This document introduces Monitoring Query Language (MQL) through examples. However, it doesn't attempt to cover all aspects of the language. MQL is comprehensively documented in Monitoring Query Language reference.
For information on MQL-based alerting policies, see Alerting policies with MQL.
You can write a particular query in many forms; the language is flexible, and there are many shortcuts you can use after you are familiar with the syntax. For more information, see Strict-form queries.
Before you begin
To access the code editor when using Metrics Explorer, do the following:
-
In the Google Cloud console, go to the leaderboard Metrics explorer page:
If you use the search bar to find this page, then select the result whose subheading is Monitoring.
- In the toolbar of the query-builder pane, select the button whose name is either code MQL or code PromQL.
- Verify that MQL is selected in the Language toggle. The language toggle is in the same toolbar that lets you format your query.
To run a query, paste the query into the editor and click Run Query. For an introduction to this editor, see Use the code editor for MQL.
Some familiarity with Cloud Monitoring concepts including metric types, monitored-resource types, and time series is helpful. For an introduction to these concepts, see Metrics, time series, and resources.
Data model
MQL queries retrieve and manipulate data in the Cloud Monitoring time-series database. This section introduces some of the concepts and terminology related to that database. For detailed information, see the reference topic Data model.
Every time series originates from a single type of monitored resource, and
every time series collects data of one metric type.
A monitored-resource descriptor defines a monitored-resource type. Similarly,
a metric descriptor defines a metric type.
For example, the resource type might be gce_instance, a
Compute Engine virtual machine (VM), and the metric type might be
compute.googleapis.com/instance/cpu/utilization, the CPU utilization
of the Compute Engine VM.
These descriptors also specify a set of labels that are used to
collect information about other attributes of the metric or resource
type. For example, resources typically have a zone label, used to
record the geographic location of the resource.
One time series is created for each combination of values for the labels from the pair of a metric descriptor and a monitored-resource descriptor.
You can find the available labels for resource types in the
Monitored resource list, for example
gce_instance.
To find the labels for metric types, see the Metrics list;
for example, see metrics from Compute Engine.
The Cloud Monitoring database stores the time series from a particular metric and resource type in one table. The metric and resource type act as the identifier for the table. This MQL query fetches the table of time series recording CPU utilization for Compute Engine instances:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
There is one time series in the table for each unique combination of metric and resource label values.
MQL queries retrieve time-series data from these tables
and transform it into output tables. These output tables can be
passed into other operations. For example, you can
isolate the time series written by resources in a particular
zone or set of zones by passing the retrieved table as input to
a filter operation:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
The preceding query results in a table that contains only
the time series from resources in a zone that begins with us-central.
MQL queries are structured to pass the output of one operation as the input to the next operation. This table-based approach lets you link operations together to manipulate this data by filtering, selection, and other familiar database operations like inner and outer joins. You can also run various functions on the data in the time series as the data is passed from one operation to another.
The operations and functions available in MQL are fully documented in Monitoring Query Language reference.
Query structure
A query is made up of one or more operations. Operations are linked, or piped, together so that the output of one operation is the input to the next. Therefore, the result of a query depends on the order of the operations. Some of the things you can do include the following:
- Start a query with a
fetchor other selection operation. - Build up a query with multiple operations piped together.
- Select a subset of information with
filteroperations. - Aggregate related information with
group_byoperations. - Look at outliers with
topandbottomoperations. - Combine multiple queries with
{ ; }andjoinoperations. - Use the
valueoperation and functions to compute ratios and other values.
Not all queries use all of these options.
These examples introduce only some of the available operations and functions. For detailed information about the structure of MQL queries, see reference topic Query Structure.
These examples don't specify two things that you might expect to see: time ranges and alignment. The following sections explain why.
Time ranges
When you use the code editor, the chart settings define the time range for queries. By default, the chart's time range is set to one hour.
To change the time range of the chart, use the time-range selector. For example, if you want to view the data for the past week, then select Last 1 week from the time-range selector. You can also specify a start and end time, or specify a time to view around.
For more information about time ranges in the code editor, see Time ranges, charts, and the code editor.
Alignment
Many of the operations used in these examples, like the join and group_by
operations, depend on all the time series points in a table occurring at
regular intervals. The act of making all the points line up at regular
timestamps is called alignment. Usually, alignment is done implicitly, and
none of the examples here show it.
MQL automatically aligns tables for join and group_by operations
when needed, but MQL lets you do alignment explicitly as well.
For general information on the concept of alignment, see Alignment: within-series aggregation.
For information on alignment in MQL, see the reference topic Alignment. Alignment can be explicitly controlled by using the
alignandeveryoperations.
Fetch and filter data
MQL queries start with the retrieval and selection or filtering of data. This section illustrates some basic retrieval and filtering with MQL.
Retrieve time-series data
A query always starts with a fetch operation, which retrieves time
series from Cloud Monitoring.
The simplest query consists of a single fetch operation and an argument that
identifies the time series to fetch, such as the following:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
The argument consists of a monitored-resource type, gce_instance,
a pair of colon characters, ::,
and a metric type, compute.googleapis.com/instance/cpu/utilization.
This query retrieves the time series written by Compute Engine instances
for the metric type compute.googleapis.com/instance/cpu/utilization, which
records the CPU utilization of those instances.
If you run the query from the code editor in Metrics Explorer, you get a chart showing each of the requested time series:
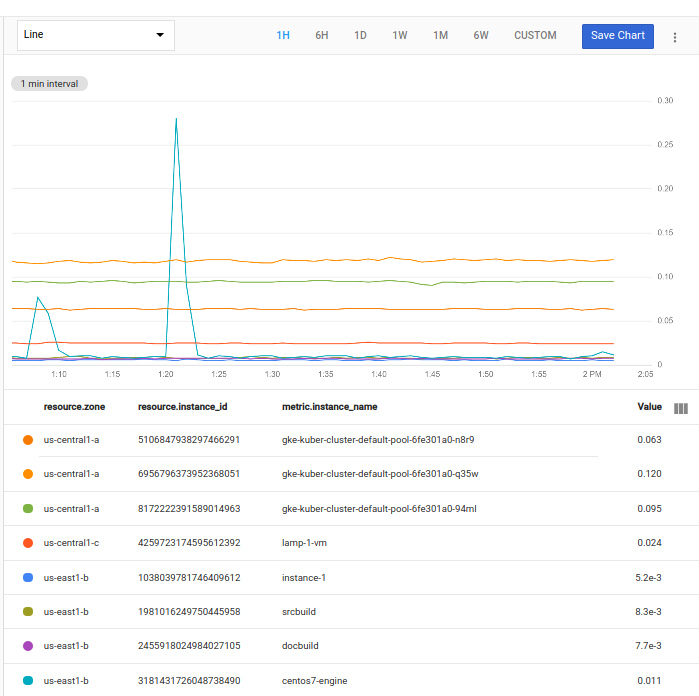
Each of the requested time series is displayed as a line on the chart. Each time series includes a list of time-stamped values from the CPU-utilization metric for one VM instance in this project.
