이 문서에서는 프로젝트에서 수집된 시계열 데이터 표시를 위해 커스텀 대시보드에서 차트를 구성하는 방법을 설명합니다. 차트는 숫자 시계열 데이터만 표시할 수 있습니다. 차트 스타일 구성 방법에 대한 자세한 내용은 차트 표시 옵션 설정을 참조하세요.
표시할 데이터 선택
차트에 표시할 시계열을 구성하려면 메뉴에서 선택하여 쿼리를 빌드하거나 쿼리를 작성하면 됩니다. 쿼리를 작성할 때는 쿼리 언어를 선택한 후 쿼리 편집기 또는 텍스트 기반 인터페이스를 사용합니다.
Monitoring 쿼리 언어(MQL) 쿼리는 시계열을 지정하고 이러한 시계열을 그룹화하고 정렬하는 방법을 지정합니다. MQL 인터페이스는 추천 및 구문 검사가 포함된 코드 편집기를 지원합니다.
일반적으로는 MQL 쿼리를 다른 인터페이스에서 사용할 수 있는 양식으로 변환할 수 없습니다. 저장하지 않은 쿼리는 MQL 탭에서 전환할 때 삭제됩니다.
Prometheus 쿼리 언어(PromQL) 쿼리는 시계열을 지정하고 이러한 시계열을 그룹화하고 정렬하는 방법을 지정합니다. PromQL 인터페이스에서 제안사항이 있는 편집기를 지원합니다.
일반적으로는 PromQL 쿼리를 다른 인터페이스에서 사용할 수 있는 양식으로 변환할 수 없습니다. 저장하지 않은 쿼리는 PromQL 탭에서 전환할 때 삭제됩니다.
Monitoring 필터 쿼리는 시계열을 지정하지만 그룹화 또는 정렬 문을 포함하지 않습니다.
Monitoring이 차트로 작성할 수 있는 모든 시계열은 Monitoring 필터를 사용하여 지정할 수 있습니다. 예를 들어 VM에서 실행되는 프로세스 수를 차트로 작성하려면 함수를 지정하는 Monitoring 필터를 사용해야 합니다.
Monitoring 필터를 다른 인터페이스에 필요한 양식으로 변환하는 것이 항상 가능하지는 않습니다. 따라서 다른 인터페이스로 전환할 때 쿼리가 삭제될 수 있습니다.
쿼리는 일반적으로 측정항목 유형, 리소스 유형, 필터를 지정합니다.
측정항목 유형은 리소스에서 수집할 측정값을 식별합니다. 여기에 측정 대상과 측정값을 해석하는 방법에 대한 설명이 포함됩니다. 측정항목 유형을 측정항목이라고도 부릅니다. 'CPU 사용량'도 측정항목 예시 중 하나입니다. 개념 정보는 측정항목 유형을 참조하세요.
리소스 유형은 측정항목 데이터가 캡처된 리소스를 지정합니다. 리소스 유형은 모니터링 리소스 유형 또는 리소스라고도 합니다. 리소스 예시로는 'Compute Engine 가상 머신(VM) 인스턴스'가 있습니다. 개념 정보는 모니터링 리소스를 참조하세요.
MQL 및 PromQL 쿼리 모두 그룹화 및 정렬 문을 포함합니다. 그러나 Monitoring 필터를 작성하거나 메뉴를 사용해서 차트로 작성할 시계열을 선택할 때 메뉴를 사용해서 그룹화 및 정렬 설정을 구성합니다.
메뉴를 사용하여 쿼리 빌드
메뉴를 사용한 쿼리 빌드가 기본 구성입니다. 일반적으로 측정항목과 필터를 선택한 후 다른 인터페이스로 전환하면 선택 항목이 보존되고 해당 인터페이스에 맞게 형식이 다시 지정됩니다. 즉, 메뉴로 구성된 쿼리를 MQL 쿼리로 변환할 수 있습니다.
tune 빌더를 선택하여 다른 인터페이스에서 메뉴 기반 인터페이스로 돌아갈 수 있습니다. 하지만 쿼리는 삭제됩니다. 즉, MQL 쿼리를 상응하는 메뉴 기반 형식으로 변환할 수 없습니다.
메뉴를 사용하여 쿼리를 빌드하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서
 대시보드 페이지로 이동합니다.
대시보드 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- Google Cloud 콘솔의 툴바에서 Google Cloud 프로젝트를 선택합니다. App Hub 구성의 경우 App Hub 호스트 프로젝트 또는 앱 지원 폴더의 관리 프로젝트를 선택합니다.
