이 문서에서는 예시를 통해 모니터링 쿼리 언어(MQL)를 소개합니다. MQL의 모든 측면을 다루지는 않습니다. MQL은 Monitoring Query Language 참조에 자세히 설명되어 있습니다.
MQL 기반 알림 정책에 대한 상세 설명은 MQL을 사용한 알림 정책을 참조하세요.
여러 형식으로 특정 쿼리를 작성할 수 있습니다. 매우 유연한 언어이므로 문법에 익숙해지면 여러 가지 단축키를 사용할 수 있습니다. 자세한 내용은 엄격한 쿼리를 참조하세요.
시작하기 전에
측정항목 탐색기를 사용할 때 코드 편집기에 액세스하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서 leaderboard 측정항목 탐색기 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- 쿼리 빌더 창의 툴바에서 이름이 code MQL 또는 code MQL인 버튼을 선택합니다.
- MQL 전환 버튼에 MQL이 선택되어 있는지 확인합니다. 언어 전환 버튼은 쿼리 형식을 지정할 수 있는 동일한 툴바에 있습니다.
쿼리를 실행하려면 편집기에 쿼리를 붙여넣고 쿼리 실행을 클릭합니다. 이 편집기에 대한 소개는 MQL용 코드 편집기 사용을 참조하세요.
측정항목 유형, 모니터링 리소스 유형, 시계열을 비롯한 Cloud Monitoring 개념에 대해 어느 정도 익숙해야 합니다. 이러한 개념은 측정항목, 시계열, 리소스를 참조하세요.
데이터 모델
MQL 쿼리는 Cloud Monitoring 시계열 데이터베이스에서 데이터를 검색하고 조작합니다. 이 섹션에서는 해당 데이터베이스와 관련된 몇 가지 개념과 용어를 소개합니다. 자세한 내용은 참조 주제 데이터 모델을 참조하세요.
모든 시계열은 모니터링 리소스의 단일 유형에서 시작되며 모든 시계열은 단일한 측정항목 유형의 데이터를 수집합니다.
모니터링 리소스 설명자는 모니터링 리소스 유형을 정의합니다. 마찬가지로 측정항목 설명자는 측정항목 유형을 정의합니다.
예를 들어 리소스 유형은 gce_instance, Compute Engine 가상 머신(VM), 측정항목 유형은 compute.googleapis.com/instance/cpu/utilization, Compute Engine VM의 CPU 사용률일 수 있습니다.
이러한 설명자는 측정항목 또는 리소스 유형의 다른 속성에 대한 정보를 수집하는 데 사용되는 라벨 집합도 지정합니다. 예를 들어 리소스에는 일반적으로 리소스의 지리적 위치를 기록하는 데 사용되는 zone 라벨이 있습니다.
측정항목 설명자와 모니터링 리소스 설명 자의 쌍에 있는 라벨의 값 조합마다 시계열이 하나씩 생성됩니다.
모니터링 리소스 목록에서 리소스 유형에 사용 가능한 라벨(예: gce_instance)을 찾을 수 있습니다.
측정항목 유형의 라벨을 찾으려면 측정항목 목록을 참조하세요. 예를 들어 Compute Engine의 측정항목을 참조하세요.
Cloud Monitoring 데이터베이스는 특정 측정항목 및 리소스 유형의 시계열을 하나의 테이블에 저장합니다. 측정항목 및 리소스 유형은 테이블의 식별자 역할을 수행합니다. 이 MQL 쿼리는 Compute Engine 인스턴스의 CPU 사용률을 기록하는 시계열 테이블을 가져옵니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
이 테이블에는 측정항목 및 리소스 라벨 값의 고유한 조합마다 하나의 시계열이 있습니다.
MQL 쿼리는 이러한 테이블에서 시계열 데이터를 검색하여 출력 테이블로 변환합니다. 이 출력 테이블은 다른 작업으로 전달할 수 있습니다. 예를 들어 검색된 테이블을 filter 작업에 입력으로 전달하여 특정 영역 또는 영역 집합의 리소스가 작성한 시계열을 분리할 수 있습니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
앞의 쿼리는 us-central로 시작하는 영역의 리소스에서 시계열만 포함하는 테이블을 생성합니다.
MQL 쿼리는 한 작업의 출력을 다음 작업의 입력으로 전달하도록 구조화됩니다. 이 테이블 기반 접근 방식을 사용하면 작업들을 서로 연결하여 필터링, 선택, 내부 및 외부 조인과 같은 익숙한 데이터베이스 작업을 통해 이러한 데이터를 조작할 수 있습니다. 데이터가 한 연산에서 다른 연산으로 전달되면 시계열의 데이터에 대해 다양한 함수를 실행할 수도 있습니다.
MQL에서 이용 가능한 작업과 기능은 Monitoring Query Language 참조에 상세하게 설명되어 있습니다.
쿼리 구조
쿼리는 하나 이상의 작업으로 구성됩니다. 작업은 하나의 작업의 출력이 다음 입력의 입력이 되도록 연결되거나 파이핑됩니다. 따라서 쿼리 결과는 작업 순서에 따라 달라집니다. 할 수 있는 작업중에는 다음과 같은 것들이 포함됩니다.
fetch또는 다른 선택 작업으로 쿼리를 시작합니다.- 다수의 작업이 함께 파이프 된 쿼리를 빌드합니다.
filter작업으로 정보의 하위 집합을 선택합니다.group_by작업으로 관련 정보를 집계합니다.top및bottom작업으로 이상점을 확인합니다.{ ; }및join작업으로 여러 쿼리를 조합합니다.value연산과 함수를 사용하여 비율 및 기타 값을 계산합니다.
모든 쿼리가 위의 옵션을 모두 사용하는 것은 아닙니다.
이 예시에서는 사용 가능한 일부 작업과 함수만 소개합니다. MQL 쿼리의 구조에 대한 상세 정보는 쿼리 구조를 참조하세요.
이 예시에서는 시간 범위와 정렬 두 가지에 대해서는 다루지 않습니다. 다음 섹션에서 그 이유를 설명합니다.
기간
코드 편집기를 사용할 경우 차트 설정이 쿼리 기간을 정의합니다. 기본적으로 차트의 시간 범위는 1시간으로 설정됩니다.
차트의 시간 범위를 변경하려면 시간 범위 선택기를 사용합니다. 예를 들어 지난주의 데이터를 보려면 시간 범위 선택기에서 지난 1주를 선택합니다. 시작 및 종료 시간을 지정하거나 살펴볼 시간을 지정할 수도 있습니다.
코드 편집기의 시간 범위에 대한 자세한 내용은 시간 범위, 차트, 코드 편집기를 참조하세요.
정렬
join 및 group_by 작업과 같이 이 예시에서 사용되는 많은 작업은 일정 간격으로 발생하는 테이블의 모든 시계열 지점에 따라 다릅니다. 모든 지점을 일반 타임스탬프에 맞춰 줄세우는 작업을 정렬이라고 합니다. 일반적으로 정렬은 암시적으로 수행되며 여기에서는 예시를 제공하지 않습니다.
필요한 경우 MQL은 join 및 group_by 작업의 테이블을 자동으로 정렬하지만, 개발자가 명시적으로 정렬하도록 허용하기도 합니다.
정렬 개념에 대한 일반 정보는 정렬 : 시계열 내 집계를 참조하세요.
MQL의 정렬에 대한 정보는 정렬 참조 주제에서 확인하세요. 정렬은
align및every작업을 사용하여 명시 적으로 제어할 수 있습니다.
데이터 가져오기 및 필터링
MQL쿼리는 데이터 검색 및 선택 또는 필터링으로 시작됩니다. 이 섹션에서는 MQL을 이용한 몇 가지 기본적인 검색 및 필터링을 설명합니다.
시계열 데이터 검색
쿼리는 항상 fetch 작업으로 시작되며 Cloud Monitoring에서 시계열을 검색합니다.