In the backend storage used by Cloud Monitoring, time series are stored in
tables. The fetch operation organizes the time series for the specified
monitored-resource and metric types into a table, and then it returns the table.
The returned data is displayed in the chart.
The fetch operation is described, along with its arguments, on the
fetch reference page. For more information on the
data produced by operations, see the reference pages for time series
and tables.
Filter operations
Queries typically consist of a combination of multiple operations. The simplest
combination is to pipe the output of one operation into the input of the next
by using the pipe operator, |. The following example illustrates using a
pipe to input the table to a filter operation:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter instance_name =~ 'gke.*'
This query pipes the table, returned by the fetch operation shown in the
previous example, into a filter operation which takes as an expression
that evaluates to a boolean value. In this example, the expression means
"instance_name starts with gke".
The filter operation takes the input table, removes the time series for
which the filter is false, and outputs the resulting table. The following
screenshot shows the resulting chart:
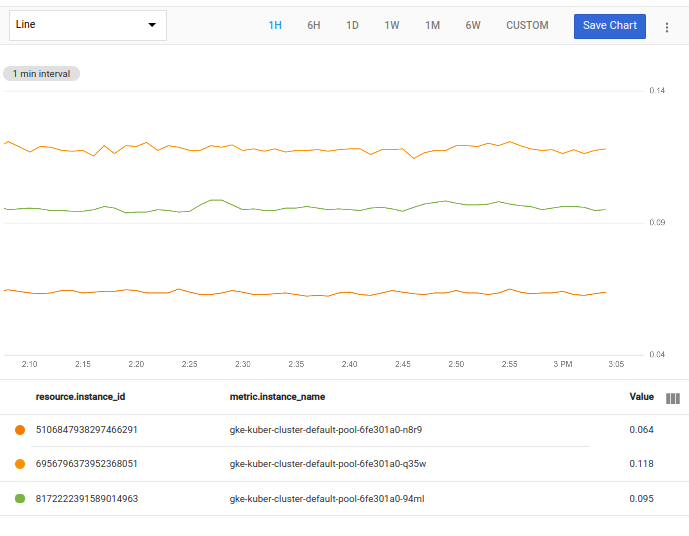
If you don't have any instance names that start with
gke, change the filter before trying this query. For example, if you have
VM instances with apache at the beginning of their names, use the following
filter:
| filter instance_name =~ 'apache.*'
The filter expression is evaluated once for each input time series.
If the expression evaluates to true, that time series is included in the
output. In this example, the filter expression does a regular expression
match, =~, on the instance_name label of each time series. If the value
of the label matches the regular expression 'gke.*', then the time series
is included in the output. If not, the time series is dropped from the output.
For more information on filtering, see the
filter reference page.
The filter predicate can be any arbitrary expression that returns a boolean
value; for more information, see Expressions.
Group and aggregate
Grouping lets you group time series along specific dimensions. Aggregation combines all the time series in a group into one output time series.
The following query filters the output of the initial fetch operation
to retain only those time series from resources in a zone that begins with
us-central. It then groups the time series by zone and combines them
using mean aggregation.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
| group_by [zone], mean(val())
The table resulting from the group_by operation has one time series per zone.
The following screenshot shows the resulting chart:
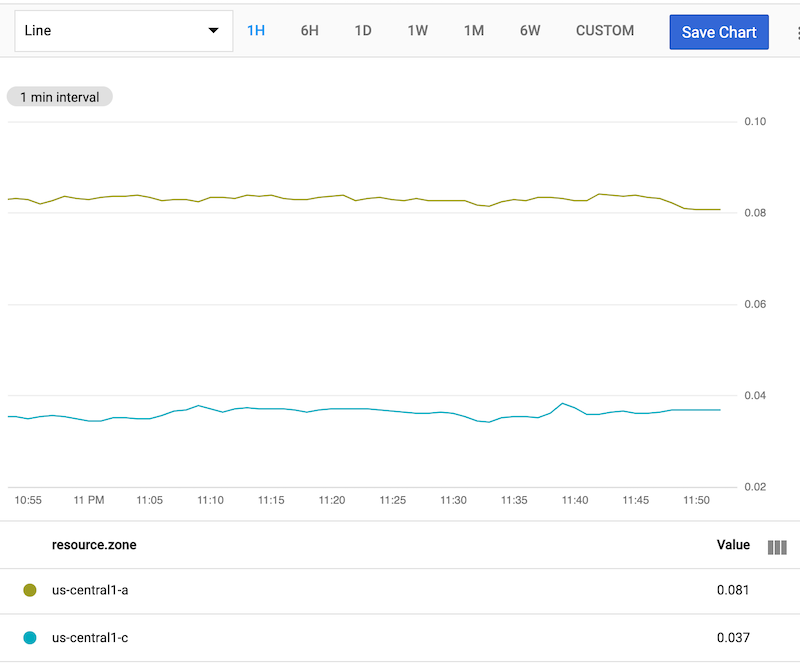
The group_by operation takes two arguments, separated by a
comma, ,. These arguments determine the precise grouping behavior. In
this example, group_by [zone], mean(val()), the arguments act as follows:
The first argument,
[zone], is a map expression that determines the grouping of the time series. In this example, it specifies the labels to use for grouping. The grouping step collects all input time series that have the same outputzonevalues into one group. In this example, the expression collects the time series from the Compute Engine VMs in one zone.The output time series has only a
zonelabel, with the value copied from the input time series in the group. Other labels on the input time series are dropped from the output time series.The map expression can do much more than list labels; for more information, see the
mapreference page.The second argument,
mean(val()), determines how the time series in each group are combined, or aggregated, into one output time series. Each point in the output time series for a group is the result of aggregating the points with the same timestamp from all input time series in the group.The aggregation function,
meanin this example, determines the aggregated value. Theval()function returns the points to be aggregated, the aggregation function is applied to those points. In this example, you get the mean of the CPU utilization of the virtual machines in the zone at each output time point.The expression
mean(val())is an example of an aggregating expression.