다음 중 하나를 수행합니다.
- 새 대시보드를 만들려면 대시보드 만들기를 선택합니다.
- 기존 대시보드를 업데이트하려면 대시보드 목록에서 대시보드를 찾은 후 해당 이름을 선택합니다.
툴바에서 add 위젯 추가를 클릭합니다.
위젯 추가 대화상자에서 leaderboard 측정항목을 선택합니다.
쿼리 창의 툴바에서 다음을 수행합니다.
측정항목 요소에서 측정항목 선택 메뉴를 확장합니다.
측정항목 선택 메뉴에는 사용 가능한 측정항목 유형을 찾는 데 도움이 되는 기능이 포함되어 있습니다.
특정 측정항목 유형을 찾으려면 filter_list 필터 표시줄을 사용합니다. 예를 들어
util을 입력하면util이 포함된 항목이 표시되도록 메뉴를 제한합니다. 항목이 대소문자를 구분하지 않는 'contains' 테스트를 통과하면 표시됩니다.데이터가 없는 측정항목 유형을 포함하여 모든 측정항목 유형을 표시하려면 활성을 클릭합니다. 기본적으로 메뉴에는 데이터가 있는 측정항목 유형만 표시됩니다.
리소스 메뉴, 측정항목 카테고리 메뉴, 측정항목 메뉴에서 선택한 후 적용을 클릭합니다.
예를 들어 Compute Engine 가상 머신의 CPU 사용률을 차트로 표시하려면 VM 인스턴스, 인스턴스, CPU 사용률을 선택하고 적용을 클릭합니다.
리소스 메뉴에는 데이터가 수집되는 리소스가 나열됩니다. 리소스에 대해 측정항목이 기록되지 않으면 미지정을 선택합니다.
이전 단계를 완료하면 차트에 사용 가능한 시계열이 표시됩니다.
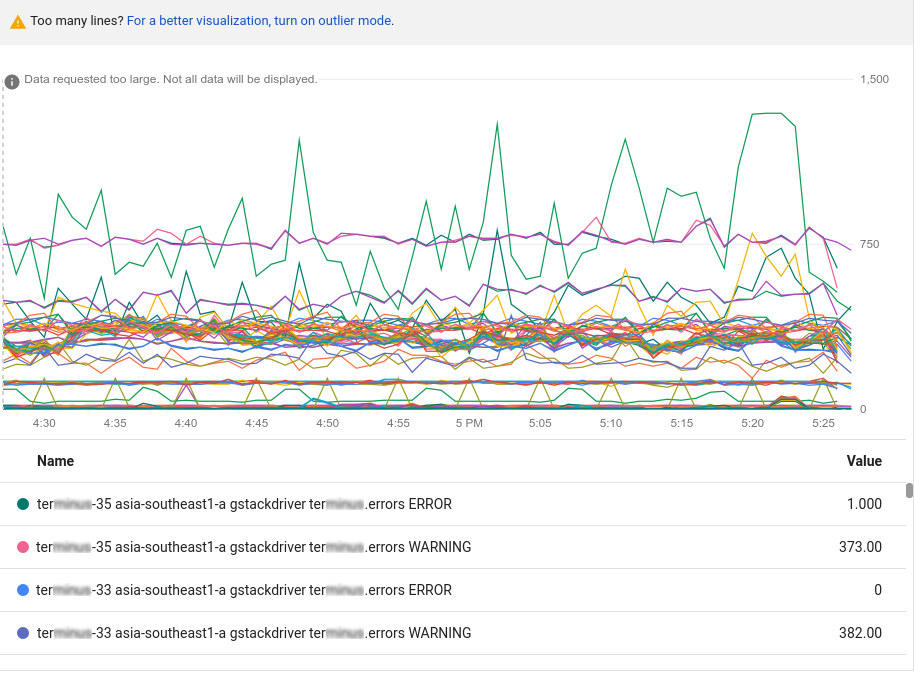
이전 차트에 표시할 수 있는 것보다 많은 데이터가 있습니다. 차트에 표시 가능한 선은 50개로 제한됩니다. 이 차트는 표시할 데이터가 너무 많음을 알립니다. 데이터 양을 줄이려면 정렬 및 한도 요소에 있는 필드를 사용합니다. 자세한 내용은 이상점 표시를 참조하세요.