가장 간단한 쿼리는 다음과 같이 가져올 시계열을 식별하는 인수로 단일 fetch 작업과 인수로 구성됩니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
인수는 모니터링 리소스 유형 gce_instance, 콜론 문자 쌍 ::, 측정항목 유형 compute.googleapis.com/instance/cpu/utilization으로 구성됩니다.
이 쿼리는 해당 인스턴스의 CPU 사용률을 기록하는 측정항목 유형 compute.googleapis.com/instance/cpu/utilization에 대해 Compute Engine 인스턴스가 작성한 시계열을 검색합니다.
측정항목 탐색기의 코드 편집기에서 쿼리를 실행하면 요청된 각 시계열을 보여주는 차트가 표시됩니다.
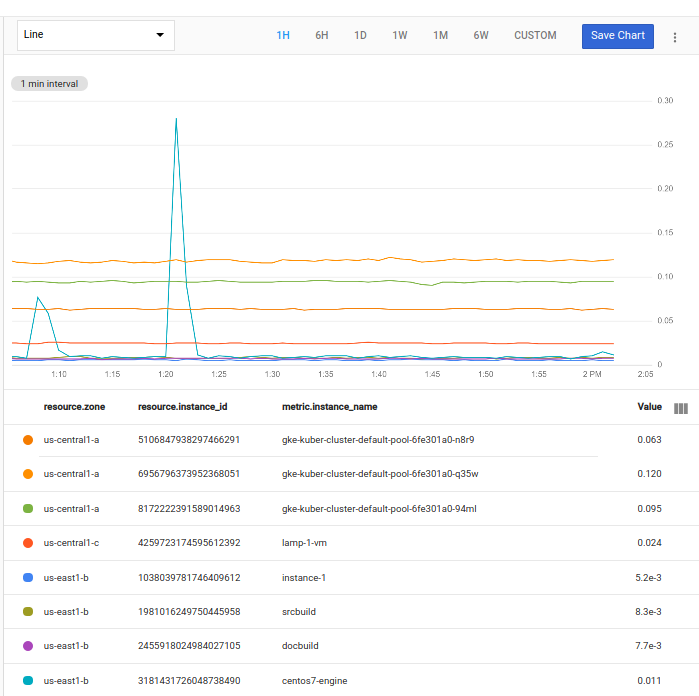
요청된 각 시계열은 차트에 선으로 표시됩니다. 각 시계열에는 이 프로젝트에서 하나의 VM 인스턴스에 대한 CPU 사용률 측정항목의 타임스탬프 값 목록이 포함됩니다.
Cloud Monitoring에서 사용하는 백엔드 저장소에서 시계열은 테이블로 저장됩니다. fetch 작업은 지정된 모니터링 리소스 및 측정항목 유형의 시계열을 테이블로 구성한 다음 테이블을 반환합니다.
반환된 데이터가 차트에 표시됩니다.
fetch 작업은 fetch 참조 페이지에 인수와 함께 설명되어 있습니다. 작업으로 생성한 데이터에 대한 상세 내용은 시계열 및 표 참조 페이지를 확인하세요.
작업 필터링
일반적으로 쿼리는 여러 작업의 조합으로 구성됩니다. 가장 간단한 조합은 파이프 연산자 |를 사용하여 한 작업의 출력을 다음 작업의 입력으로 파이프 하는 것입니다. 다음 예시는 파이프를 사용하여 테이블을 필터 작업에 입력하는 방법을 보여줍니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter instance_name =~ 'gke.*'
이 쿼리는 이전 예시에서 표시된 fetch 작업이 반환한 표를 filter 작업에 파이프하여 부울 값으로 평가하는 표현식으로 가져옵니다. 이 예시에서 표현식은 'instance_name이 gke로 시작'을 의미합니다.
filter 작업은 입력 테이블을 사용하고 필터가 false인 시계열을 삭제하며 결과 테이블을 출력합니다. 다음 스크린샷은 결과 차트를 보여줍니다.
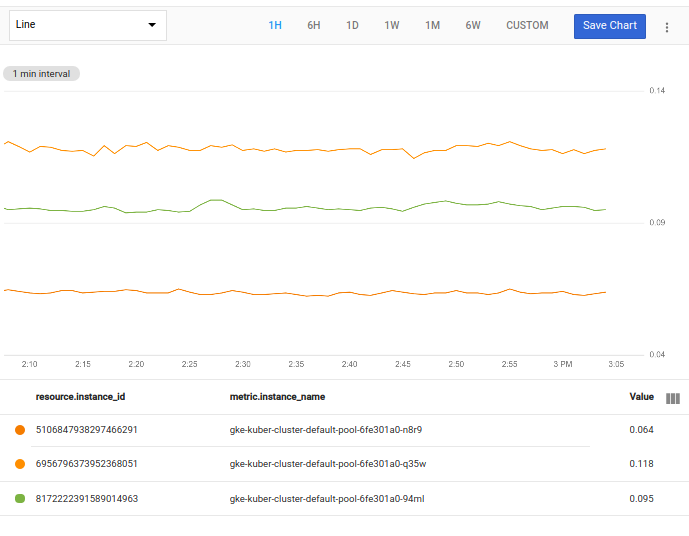
gke로 시작하는 인스턴스 이름이 없는 경우 이 쿼리를 시도하기 전에 필터를 변경하세요. 예를 들어 이름 앞에 apache가 있는 VM 인스턴스가 있는 경우 다음 필터를 사용합니다.
| filter instance_name =~ 'apache.*'
filter 표현식은 각 입력 시계열에 대해 한 번씩 평가됩니다.
표현식이 true로 평가되면 해당 시계열이 출력에 포함됩니다. 이 예시에서 필터 표현식은 각 시계열의 instance_name 라벨에서 정규 표현식 일치 =~를 수행합니다. 라벨 값이 정규 표현식 'gke.*'와 일치하면 시계열이 출력에 포함됩니다. 그렇지 않으면 시계열이 출력에서 삭제됩니다.
필터링에 대한 상세 내용은 filter 참조 페이지를 확인하세요.
filter 술부는 부울 값을 반환하는 임의의 표현식일 수 있습니다. 자세한 내용은 표현식을 참조하세요.
그룹화 및 집계
그룹화를 사용하면 특정 측정기준에 따라 시계열을 그룹화할 수 있습니다. 집계를 통해 그룹의 모든 시계열을 하나의 출력 시계열로 결합합니다.
다음 쿼리는 초기 fetch 작업의 출력을 필터링하여 us-central로 시작하는 영역의 리소스에서 이러한 시계열만 유지합니다. 그런 다음 시계열을 영역별로 그룹화하고 mean 집계를 사용하여 결합합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
| group_by [zone], mean(val())
group_by 작업으로 생성된 테이블에는 영역당 하나의 시계열이 있습니다.
다음 스크린샷은 결과 차트를 보여줍니다.
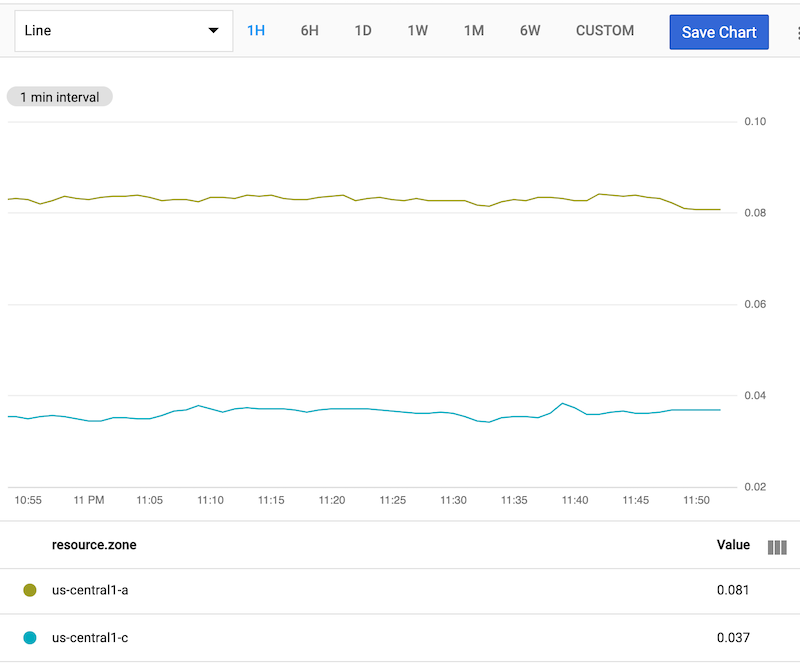
group_by 연산은 쉼표로 구분된 두 개의 인수(,)를 가집니다. 이 인수들은 정확한 그룹화 동작을 결정합니다. 이 예시 group_by [zone], mean(val())에서 인수는 아래와 같이 작동합니다.