The group_by operation always combines grouping and aggregation.
If you specify a grouping but omit the aggregation argument, group_by uses
a default aggregation, aggregate(val()), which selects an appropriate
function for the data type. See aggregate for the list
of default aggregation functions.
Use group_by with a log-based metric
Suppose you have created a distribution log-based metric to extract the number of data points processed from a set of long entries including strings like following:
... entry ID 1 ... Processed data points 1000 ... ... entry ID 2 ... Processed data points 1500 ... ... entry ID 3 ... Processed data points 1000 ... ... entry ID 4 ... Processed data points 500 ...
To create a time series that shows the count of all processed data points, use an MQL such as the following:
fetch global
| metric 'logging.googleapis.com/user/METRIC_NAME'
| group_by [], sum(sum_from(value))
To create a log-based distribution metric, see configure distribution metrics.
Exclude columns from a group
You can use the drop modifier in a mapping to exclude columns from a
group.
For example, the Kubernetes core_usage_time metric has six columns:
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by [project_id, location, cluster_name, namespace_name, container_name]
If you don't need to group pod_name, then you can exclude it with drop:
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by drop [pod_name]
Select time series
The examples in this section illustrate ways to select particular time series out of an input table.
Select top or bottom time series
To see the time series data for the three Compute Engine instances with the highest CPU utilization within your project, enter the following query:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3
The following screenshot shows the result from one project:
You can retrieve the time series with the lowest CPU utilization by
replacing top with bottom.
The top operation outputs a table with a specified number of
time series selected from its input table. The time series included in the
output have the largest value for some aspect of the time series.
Since this query doesn't specify a way to order the time series,
it returns those time series with the largest value for the most recent point.
To specify how to determine which time series have the largest value, you
can provide an argument to the top operation. For example, the
previous query is equivalent to the following query:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, val()
The val() expression selects the value of the most recent point in each
time series it is applied to. Therefore, the query returns those time series
with the largest value for the most recent point.
You can provide an expression that does aggregation over some or all points in a time series to give the sorting value. The following takes the mean of all points within the last 10 minutes:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, mean(val()).within(10m)
If the within function isn't used, the mean function
is applied to the values of all the displayed points in the time series.
The bottom operation works similarly.
The following query finds the value of the largest point in each time series
with max(val()) and then selects the three time series for which that value is