필터링 및 집계 옵션을 사용하여 차트로 작성되는 데이터의 양을 줄일 수도 있습니다. 이러한 기법을 사용하면 차트의 진단 및 분석 효율을 높이고 사용자 인터페이스 자체의 성능과 응답성도 향상시킬 수 있습니다.
선택사항: 표시할 시계열을 제한하는 필터를 추가합니다. 다음 섹션에서는 필터링 옵션에 대해 설명합니다.
선택사항: 시계열을 그룹화하고 정렬하는 방법을 구성합니다. 자세한 내용은 차트 데이터 표시 방법 선택을 참조하세요.
대시보드에 변경사항을 적용하려면 툴바에서 적용을 클릭합니다. 변경사항을 삭제하려면 취소를 클릭합니다.
차트 데이터 필터링
필터를 사용하면 일부 기준 집합을 충족하는 시계열만 차트로 표시할 수 있습니다. 필터를 적용할 때는 차트 줄 수를 줄여서 차트 성능을 향상시킬 수 있습니다. 차트의 응답성을 개선할 수 있는 또 다른 방법은 집계 옵션을 구성하고 표시되는 시계열 수를 정렬하고 제한하는 것입니다. 자세한 내용은 이상점 표시를 참조하세요.
필터는 라벨, 비교 연산자, 값으로 구성됩니다. 예를 들어 zone 라벨이 "us-central1"로 시작하는 모든 시계열을 일치시키려면 정규 표현식을 사용하여 비교를 수행하는 zone=~"us-central1.*" 필터를 사용하면 됩니다. 다음과 같은 비교 연산자 4개가 있습니다.
- 같음(
=) - 같지 않음(
!=) - 정규 표현식 일치(
=~) - 정규 표현식이 일치하지 않음(
!=~)
프로젝트 ID 또는 리소스 컨테이너로 필터링할 때는 등호 연산자((=))를 사용해야 합니다. 다른 라벨로 필터링할 때는 지원되는 비교 연산자를 사용할 수 있습니다.
일반적으로 측정항목 및 리소스 라벨과 리소스 그룹을 기준으로 필터링할 수 있습니다.
필터링 기준을 여러 개 제공하면 해당 차트에 모든 기준을 충족하는 시계열인 논리적 AND만 표시됩니다.
Google Cloud 콘솔의 메뉴 기반 인터페이스를 사용할 때 필터를 추가하려면 다음을 수행합니다.
필터 요소에서 필터 추가를 클릭하고 메뉴에서 항목을 선택합니다.
비교를 변경하려면 비교 연산자 메뉴에서 값을 선택합니다.
값 필드에서 값을 입력하거나 선택합니다.
=또는!=의 직접 비교의 경우 메뉴에서 값을 선택하거나 값을 입력하고 확인을 클릭합니다.us-central1-a와 같은 값을 입력하거나starts_with또는ends_with로 시작하는 필터 문자열을 만들 수 있습니다. 예를 들어us-central1영역의 데이터를 표시하려면 필터 문자열starts_with("us-central1")를 입력하면 됩니다. 필터 문자열에 대한 자세한 내용은 Monitoring 필터를 참조하세요.메뉴 항목은 수신된 시계열에서 파생되므로 모니터링 리소스가 선택한 측정항목의 데이터를 생성하지 않는 경우 라벨 값을 입력해야 합니다.
=~또는!=~의 정규 표현식 비교의 경우에는 RE2 정규 표현식을 값 필드에 입력하고 확인을 클릭합니다. 예를 들어 정규 표현식us-central1-.*는 모든us-central1영역과 일치합니다.'a'로 끝나는 미국 영역과 일치시키려면 정규 표현식
^us.*.a$를 사용하면 됩니다.정규 표현식을 사용해
project_id리소스 라벨을 필터링할 수는 없습니다.예를 들어
us-central1영역 중 하나에서 시계열만 보려면zone=~"us-central1.*"필터를 적용합니다.
필터를 여러 개 추가하면 다음 사항이 적용됩니다.
동일한 라벨을 여러 번 사용해서 값 범위에 대해 필터를 지정할 수 있습니다.
모든 필터 기준은 논리적
AND로 구성되므로 충족되어야 합니다.
필터 값 또는 비교 연산자를 수정하려면 필터 요소에서 arrow_drop_down 메뉴를 클릭하고, 항목을 변경한 후 확인을 클릭합니다.
필터를 삭제하려면 cancel 취소를 클릭합니다.
MQL 쿼리 작성
MQL 또는 PromQL 쿼리를 입력하려면 다음 단계를 따르세요.
