このページでは、時系列データの操作方法について説明します。このコンテンツは、指標、時系列、リソースのコンセプトと議論に基づいています。
元の時系列データは、分析する前に操作する必要があります。分析では、一部のデータを除外したり、一部のデータを集計することがよくあります。このページでは、元データを絞り込むための次の 2 つの手法について説明します。
- フィルタリング: 一部のデータを対象から除外します。
- 集計: 指定した分割項目に基づいて、複数のデータをまとめて小さなセットにします。
フィルタリングと集計は、他のものから興味深いパターンを特定し、データの傾向や外れ値を強調するのに便利な強力なツールです。
このページでは、フィルタリングと集計のコンセプトについて説明します。これらを直接適用する方法については説明しません。時系列データにフィルタリングまたは集計を適用するには、Cloud Monitoring API または Google Cloud コンソールのグラフ生成ツールとアラートツールを使用します。例については、API サンプル ポリシーと Monitoring Query Language の例をご覧ください。元の時系列データ
1 つの時系列の元の指標データは極めて大量になる可能性があり、通常は指標タイプに関連付けられた時系列が多数あります。共通項、傾向、または外れ値のセット全体を分析するには、セット内の時系列の処理を行う必要があります。これは、考慮すべきデータが膨大になることを防ぐためです。
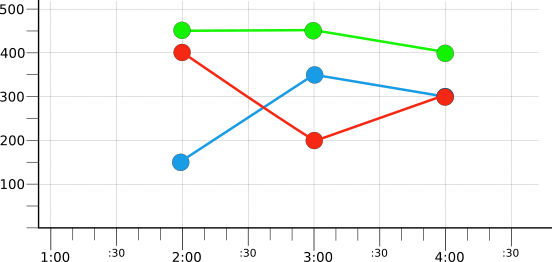
フィルタリングと集計を導入するために、このページの例では少数の仮の時系列を使用します。たとえば、次の図は、3 つの時系列からの数時間分の元データを示しています。
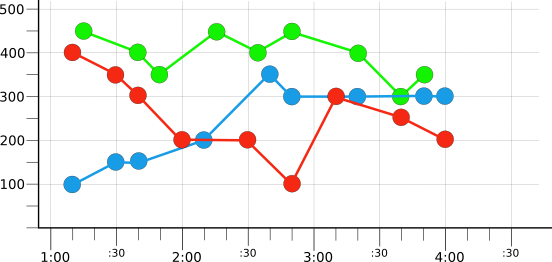
各時系列は、仮の color ラベルの値を反映して赤、青、緑のいずれかの色で表示されます。ラベルの値ごとに 1 つの時系列が存在します。記録された時刻が異なるため、値が整然と配列されないことに留意してください。
フィルタリング
分析に最も便利なツールの一つがフィルタリングです。これにより、さしあたって関心のないデータは非表示にできます。
時系列データは、次のものに基づいてフィルタリングできます。
- 時間。
- 1 つまたは複数のラベルの値。
次の図は、元の時系列の元のセットから赤の時系列のみを表示するフィルタリングの結果を示しています(図 1)。
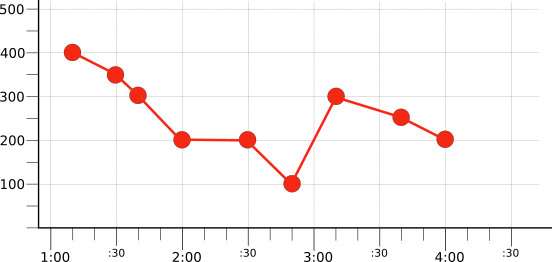
次のセクションでは、フィルタリングによって選択されたこの時系列を使用して、アライメントを示します。
集計
データの量を減らすための方法の一つに、要約または集計する方法があります。集計には次の 2 つの側面があります。
- 単一時系列のデータ内でアライメントまたは正則化します。
- 複数の時系列の縮小または結合。
時系列を縮小する前に、時系列をアライメントする必要があります。この後のセクションでは、整数値を保存する時系列を使用してアライメントと縮小について説明します。これらの一般的なコンセプトは、時系列に Distribution の値型がある場合にも適用されます。ただし、この場合は追加の制約があります。詳細については、分布値の指標についてをご覧ください。
アライメント: 系列内の正則化
時系列データを集計するための最初のステップは、アライメントです。アライメントにより、元データを時間で正規化した新しい時系列を生成することで、他のアライメントされた時系列との結合が可能になります。アライメントによって生成されるのは、一定間隔のデータからなる時系列です。
アライメントには 2 つのステップがあります。
時系列を定期的な時間間隔に分割する(データのバケット化とも呼ばれる)。この間隔は、期間、アライメント期間、またはアライメント ウィンドウと呼ばれます。
