MySQL のバックアップと復元
予期しない事態が発生すると、ビジネスが影響を受ける可能性があります。ハードウェアの障害、データベースの破損、ユーザーのミス、さらには悪意のある攻撃によって、データ損失のリスクが生じる可能性があります。データベースをバックアップすることで、何か問題が発生した場合でも、ビジネスを復旧させ、運用を継続できます。また、問題がなければ、データベースのバックアップを使用してデータベースを過去の特定の時点に復元することで、コンプライアンスと監査の要件を満たすことができます。
MySQL はデータベースをバックアップするために複数の方法をサポートしていますが、それぞれに異なる長所があります。ニーズに合わせ、最適な方法を自由に組み合わせて選択できます。
バックアップの種類
MySQL データベースをバックアップする方法は、主に、物理バックアップと論理バックアップの 2 つがあります。物理バックアップによって実際のデータファイルがコピーされ、論理バックアップによって、データを再作成できる CREATE TABLE や INSERT などのステートメントが生成されます。
物理バックアップ
物理バックアップには、ディスク上に存在するすべてのファイルとディレクトリの生のコピーが含まれます。この種類のバックアップでは、論理バックアップと比較して RAW ファイルのコピーの方がはるかに高速であるため、大規模なデータベースに適しています。
メリット:
- 物理バックアップはシンプルで効率的です。実行するために多くのメモリや多くの CPU サイクルを必要としません
- 物理バックアップの場合、RAW ファイルを生成するために追加の作業は必要ありません。必要なことは、未加工のファイルとディレクトリをバックアップ用の場所にコピーすることだけです。
- MySQL では、データベース オブジェクトを再作成してデータをインポートする必要がないため、物理バックアップは論理バックアップよりも復元が高速です。
デメリット:
- 物理バックアップの場合は、InnoDB のテーブルスペース(共有され、テーブル .ibd ファイルに従い、通常は断片化されたスペースがあります)に加え、トランザクション ログやアンドゥーログなどを含むため、論理バックアップよりもはるかに多くの容量を使用することが大半です。
- 物理バックアップは、異なるプラットフォーム、オペレーティング システム、MySQL バージョンへ常に移せるとは限りません。
- 物理バックアップは RAW ファイルをコピーするため、それらに基盤となる破損がある場合、バックアップ ファイルにもコピーされます。
MySQL エコシステム全体で一般的な物理バックアップ ツール
論理バックアップ
論理バックアップには、MySQL が SQL または区切りテキストとして解釈できる形式でデータベースのデータが含まれています。これはデータベースを一連の SQL ステートメントとして表現したもので、これを実行してデータベース オブジェクトの再作成やデータのインポートを行います。論理バックアップは物理バックアップよりも復元にかなり時間がかかるため、小規模なデータベースに適しています。このバックアップの種類は、クラウドでのマネージド データベース サービスに移行する場合や、そこから移行する場合に役立ちます。
メリット:
- 論理バックアップは非常に柔軟なものです。サーバーレベル(すべてのデータベース)、データベース レベル(特定のデータベース内のすべてのテーブル)、テーブルレベル、さらには行レベル(WHERE 条件に一致するテーブル行)で、バックアップと復元オペレーションを細かく制御できます。
- 論理バックアップは、復元が簡単です。バックアップ ファイルを mysql クライアントにパイプで渡し、LOAD DATA ステートメントまたは mysqlimport コマンドを使用して、テキスト区切りファイルを読み込みます。
- 論理バックアップは別のマシンからリモートで実行できるため、ネットワークを介してデータベースのバックアップと復元を行えます。これは、ユーザーが仮想マシンに直接アクセスできない Google Cloud SQL、Amazon RDS、Microsoft Azure などのクラウド データベースでたいへん役立ちます。
- 論理バックアップはデータの破損を回避する効果があります。物理バックアップは破損することがあり、その場合、検証されるまで通知されない可能性があります。通常、論理バックアップはテキスト ファイルであるため、テキスト エディタで確認して破損を特定することが簡単に行えます。論理バックアップが破損することはほとんどありません。
- 物理バックアップとは異なり、論理バックアップは、プラットフォーム、オペレーティング システム、MySQL のバージョン間でのポータビリティに優れています。
- 論理バックアップは圧縮性に優れています。