첫 번째 인수인
[zone]는 시계열의 그룹화를 결정하는 지도 표현식입니다. 이 예시에서는 그룹화에 사용할 라벨을 지정합니다. 그룹화 단계는 출력zone값이 동일한 모든 입력 시계열을 하나의 그룹으로 수집합니다. 이 예시에서 표현식은 한 영역의 Compute Engine VM에서 시계열을 수집합니다.출력 시계열에는 그룹의 입력 시계열에서 복사한 값이 있는
zone라벨만 있습니다. 입력 시계열의 다른 라벨은 출력 시계열에서 삭제됩니다.지도 표현식은 목록 라벨보다 훨씬 더 많은 작업을 수행할 수 있습니다. 자세한 내용은
map참조 페이지를 확인하세요.두 번째 인수
mean(val())은 각 그룹의 시계열을 하나의 출력 시계열로 결합하거나 집계하는 방법을 결정합니다. 그룹의 출력 시계열의 각 지점은 그룹의 모든 입력 시계열에서 동일한 타임스탬프로 지점들을 집계한 결과입니다.이 예시의 집계 함수
mean은 집계 값을 결정합니다.val()함수는 집계할 지점을 반환하고, 집계 함수는 해당 지점에 적용됩니다. 이 예시에서는 각 출력 시점에 영역에 있는 가상 머신의 CPU 사용률 평균을 가져옵니다.mean(val())표현식은 집계 표현식의 예시입니다.
group_by 작업은 항상 그룹화와 집계를 결합합니다.
그룹화를 지정하고 집계 인수를 생략하면 group_by가 기본 집계인 aggregate(val())을 사용하여 데이터 유형에 적합한 함수를 선택합니다. 기본 집계 함수 목록은 aggregate를 참조하세요.
로그 기반 측정항목에 group_by 사용
다음과 같은 문자열을 포함한 긴 항목 집합에서 처리된 데이터 포인트 수를 추출하기 위해 배포 로그 기반 측정항목을 만들었다고 가정해 보겠습니다.
... entry ID 1 ... Processed data points 1000 ... ... entry ID 2 ... Processed data points 1500 ... ... entry ID 3 ... Processed data points 1000 ... ... entry ID 4 ... Processed data points 500 ...
처리된 모든 데이터 포인트 수를 표시하는 시계열을 만들려면 다음과 같이 MQL을 사용합니다.
fetch global
| metric 'logging.googleapis.com/user/metric_name'
| group_by [], sum(sum_from(value))
로그 기반 배포 측정항목을 만들려면 배포 측정항목 구성을 참조하세요.
그룹에서 열 제외
매핑의 drop 한정자를 사용하여 그룹에서 열을 제외할 수 있습니다.
예를 들어 Kubernetes core_usage_time 측정항목에는 6개의 열이 있습니다.
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by [project_id, location, cluster_name, namespace_name, container_name]
pod_name을 그룹화할 필요가 없으면 drop을 사용하여 제외할 수 있습니다.
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by drop [pod_name]
시계열 선택
이 섹션의 예시는 입력 테이블에서 특정 시계열을 선택하는 방법을 보여줍니다.
상단 또는 하단 시계열 선택
프로젝트 내에서 CPU 사용률이 가장 높은 Compute Engine 인스턴스 3개의 시계열 데이터를 보려면 다음 쿼리를 입력합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3
다음 스크린 샷은 한 프로젝트의 결과입니다.
top를 bottom로 바꾸면 CPU 사용률이 가장 낮은 시계열을 검색할 수 있습니다.
top 작업은 입력 테이블에서 지정된 수의 시계열이 포함된 테이블을 출력합니다. 출력에 포함된 시계열은 시계열의 일부 측면에 가장 큰 값을 가집니다.
이 쿼리는 시계열의 순서를 지정하지 않으므로 가장 최근 지점에 가장 큰 값을 가진 시계열을 반환합니다.
값이 가장 큰 시계열을 결정하는 방법을 지정하기 위해 top 작업에 인수를 제공할 수 있습니다. 예를 들어 이전 쿼리는 다음 쿼리와 동일합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, val()
val() 표현식은 적용되는 각 시계열에서 가장 최근 지점의 값을 선택하므로 쿼리는 가장 최근 지점의 값이 가장 큰 시계열을 반환합니다.
시계열의 일부 또는 모든 점에 대해 집계를 수행하여 정렬 값을 제공하는 표현식을 제공할 수 있습니다. 다음은 최근 10분 동안의 모든 지점의 평균을 가져옵니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, mean(val()).within(10m)
within 함수가 사용되지 않으면 mean 함수는 시계열에 표시된 모든 포인트의 값에 적용됩니다.
bottom 연산도 유사하게 작동합니다.
다음 쿼리는 max(val())를 사용하여 각 시계열에서 가장 큰 지점 값을 찾은 후 해당 값이 가장 작은 3개의 시계열을 선택합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| bottom 3, max(val())
다음 스크린샷은 급증이 가장 적은 스트림을 표시하는 차트를 보여줍니다.
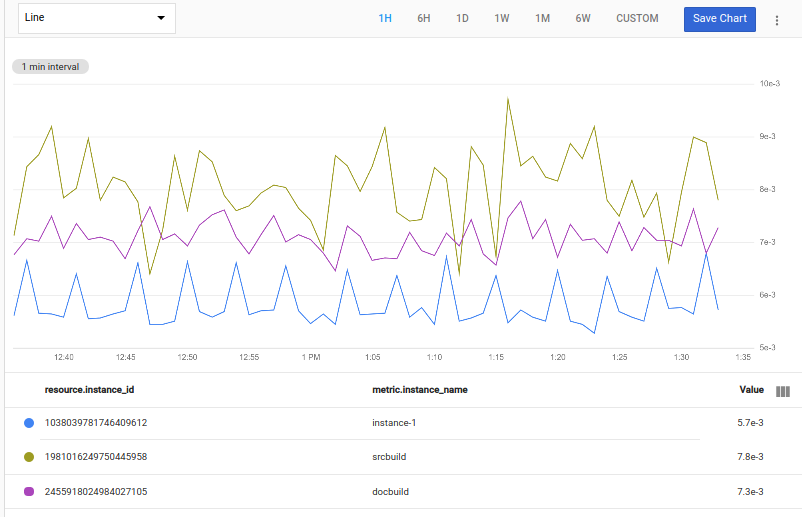
시계열에서 최상위 또는 최하위 n개 결과 제외
Compute Engine VM 인스턴스가 많은 시나리오가 있다고 가정해보세요. 이러한 인스턴스 중 일부가 대부분의 인스턴스보다 많은 메모리를 사용하고, 이러한 이상점으로 인해 대규모 그룹의 사용량 패턴을 확인하는 것이 어렵습니다. CPU 사용률 차트는 다음과 같이 표시됩니다.