アライメント期間のポイントに対して単一の値を計算します。その単一ポイントの計算方法を選択します。すべての値を合計することも、平均を計算することも、最大値を使用することもできます。
アライメントによって作成された新しい時系列は、アライメント期間内の元の時系列のすべての値を単一の値で表すため、系列内縮小または系列内集計とも呼ばれます。
時間間隔の正則化
時系列データを分析するには、データポイントを一定間隔の期間内で利用できるようにする必要があります。アライメントは、この処理を行うためのプロセスです。
アライメントは、データポイント間に一定の間隔を持つ新しい時系列(アライメント期間)を作成します。通常、アライメントはさらに操作を行うために複数の時系列に適用されます。
このセクションでは、単一時系列に適用することでアライメントの手順を説明します。この例では、図 2 に示す時系列の例に 1 時間のアライメント期間を適用しています。時系列は、3 時間で取得されたデータを示しています。データポイントを 1 時間で分割すると、各期間に次のポイントが含まれます。
| 期間 | 値 |
|---|---|
| 1:01~2:00 | 400、350、300、200 |
| 2:01~3:00 | 200、100 |
| 3:01~4:00 | 300、250、200 |
アライメント期間の選択
アライメント期間の長さは、次の 2 つの要因によって決まります。
- データ内で検索する対象の粒度。
- データのサンプリング期間(レポートの頻度)。
以降のセクションでは、これらの要因について詳しく説明します。
また、Cloud Monitoring は特定の期間の指標データを保持します。期間は指標タイプによって異なります。詳しくは、データの保持をご覧ください。保持期間は、最も長い有意義なアライメント期間です。
粒度
2、3 時間のスパン以内に何かが発生したことがわかっていて、さらに深く調べたい場合は、アライメントに 1 時間または数分を使用します。
これより長い期間の傾向を検討したい場合は、より長いアライメント期間のほうが適切である可能性があります。通常、長いアライメント期間は、短時間の異常条件の確認には役立ちません。たとえば、数週間のアライメント期間を使用すると、その期間の異常の検出は可能ですが、アライメントされたデータはあまりにも粗く、役に立ちません。
サンプリング レート
データが書き込まれる頻度(サンプリング レート)もアライメント期間の選択に影響します。組み込み指標のサンプリング レートについては、指標の一覧をご覧ください。次の図について考えてみましょう。この図は、1 分あたり 1 ポイントのサンプリング レートで時系列を示しています。
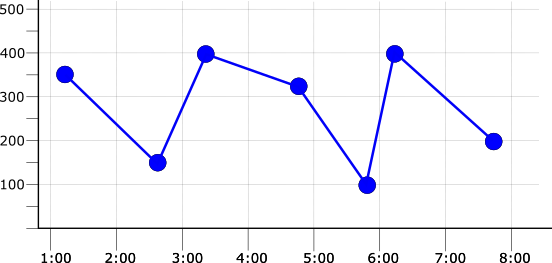
アライメント期間がサンプリング期間と同じ場合、各アライメント期間には 1 つのデータポイントが存在します。たとえば、max、mean、min のいずれかのアライメントを適用すると、同じアライメント時系列になります。次の図は、この結果と元の時系列をフェードラインとして示しています。
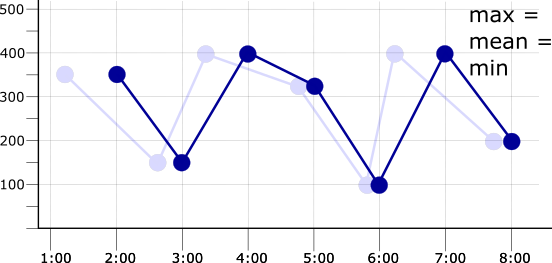
整列指定子の機能の詳細は、整列指定子をご覧ください。
アライメント期間を 2 分に設定するか、サンプリング期間を 2 倍にすると、各期間に 2 つのデータポイントが存在します。max、mean、または min 整列指定子が 2 分のアライメント期間内ポイントに適用されると、結果の時系列は異なります。次の図は、この結果と元の時系列をフェードラインとして示しています。
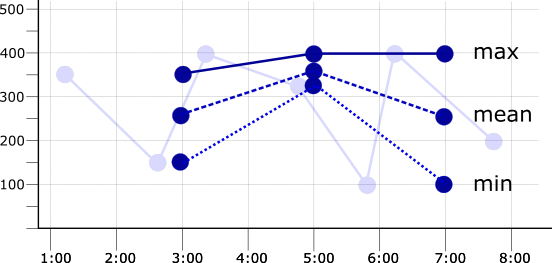
アライメント期間を選択するときに、サンプリング期間よりも長く設定しますが、関連するトレンドを表示できる程度に短くします。有効なアライメント期間を判断するために、テストが必要になる場合があります。たとえば、1 日に 1 ポイントのレートでデータが収集される場合、1 時間のアライメント期間は短すぎます。ほとんどの場合、データはありません。
