De forma predeterminada, el agente de operaciones y el agente de Monitoring heredado están configurados para recopilar métricas que capturan información sobre los procesos que se ejecutan en tus máquinas virtuales (VM) de Compute Engine. También puedes recopilar estas métricas en las VM de Amazon Elastic Compute Cloud (EC2) mediante el agente de Monitoring.
Este conjunto de métricas, llamadas métricas de proceso, se identifica con el prefijo agent.googleapis.com/processes. Estas métricas no se recopilan en Google Kubernetes Engine (GKE).
A partir del 6 de agosto de 2021, se presentarán cargos por estas métricas, como se describe en la sección sobre métricas cobrables de la página Precios de Google Cloud Observability. El conjunto de métricas de procesos se clasifica como cobrable, pero los cargos nunca se implementaron.
En este documento, se describen herramientas para visualizar métricas de procesos, cómo determinar la cantidad de datos que transfieres desde estas métricas y cómo minimizar los cargos relacionados.
Trabaja con métricas de procesos
Puedes visualizar tus datos de métricas del proceso con gráficos creados mediante el Explorador de métricas o los paneles personalizados. Para obtener más información, consulta Usa los paneles y gráficos. Además, Cloud Monitoring incluye datos de métricas de procesos en dos paneles predefinidos:
- Panel Instancias de VM en Monitoring
- Panel Detalles de la instancia de VM en Compute Engine
En las siguientes secciones, se describen estos paneles.
Monitoring: Consulta métricas de procesos agregadas
Para ver las métricas de procesos agregadas dentro de un alcance de métricas, ve a la pestaña Procesos en el panel de Instancias de VM:
-
En la consola de Google Cloud , accede a la página Paneles
 :
:
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Monitoring.
Selecciona el panel de Instancias de VM de la lista.
Haz clic en Procesos.
En la siguiente captura de pantalla, se muestra un ejemplo de la página Procesos de Monitoring:
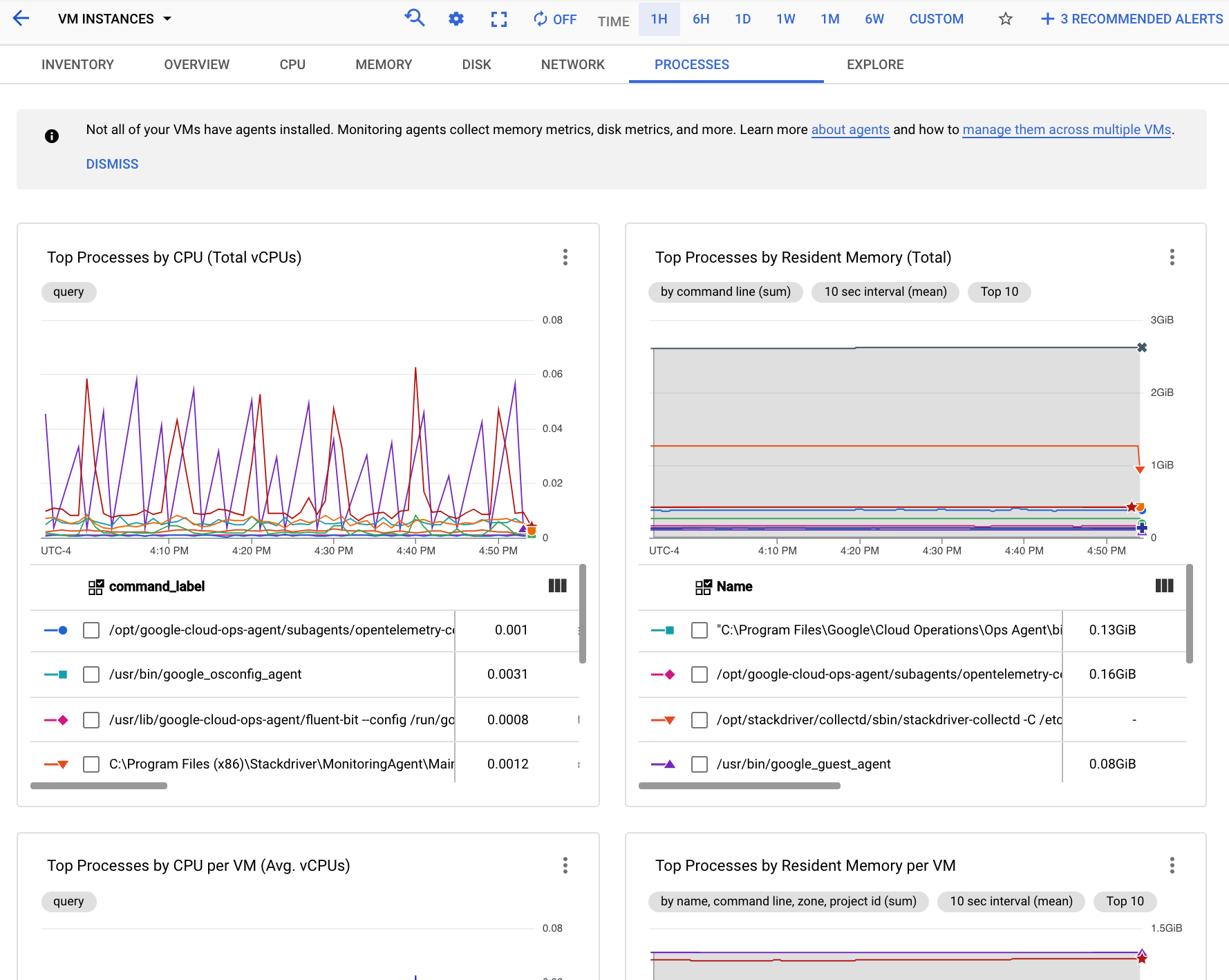
Puedes usar los gráficos de la pestaña Procesos para identificar los procesos en tu alcance de métricas que consumen más CPU y memoria, y que tienen el mayor uso de disco.
Compute Engine: Visualiza las métricas de rendimiento de las VMs que consumen más recursos
Para ver los gráficos de rendimiento que muestran las cinco VMs que consumen la mayor cantidad de un recurso en tu proyecto de Google Cloud , ve a la pestaña Observabilidad de tus instancias de VM:
-
En la consola de Google Cloud , ve a la página Instancias de VM.
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Compute Engine.
- Haz clic en Observabilidad.
En la siguiente captura de pantalla, se muestra un ejemplo de la página Observabilidad de Compute Engine.
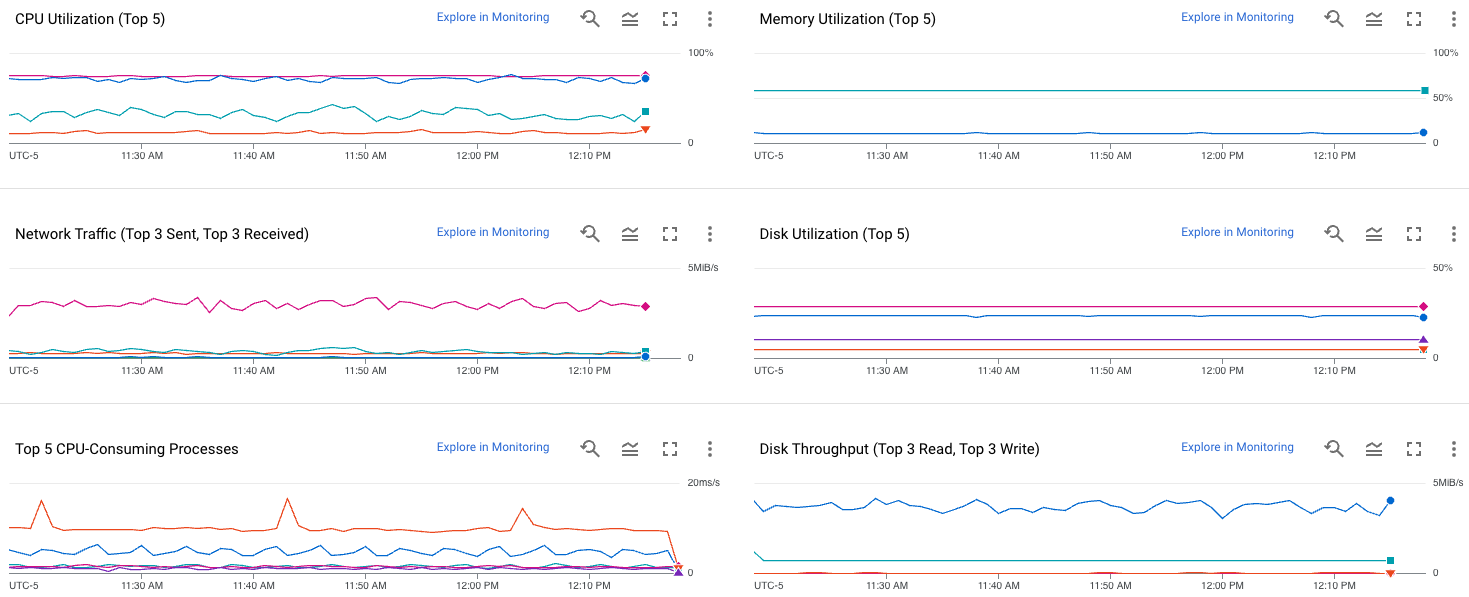
Si deseas obtener información para usar estas métricas y diagnosticar problemas con tus VMs, consulta Soluciona problemas de rendimiento de la VM.
Compute Engine: Visualiza métricas de procesos por VM
Para ver una lista de los procesos que se ejecutan en una sola máquina virtual (VM) de Compute Engine y los gráficos de los procesos con el mayor consumo de recursos, ve a la pestaña Observabilidad de la VM:
-
En la consola de Google Cloud , ve a la página Instancias de VM.
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Compute Engine.
En la pestaña Instancias, haz clic en el nombre de una VM que se inspeccionará.
Haz clic en Observabilidad para ver las métricas de esta VM.
En el panel de navegación de la pestaña Observabilidad, selecciona Procesos.
En la siguiente captura de pantalla, se muestra un ejemplo de la página Procesos de Compute Engine:
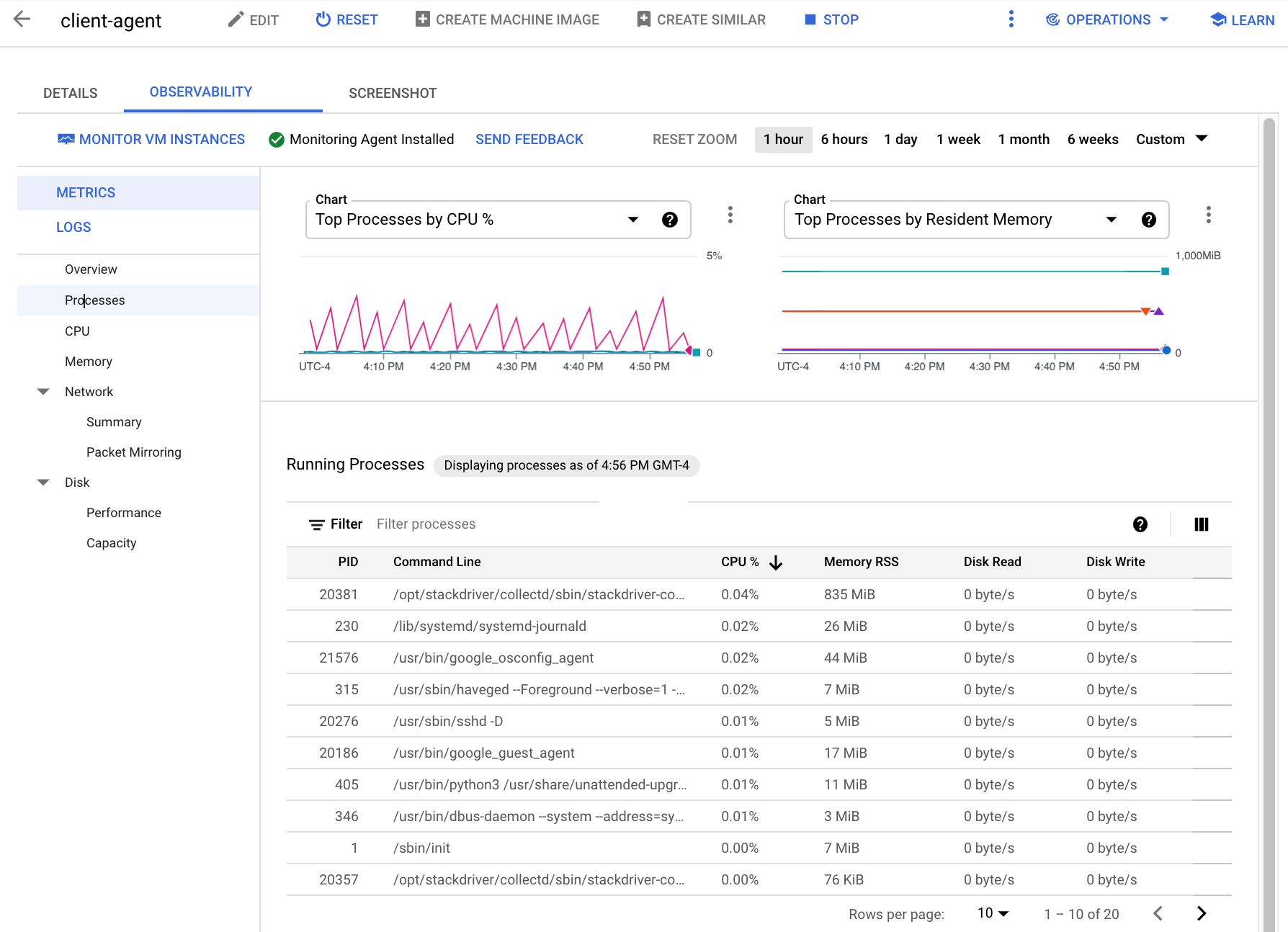
Las métricas de procesos se retienen por hasta 24 horas, por lo que puedes usarlas para retroceder en el tiempo y atribuir anomalías en el consumo de recursos a procesos específicos o identificar a tus consumidores de recursos más costosos. Por ejemplo, en el siguiente gráfico, se muestran los procesos que consumen los porcentajes más altos de recursos de CPU. Puedes usar el selector de intervalo de tiempo para cambiar el intervalo de tiempo del gráfico. El selector de intervalo de tiempo ofrece valores predeterminados, como la hora más reciente, y también te permite ingresar un intervalo de tiempo personalizado.
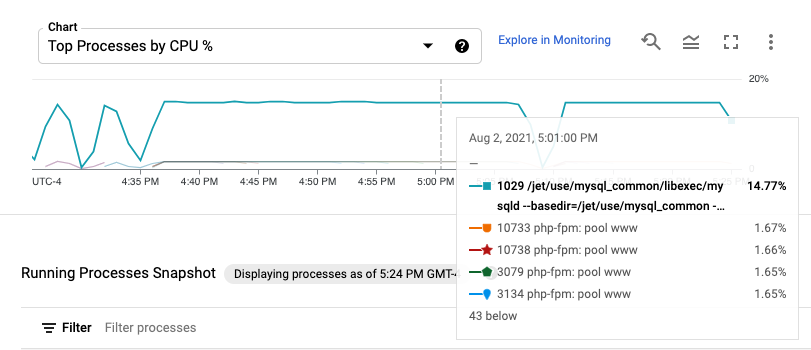
En la tabla Running procesos, se proporciona una lista de consumo de recursos analógicos al resultado del comando top de Linux.
De forma predeterminada, en la tabla se muestra una instantánea de los datos más recientes.
Sin embargo, si seleccionas un intervalo de tiempo en un gráfico que finaliza en el pasado, la tabla mostrará los procesos que se ejecutan al final de ese rango.
Si deseas obtener información para usar estas métricas y diagnosticar problemas con tus VMs, consulta Soluciona problemas de rendimiento de la VM.
