本页面介绍了可用于监控 Google Kubernetes Engine (GKE) 工作负载和底层集群节点的启动延迟时间的指标和信息中心。您可以使用这些指标对启动延迟时间进行跟踪、问题排查和缩短。
本页面适用于需要监控和优化工作负载启动延迟时间的平台管理员和运维人员。如需详细了解我们在 Google Cloud 内容中提及的常见角色,请参阅常见的 GKE 用户角色和任务。
概览
启动延迟时间会显著影响应用对流量高峰的响应方式、其副本从中断中恢复的速度,以及集群和工作负载的运营成本可以实现的效率。监控工作负载的启动延迟时间有助于您检测延迟时间变长,并跟踪工作负载和基础设施更新对启动延迟时间的影响。
优化工作负载启动延迟时间具有以下优势:
- 在流量高峰期间,缩短服务对用户的响应延迟时间。
- 减少在创建新副本时应对需求高峰所需的过剩服务容量。
- 在批量计算期间,减少已部署并等待其余资源启动的资源的空闲时间。
准备工作
在开始之前,请确保您已执行以下任务:
- 启用 Google Kubernetes Engine API。 启用 Google Kubernetes Engine API
- 如果您要使用 Google Cloud CLI 执行此任务,请安装并初始化 gcloud CLI。 如果您之前安装了 gcloud CLI,请运行
gcloud components update命令以获取最新版本。较早版本的 gcloud CLI 可能不支持运行本文档中的命令。
启用 Cloud Logging 和 Cloud Monitoring API。
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
要求
如需查看工作负载启动延迟时间的指标和信息中心,您的 GKE 集群必须满足以下要求:
- 您必须使用 GKE 1.31.1-gke.1678000 或更高版本。
- 您必须配置系统指标收集。
- 您必须配置系统日志收集。
- 在集群上通过
POD组件启用 Kube State Metrics,以查看 Pod 和容器指标。
所需的角色和权限
如需获得启用日志生成以及访问和处理日志所需的权限,请让您的管理员为您授予以下 IAM 角色:
-
查看 GKE 集群、节点和工作负载:项目的 Kubernetes Engine Viewer (
roles/container.viewer) -
访问启动延迟时间指标并查看信息中心:项目的 Monitoring Viewer (
roles/monitoring.viewer) -
访问包含延迟时间信息的日志(例如 Kubelet 映像拉取事件),并在 Logs Explorer 和 Log Analytics 中查看这些日志:项目的 Logs Viewer (
roles/logging.viewer)
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
启动延迟时间指标
启动延迟时间指标包含在 GKE 系统指标中,会导出到 GKE 集群所在项目中的 Cloud Monitoring。
此表中的 Cloud Monitoring 指标名称必须以 kubernetes.io/ 为前缀。表中的条目已省略该前缀。
| 指标类型(资源层次结构级别) 显示名称 |
|
|---|---|
|
种类、类型、单位
受监控的资源 |
说明 标签 |
pod/latencies/pod_first_ready
(项目)
Pod 首次就绪延迟时间 |
|
GAUGE、Double、s
k8s_pod |
Pod 端到端启动延迟时间(从 Pod Created 到 Ready),包括映像拉取。每 60 秒采样一次。 |
node/latencies/startup
(项目)
节点启动延迟时间 |
|
GAUGE、INT64、s
k8s_node |
节点的总启动延迟时间,从 GCE 实例的 CreationTimestamp 到首次实现 Kubernetes node ready。每 60 秒采样一次。accelerator_family:基于硬件加速器的节点分类:gpu、tpu、cpu。