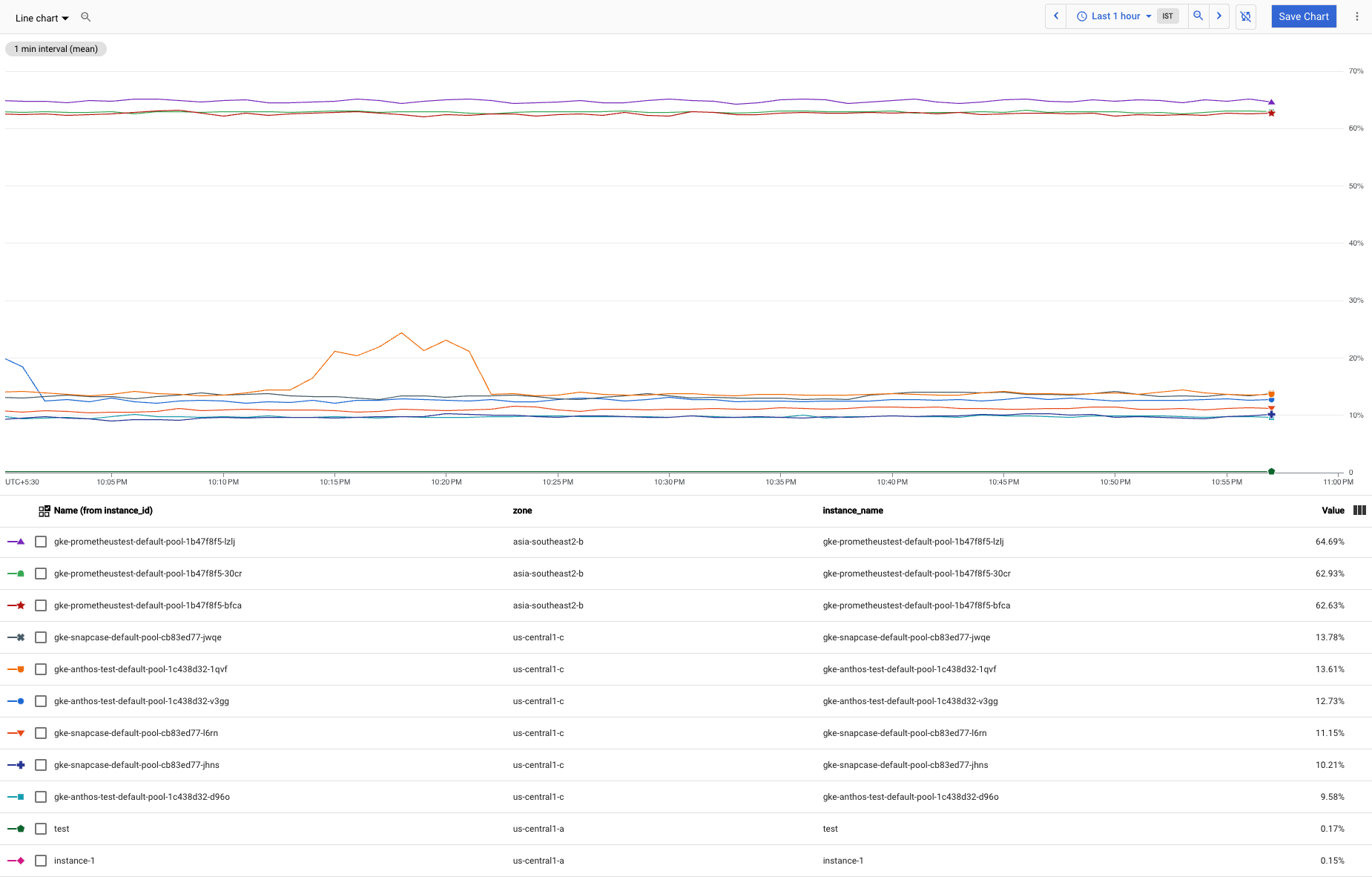
큰 그룹의 패턴을 보다 명확하게 볼 수 있도록 차트에서 3개의 이상점을 제외해야 합니다.
Compute Engine CPU 사용률에 대해 시계열을 검색하는 쿼리에서 최상위 3개 시계열을 제외하려면 top 테이블 작업을 사용하여 시계열을 식별하고 outer_join 테이블 작업을 사용하여 식별된 시계열을 결과에서 제외합니다. 다음 쿼리를 사용할 수 있습니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 3 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
fetch 작업은 모든 인스턴스에서 CPU 사용률에 대한 시계열 테이블을 반환합니다. 그런 후 이 테이블이 2개의 결과 테이블로 처리됩니다.
top n테이블 작업은 최고 값이 포함된 n개 시계열을 포함하는 테이블을 출력합니다. 여기에서는 n = 3입니다. 결과 테이블에는 제외할 3개의 시계열이 포함됩니다.최상위 3개 시계열이 포함된 테이블이
value테이블로 전달됩니다. 이 작업은 상위 3개 테이블의 각 시계열에 다른 열을 추가합니다. 이is_default_value열에는 상위 3개 테이블의 모든 시계열에 대한 불리언 값false가 제공됩니다.ident작업은 여기에 전달된 동일한 테이블인 CPU 사용률 시계열에 대한 원래 테이블을 반환합니다. 이 테이블의 시계열에는is_default_value열이 포함되지 않습니다.
그런 후 상위 3개 테이블 및 원래 테이블이 outer_join 테이블 작업으로 전달됩니다. 상위 3개 테이블은 조인에서 왼쪽 테이블이고 가져온 테이블은 조인에서 오른쪽 테이블입니다.
조인하려는 행에 존재하지 않는 필드의 값으로 true 값을 제공하도록 외부 조인이 설정되었습니다. 외부 조인의 결과가 병합된 테이블이고, 상위 3개 테이블의 행은 is_default_value 열을 false 값으로 유지하고, 상위 3개 테이블에 없던 원래 테이블의 모든 행은 true 열의 값이 is_default_value로 설정됩니다.
그런 후 조인의 결과 테이블이 filter 테이블 작업으로 전달되고 is_default_value 열에서 값이 false인 행을 필터로 제외합니다. 결과 테이블에는 상위 3개 테이블의 행이 없는 원래 가져온 테이블의 행이 포함됩니다. 이 테이블에는 추가된 is_default_column과 함께 원하는 시계열 집합이 포함됩니다.
마지막으로 조인으로 추가된 is_default_column 열을 삭제합니다. 그러면 출력 테이블이 원래 가져온 테이블과 동일한 열을 갖습니다.
다음 스크린샷은 이전 쿼리의 차트를 보여줍니다.