Métricas de procesos que recopila el agente
Los agentes de Linux recopilan todas las métricas que se enumeran en la siguiente tabla a partir de los procesos que se ejecutan en las VM de Compute Engine y mediante el agente de Monitoring, las VM de Amazon Elastic Compute Cloud (EC2). Puedes inhabilitar la recopilación mediante el agente de operaciones (versiones 2.0.0 y posteriores) y el agente de Monitoring heredado.
También puedes inhabilitar la recopilación de métricas de procesos para el agente de operaciones (versiones 2.0.0 y posteriores) que se ejecutan en las VM de Windows.
Para obtener más información, consulta Inhabilita las métricas de procesos.
Si quieres inhabilitar la recopilación de estas métricas en Windows, te recomendamos que actualices a la versión 2.0.0 o posterior del agente de operaciones. Para obtener más información, consulta Instala el agente de operaciones.
Tabla de métricas de procesos
Las strings de “tipo de métrica” de esta tabla deben tener el prefijo agent.googleapis.com/processes/. Este prefijo se omitió en las entradas de la tabla.
Cuando consultes una etiqueta, usa el prefijo metric.labels.. Por
ejemplo, metric.labels.LABEL="VALUE".
| Tipo de métrica Etapa de lanzamiento (niveles de jerarquía de recursos) Nombre visible |
|
|---|---|
| Clase, tipo, unidad Recursos supervisados |
Descripción Etiquetas |
count_by_state
GA
(proyecto)
Procesos |
|
GAUGE, DOUBLE, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Recuento de procesos en el estado determinado. Solo en Linux. Se tomaron muestras cada 60 segundos.
state: ejecución, suspensión, zombis, etcétera.
|
cpu_time
GA
(proyecto)
Procesamiento de CPU |
|
CUMULATIVE, INT64, us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Tiempo de CPU de un proceso determinado. Se tomaron muestras cada 60 segundos.
process:
Nombre del proceso.
user_or_syst: Un usuario o proceso del sistema.
command: Procesar comando.
command_line: Línea de comandos de proceso, 1,024 caracteres como máximo.
owner: Propietario del proceso.
pid:
ID de proceso.
|
disk/read_bytes_count
GA
(proyecto)
Procesa E/S de lectura en el disco |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
E/S de lectura del disco de un proceso. Solo en Linux. Se tomaron muestras cada 60 segundos.
process:
Nombre del proceso.
command: Procesar comando.
command_line: Línea de comandos de proceso, 1,024 caracteres como máximo.
owner: Propietario del proceso.
pid:
ID de proceso.
|
disk/write_bytes_count
GA
(proyecto)
Procesa E/S de escritura en el disco |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
E/S de escritura del disco de un proceso. Solo en Linux. Se tomaron muestras cada 60 segundos.
process:
Nombre del proceso.
command: Procesar comando.
command_line: Línea de comandos de proceso, 1,024 caracteres como máximo.
owner: Propietario del proceso.
pid:
ID de proceso.
|
fork_count
GA
(proyecto)
Recuento de bifurcaciones |
|
CUMULATIVE, INT64, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Cantidad total de procesos bifurcados. Solo en Linux. Se tomaron muestras cada 60 segundos. |
rss_usage
GA
(proyecto)
Procesa la memoria residente |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Uso de memoria residente de un proceso determinado. Solo en Linux. Se tomaron muestras cada 60 segundos.
process:
Nombre del proceso.
command: Procesar comando.
command_line: Línea de comandos de proceso, 1,024 caracteres como máximo.
owner: Propietario del proceso.
pid:
ID de proceso.
|
vm_usage
GA
(proyecto)
Procesa memoria virtual |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Uso de VM del proceso determinado. Se tomaron muestras cada 60 segundos.
process:
Nombre del proceso.
command: Procesar comando.
command_line: Línea de comandos de proceso, 1,024 caracteres como máximo.
owner: Propietario del proceso.
pid:
ID de proceso.
|
Tabla generada el 8 de agosto de 2025 a las 23:40:45 UTC.