-
Google Cloud 콘솔에서
대시보드 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- Google Cloud 콘솔의 툴바에서 Google Cloud 프로젝트를 선택합니다. App Hub 구성의 경우 App Hub 호스트 프로젝트 또는 앱 지원 폴더의 관리 프로젝트를 선택합니다.
다음 중 하나를 수행합니다.
- 새 대시보드를 만들려면 대시보드 만들기를 선택합니다.
- 기존 대시보드를 업데이트하려면 모든 대시보드 목록에서 대시보드를 찾은 후 해당 이름을 선택합니다.
툴바에서 add 위젯 추가를 클릭합니다.
위젯 추가 대화상자에서 leaderboard 측정항목을 선택합니다.
쿼리 빌더 창의 툴바에서 이름이 code MQL 또는 code PromQL인 버튼을 선택합니다.
언어 전환 버튼에 MQL이 선택되어 있는지 확인합니다. 언어 전환 버튼은 쿼리 형식을 지정할 수 있는 동일한 툴바에 있습니다.
선택사항: 자동 실행 전환 버튼을 중지합니다.
쿼리 편집기에 쿼리를 입력합니다. 예를 들어 Google Cloud 프로젝트에서 VM 인스턴스 CPU 사용률을 차트로 표시하려면 다음 쿼리를 사용합니다.
fetch gce_instance | metric 'compute.googleapis.com/instance/cpu/utilization' | group_by 1m, [value_utilization_mean: mean(value.utilization)] | every 1mMQL에 대한 자세한 내용은 다음 문서를 참조하세요.
쿼리 실행을 클릭합니다.
자동 실행 전환 버튼이 사용 설정되면 쿼리 실행 버튼이 표시되지 않습니다.
PromQL 쿼리 작성
MQL 또는 PromQL 쿼리를 입력하려면 다음 단계를 따르세요.
-
Google Cloud 콘솔에서
대시보드 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- Google Cloud 콘솔의 툴바에서 Google Cloud 프로젝트를 선택합니다. App Hub 구성의 경우 App Hub 호스트 프로젝트 또는 앱 지원 폴더의 관리 프로젝트를 선택합니다.
다음 중 하나를 수행합니다.
- 새 대시보드를 만들려면 대시보드 만들기를 선택합니다.
- 기존 대시보드를 업데이트하려면 모든 대시보드 목록에서 대시보드를 찾은 후 해당 이름을 선택합니다.
툴바에서 add 위젯 추가를 클릭합니다.
위젯 추가 대화상자에서 leaderboard 측정항목을 선택합니다.
쿼리 빌더 창의 툴바에서 이름이 code MQL 또는 code PromQL인 버튼을 선택합니다.
PromQL 전환 버튼에 PromQL이 선택되어 있는지 확인합니다. 언어 전환 버튼은 쿼리 형식을 지정할 수 있는 동일한 툴바에 있습니다.
선택사항: 자동 실행 전환 버튼을 중지합니다.
쿼리 편집기에 쿼리를 입력합니다. 예를 들어 Google Cloud 프로젝트에서 VM 인스턴스 평균 CPU 사용률을 차트로 표시하려면 다음 쿼리를 사용합니다.
avg(compute_googleapis_com:instance_cpu_utilization)PromQL 사용에 대한 자세한 내용은 Cloud Monitoring의 PromQL을 참조하세요.
쿼리 실행을 클릭합니다.
자동 실행 전환 버튼이 사용 설정되면 쿼리 실행 버튼이 표시되지 않습니다.
Monitoring 필터 쿼리 작성
다음을 수행하려는 경우 Monitoring 필터를 입력할 수 있는 직접 필터 모드를 사용해야 합니다.
- 서비스 수준 목표(SLO)를 표시합니다.
- 가상 머신(VM)에서 실행되는 프로세스 수를 표시합니다.
- 아직 데이터가 없는 커스텀 측정항목을 표시합니다.
- 데이터가 아직 없는 라벨을 기준으로 시계열을 필터링합니다.
Monitoring 필터 또는 이에 상응하는 측정항목 필터는 Monitoring에서 차트로 작성할 시계열을 식별하기 위해 사용되는 표현식입니다.