kube_control_plane_available:在 KCP(Kube 控制平面)可用时是否收到了节点创建请求。
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(项目)
每个 HPA 建议扩缩延迟时间 |
|
GAUGE、DOUBLE、s
k8s_scale |
Pod 横向自动扩缩器 (HPA) 目标的 HPA 扩缩建议延迟时间(从创建指标到将相应扩缩建议应用于 apiserver 之间的时间)。每 60 秒采样一次。采样后,数据在最长 20 秒的时间内不会显示。metric_type:指标来源的类型。它应该是 "ContainerResource"、"External"、"Object"、"Pods" 或 "Resource" 中的一个。
|
查看工作负载的启动延迟信息中心
工作负载的启动延迟信息中心仅适用于部署。如需查看部署的启动延迟时间指标,请在 Google Cloud 控制台中执行以下步骤:
转到工作负载页面。
如需打开部署详情视图,请点击要检查的工作负载的名称。
点击可观测性标签页。
从左侧的菜单中选择启动延迟。
查看 Pod 的启动延迟时间分布情况
Pod 的启动延迟时间是指总启动延迟时间(包括映像拉取),此延迟时间衡量从 Pod 的 Created 状态到 Ready 状态的时间。您可以使用以下两个图表评估 Pod 的启动延迟时间:
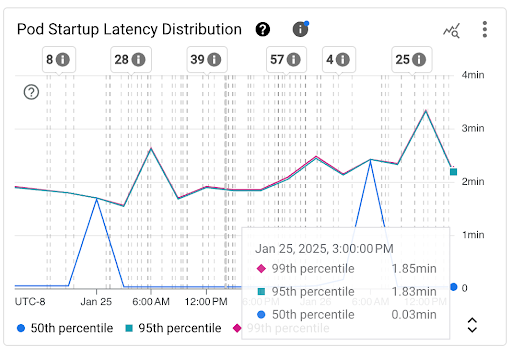
Pod 启动延迟时间分布情况图表:此图表显示 Pod 的启动延迟时间百分位(第 50 百分位、第 95 百分位和第 99 百分位),这些百分位是根据在固定 3 小时时间间隔(例如午夜 12:00 至凌晨 3:00 和凌晨 3:00 至早上 6:00)内对 Pod 启动事件的观察结果计算得出的。您可以将此图表用于以下用途:
- 了解基准 Pod 启动延迟时间。
- 了解 Pod 启动延迟时间随时间的变化情况。
- 将 Pod 启动延迟时间的变化与近期事件(例如工作负载部署或集群自动扩缩器事件)相关联。您可以在信息中心顶部的注解列表中选择相应事件。
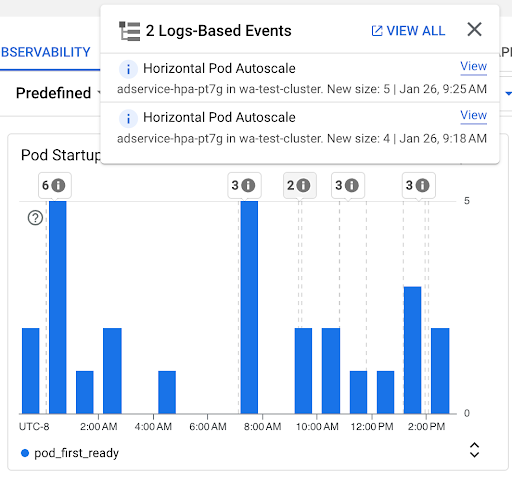
Pod 启动次数图表:此图表显示在所选时间间隔内启动的 Pod 的数量。您可以将此图表用于以下用途:
- 了解用于针对给定时间间隔计算 Pod 启动延迟时间分布情况百分位的 Pod 样本规模。
- 了解 Pod 启动的原因,例如工作负载部署或 Pod 横向自动扩缩器事件。您可以在信息中心顶部的注解列表中选择相应事件。
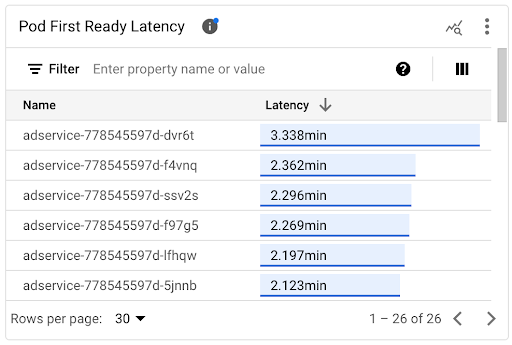
查看各个 Pod 的启动延迟时间
您可以在 Pod 首次就绪延迟时间时间轴图表和关联列表中查看各个 Pod 的启动延迟时间。
- 使用 Pod 首次就绪延迟时间时间轴图表将各个 Pod 启动与近期事件(例如 Pod 横向自动扩缩器或集群自动扩缩器事件)相关联。您可以在信息中心顶部的注解列表中选择这些事件。此图表可帮助您确定与其他 Pod 相比,启动延迟时间发生任何变化的潜在原因。
- 您可以使用 Pod 首次就绪延迟时间列表来确定启动时间最长或最短的各个 Pod。您可以按延迟时间列对列表进行排序。确定启动延迟时间最长的 Pod 时,您可以将 Pod 启动事件与其他近期事件相关联,从而排查延迟时间变长问题。
您可以通过查看相应 Pod 创建事件中 timestamp 字段的值,了解个别 Pod 的创建时间。如需查看 timestamp 字段,请在 Logs Explorer 中运行以下查询:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
如需列出工作负载的所有 Pod 创建事件,请在上述查询中使用以下过滤条件:protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