Determina la transferencia actual
Puedes usar el Explorador de métricas para ver cuántos datos transfieres para las métricas de procesos. Usa el siguiente procedimiento:
-
En la consola de Google Cloud , accede a la página leaderboard Explorador de métricas:
Acceder al Explorador de métricas
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Monitoring.
En la barra de herramientas del panel del compilador de consultas, selecciona el botón cuyo nombre sea codeMQL o codePromQL.
Verifica que MQL esté seleccionado en el botón de activación Lenguaje. El botón de activación de lenguaje se encuentra en la misma barra de herramientas que te permite dar formato a tu consulta.
Para ver la cantidad total de puntos de métrica de proceso de tus recursos
gce_instanceyaws_ec2_instance, haz lo siguiente:Ingrese la siguiente consulta:
def tagged_process_metric name = metric 'agent.googleapis.com/processes/'$name | add [metric_suffix: $name]; def process_metrics resource_type = fetch $resource_type | { @tagged_process_metric 'cpu_time' ; @tagged_process_metric 'disk/read_bytes_count' ; @tagged_process_metric 'disk/write_bytes_count' ; @tagged_process_metric 'rss_usage' ; @tagged_process_metric 'vm_usage' ; @tagged_process_metric 'count_by_state' ; @tagged_process_metric 'fork_count' } | within 1d | group_by [metric_suffix], 1m, [row_count: row_count()] | union; { @process_metrics 'gce_instance' ; @process_metrics 'aws_ec2_instance' } | outer_join 0, 0 | { rename [], [out: val(0)] | add [resource_type: 'gce_instance'] ; rename [], [out: val(1)] | add [resource_type: 'aws_ec2_instance'] } | union | group_by drop[metric_suffix], 1d, .sumHaga clic en Ejecutar consulta. En el gráfico resultante, se muestran los valores para cada tipo de recurso.
Estima el costo de las métricas
En los ejemplos de precios de Monitoring, se ilustra cómo puedes estimar el costo de la transferencia de métricas. Estos ejemplos se pueden aplicar a las métricas de procesos.
Se realizan muestras de todas las métricas de procesos cada 60 segundos y todas escriben datos que se cuentan como ocho bytes para la determinación de los precios.
Los precios de las métricas de procesos se establecen en un 5% del costo de volumen estándar usado en los ejemplos de precios. Por lo tanto, si suponemos que todas las métricas en las situaciones descritas en esos ejemplos son métricas de procesos, puedes usar el 5% del costo total para cada situación como una estimación del costo de métricas de procesos.
Inhabilita la recopilación de métricas de procesos
Existen varias maneras de inhabilitar la recopilación de estas métricas por el agente de operaciones (versiones 2.0.0 y posteriores) y por el agente de Monitoring heredado en Linux.
Los agentes se ejecutan solo en las VM de Compute Engine y, en el agente de Monitoring, las VM de Amazon Elastic Compute Cloud (EC2). Estos procedimientos se aplican solo a esas plataformas.
No puedes inhabilitar la recopilación mediante el agente de operaciones si ejecutas versiones anteriores a la 2.0.0 o el agente de Monitoring heredado en Windows. Si quieres inhabilitar la recopilación de estas métricas en Windows, te recomendamos que actualices a la versión 2.0.0 o posterior del agente de operaciones. Para obtener más información, consulta Instala el agente de operaciones.
El procedimiento general se ve de la siguiente manera:
Conéctate a la VM.
Haz una copia del archivo de configuración existente como una copia de seguridad. Almacena la copia de seguridad fuera del directorio de configuración del agente, de modo que el agente no intente cargar ambos archivos. Por ejemplo, con el siguiente comando, se crea una copia del archivo de configuración para el agente de Monitoring en Linux:
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
Cambia la configuración mediante una de las opciones que se describen a continuación:
Reinicia el agente para recoger la configuración nueva:
- Agente de supervisión:
sudo service stackdriver-agent restart - Agente de operaciones:
sudo service google-cloud-ops-agent restart
- Agente de supervisión:
Verifica que las métricas del proceso ya no se recopilen para esta VM:
Selecciona Explorador de métricas.
Haz clic en MQL.