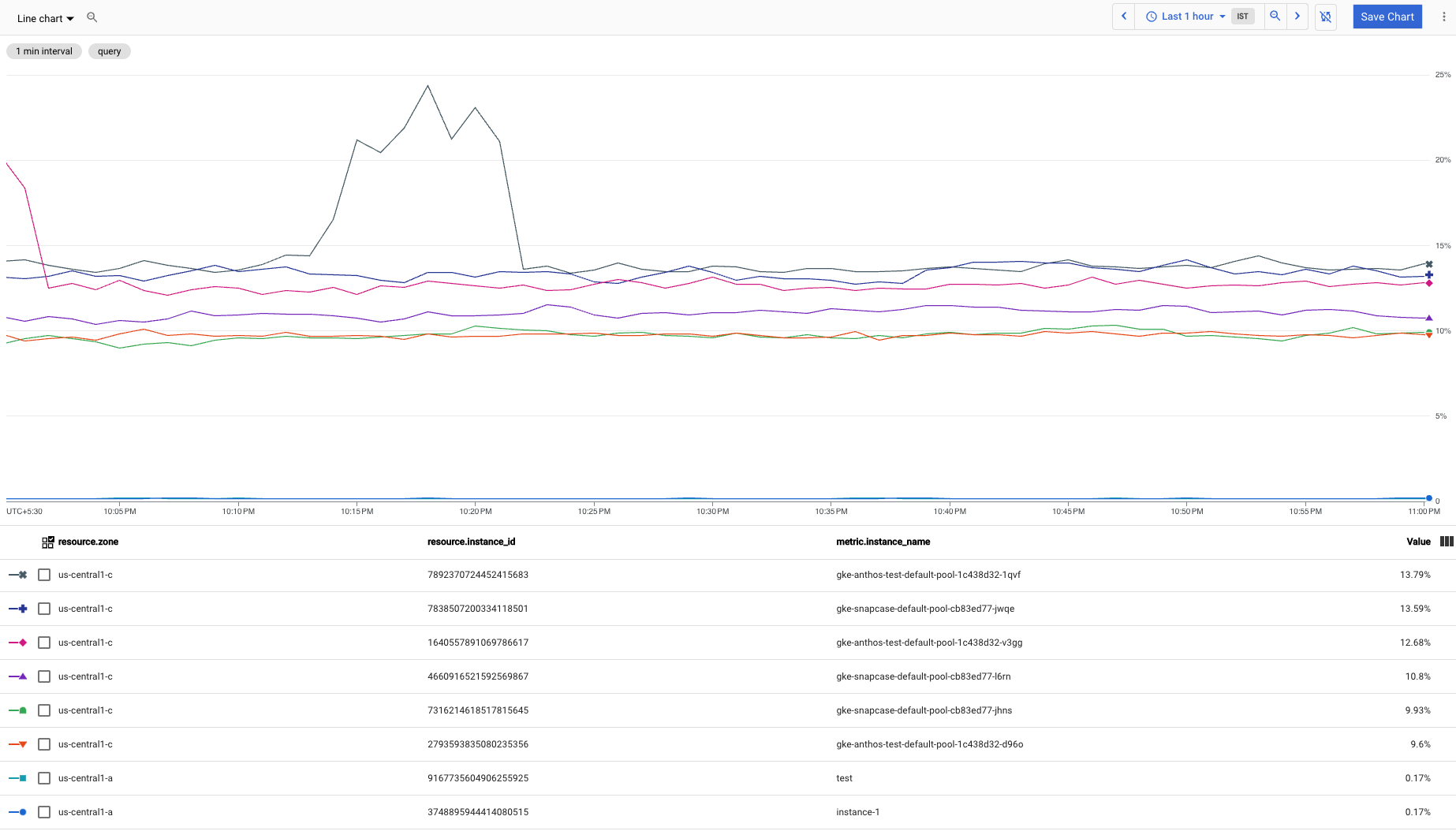
top n을 bottom
n으로 바꿔서 최하위 CPU 사용률을 포함하는 시계열을 제외하도록 쿼리를 만들 수 있습니다.
이상점을 제외하는 기능은 알림을 설정하지만 이상점으로 인해 알림이 계속해서 트리거되지 않도록 하려는 경우에 유용할 수 있습니다. 다음 알림 쿼리는 이전 쿼리와 동일한 제외 논리를 사용해서 최상위 2개 포드를 제외한 후 Kubernetes 포드 집합을 기준으로 CPU 제한 사용률을 모니터링합니다.
fetch k8s_container
| metric 'kubernetes.io/container/cpu/limit_utilization'
| filter (resource.cluster_name == 'CLUSTER_NAME' &&
resource.namespace_name == 'NAMESPACE_NAME' &&
resource.pod_name =~ 'POD_NAME')
| group_by 1m, [value_limit_utilization_max: max(value.limit_utilization)]
| {
top 2 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
| every 1m
| condition val(0) > 0.73 '1'
그룹에서 최상위 또는 최하위 선택
top 및 bottom 테이블 작업은 전체 입력 테이블에서 시계열을 선택합니다. top_by 및 bottom_by 작업은 테이블에서 시계열을 그룹화한 후 각 그룹에서 몇 개의 시계열을 선택합니다.
다음 쿼리는 각 영역에서 최댓값이 가장 높은 시계열을 선택합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 1, max(val())
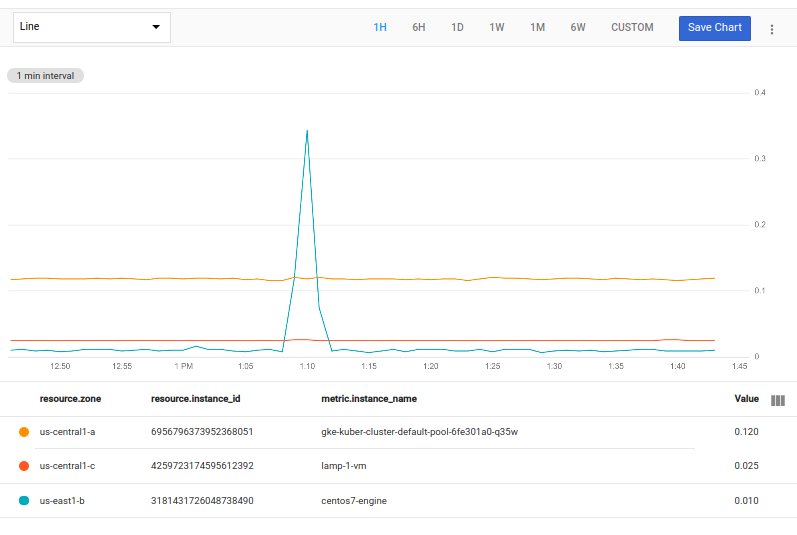
[zone] 표현식은 그룹이 zone 열의 값이 동일한 시계열로 구성되어 있음을 나타냅니다.
top_by의 1는 각 영역 그룹에서 선택할 시계열 수를 나타냅니다. max(val()) 표현식은 각 시계열에서 차트의 시간 범위 중 최대값을 찾습니다.
max 대신 아무 집계 함수나 사용할 수 있습니다.
예를 들어 다음은 mean 애그리게이터를 사용하고 within를 사용하여 정렬 범위를 20분으로 지정합니다. 그리고 각 영역의 상위 2개 시계열을 선택합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 2, mean(val()).within(20m)
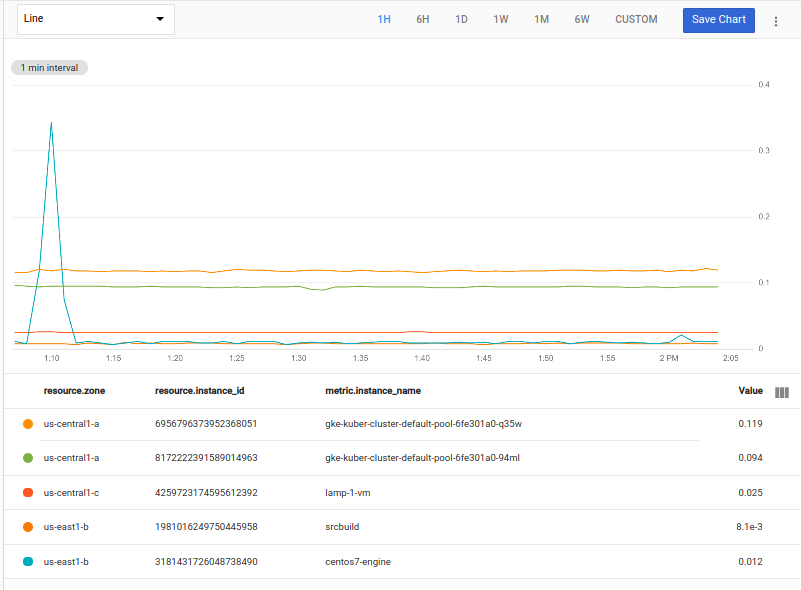
이전 예시에서는 us-central-c 영역에는 인스턴스가 하나뿐이므로 하나의 시계열만 반환됩니다. 즉, 그룹에 '상위 2개'가 없습니다.
union으로 선택 항목 결합
top 및 bottom 같은 선택 작업을 조합하여 둘 다 표시하는 차트를 만들 수 있습니다. 예를 들어 다음 쿼리는 최댓값이 있는 단일 시계열과 단일 시계열을 반환합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 1, max(val())
;
bottom 1, min(val())
}
| union
결과 차트는 가장 높은 값을 포함하는 행 1개와 가장 낮은 값을 포함하는 행 2개를 보여줍니다.
