可提高读取副本的写入性能。
Cloud SQL 不支持更改 Cloud SQL 主实例的耐用性设置。但是,Cloud SQL 允许更改读取副本上的标志。降低读取副本的耐用性可提高副本的写入性能。这有助于解决副本的复制延迟问题。详细了解 innodb_flush_log_at_trx_commit。
InnoDB 日志缓冲区大小
InnoDB 日志缓冲区大小是 InnoDB 用于写入日志文件(重做日志)的缓冲区量。
如果数据库中的事务(插入、更新或删除)很大,并且使用的缓冲区超过 16 MB,则 InnoDB 需要在提交事务之前执行磁盘 IO,这会影响性能。为避免磁盘 IO,请提高 innodb_log_buffer_size 的值。
Cloud SQL 为 InnoDB 日志缓冲区空间定义了默认值 16 MB。MySQL 状态变量 innodb_log_waits 显示的是 innodb_log_buffer_size 较小且 InnoDB 必须等待刷新操作发生后才提交事务的次数。如果 innodb_log_waits 的值大于 0 且在增大,请使用数据库标志提高 innodb_log_buffer_size 的值,以提高性能。您可以通过在 MySQL shell (CLI) 中运行以下查询来确定 innodb_log_buffer_size 和 innodb_log_waits 的值。这些查询会显示 MySQL 中状态变量和全局变量的值。
SHOW GLOBAL VARIABLES LIKE 'innodb_log_buffer_size';
SHOW GLOBAL STATUS LIKE 'innodb_log_waits';
InnoDB IO 容量
InnoDB IO 容量定义了可用于后台任务的 IOPS 数量(例如,来自缓冲区池的页面刷新以及来自更改缓冲区的合并数据)。
Cloud SQL 为 innodb_io_capacityinnodb_io_capacity 定义了 5,000 的默认值,为 innodb_io_capacity_maxinnodb_io_capacity 定义了 10,000 的默认值。
此默认设置最适合大多数工作负载,但是如果工作负载是写入密集型工作负载或实例上未应用的更改很多,并且实例上有足够的 IOPS,请考虑增加 innodb_io_capacity和 innodb_io_capacity。您可以在 MySQL shell 中使用以下查询找到所应用更改的值:
mysql -e 'show engine InnoDB status \G;' | grep Ibuf
会话缓冲区
会话缓冲区是为各个会话分配的内存。如果您的应用或查询包含大量插入、更新、排序、联接且需要更高的缓冲区,则在特定会话中运行查询时定义高缓冲区值可避免性能开销。用户可以防止全局级别的缓冲区分配过多,这会增加所有连接的值,进而增加实例的总内存用量。更改以下缓冲区的默认值有助于提高查询性能。您可以使用数据库标志更改这些值。
请注意,这些是每个会话的缓冲区值,提高限制可能会影响所有连接,并最终可能导致整体内存用量增加。
Table_open_cache 和 Table_definition_cache
如果数据库实例(单个或多个数据库)中的表过多(超过数千个),请增加 table_open_cache 和 table_definition_cache 的值以加快打开表的速度。table_open_cachetable_open_cache
Table_definition_cache 可加快表的打开速度,并且每个表只有一个条目。表定义缓存占用的空间较少,不使用文件描述符。如果字典对象缓存中的表实例数超过了 table_definition_cache 限制,则 LRU 机制会开始标记要逐出的表实例,并最终将其从字典对象缓存中移除,以便为新表定义腾出空间。每次打开新的表空间时都会执行此过程。只有非活跃表空间会被关闭。此逐出过程会减慢表的打开速度。
Table_open_cachetable_open_cache 定义了所有线程的打开表的数量。您可以通过检查 Opened_tables 状态变量来确认是否需要增加表缓存。如果 Opened_tables 的值很大,而且您不经常使用 FLUSH TABLES,请考虑增加 table_open_cache 变量的值。