예를 들어 다음 표현식은 이름에 nginx가 포함된 프로세스 수를 표시하는 차트를 생성합니다.
select_process_count("monitoring.regex.full_match(\".*nginx.*\")")
resource.type="gce_instance"
또한 Monitoring 필터를 사용해서 해당 리소스 및 측정항목 유형에 따라 시계열을 식별할 수 있습니다. 다음 표현식은 us-east1-b 영역에 있는 모든 Google Cloud 가상 머신 인스턴스의 로그 항목 수를 보여주는 차트를 표시합니다.
metric.type="logging.googleapis.com/log_entry_count"
resource.type="gce_instance"
resource.label."zone"="us-east1-b"
모니터링 필터를 입력하려면 다음을 수행합니다.
-
Google Cloud 콘솔에서
대시보드 페이지로 이동합니다.
검색창을 사용하여 이 페이지를 찾은 경우 부제목이 Monitoring인 결과를 선택합니다.
- Google Cloud 콘솔의 툴바에서 Google Cloud 프로젝트를 선택합니다. App Hub 구성의 경우 App Hub 호스트 프로젝트 또는 앱 지원 폴더의 관리 프로젝트를 선택합니다.
다음 중 하나를 수행합니다.
- 새 대시보드를 만들려면 대시보드 만들기를 선택합니다.
- 기존 대시보드를 업데이트하려면 대시보드 목록에서 대시보드를 찾은 후 해당 이름을 선택합니다.
툴바에서 add 위젯 추가를 클릭합니다.
위젯 추가 대화상자에서 leaderboard 측정항목을 선택합니다.
측정항목 요소에서 help_outline 도움말을 클릭한 후 직접 필터 모드를 선택합니다.
측정항목 및 필터 요소가 삭제되고 텍스를 입력할 수 있는 필터 요소가 생성됩니다.
직접 필터 모드로 전환하기 전 리소스 유형, 측정항목 또는 필터를 선택한 경우 해당 설정이 필터 요소에 표시됩니다.
필터 요소의 텍스트 영역에 모니터링 필터 표현식을 입력합니다. 구문 정보는 다음 문서를 참조하세요.
직접 필터 모드를 사용할 때 필터에 맞는 데이터가 없으면 오류가 표시됩니다. 일반적인 오류 메시지에는
Chart definition invalid및No data is available for the selected timeframe.이 있습니다.선택사항: 시계열을 그룹화하고 정렬하는 방법을 구성합니다. 자세한 내용은 차트 데이터 표시 방법 선택을 참조하세요.
메뉴 기반 인터페이스로 돌아가려면 tune 직접 필터 모드 종료를 클릭합니다.
차트 데이터를 표시하는 방법 선택
시계열 데이터를 선택한 후 다음 단계는 데이터가 표시되는 방식을 결정하는 것입니다. 예를 들어 각 시계열을 표시할 것인지 아니면 시계열을 결합할 것인지 결정합니다.
이 섹션에서는 집계 필드를 설정하는 방법을 설명합니다. 집계는 시계열 내의 데이터 포인트 정렬로 구성되며, 서로 다른 시계열을 하나로 결합합니다. 집계에 대한 자세한 설명은 필터링 및 집계: 시계열 조작을 참조하세요.
- 보기 옵션에 대한 자세한 내용은 차트 표시 옵션 설정을 참조하세요.
- 차트와의 상호작용에 대한 자세한 내용은 차트 데이터 탐색을 참조하세요.
이 섹션의 콘텐츠는 MQL 또는 PromQL을 사용하여 차트로 작성할 데이터를 선택할 때 적용되지 않습니다.
시계열 조합
서로 다른 시계열을 조합하여 측정항목에 대해 반환되는 데이터 양을 줄일 수 있습니다. 여러 시계열을 조합하려면 일반적으로 하나 이상의 라벨과 함수를 지정합니다. 지정된 모든 라벨에 대해 값이 동일한 시계열이 그룹으로 지정된 후 사용자가 지정한 함수가 이러한 시계열을 새로운 시계열로 조합합니다.
집계 요소의 설정은 차트에 표시되는 시계열 수를 변경할 수 있습니다. 이 요소의 기본 설정은 선택한 측정항목 유형에 따라 결정됩니다. 디스플레이를 수정하려면 다음을 수행합니다.
모든 시계열을 표시하려면 집계 요소에서 첫 번째 메뉴가 집계되지 않음으로, 두 번째 메뉴는 없음으로 설정되었는지 확인합니다.
시계열을 조합하려면 집계 요소에서 다음을 수행합니다.
첫 번째 메뉴를 확장하고 함수를 선택합니다.
차트가 새로고침되고 단일 시계열이 표시됩니다. 예를 들어 평균을 선택하면 모든 시계열의 평균이 시계열로 표시됩니다.