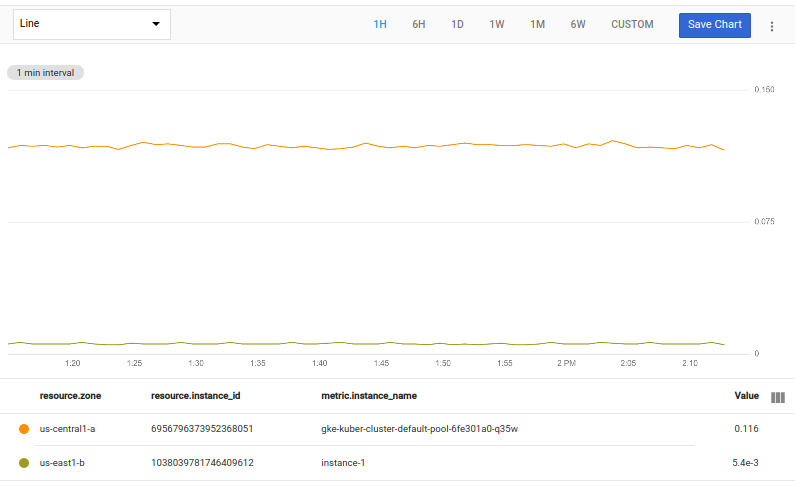
중괄호({ })를 사용하여 작업 시퀀스를 지정할 수 있으며, 각 작업 테이블은 하나의 시계열을 출력으로 생성합니다. 개별 작업은 세미콜론 ;으로 구분합니다.
이 예시에서 fetch 작업은 단일 테이블을 반환합니다. 이 테이블은 시퀀스의 두 작업(top 작업 및 bottom 작업)으로 각각 파이핑됩니다. 이러한 각 작업은 동일한 입력 테이블을 기반으로 출력 테이블을 만듭니다. 그런 다음 union 작업은 두 테이블을 하나의 테이블로 결합하여 차트에 표시됩니다.
참조 주제 쿼리 구조에서 { }를 사용한 시퀀싱 작업에 대해 자세히 알아보세요.
한 라벨에 대한 여러 값과 시계열 조합
동일한 측정항목 유형에 여러 시계열이 있고 몇 가지 시계열을 하나로 결합한다고 가정해 보겠습니다. 단일 라벨의 값을 기준으로 선택하려는 경우에는 측정항목 탐색기에서 쿼리 빌더 인터페이스를 사용하여 쿼리를 만들 수 없습니다. 동일한 라벨의 값을 두 개 이상 필터링해야 하지만 쿼리 빌더 인터페이스에서는 선택할 모든 필터와 일치하는 시계열을 사용해야 합니다. 라벨 일치는 AND 테스트입니다. 시계열은 동일한 라벨에 서로 다른 두 값을 포함할 수 없지만 쿼리 빌더의 필터에 대한 OR 테스트는 만들 수 없습니다.
다음 쿼리는 두 개의 특정 Compute Engine 인스턴스에 대한 Compute Engine instance/disk/max_read_ops_count 측정항목의 시계열을 검색하고 1분 간격으로 출력을 정렬합니다.
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| every 1m
다음 차트는 이 쿼리의 결과를 보여줍니다.
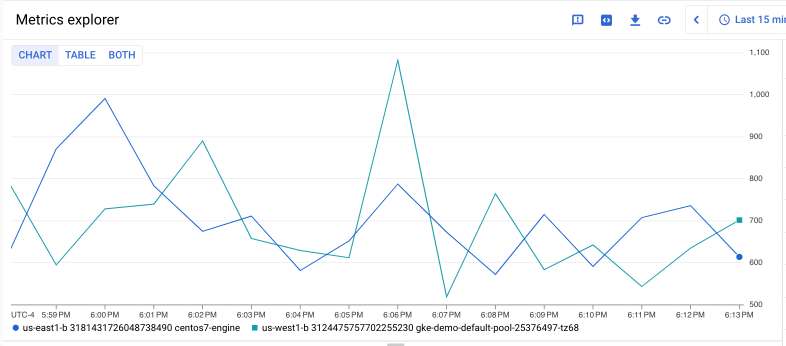
이러한 두 VM의 최대 max_read_ops_count 값 합계를 찾고 합산하려면 다음을 수행하면 됩니다.
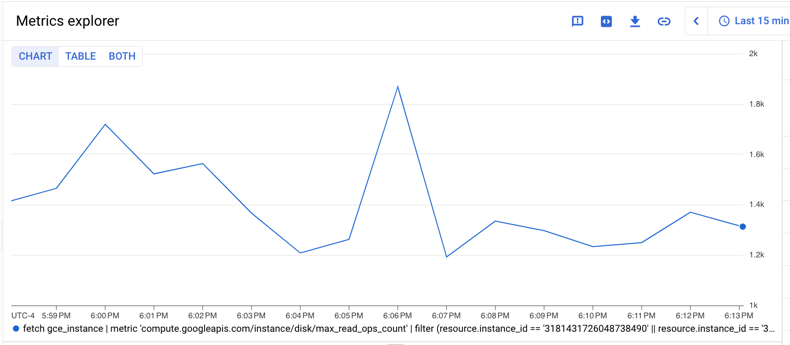
group_by테이블 연산자를 사용하고 동일한 1분 정렬 기간을 지정하고max애그리게이터로 해당 기간 동안 집계하여 각 시계열의 최댓값을 찾아 출력 테이블에max_val_of_read_ops_count_max라는 열을 만듭니다.max_val_of_read_ops_count_max열에서group_by테이블 연산자와sum애그리게이터를 사용하여 시계열의 합계를 찾습니다.
다음은 쿼리를 보여줍니다.
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| group_by 1m, [max_val_of_read_ops_count_max: max(value.max_read_ops_count)]
| every 1m
| group_by [], [summed_value: sum(max_val_of_read_ops_count_max)]
다음 차트는 이 쿼리의 결과를 보여줍니다.
시간 및 스트림 간 백분위수 통계 계산
각 스트림에 대해 슬라이딩 구간에서 개별적으로 백분위수 스트림 값을 계산하려면 일시적인 group_by 연산을 사용하세요. 예를 들어 다음 쿼리는 1시간 슬라이딩 구간 동안 스트림의 99번째 백분위수 값을 계산합니다.
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by 1h, percentile(val(), 99) | every 1m
한 스트림 내의 시간이 아니라 여러 스트림의 특정 시점에서 동일한 백분위수 통계를 계산하려면 공간 group_by 연산을 사용합니다.
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by [], percentile(val(), 99)
컴퓨팅 비율
Compute Engine VM 인스턴스에서 실행되고 Cloud Load Balancing을 사용하는 분산 웹 서비스를 빌드했다고 가정해 봅시다.
HTTP 500 응답 (내부 오류)을 총 요청 수로 반환하는 요청의 비율을 보여주는 차트, 즉 요청 실패 비율을 확인할 수 있습니다. 이 섹션에서는 요청 실패 비율을 계산하는 여러 가지 방법을 보여줍니다.
Cloud Load Balancing은 모니터링 리소스 유형 http_lb_rule을 사용합니다.
http_lb_rule 모니터링 리소스 유형에는 규칙에 정의된 URL의 프리픽스를 기록하는 matched_url_path_rule 라벨이 있는데 기본값은 UNMATCHED입니다.
loadbalancing.googleapis.com/https/request_count 측정항목 유형에는 response_code_class 라벨이 있습니다. 이 라벨은 응답 코드 클래스를 캡처합니다.
outer_join 및 div 사용
다음 쿼리는 프로젝트의 각 http_lb_rule 모니터링 리소스에서 matched_url_path_rule 라벨의 각 값에 대한 500 응답을 결정합니다. 그런 다음에 이 실패 횟수 테이블을 모든 응답 수를 포함하는 원래 테이블과 조인하고 총 응답 수 대비 실패 응답의 비율을 표시합니다.
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| outer_join 0
| div
다음 차트는 한 프로젝트의 결과입니다.