整列指定子
データをアライメント期間に分割した後、その期間のデータポイントに適用する関数(整列指定子)を選択します。整列指定子は、各アライメント期間の終了時に単一の値を生成します。
アライメント オプションには、値の合計、値の最大値、最小値、平均値の検索、選択したパーセンタイル値の検索、値のカウントなどがあります。Cloud Monitoring API は、ここに示すセット以外にも、多数のアライメント関数をサポートしています。完全なリストについては、Aligner をご覧ください。時系列データを変換するレートとデルタ アライメントについては、種類、タイプ、変換をご覧ください。
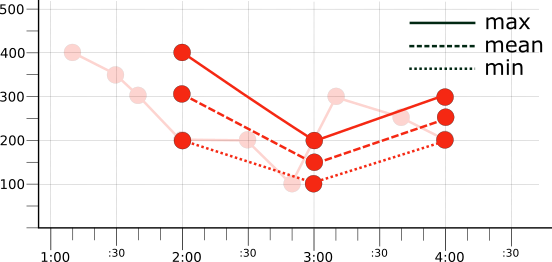
たとえば、元の時系列からバケット化されたデータを取得し(図 1)、整列指定子を選択して、各バケットのデータに適用します。次の表は、元の値と MAX、MEAN、MIN の 3 つの異なる整列指定子の結果を示しています。
| 期間 | 値 | 整列指定子: MAX | 整列指定子: MEAN | 整列指定子: MIN |
|---|---|---|---|---|
| 1:01~2:00 | 400、350、300、200 | 400 | 312.5 | 200 |
| 2:01~3:00 | 200、100 | 200 | 150 | 100 |
| 3:01~4:00 | 300、250、200 | 300 | 250 | 200 |
次の図は、元の赤色の時系列に 1 時間のアライメント期間を使用して、MAX、MEAN、MIN 整列指定子を適用した結果を示しています(図ではフェードラインで表現されています)。
その他の整列指定子
次の表は、同じ元の値と、他の 3 つの整列指定子の結果を示します。
- COUNT は、アライメント期間内の値の数をカウントします。
- SUM は、アライメント期間のすべての値を合計します。
- NEXT OLDER は、期間内の最新の値をアライメント値として使用します。
| 期間 | 値 | 整列指定子: COUNT | 整列指定子: SUM | 整列指定子: NEXT OLDER |
|---|---|---|---|---|
| 1:01~2:00 | 400、350、300、200 | 4 | 1250 | 200 |
| 2:01~3:00 | 200、100 | 2 | 300 | 100 |
| 3:01~4:00 | 300、250、200 | 3 | 750 | 200 |
これらの結果はグラフには表示されません。
縮小: 時系列の結合
プロセスの次のステップである縮小は、複数の時系列を組み合わせて新しい時系列にするプロセスです。このステップでは、アライメント期間の境界のすべての値を単一の値に置き換えます。別々の時系列で機能するため、縮小は系列間集計とも呼ばれます。
レデューサ
レデューサは、一連の時系列の値に適用され、単一の値を生成する関数です。
レデューサのオプションには、アライメントされた値の合計や、最大値、最小値、平均値の検索があります。Cloud Monitoring API は、多数の縮小関数をサポートしています。完全なリストについては、Reducer をご覧ください。レデューサのリストは、整列指定子のリストに対応しています。
時系列は縮小する前にアライメントする必要があります。次の図は、すべての 3 つの元の時系列(図 1)を 1 時間単位で MEAN 整列指定子でアライメントした結果を示します。
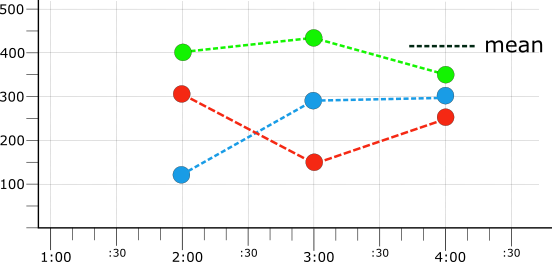
次の表は、MEAN でアライメントされた 3 つの時系列の値(図 4)を示します。
| アライメントの境界 | 赤 | 青 | 緑 |
|---|---|---|---|