함수 메뉴는 평균, 최소, 최대, 합계와 같은 일반적인 대수 함수를 지원합니다. 시계열 수 집계 옵션은 측정항목 및 필터 설정과 일치하는 시계열 수를 집계합니다. 99번째 백분위수와 같은 백분위수 옵션은 측정항목 및 필터 설정과 일치하는 시계열에서 파생된 통계 값입니다.
라벨 값이 동일한 시계열을 조합하려면 두 번째 메뉴를 확장한 후 하나 이상의 라벨을 선택합니다.
차트가 새로고침되고 각각의 고유한 라벨 값 조합에 대해 하나의 시계열이 표시됩니다. 예를 들어 영역당 하나의 시계열을 표시하려면 두 번째 메뉴를 영역으로 설정합니다.
데이터 포인트 사이의 간격을 구성하려면 add 쿼리 요소 추가를 클릭하고 최소 간격을 선택한 후 값을 입력합니다.
예를 들어 함수를 합계로 설정하고 user_labels.version 라벨을 선택하면 user_labels.version 라벨의 각 값에 대해 하나의 시계열이 생성됩니다. 각 시계열의 데이터 포인트는 특정 버전에 대한 개별 시계열의 모든 값 합계에서 계산됩니다.
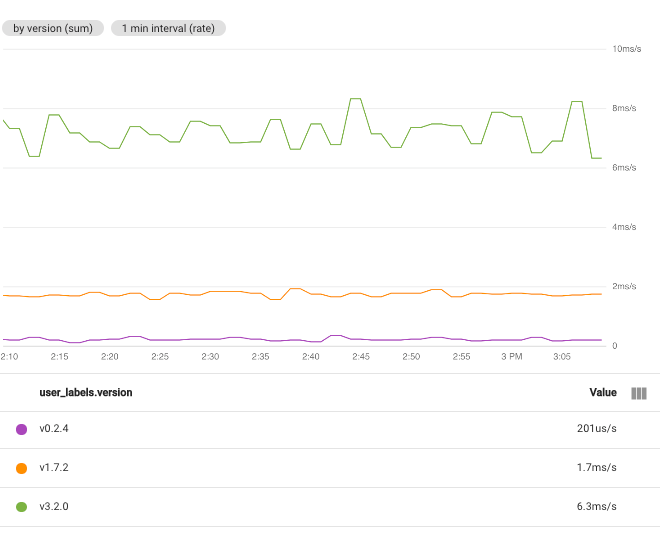
여러 라벨을 선택하면 선택한 라벨의 값이 동일한 시계열이 조합됩니다. 결과 차트는 라벨 값 조합마다 하나의 시계열을 표시합니다. 라벨을 지정하는 순서는 중요하지 않습니다. 다음 스크린샷은 시계열이 user_labels.version 및 system_labels.machine_image 라벨로 조합된 차트를 보여줍니다.
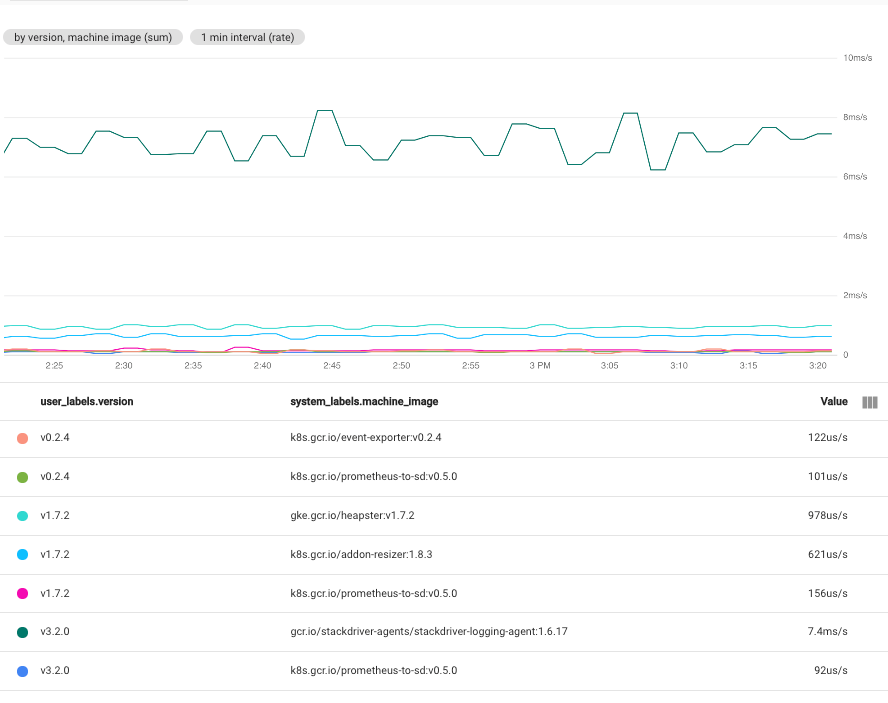
표시된 대로 차트에는 각 라벨 값 쌍에 대해 하나의 시계열을 표시합니다. 라벨 조합마다 시계열을 얻을 수 있으므로, 이 기법을 사용하면 단일 차트에 효율적으로 넣을 수 있는 것보다 많은 데이터가 생성됩니다.