Para un recurso
gce_instance, ingresa la siguiente consulta y reemplaza VM_NAME por el nombre de esta VM:fetch gce_instance | metric 'agent.googleapis.com/processes/cpu_time' | filter (metadata.system_labels.name == 'VM_NAME') | align rate(1m) | every 1m
Para un recurso
aws_ec2_instance, reemplazagce_instanceen la consulta.Haga clic en Ejecutar consulta.
Agente de operaciones en Linux o Windows
La ubicación del archivo de configuración del agente de operaciones depende del sistema operativo:
- Para Linux:
/etc/google-cloud-ops-agent/config.yaml - Para Windows:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
Para inhabilitar la recopilación de todas las métricas de procesos del agente de operaciones, agrega lo siguiente al archivo config.yaml:
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
Esto excluye las métricas de procesos de la recopilación en el procesador metrics_filter que se aplica a la canalización predeterminada en el servicio metrics.
Si deseas obtener más información sobre las opciones de configuración para el agente de operaciones, consulta Configura el agente de operaciones.
Agente de supervisión en Linux
Tienes las siguientes opciones para inhabilitar la recopilación de métricas de procesos con el agente heredado de Monitoring:
En las siguientes secciones, se describe cada opción y se enumeran los beneficios y riesgos asociados con ella.
Modifica el archivo de configuración del agente
Con esta opción, editas de forma directa el archivo de configuración principal del agente, /etc/stackdriver/collectd.conf, para quitar las secciones que habilitan la recopilación de las métricas del proceso.
Procedimiento
Hay tres grupos de eliminaciones que debes realizar en el archivo collectd.conf:
Borra la siguiente directiva
LoadPluginy la configuración del complemento:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>Borra la siguiente directiva
PostCacheChainy la configuración de la cadenaPostCache:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>Borra la cadena
MaybeThrottleProcessesque usa la cadenaPostCache:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
Beneficios y riesgos
- Beneficios
- Reduces los recursos que consume el agente, ya que las métricas nunca se recopilan.
- Si realizaste otros cambios en tu archivo
collectd.conf, es posible que puedas conservar esos cambios con facilidad.
- Riesgos
- Debes usar la cuenta
rootpara editar este archivo de configuración. - Corres el riesgo de ingresar errores tipográficos en el archivo.
- Debes usar la cuenta
Reemplaza el archivo de configuración del agente
Con esta opción, reemplazarás el archivo de configuración principal del agente por una versión editada con las secciones relevantes que se quitaron.
Procedimiento
Descarga el archivo editado previamente,
collectd-no-process-metrics.conf, del repositorio de GitHub al directorio/tmpy, luego, haz lo siguiente:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.confReemplaza el archivo
collectd.confexistente por el archivo editado previamente:cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
Beneficios y riesgos
- Beneficios
- Reduces los recursos que consume el agente, ya que las métricas nunca se recopilan.
- No es necesario que edites el archivo de forma manual como
root. - Las herramientas de administración de configuración pueden reemplazar fácilmente un archivo.
- Riesgos
- Si realizaste otros cambios en el archivo
collectd.conf, debes combinar esos cambios en el archivo de reemplazo.
- Si realizaste otros cambios en el archivo
Soluciona problemas
Los procedimientos que se describen en este documento son cambios en la configuración del agente, por lo que los siguientes problemas son los más probables:
- No hay privilegios suficientes para editar los archivos de configuración. Los archivos de configuración deben editarse desde la cuenta
root. - Introducción de errores tipográficos en el archivo de configuración, si lo editas directamente.
Para obtener más información para resolver otros problemas, consulta Solución de problemas del agente de Monitoring.
Agente de supervisión en Windows
No puedes inhabilitar la recopilación de métricas del proceso mediante el agente de Monitoring heredado que se ejecuta en las VM de Windows. Este agente no se puede configurar. Si quieres inhabilitar la recopilación de estas métricas en Windows, te recomendamos que actualices a la versión 2.0.0 o posterior del agente de operaciones. Para obtener más información, consulta Instala el agente de operaciones.
Si ejecutas el agente de operaciones, consulta Agente de operaciones en Linux o Windows.