smallest:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| bottom 3, max(val())
The following screenshot shows a chart displaying the streams with the smallest spikes:
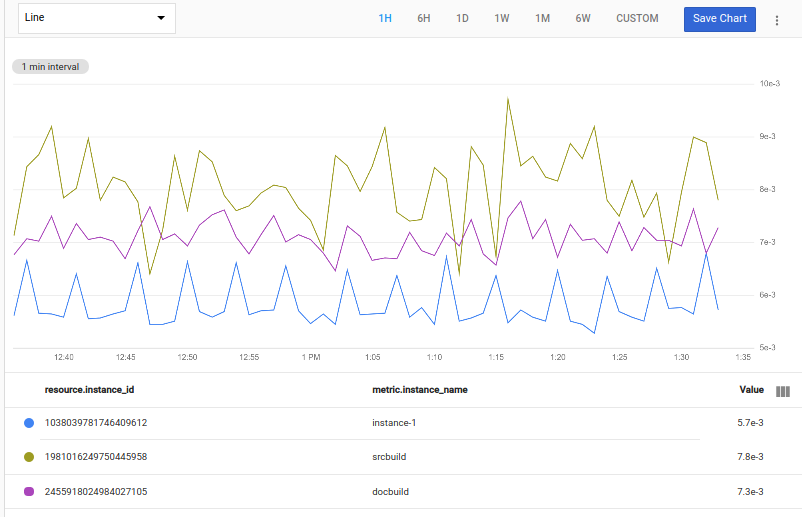
Exclude the top or bottom n results in the time series
Consider a scenario in which you have many Compute Engine VM instances. A few of these instances consume a lot more memory than most instances, and these outliers are making it harder to see the usage patterns in the larger group. Your CPU utilization charts look like the following:
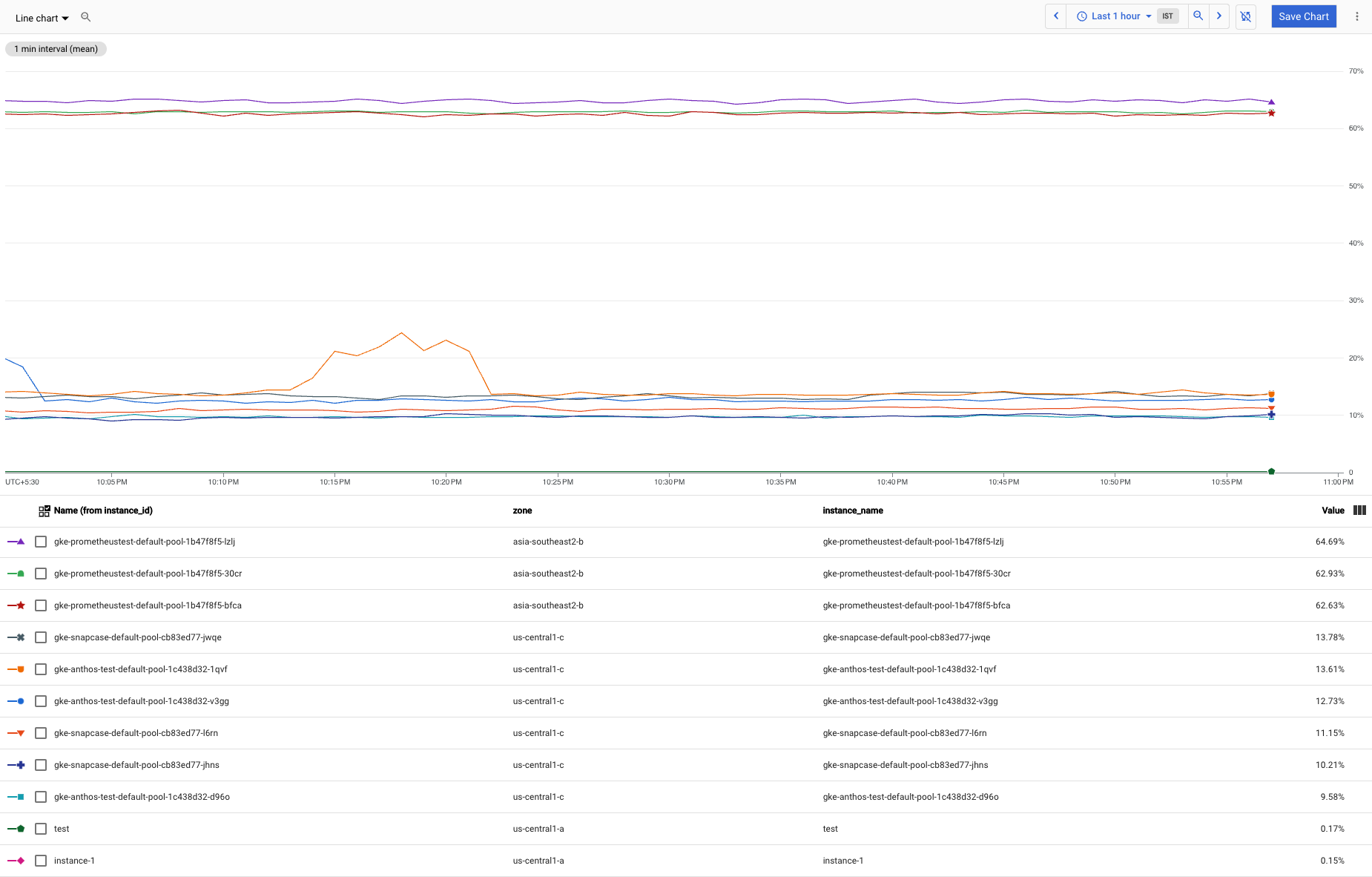
You want to exclude the three outliers from the chart so that you can see the patterns in the larger group more clearly.
To exclude the top three time series in a query that retrieves the time series
for Compute Engine CPU utilization, use the top table operation
to identify the time series and the outer_join table operation
to exclude the identified time series from the results. You can use the
following query:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 3 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
The fetch operation returns a table of time series for CPU utilization from
all instances. This table is then processed into two resulting tables:
The
top ntable operation outputs a table that contains the n time series with the highest values. In this case, n = 3. The resulting table contains the three times series to be excluded.The table containing the top three time series is then piped into a
valuetable operation. This operation adds another column to each of the time series in the top-three table. This column,is_default_value, is given the boolean valuefalsefor all time series in the top-three table.The
identoperation returns the same table that was piped into it: the original table of CPU utilization time series. None of the time series in this table have theis_default_valuecolumn.
The top-three table and the original table are then piped into the
outer_join table operation. The top-three table is the left table
in the join, the fetched table is the right table in the join.
The outer join is set up to provide the value true as the value for
any field that doesn't exist in a row being joined. The result of the
outer join is a merged table, with the rows from the top-three table keeping
the column is_default_value with the value false, and all the rows from
the original table that weren't also in the top-three table getting the
is_default_value column with the value true.
The table resulting from the join is then passed to the filter
table operation, which filters out the rows that have a
value of false in the is_default_value column. The resulting table
contains the rows from the originally fetched table without the rows
from the top-three table. This table contains the intended set of time series,
with the added is_default_column.
The final step is to drop the column is_default_column that was added by
the join, so the output table has the same columns as the originally fetched
table.
The following screenshot shows the chart for the prior query:
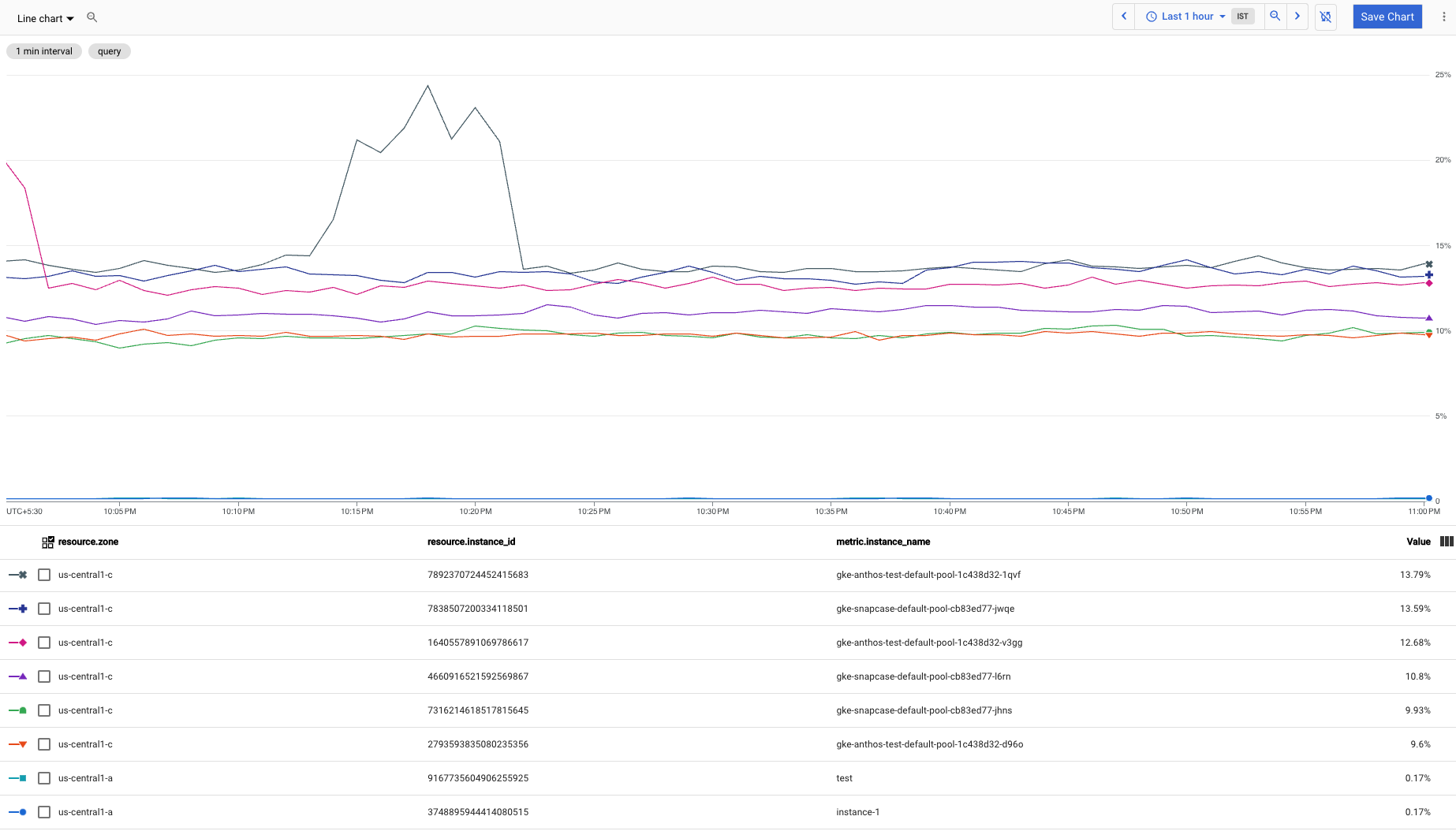
You can create a query to exclude the time series with the lowest
CPU utilization by replacing top n with bottom
n.