デメリット:
- 論理バックアップは、MySQL サーバーにクエリを実行してスキーマと行を取得してから論理形式に変換する必要があるため、作成に時間がかかります。
- また、MySQL ではテーブルの作成、行のインポート、インデックスの再構築のために SQL ステートメントを実行する必要があるため、論理バックアップでは復元も遅くなります。
- 物理バックアップと比較して、論理バックアップはバックアップと復元の操作により多くのサーバー リソース(CPU、RAM、ディスク I/O)を必要とします。
一般的な論理バックアップ ツール
ポイントインタイム リカバリ(PITR)
その名が示すように、ポイントインタイム リカバリは、インスタンスを特定の時点に復元するためのものです。たとえば、エラーによってデータが失われた場合、エラーが発生する前の状態にデータベースを復旧できます。
PITR は 2 段階のプロセスで、バイナリログに依存します。
- 完全な物理または論理バックアップを復元して、サーバーをバックアップ時と同じ状態にする
- バイナリログを適用して、バックアップの時点と目的の時点との間の変更を再生する
バイナリログには、テーブルの作成、行の挿入 / 更新 / 削除など、データベース インスタンスに加えた変更が含まれます。たとえば、毎日のバックアップが午前 6 時で、午前 10 時 15 分までインスタンスを回復したいとします。午前 10 時 15 分に状態を復元するには、まず午前 6 時から完全バックアップを復元してから、午前 6 時から午前 10 時 15 分までバイナリ ログイベントを再生します。これにより、サーバーは望ましいタイミングで望ましい状態になります。
レプリケーションと PITR にはバイナリログが必要で、それはベースとなるデータと同じくらい重要です。バイナリログを復元計画で活用するには、リアルタイムでバックアップする必要があり、ログは mysqlbinlog コマンドを使用してダウンロードできます。
例:
mysqlbinlog --host=<ホスト名> --port=<ポート> --user=<ユーザー> --password=<パスワード> --read-from-remote-server --raw --stop-never <binlog_filename> |
<binlog_filename> が最初にダウンロードされるファイルになり、その後 mysqlbinlog は次のファイルに自動的に切り替わります。そうしたバイナリログは、mysqlbinlog コマンドを実行するサーバーの現在のディレクトリに書き込まれます。ファイル名と場所は、--result-file オプションを使用して変更できます。また、--stop-never オプションを使用して、mysqlbinlog binlog をサーバーに接続したままにし、書き込まれた新しい変更をダウンロードすることもできます。
リモート サーバーに接続し、書き込まれたバイナリログをダウンロードする方法については、mysqlbinlog のマニュアルに詳しく説明されています。
Cloud SQL for MySQL でのバックアップと復元
Cloud SQL は、Google Cloud の MySQL 用マネージド データベース サービスとして、データ保護を目的とする自動バックアップとポイントインタイム リカバリ(PITR)を提供します。これらはデフォルトで有効になっており、Cloud SQL for MySQL インスタンスで高可用性(HA)を可能とするために必要です。
Cloud SQL バックアップは、バックアップが Persistent Disk(PD)上に作成されたスナップショットとなるため、物理バックアップの一種です。Cloud SQL は、バックアップを自動的に行う柔軟性を備えています。また、いつでもオンデマンドでバックアップすることも可能です。論理バックアップは、マネージド バックアップを中断することなく、標準の MySQL 論理バックアップ ツール(mysqldump、mydumper、mysqlpump など)を使用して引き続き取得できます。
Cloud SQL のバックアップの仕組みについて詳しく見てみましょう。
Cloud SQL スナップショットについて
Cloud SQL では、ストレージに Persistent Disk(PD)を使用します。すべての Cloud SQL インスタンスには、データベース ファイルやディレクトリを保存するために永続ディスクがアタッチされています。