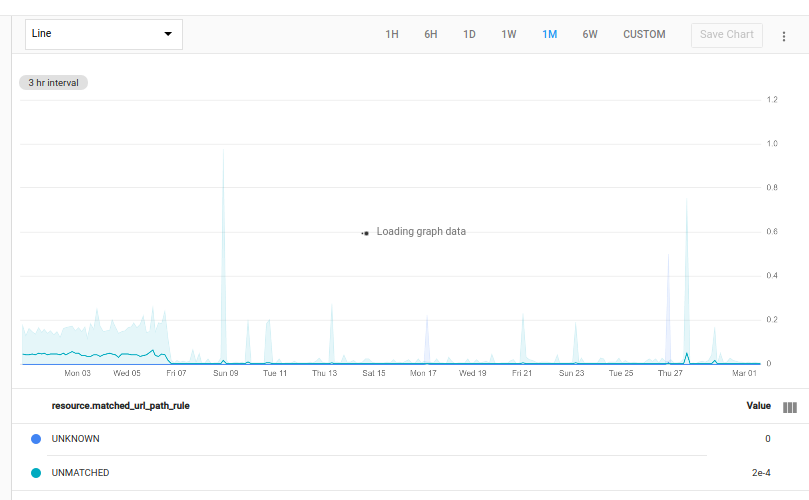
차트의 선을 주변에 색칠된 영역은 최소/최대 대역입니다. 자세한 내용은 최소/최대 대역을 참조하세요.
fetch 작업은 모든 부하 분산 쿼리의 요청 수를 포함하는 시계열 테이블을 출력합니다. 이 테이블은 중괄호로 된 두 가지 연산 시퀀스를 통해 두 가지 방법으로 처리됩니다.
filter response_code_class = 500은 값500에response_code_class라벨을 가지는 시계열만 출력합니다. 결과 시계열은 HTTP 5xx(오류) 응답 코드로 요청을 계산합니다.다음 표는 비율의 분자입니다.
ident또는 identity 작업은 입력을 출력하므로 원래 가져오기 한 테이블을 반환합니다. 모든 응답 코드의 개수가 카운트된 시계열이 포함된 표입니다.이 테이블은 비율의 분모입니다.
filter 및 ident 작업으로 생성된 분자 및 분모 테이블은 group_by 작업에서 별도로 처리됩니다.
group_by 작업은 각 테이블의 시계열을 matched_url_path_rule 라벨 값으로 그룹화하고 라벨의 각 값에 대한 합계를 계산합니다. 이 group_by 작업은 합계 함수를 명시적으로 지정하지 않으므로 기본값 sum가 사용됩니다.
필터링된 테이블의 경우
group_by결과는 각matched_url_path_rule값에 대해500응답을 반환하는 요청 수입니다.ID 테이블의 경우
group_by결과는 각matched_url_path_rule값의 총 요청 수입니다.
이 테이블들은 outer_join 작업으로 파이핑됩니다. 이 작업은 시계열을 두 입력 테이블 각각에서 하나씩 일치하는 라벨 값과 연결합니다. 페어링된 시계열은 한 시계열의 각 지점의 타임스탬프를 다른 시계열의 지점 타임스탬프와 일치 시켜 압축됩니다. 일치하는 지점 쌍마다 outer_join은 각 입력 테이블에서 하나씩 두 개의 값이 있는 단일 출력 점을 생성합니다.
압축된 시계열은 두 입력 시계열과 동일한 라벨을 가진 조인에 의해 출력됩니다.
외부 조인을 사용하는 경우 두 번째 테이블의 점이 첫 번째 테이블에 일치하는 점이 없으면 대기 값을 제공해야 합니다. 이 예시에서는 outer_join 작업의 인수로 값이 0인 점을 사용합니다.
마지막으로 div 연산은 두 개의 값을 갖는 각 점을 취해 단일 URL을 반환합니다. 즉, 각 URL 맵의 모든 응답에 대한 응답 500개의 비율입니다.
여기서 문자열 div는 실제로 2개의 숫자 값을 나타내는 div 함수의 이름입니다. 하지만 여기서 이 역할은 작업으로 사용됩니다. 작업으로 사용되는 경우 div 같은 함수는 각 입력 지점에 두 개의 값(이 join이 보장 함)을 예상하고 해당 출력 지점에 대해 단일 값을 생성합니다.
쿼리의 | div 부분은 | value val(0) / val(1)의 바로가기입니다.
value 연산을 사용하면 입력 테이블의 값 열에서 임의의 표현식을 사용하여 출력 테이블의 값 열을 생성할 수 있습니다.
자세한 내용은 value 작업 및 표현식의 참조 페이지를 확인하세요.
ratio 사용
div 함수는 두 값에 대한 함수로 대체할 수 있지만 비율이 너무 자주 사용되기 때문에 MQL은 직접 비율을 계산하는 ratio 테이블 작업을 제공합니다.
다음 쿼리는 outer_join 및 div를 사용하는 이전 버전과 동일합니다.
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| ratio
이 버전에서 ratio 작업은 이전 버전의 outer_join 0 | div 작업을 대체하여 동일한 결과를 생성합니다.
분자와 분모 입력 모두 MQL outer_join에 필요한 각 시계열을 식별하는 동일한 라벨이 있는 경우 ratio는 outer_join만 사용하여 분자에 0을 제공합니다. 분자 입력에 추가 라벨이 있으면 분모에서 누락된 지점에 대한 출력이 없습니다.
group_by 및 / 사용
모든 응답에 대한 오류 응답의 비율을 계산하는 또 다른 방법이 있습니다. 이 경우 비율의 분자 및 분모는 동일 시계열에서 파생되므로 단독으로 그룹화만으로 비율을 계산할 수도 있습니다. 다음 쿼리는 이 접근 방식을 보여줍니다.
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| group_by [matched_url_path_rule],
sum(if(response_code_class = 500, val(), 0)) / sum(val())
이 쿼리는 두 합계의 비율을 기반으로 하는 집계 표현식을 사용합니다.
첫 번째
sum은if함수를 사용하여 500 값 라벨을 카운트하고 나머지는 0으로 계산합니다.sum함수는 500을 반환한 요청 수를 계산합니다.두 번째
sum모든 요청 수val()을 더합니다.
그런 다음 두 합계를 나누어 모든 응답에 대한 500개 응답의 비율을 계산합니다. 이 쿼리는 outer_join 및 div 사용과 ratio 사용의 쿼리와 동일한 결과를 생성합니다.
filter_ratio_by 사용
비율은 동일한 테이블에서 파생된 두 개의 합계를 나누는 경우가 많으므로, MQL은 이를 위해 filter_ratio_by 작업을 제공합니다. 다음 쿼리는 합계를 명시적으로 나누는 이전 버전과 동일합니다.
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| filter_ratio_by [matched_url_path_rule], response_code_class = 500
filter_ratio_by 연산의 첫 번째 피연산자(여기서 [matched_url_path_rule])는 응답을 그룹화하는 방법을 나타냅니다. 두 번째 연산(여기서 response_code_class = 500)은 분자의 필터링 표현식 역할을 합니다.
- 분모 테이블은 가져오기 한 테이블을
matched_url_path_rule로 그룹화하고sum을 사용하여 집계한 결과입니다. - 분모 테이블은 가져오기 한 테이블로, HTTP 응답 코드 5xx로 시계열을 필터링한 후
matched_url_path_rule로 그룹화하고sum을 사용하여 집계한 것입니다.
비율 및 할당량 측정항목
MQL을 사용하면 serviceruntime 할당량 측정항목과 리소스별 할당량 측정항목에 대한 쿼리 및 알림을 설정하여 할당량 소비를 모니터링할 수 있습니다. 예시를 포함한 자세한 내용은 할당량 측정항목 사용을 참조하세요.
산술 계산
때때로 차트를 작성하기 전에 데이터에 대한 산술 연산을 수행해야 할 수 있습니다. 예를 들어 시계열을 확장하거나, 데이터를 로그 배율로 변환하거나, 두 시계열의 합계를 차트로 표시할 수 있습니다. MQL에서 사용 가능한 산술 함수 목록은 산술을 참조하세요.
시계열을 확장하려면 mul 함수를 사용합니다. 예를 들어 다음 쿼리는 시계열을 검색한 다음 각 값에 10을 곱합니다.