The ability to exclude outliers can be useful in cases where you want to set an alert but don't want the outliers to constantly trigger the alert. The following alert query uses the same exclusion logic as the prior query to monitor the CPU limit utilization by a set of Kubernetes pods after excluding the top two pods:
fetch k8s_container
| metric 'kubernetes.io/container/cpu/limit_utilization'
| filter (resource.cluster_name == 'CLUSTER_NAME' &&
resource.namespace_name == 'NAMESPACE_NAME' &&
resource.pod_name =~ 'POD_NAME')
| group_by 1m, [value_limit_utilization_max: max(value.limit_utilization)]
| {
top 2 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
| every 1m
| condition val(0) > 0.73 '1'
Select top or bottom from groups
The top and bottom table operations select time series from the entire
input table. The top_by and bottom_by
operations group the time series in a table and then pick some number of
time series from each group.
The following query selects the time series in each zone with the largest peak value:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 1, max(val())
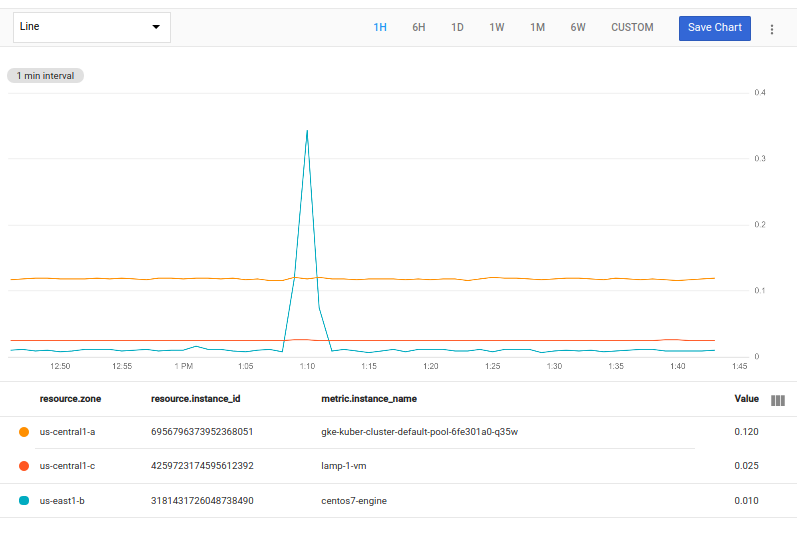
The [zone] expression indicates that a group consists of
the time series with the same value of the zone column.
The 1 in the top_by indicates how many time series to select from each
zone's group. The max(val()) expression looks for the largest value in
the chart's time range in each time series.
You can use any aggregation function in place of max.
For example, the following uses the mean aggregator and uses within
to specify the sorting range of 20 minutes. It selects the top 2 time series
in each zone:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 2, mean(val()).within(20m)
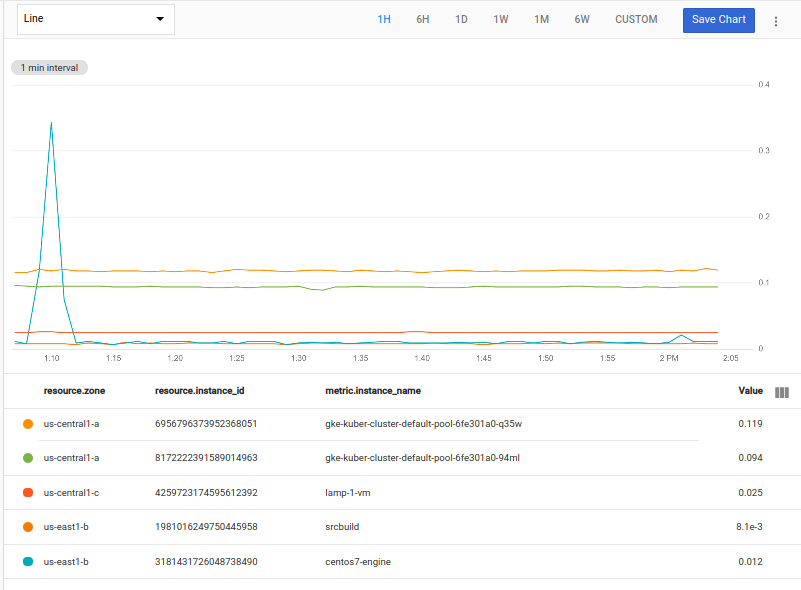
In the previous example, there is only one instance in the zone us-central-c,
so there is only one time series returned; there isn't a "top 2" in the group.