| 2:00 | 312.5 | 133.3 | 400 |
| 3:00 | 150 | 283.3 | 433.3 |
| 4:00 | 250 | 300 | 350 |
上記の表のアライメントされたデータを使用して、レデューサを選択し、値に適用します。次の表は、MEAN でアライメントされたデータに異なるレデューサを適用した結果を示します。
| アライメントの境界 | レデューサ: MAX | レデューサ: MEAN | レデューサ: MIN | レデューサ: SUM |
|---|---|---|---|---|
| 2:00 | 400 | 281.9 | 133.3 | 845.8 |
| 3:00 | 433.3 | 288.9 | 150 | 866.7 |
| 4:00 | 350 | 300 | 250 | 900 |
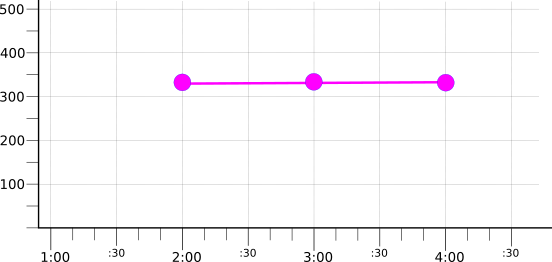
デフォルトでは、縮小はすべての時系列に適用され、単一の時系列になります。次の図は、MEAN でアライメントされた 3 つの時系列を MAX レデューサで集計した結果を示します。
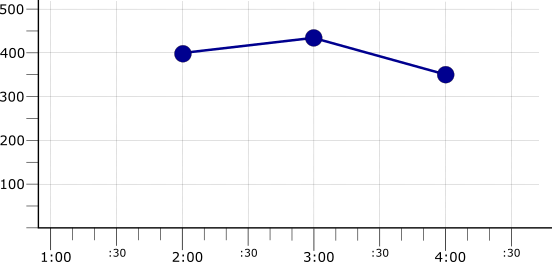
縮小は、時系列がカテゴリに整理され、各グループの時系列にわたりレデューサが適用されるグループ化とも組み合わせることができます。
グループ化
グループ化により、時系列セット全体ではなく、時系列のサブセット全体にレデューサを適用できます。時系列をグループ化するには、1 つまたは複数のラベルを選択します。その後、選択したラベルの値に基づいて時系列がグループ化されます。これにより、グループごとに 1 つの時系列が作成されます。
指標タイプに zone ラベルと color ラベルの値が記録されている場合は、いずれかまたは両方のラベルで時系列をグループ化できます。レデューサを適用すると、各グループは 1 つの時系列に縮小されます。色でグループ化すると、データに表示される色ごとに 1 つの時系列が取得されます。ゾーンでグループ化すると、データに表示されるゾーンごとに時系列が取得されます。両方でグループ化すると、色とゾーンの組み合わせごとに時系列が取得されます。
たとえば、color ラベルの「赤」、「青」、「緑」の値で多数の時系列をキャプチャしたとします。すべての時系列をアライメントした後、color 値でグループ化してから、グループ別に縮小することができます。これにより、次の 3 色の時系列が生成されます。
この例では、使用する整列指定子またはレデューサを指定していません。ここでのポイントは、グループ化によって多数の時系列が少数になり、各時系列がグループで共有する共通の属性(この例では color ラベルの値)を表す点です。
二次集計
Cloud Monitoring は、2 つの集計ステップを実行します。
一次集計では、測定されたデータが正規化され、レデューサを使用して正規化された時系列が結合されます。グループ化を使用すると、このステップの一部として実行される縮小によって、複数の時系列が生成される場合があります。
二次集計は一次集計ステップの結果に適用されます。この集計では、2 つ目のレデューサを使用して、グループ化された時系列を 1 つの結果に結合できます。
次のテーブルに、グループ化された時系列の値を示します(図 6)。
| アライメントの境界 | 赤のグループ | 青のグループ | 緑のグループ |
|---|---|---|---|
| 2:00 | 400 | 150 | 450 |
| 3:00 | 200 | 350 | 450 |
| 4:00 | 300 | 300 | 400 |
これらの 3 つの縮小された時系列は、二次集計を適用することでさらに縮小できます。次のテーブルに、選択したレデューサを適用した結果を示します。
| アライメントの境界 | レデューサ: MAX | レデューサ: MEAN | レデューサ: MIN | レデューサ: SUM |