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/read_bytes_count'
| mul(10)
두 시계열을 합산하려면 쿼리를 구성하여 시계열의 두 테이블을 가져오고 해당 결과를 조인한 다음 add 함수를 호출합니다. 다음 예시는 Compute Engine 인스턴스에서 읽고 쓴 바이트 수의 합계를 계산하는 쿼리를 보여줍니다.
fetch gce_instance
| { metric 'compute.googleapis.com/instance/disk/read_bytes_count'
; metric 'compute.googleapis.com/instance/disk/write_bytes_count' }
| outer_join 0
| add
읽은 바이트 수에서 쓴 바이트 수를 빼려면 add를 이전 표현식에서 sub로 바꿉니다.
MQL은 첫 번째 가져오기와 두 번째 가져오기에서 반환된 테이블 집합의 라벨을 사용하여 테이블 조인 방법을 결정합니다.
첫 번째 테이블에 두 번째 테이블에 없는 라벨이 포함된 경우 MQL은 테이블에서
outer_join작업을 수행할 수 없으므로 오류를 보고합니다. 예를 들어 다음 쿼리는metric.instance_name라벨이 첫 번째 테이블에 있지만 두 번째 테이블에는 없으므로 오류를 발생시킵니다.fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' } | outer_join 0 | add이 유형의 오류를 해결하는 한 가지 방법은 그룹화 절을 적용하여 두 테이블에 동일한 라벨이 있는지 확인하는 것입니다. 예를 들어 모든 시계열 라벨을 그룹화할 수 있습니다.
fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' | group_by [] ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' | group_by [] } | outer_join 0 | add두 테이블의 라벨이 일치하거나 두 번째 테이블에 첫 번째 테이블에 없는 라벨이 포함된 경우 외부 조인이 허용됩니다. 예를 들어 다음 쿼리는
metric.instance_name라벨이 두 번째 테이블에 있어도 첫 번째는 아니므로 오류를 일으키지 않습니다.fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/write_bytes_count' } | outer_join 0 | sub첫 번째 테이블에 있는 시계열에는 두 번째 테이블에 있는 여러 시계열과 일치하는 라벨 값이 있을 수 있으므로 MQL은 각 쌍에 대한 뺄셈 작업을 수행합니다.
타임 시프팅
현재 상황과 과거의 상황을 비교하고 싶을 수 있습니다. MQL은 과거 데이터를 현재 데이터와 비교할 수 있도록 데이터를 과거에서 현재 기간으로 이동하는 time_shift 테이블 작업을 제공합니다.
시간 경과 비율
다음 쿼리는 time_shift, join, div를 사용하여 지금과 1주일 전 사이에 각 영역에서 평균 사용률을 계산합니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by [zone], mean(val())
| {
ident
;
time_shift 1w
}
| join | div
다음 차트는 이 쿼리의 가능한 결과를 보여줍니다.
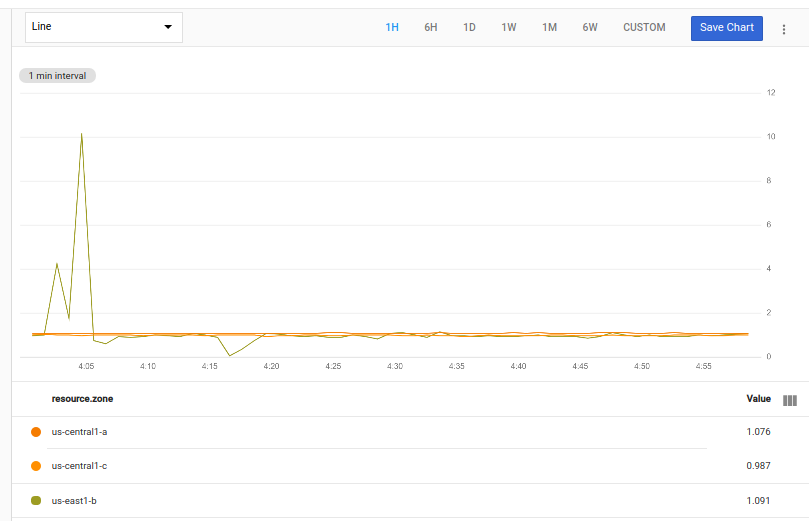
처음 두 작업은 시계열을 가져온 후 영역별로 그룹화하고 각각의 평균값을 계산합니다. 그러면 결과 테이블이 두 개의 작업으로 전달됩니다. 첫 번째 작업인 ident는 변경되지 않은 상태로 테이블을 전달합니다.
두 번째 작업 time_shift는 테이블의 값 타임스탬프에 기간(1주)을 추가하여 1주일 전부터의 데이터를 앞으로 옮깁니다. 이렇게 변경하면 두 번째 테이블의 이전 데이터에 대한 타임스탬프가 첫 번째 테이블의 현재 데이터에 대한 타임스탬프와 일치합니다.
그런 다음 변경되지 않은 테이블과 타임 시프팅 테이블은 내부 join을 사용하여 결합됩니다. join은 각 지점에 현재 사용률과 일주일 전의 사용률이 있는 시계열 테이블을 생성합니다.
그런 다음 쿼리는 div 작업을 사용하여 현재 값과 1주 전 값의 비율을 계산합니다.
과거 및 현재 데이터
time_shift와 union을 결합하면 이전 데이터와 현재 데이터를 동시에 표시하는 차트를 만들 수 있습니다. 예를 들어, 다음 쿼리는 현재와 일주일 전의 전체 평균 사용률을 반환합니다. union을 사용하면 동일한 차트에 두 개의 결과를 표시할 수 있습니다.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by []
| {
add [when: "now"]
;
add [when: "then"] | time_shift 1w
}
| union
다음 차트는 이 쿼리의 가능한 결과를 보여줍니다.
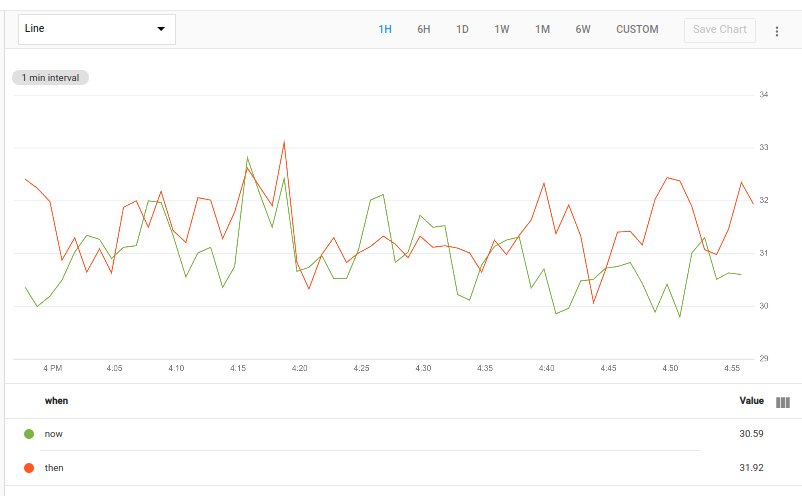
이 쿼리는 시계열을 가져온 후 group_by []를 사용하여 라벨이 없는 단일 시계열로 결합하고 CPU 사용률 데이터 포인트만 남깁니다. 이 결과는 두 가지 작업으로 전달됩니다.
첫 번째는 now값을 포함하는 when 라는 새 라벨에 열을 추가합니다.
두 번째는 then 값을 사용하여 when라는 라벨을 추가하고 결과를 time_shift 작업에 전달하여 값을 일주일씩 이동합니다. 이 쿼리는 add 맵 수정자를 사용합니다. 자세한 내용은 지도를 참조하세요.
단일 시계열의 데이터가 포함된 두 테이블이 union에 전달되면 두 입력 테이블의 시계열이 포함된 테이블 하나가 생성됩니다.
다음 단계
MQL 언어의 구조의 개요는 MQL 언어 정보를 참조하세요.
MQL에 대한 상세 설명은 Monitoring Query Language 참조를 참고하세요.
차트와의 상호 작용에 대한 자세한 내용은 차트 다루기를 참조하세요.