모든 시계열 표시
모든 시계열을 표시하려면 집계 요소에서 첫 번째 메뉴를 집계되지 않음으로 설정하고 두 번째 메뉴를 없음으로 설정합니다.
데이터 정렬
정렬은 Monitoring에서 수신한 시계열 데이터를 데이터 포인트가 고정된 간격으로 있는 새 시계열로 변환하는 프로세스입니다. 정렬 프로세스는 고정된 시간 내 수신된 모든 데이터 포인트를 수집하고, 해당 데이터 포인트를 결합하는 함수를 적용하고, 결과에 타임스탬프를 할당하는 과정으로 구성됩니다. 이러한 함수를 사용하면 모든 샘플의 평균을 계산하거나 모든 샘플의 최댓값을 추출할 수 있습니다.
정렬 간격 설정
조합할 포인트의 고정 시간 길이를 지정하려면 쿼리 창에서 add 쿼리 요소 추가를 클릭하고 최소 간격을 선택한 후 대화상자를 완료합니다.
예를 들어 샘플링 기간이 1분인 측정항목을 가정해 보겠습니다. 차트에서 1시간 분량의 데이터를 표시하도록 구성한 경우 차트에 데이터 포인트 60개 모두가 표시될 수 있습니다. 최소 간격 필드가 10 minutes로 설정되었으면 차트에 6개 데이터 포인트가 표시됩니다. 그러나 이제 1주일 동안 데이터를 표시하도록 차트를 구성하면 차트에 표시할 포인트가 너무 많으므로 포인트가 조합되는 간격이 자동으로 수정됩니다.
이 예시에서 수정된 간격은 1시간입니다.
다음 스크린샷은 특정 Google Cloud 프로젝트에 있는 Compute Engine VM 인스턴스의 CPU 사용률을 보여줍니다.
이 이미지에서 최소 간격 필드는 1 minute으로 설정됩니다.
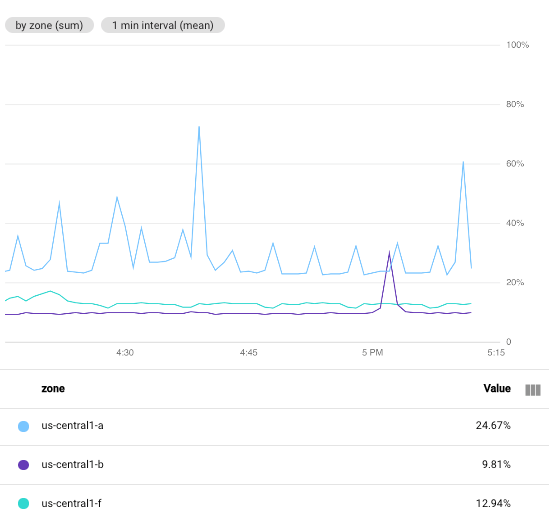
비교를 위해 다음 스크린샷은 간격을 1 minute에서 5 minutes로 변경했을 때의 결과를 보여줍니다.
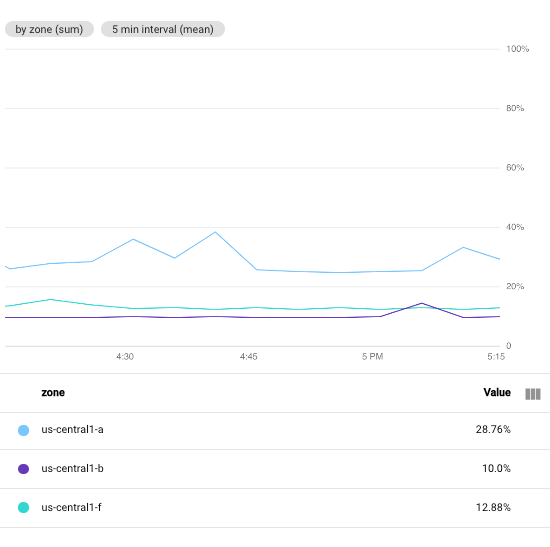
기간을 늘리면 결과 차트에 포인트가 줄어들어 시계열당 60포인트에서 시계열당 10포인트로 줄어듭니다. 최소 간격 필드를 늘리면 더 많은 포인트가 조합되어 플롯에 표시되는 데이터가 더 부드러워집니다.