|---|---|---|---|---|
| 2:00 | 450 | 333.3 | 150 | 1000 |
| 3:00 | 450 | 333.3 | 200 | 1000 |
| 4:00 | 400 | 333.3 | 300 | 1000 |
次の図は、3 つのグループ化された系列を MEAN レデューサで集計した結果を示しています。
種類、タイプ、変換
前述のとおり、時系列のデータポイントは、指標の種類と値の型によって特徴付けられます。詳しくは、値の型と指標の種類をご覧ください。あるデータセットに適した整列指定子とレデューサは、別のデータセットに適しているとは限りません。たとえば、FALSE 値の数をカウントする整列指定子またはレデューサは、ブール値データには適していますが、数値データには適していません。同様に、平均値を計算する整列指定子またはレデューサは、数値データには適用できますが、ブール値データには適用できません。
一部の整列指定子とレデューサは、時系列のデータの指標の種類または値のタイプを明示的に変更するためにも使用できます。ALIGN_COUNT などの一部は、副次的にこれを行います。
指標の種類: 累積指標は、それぞれの値が値の収集を開始した以降の合計を表す指標です。累積指標をグラフで直接使用することはできませんが、それぞれの値が前回の測定からの変化を表すデルタ指標は使用できます。
累積指標とデルタ指標の両方を変換し、ゲージ指標にすることもできます。たとえば、時系列が次のようなデルタ指標があるとします。
(開始時刻, 終了時刻](分) 値(MiB) (0, 2] 8 (2, 5] 6 (6, 9] 9 ALIGN_DELTAの整列指定子と 3 分間のアライメント期間を選択したとします。アライメント期間は各サンプルの (開始時間、終了時間] と一致しないため、補間された値を使用して時系列が作成されます。この例では、補間された時系列は次のようになります。(開始時刻, 終了時刻](分) 補間された値(MiB) (0, 1] 4 (1, 2] 4 (2, 3] 2 (3, 4] 2 (4, 5] 2 (5, 6] 0 (6, 7] 3 (7, 8] 3 (8, 9] 3 次に、3 分間のアライメント期間内のすべてのポイントを合計して、アライメント値を生成します。
(開始時刻, 終了時刻](分) アライメント値(MiB) (0, 3] 10 (3, 6] 4 (6, 9] 9 ALIGN_RATEが選択されている場合、アライメント値をアライメント期間で割ることを除いて処理は同じです。この例では、アライメント期間は 3 分間であるため、アライメント時系列には次の値が含まれています。(開始時刻, 終了時刻](分) アライメント値(MiB/秒) (0, 3] 0.056 (3, 6] 0.022 (6, 9] 0.050 累積指標をグラフ化するには、デルタ指標またはレート指標に変換する必要があります。累積指標のプロセスは、前述の説明と同様です。隣接する期間の差を計算することで、累積時系列からデルタ時系列を計算できます。
値のタイプ: 一部の整列指定子とレデューサは、入力データの値のタイプを変更しません。たとえば、整数データはアライメント後も整数データです。他の整列指定子とレデューサは、あるタイプから別のタイプにデータを変換します。つまり、元の値のタイプには適さない方法でも情報を分析できます。
たとえば、
REDUCE_COUNTレデューサは数値、ブール値、文字列、分布値のデータに適用できますが、生成する結果は期間内の値の数をカウントする 64 ビット整数になります。REDUCE_COUNTはゲージ指標とデルタ指標にのみ適用でき、指標の種類は変更しません。
Aligner と Reducer の参照表は、それぞれが適切なデータの種類とその変換を示しています。たとえば、ALIGN_DELTA のエントリは次のようになります。