Cloud SQL は、バックアップに PD スナップショットを使用し、そのスナップショットは特定の時点におけるデータディスクの状態を参照します。PD の最初のスナップショットは、PD のすべてのデータを含む完全なスナップショットであり、後続のスナップショットは増分で、前のスナップショット以降の新しいデータまたは変更されたデータのみが含まれます。これらのスナップショットは、クラウド管理された永続データディスクの物理コピーと考えることができます。また、PITR を含む Cloud SQL のすべてのバックアップと復元機能の基礎となります。
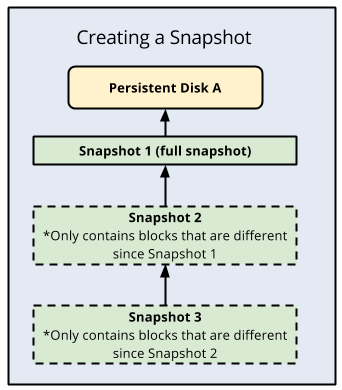
Cloud SQL バックアップ
Cloud SQL は、自動バックアップとオンデマンドの 2 種類のマネージド バックアップを実行します。デフォルトでは、どちらのタイプもインスタンスに最も近いマルチリージョン ロケーションに保存されます。たとえば、Cloud SQL インスタンスが us-central1 にある場合、バックアップはデフォルトで米国のマルチリージョンに保存されます。ただし、australia-southeast1 のようなデフォルトのロケーションはマルチリージョン外であり、最も近いマルチリージョンである asia に配置されます。バックアップには、カスタム ロケーションを選択することもできます。
自動バックアップ
自動バックアップは、選択した 4 時間の枠内で毎日作成されます。バックアップはバックアップ時間枠内に開始され、完了するまでバックアップ時間枠の外で続行されます。保持する自動バックアップの数を構成できます(1~365 の範囲)。デフォルトの保持ポリシーでは、最新の 7 つのバックアップが保持されます。
オンデマンド バックアップ
オンデマンド バックアップも、いつでも作成できます。バックアップを必要としており、バックアップの時間帯まで待ちたくない場合に利用できます。また、オンデマンド バックアップは、自動バックアップとは異なり、自動で削除されません。明示的に削除するか、インスタンスが削除されるまで維持されます。
Cloud SQL バックアップの復元
バックアップは、作成元の同じインスタンスに復元することも、同じプロジェクト内の別のインスタンスに復元することもできます。ターゲット インスタンスはリードレプリカでない必要があります。リードレプリカはプライマリ インスタンスのコピーであり、レプリカがプライマリと同期しなくなるリスクがあるため、バックアップの復元時にはリードレプリカ以外でなければなりません。リードレプリカは後でいつでも追加できます。
バックアップを復元すると、そのバックアップ スナップショットから新しい PD が作成され、インスタンスにアタッチされます。データベースは新しいディスクを使用して開始し、標準の MySQL クラッシュ リカバリ プロセスを実行してから、スナップショットから復元された本格的な MySQL データベースとしてオンラインになります。
同じインスタンスに復元する
バックアップから同じインスタンスに復元すると、そのインスタンス上のデータが、バックアップを作成したときの状態に戻ります。
別のインスタンスに復元する
バックアップから別のインスタンスに復元すると、ターゲット インスタンス上のデータが、バックアップを作成したときのソース インスタンスの状態に更新されます。
重要: バックアップを復元すると、以前のポイントインタイム リカバリ ログなど、ターゲット インスタンスの現在のデータがすべて上書きされます。上書きされたデータは復元できません。
Cloud SQL ポイントインタイム リカバリ(PITR)
Cloud SQL において、PITR は、クローン インスタンス オペレーションと同様、常にソース インスタンスの設定を継承する新しいインスタンスを作成します。この機能を使用するには、ソース インスタンスで自動バックアップとポイントインタイム リカバリ(バイナリログ)の両方を有効にする必要があります。バイナリログのデフォルトの保持ポリシーは 7 日間です。1~7 日の範囲で保持期間を構成できます。
PITR を実行するには、元のインスタンスのバックアップから新しいインスタンスを作成し、元のインスタンスのデータディスクに保存されているバイナリログを指定の時点まで再生します。
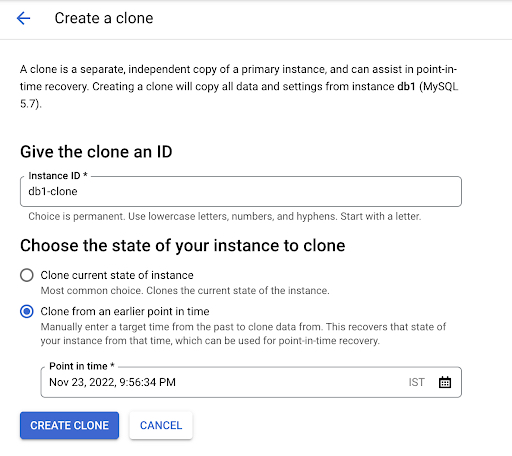
Cloud SQL で PITR を実行する場合、お客様はインスタンスの現在の状態のクローンを作成するか、過去のタイムスタンプのクローンを作成するかを選択できます。
PITR を実行する UI は次のようになります。
関連プロダクトとサービス
Google Cloud は、オンプレミスのデータセンターの廃止から SaaS アプリケーションの実行、基幹業務システムの移行まで、お客様のビジネスニーズに合わせて構築されたマネージド MySQL データベースを提供します。
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る


