Combine selections with union
You can combine selection operations like top and bottom to create
charts that show both. For example, the following query returns the single
time series with the maximum value and the single time series with the minimum
value:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 1, max(val())
;
bottom 1, min(val())
}
| union
The resulting chart shows two lines, the one containing the highest value and the one containing the lowest:
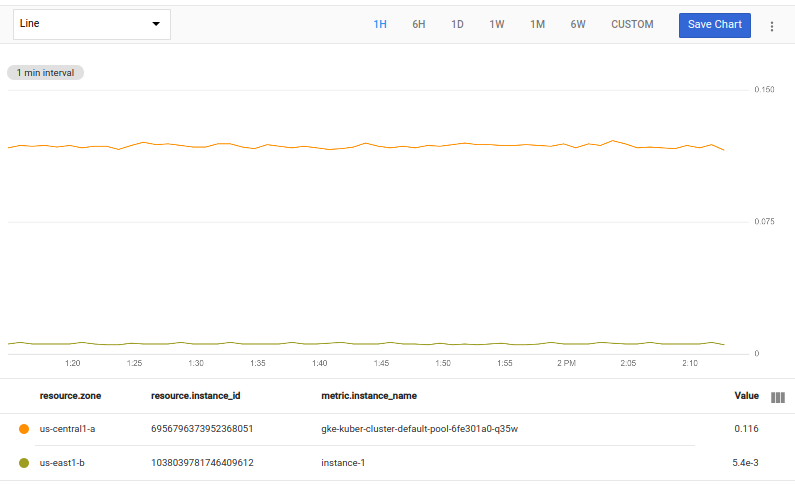
You can use braces, { }, to specify sequences of operations, each of
which yields one table of time series as output. The individual operations are
separated by a semicolon, ;.
In this example, the fetch operation returns a single table, which
is piped to each of the two operations in the sequence, a top operation
and a bottom operation. Each of these operations results in an output table
based on the same input table. The union operation then combines
the two tables into one, which is displayed on the chart.
See more about sequencing operations by using { } in the reference
topic Query Structure.
Combine time series with different values for one label
Suppose that you have multiple time series for the same metric type and
you want to combine a few of them together. If you want to select them
based on the values of a single label, then you can't create the query
by using the query-builder interface in Metrics Explorer. You need to
filter on two or more different values of the same label, but the query-builder
interface requires that a time series match all the filters to be selected:
the label matching is an AND test. No time series can have two different
values for the same label, but you can't create an OR test for filters
in the query builder.
The following query retrieves the time series for the Compute Engine
instance/disk/max_read_ops_count metric for two specific Compute Engine
instances and aligns the output over 1-minute intervals:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| every 1m
The following chart shows a result of this query:
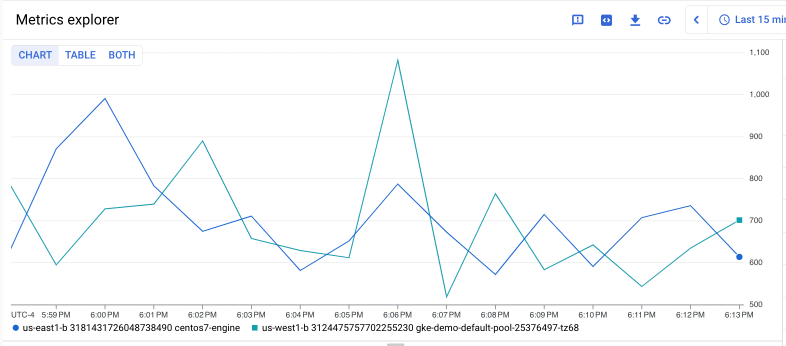
If you want to find the sum of the maximum max_read_ops_count values for these
two VMs and sum them, you can do the following:
- Find the maximum value for each time series by using the
group_bytable operator, specifying the same 1-minute alignment period and aggregating over the period with themaxaggregator to create a column namedmax_val_of_read_ops_count_maxin the output table. - Find the sum of the time series by using the
group_bytable operator and thesumaggregator on themax_val_of_read_ops_count_maxcolumn.
The following shows the query:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| group_by 1m, [max_val_of_read_ops_count_max: max(value.max_read_ops_count)]
| every 1m
| group_by [], [summed_value: sum(max_val_of_read_ops_count_max)]
The following chart shows a result of this query:
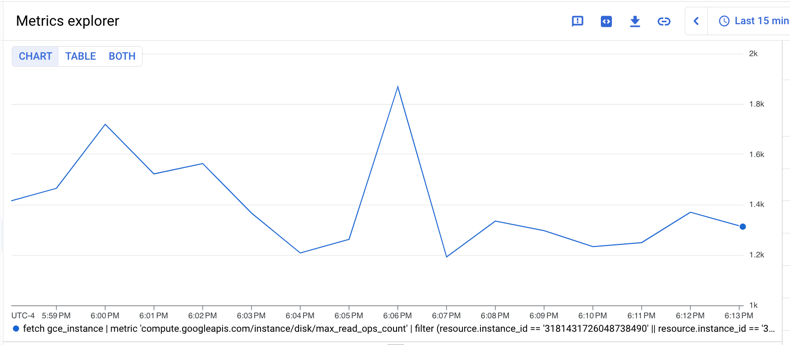
Compute percentile statistics across time and across streams
To compute a percentile stream value over a sliding window separately for each
stream, use a temporal group_by operation. For example, the following
query computes the 99th percentile value of a stream over a 1-hour sliding
window:
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by 1h, percentile(val(), 99) | every 1m
To compute the same percentile statistic at a point in time across streams,
rather than across time within one stream, use a spatial group_by operation:
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by [], percentile(val(), 99)
Compute ratios
Suppose you've built a distributed web service that runs on Compute Engine VM instances and uses Cloud Load Balancing.
You want to see a chart that displays the ratio of requests that return HTTP
500 responses (internal errors) to the total number of requests; that is,
the request-failure ratio. This section illustrates several ways to compute
the request-failure ratio.
Cloud Load Balancing uses the monitored-resource type http_lb_rule.
The http_lb_rule monitored-resource type has a
matched_url_path_rule label that records the prefix of URLs defined in
for the rule; the default value is UNMATCHED.