정렬 함수 설정
집계 함수를 선택하면 Cloud Monitoring이 정렬 함수를 자동으로 선택합니다. Cloud Monitoring은 사용자가 선택한 측정항목 유형 및 사용자의 집계 함수 선택을 기반으로 최적의 정렬 함수를 결정합니다. 하지만 정렬 함수를 지정하여 Cloud Monitoring에서 선택된 항목을 재정의할 수 있습니다.
정렬 함수를 지정하려면 다음을 수행합니다.
- 집계 요소에서 첫 번째 메뉴를 확장하고 정렬기 구성을 선택합니다. 정렬 함수 및 그룹화 요소가 추가됩니다.
- 정렬 함수 요소를 확장하고 항목을 선택합니다.
지원되는 정렬 함수 대부분이 일반적인 연산 기능을 수행하지만 일부는 보다 복잡한 작업을 수행합니다.
next older: 정렬 기간 내에 가장 최근 샘플만 보존하려면 next older를 선택합니다. 이 함수는 일반적으로 업타임 체크와 함께 사용되며 최신 값만 필요할 때 유용한 옵션입니다.
이 함수는 게이지 측정항목에만 유효합니다.
percentile: 선 차트, 누적 영역 차트, 누적 막대 차트의 도표 유형에 배포 측정항목을 표시하려면, 배포에 표시할 백분위수를 선택해야 합니다. 이 백분위수를 지정하는 한 가지 방법은 percentile 함수를 선택하는 것입니다. 5번째, 50번째, 95번째, 99번째 백분위수를 선택할 수 있습니다. 정렬된 데이터 포인트는 정렬 기간의 모든 데이터 포인트를 사용해서 지정된 백분위수를 계산하여 확인됩니다.
이 함수는 배포 데이터 유형을 포함할 때 게이지 및 델타 측정항목에만 유효합니다.
delta: 누적 측정항목 또는 델타 측정항목을 정렬 기간별로 하나의 샘플이 포함된 델타 측정항목으로 변환하려면 이 함수를 사용합니다. 이 함수를 사용하면 데이터 보간이 발생할 수 있습니다. 이에 대한 예시는 종류, 유형, 변환을 참조하세요.
이 함수는 누적 및 델타 측정항목에만 유효합니다.
rate: 누적 또는 델타 측정항목을 게이지 측정항목으로 변환하려면 이 함수를 사용합니다. 이 함수를 선택할 경우 변환되는 시계열을 델타 함수와 같이 생각하고, 정렬 기간으로 분할되는 것으로 생각할 수 있습니다. 예를 들어 원래 시계열의 단위가 MiB이고 정렬 기간의 단위가 초이면 차트에 초당 MiB 단위가 사용됩니다. 자세한 내용은 종류, 유형, 변환을 참조하세요.
이 함수는 누적 및 델타 측정항목에만 유효합니다.
사용 가능한 정렬 함수에 대한 자세한 내용은 API 참조에서 Aligner를 확인하세요.
보조 집계
이미 집계를 나타내는 여러 시계열이 있으면 보조 애그리게이터를 선택하여 차트의 모든 시계열을 단일 시계열로 줄일 수 있습니다. 예를 들어 영역별로 데이터를 그룹화하는 경우 차트에 각 영역별로 하나의 시계열이 표시됩니다. 단일 시계열로 차트를 만들려면 보조 집계 필드를 사용합니다.
일부 측정항목 유형의 경우 데이터 전송 옵션을 선택할 수 있습니다. 이 옵션을 사용할 수 있고 변환 필드를 없음 이외의 값으로 설정한 경우에는 다른 모든 필드가 보조 집계 설정입니다.
보조 집계 필드를 구성할 수 있을 때 이러한 필드에 액세스하려면 다음을 수행합니다.
- add 쿼리 요소 추가를 클릭한 후 보조 집계를 선택합니다.
- 보조 집계 요소를 구성합니다.