可以将 table_open_cacheTable_open_cache 和 table_definition_cacheTable_open_cache 设置为实例中的实际表数。详细了解 Cloud SQL high-number-of-open-tables Recommender。
注意:Cloud SQL 提供了更改这些值的灵活性。
架构建议
始终定义主键
为表定义主键可按物理方式组织数据,以便于更快地查找、检索和排序记录,从而提升性能。
最好是使用自动递增的整数值主键非常适合 OLTP 系统。
主键缺失也是导致基于行的复制场景的复制延迟的主要原因之一。
创建索引
创建索引有助于加快数据检索速度,从而提高读取查询的性能。为查询的 WHERE、ORDER BY 和 GROUP BY 子句中使用的列创建索引。
注意:索引过多或未使用也可能影响数据库的性能。
性能优化最佳实践
运行基准
运行性能测试或基准测试,了解配置是最佳的还是可以通过调整硬件、MySQL 数据库或架构设计的配置来进一步改进。一次更改一个参数,并对照基准测试结果进行检查,查看是否有改进。
连接池
连接池是一种创建和管理连接池的技术,可供任何需要它们的进程使用。连接池可显著提高应用的性能,同时减少总体资源用量。在如何管理应用的连接(包括连接计数和超时)上查看详细信息。
将读取工作负载分发到读取副本
读取副本(多个副本,跨可用区)可用于从主实例中分流读取工作负载。这将减少主实例的开销或负载,进而提高主实例的性能。此外,更多资源可用于读取副本上的读取查询。
ProxySQL 是一种高性能的开源 MySQL 代理,能够路由数据库查询,可用于横向扩容 Cloud SQL for MySQL 数据库。
避免长时间运行的查询
已知运行几分钟或几小时的查询会导致性能下降。
- 撤消日志用于存储已更改行的旧版本,以便回滚事务并在事务中提供一致的读取(数据快照)。这些撤消日志以链接列表的形式存储,最新版本指向旧版本,旧版本进一步指向更旧的版本,依此类推。长时间运行的事务往往会延迟完全清除撤消日志,因此撤消日志的列表会增加。InnoDB 必须遍历大量撤消日志和冗长的链接列表,这降低了性能。
- 长时间运行的查询还会消耗资源(例如内存、缓冲区和锁),这些资源长时间未被释放,并且会因资源不足而影响其他查询。
避免大型事务
在单个事务中对记录进行过多更改(更新、删除、插入)将占用过多记录的资源(锁、缓冲区)。它可能会溢出日志缓冲区,从而导致磁盘 IO。剩余查询将必须等待资源或锁被释放。这会导致缓冲区池中的数据过多,从而阻止进一步使用缓冲区池。此类大型事务的回滚也会降低数据库的性能。为克服此问题,建议将大型事务拆分为多个小型且运行速度更快的事务。
优化查询
始终优化查询以获得最佳结果,即减少资源和加快执行速度。查看关于 MySQL 查询调优的建议。
性能微调工具
监控
监控
Cloud SQL 为多个 Google Cloud 产品提供预定义的信息中心,包括默认的 Cloud SQL 监控信息中心。用户可以使用此信息中心来监控主实例和副本实例的整体健康状况。用户也可以创建自己的自定义信息中心来显示自己感兴趣的指标。借助这些信息中心和指标,您可以使用前面列出的建议来识别和解决各种性能瓶颈(例如高 CPU 或高内存使用率)。您还可以根据这些指标配置警报。
慢查询标志
慢查询标志
您可以在 Cloud SQL for MySQL 实例上启用慢查询标志,以识别执行时间超过 long_query_time 的查询。可以进一步分析和调整这些运行缓慢的查询以提高性能。了解如何启用和检查 Cloud SQL 实例的慢查询。
Query Insights
Query Insights
Query Insights 是 Cloud SQL 的原生功能,可以在其中分析查询以提高查询的性能。Query Insights 支持直观监控并提供诊断信息,帮助您不仅仅在检测的范围内确定性能问题的根本原因。
相关产品和服务
Google Cloud 提供旨在满足您业务需求的托管式 MySQL 数据库,可以完成包括弃用本地数据中心、运行 SaaS 应用和迁移核心业务系统在内的各种任务。