The loadbalancing.googleapis.com/https/request_count
metric type has a response_code_class label. This label captures the class
of response codes.
Use outer_join and div
The following query determines the 500 responses for each value of
the matched_url_path_rule label in each http_lb_rule monitored resource
in your project. It then joins this failure-count table with the original
table, which contains all response counts and divides the values to show
the ratio of failure responses to total responses:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| outer_join 0
| div
The following chart shows the result from one project:
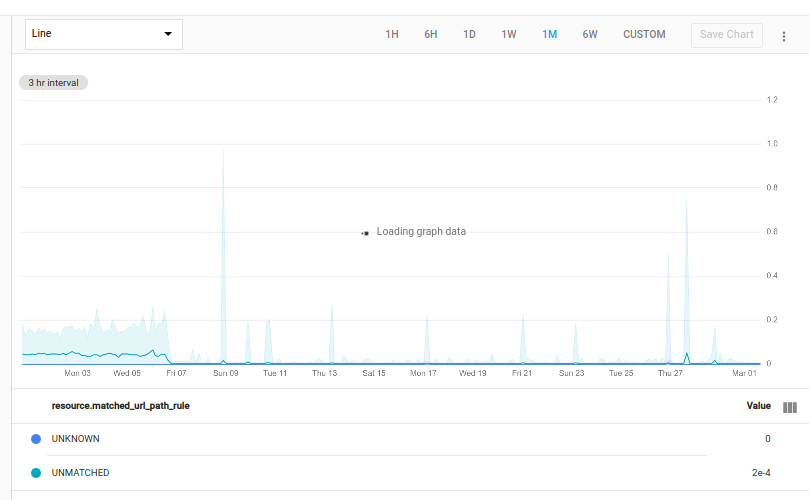
The shaded areas around the lines on the chart are min/max bands; for more information, see Min/max bands.
The fetch operation outputs a table of time series containing counts of
request for all load-balanced queries. This table is processed in two ways by
the two operation sequences in the braces:
filter response_code_class = 500outputs only the time series that haveresponse_code_classlabel with the value500. The resulting time series counts the requests with HTTP 5xx (error) response codes.This table is the numerator of the ratio.
The
ident, or identity, operation outputs its input, so this operation returns the originally fetched table. That's the table that contains time series with counts for every response code.This table is the denominator of the ratio.
The numerator and denominator tables, produced by the filter and ident
operations respectively, are processed separately by the group_by operation.
The group_by operation groups the time series in each table by the value of
the matched_url_path_rule label and sums the counts for each value of the
label. This group_by operation doesn't explicitly state the aggregator
function, so a default, sum, is used.
For the filtered table, the
group_byresult is the number of requests returning a500response for eachmatched_url_path_rulevalue.For the identity table, the
group_byresult is the total number of requests for eachmatched_url_path_rulevalue.
These tables are piped to the outer_join operation,
which pairs time series with matching label values, one from each
of the two input tables. The paired time series are zipped up by matching the
timestamp of each point in one time series to the timestamp of a point in
the other time series. For each matched pair of points, outer_join produces a
single output point with two values, one from each of the input tables.
The zipped-up time series is output by the join with the same labels as the
two input time series.
With an outer join, if a point from the second table doesn't have a
matching point in the first, a stand-in value must be provided. In this
example, a point with value 0—the argument to the outer_join
operation—is used.
Finally, the div operation takes each point with two values and divides the
values to produce a single output point: the ratio of 500 responses to all
responses for each URL map.
The string div here is actually the name of the div function,
which divides two numeric values. But it's used here as an operation. When
used as operations, functions like div expect two values in each input point
(which this join ensures) and produce a single value for the corresponding
output point.
The | div part of the query is a shortcut for | value val(0) / val(1).
The value operation allows arbitrary expressions on the value columns
of an input table to produce the value columns of the output table.
For more information, see the reference pages for the value
operation and for expressions.
Use ratio
The div function could be replaced with any function on two values, but
because ratios are so frequently used, MQL provides a
ratio table operation that computes ratios directly.
The following query is equivalent to the preceding version, using
outer_join and div:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| ratio
In this version, the ratio operation replaces the outer_join 0 | div
operations in the earlier version and produces the same result.
Note that ratio only uses outer_join to supply a 0 for the numerator if
both the numerator and denominator inputs have the same labels identifying
each time series, which MQL outer_join requires. If the numerator input
has extra labels, then there will be no output for any point missing in the
denominator.
Use group_by and /
There's yet another way to compute the ratio of error responses to all responses. In this case, because the numerator and denominator for the ratio are derived from the same time series, you can also compute the ratio by grouping alone. The following query shows this approach:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| group_by [matched_url_path_rule],
sum(if(response_code_class = 500, val(), 0)) / sum(val())
This query uses an aggregation expression built on the ratio of two sums:
The first
sumuses theiffunction to count 500-valued labels and 0 for others. Thesumfunction computes the count of the requests that returned 500.The second
sumadds up the counts for all requests,val().
The two sums are then divided, resulting in the ratio of 500 responses to all
responses. This query produces the same result as those queries in
Using outer_join and div and Using
ratio.
Use filter_ratio_by
Because ratios are frequently computed by dividing two sums derived from
the same table, MQL provides the filter_ratio_by
operation for this purpose. The following query does the same thing
as the preceding version, which explicitly divides the sums:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| filter_ratio_by [matched_url_path_rule], response_code_class = 500
The first operand of the filter_ratio_by operation, here
[matched_url_path_rule], indicates how to group the responses. The
second operation, here response_code_class = 500, acts as a filtering
expression for the numerator.
- The denominator table is the result of grouping the fetched table by
matched_url_path_ruleand aggregated by usingsum. - The numerator table is the fetched table, filtered for time series with
an HTTP response code of 5xx, and then grouped by
matched_url_path_ruleand aggregated by usingsum.
Ratios and quota metrics
To set up queries and alerts on serviceruntime quota
metrics and resource-specific quota metrics to monitor your
quota consumption, you can use MQL. For more information,
including examples, see Using quota metrics.
Arithmetic computation
Sometimes you might want to perform an arithmetic operation on data before you chart it. For example, you might want to scale time series, convert the data to log scale, or chart the sum of two time series. For a list of arithmetic functions available in MQL, see Arithmetic.
To scale a time series, use the mul function. For example, the
following query retrieves the time series and then multiplies each value
by 10:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/read_bytes_count'
| mul(10)
To sum two time series, configure your query to fetch two tables of time series,
join those results, and then call the add function. The following
example illustrates a query that computes the sum of the number of bytes read
from, and written to, Compute Engine instances:
fetch gce_instance
| { metric 'compute.googleapis.com/instance/disk/read_bytes_count'
; metric 'compute.googleapis.com/instance/disk/write_bytes_count' }
| outer_join 0
| add
To subtract the written byte counts from the read bytes count, replace add
with sub in the previous expression.
MQL uses the labels in the sets of tables returned from the first and second fetch to determine how to join the tables:
If the first table contains a label not found in the second table, then MQL can't perform an
outer_joinoperation on the tables and therefore it reports an error. For example, the following query causes an error because themetric.instance_namelabel is present in the first table but not in the second table:fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' } | outer_join 0 | addOne way to resolve this type of error is to apply grouping clauses to ensure the two tables have the same labels. For example, you can group away the all time series labels:
fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' | group_by [] ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' | group_by [] } | outer_join 0 | addIf the labels of the two tables match, or if the second table contains a label not found in the first table, then the outer join is allowed. For example, the following query doesn't cause an error even though the
metric.instance_namelabel is present in the second table, but not the first:fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/write_bytes_count' } | outer_join 0 | subA time series found in the first table might have label values that match multiple time series in the second table, so MQL performs the subtraction operation for each pairing.
Time shifting
Sometimes you want to compare what is going on now with what has happened in the
past. To let you compare past data to current data,
MQL provides the time_shift table operation to move data from
the past into the current time period.
Over-time ratios
The following query uses time_shift, join,
and div to compute the ratio of the mean utilization in each
zone between now and one week ago.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by [zone], mean(val())
| {
ident
;
time_shift 1w
}
| join | div
The following chart shows a possible result of this query:
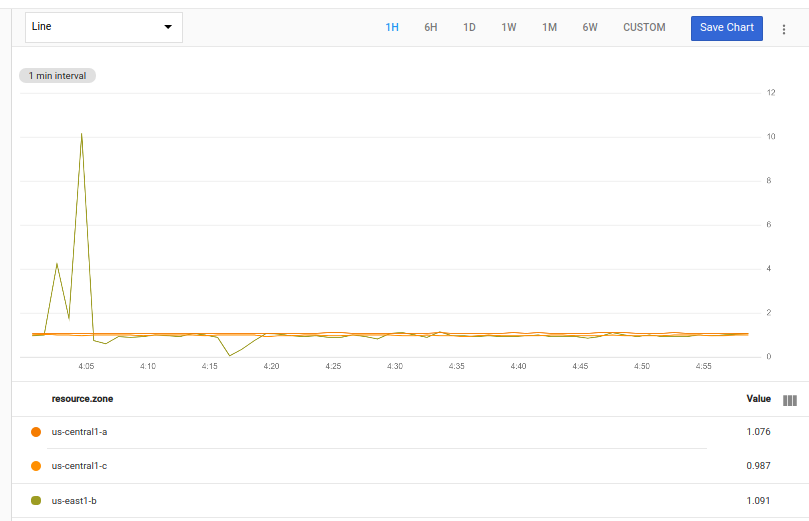
The first two operations fetch the time series and then group
them, by zone, computing the mean values for each. The resulting table
is then passed to two operations. The first operation, ident, passes
the table through unchanged.
The second operation, time_shift, adds the period (1 week) to the
timestamps for values in the table, which shifts data from one week ago
forward. This change makes the timestamps for older data in the second table
line up with the timestamps for the current data in the first table.
The unchanged table and the time-shifted table are then combined by using an
inner join. The join produces a table of time series where each
point has two values: the current utilization and the utilization a week ago.
The query then uses the div operation to compute the ratio of the current
value to the week-old value.
Past and present data
By combining time_shift with union, you can create a chart that shows
past and present data simultaneously. For example, the following query
returns the overall mean utilization now and from a week ago. Using union,
you can display these two results on the same chart.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by []
| {
add [when: "now"]
;
add [when: "then"] | time_shift 1w
}
| union
The following chart shows a possible result of this query:
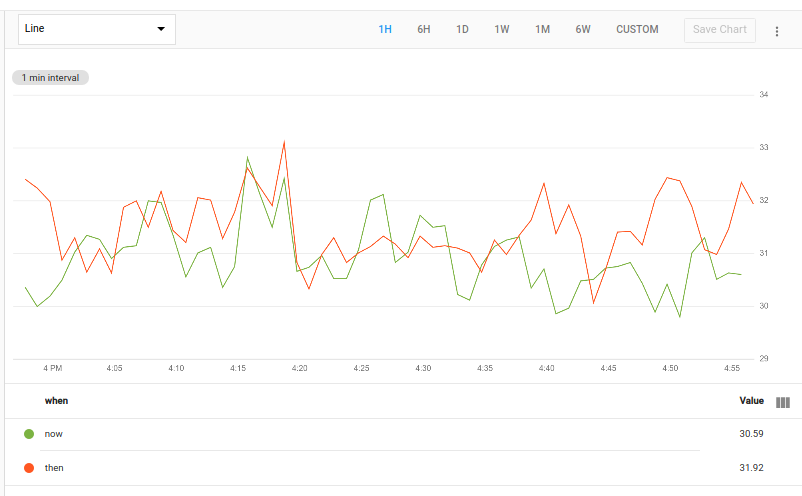
This query fetches the time series and then uses group_by []
to combine them into a single time series with no labels, leaving the
CPU-utilization data points. This result is passed to two operations.
The first adds a column for a new label called when with the value now.
The second adds a label called when with the value then and
passes the result to the time_shift operation to shift the values
by a week. This query uses the add map modifier; see Maps
for more information.
The two tables, each containing data for a single time series, are passed
to union, which produces one table containing the time series from both
input tables.
What's next
For an overview of MQL language structures, see About the MQL language.
For a complete description of MQL, see the Monitoring Query Language reference.
For information about interacting with charts, see Working with charts.