在比较各个 Pod 的延迟时间时,您可以测试各种配置对 Pod 启动延迟时间的影响,并根据您的要求确定最佳配置。
确定 Pod 调度延迟时间
Pod 调度延迟时间是指从创建 Pod 到在节点上调度 Pod 之间的时间量。Pod 调度延迟时间会影响 Pod 的端到端启动时间,其计算方法是将 Pod 调度事件的时间戳与 Pod 创建请求的时间戳相减。
您可以通过相应 Pod 调度事件中的 jsonPayload.eventTime 字段获得个别 Pod 调度事件的时间戳。如需查看 jsonPayload.eventTime 字段,请在 Logs Explorer 中运行以下查询:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
如需列出工作负载的所有 Pod 调度事件,请在上述查询中使用以下过滤条件:resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
查看映像拉取延迟时间
在节点上尚未提供映像或需要刷新映像时,容器映像拉取延迟时间会影响 Pod 启动延迟时间。优化映像拉取延迟时间后,您可以缩短集群扩容事件期间的工作负载启动延迟时间。
您可以查看 Kubelet 映像拉取事件表,了解工作负载容器映像的拉取时间以及该过程所耗费的时长。
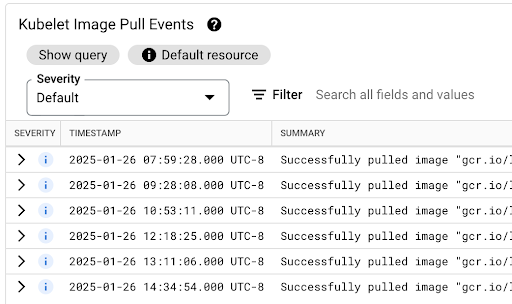
映像拉取延迟时间可在 jsonPayload.message 字段中获得,该字段包含类似于以下内容的消息:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
查看 HPA 扩缩建议延迟时间分布
Pod 横向自动扩缩器 (HPA) 目标的 HPA 扩缩建议延迟时间是指从创建指标到将相应扩缩建议应用于 API 服务器之间的时间量。优化 HPA 扩缩建议延迟时间后,您可以缩短扩容事件期间的工作负载启动延迟时间。
您可以在以下两个图表中查看 HPA 扩缩:
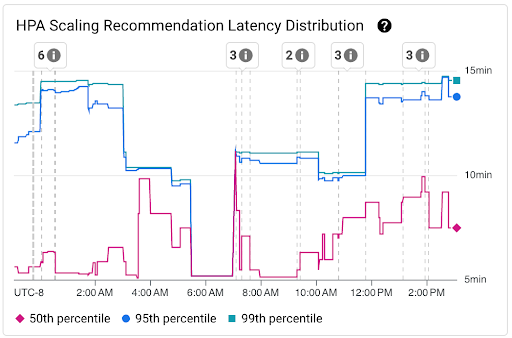
HPA 扩缩建议延迟时间分布图表:此图表显示 HPA 扩缩建议延迟时间的百分位(第 50 百分位、第 95 百分位和第 99 百分位),这些百分位是根据在后续 3 小时时间间隔内对 HPA 扩缩建议的观察结果计算得出的。您可以将此图表用于以下用途:
- 了解基准 HPA 扩缩建议延迟时间。
- 了解 HPA 扩缩建议延迟时间随时间的变化情况。
- 将 HPA 扩缩建议延迟时间的变化与近期事件相关联。 您可以在信息中心顶部的注解列表中选择相应事件。
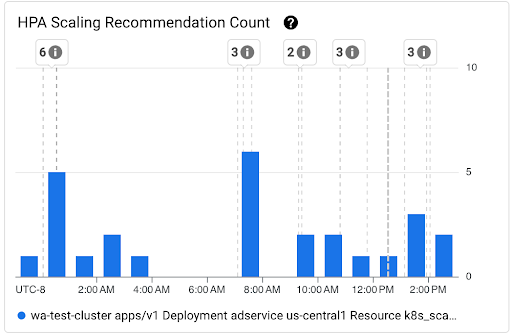
HPA 扩缩建议数图表:此图表显示在所选时间间隔内观察到的 HPA 扩缩建议的数量。使用此图表可完成以下任务:
- 了解 HPA 扩缩建议样本规模。这些样本用于针对给定时间间隔计算 HPA 扩缩建议延迟时间分布的百分位。
- 将 HPA 扩缩建议与新的 Pod 启动事件和 Pod 横向自动扩缩器事件相关联。您可以在信息中心顶部的注解列表中选择相应事件。
查看 Pod 的调度问题
Pod 调度问题可能会影响工作负载的端到端启动延迟时间。如需缩短工作负载的端到端启动延迟时间,请排查这些问题并减少其数量。
以下是可用于跟踪此类问题的两个图表:
- 不可调度/待处理/已失败的 Pod 图表显示一段时间内不可调度、待处理和已失败的 Pod 的数量。
- 退避/等待/就绪性失败的容器图表显示一段时间内处于这些状态的容器的数量。
查看节点的启动延迟信息中心
如需查看节点的启动延迟时间指标,请在Google Cloud 控制台中执行以下步骤:
前往 Kubernetes 集群页面。
如需打开集群详情视图,请点击要检查的集群的名称。
点击可观测性标签页。
从左侧菜单中选择启动延迟。
查看节点的启动延迟时间分布情况
节点的启动延迟时间是指总启动延迟时间,此延迟时间衡量从节点的 CreationTimestamp 到 Kubernetes node ready 状态的时间。您可以在以下两个图表中查看节点启动延迟时间:
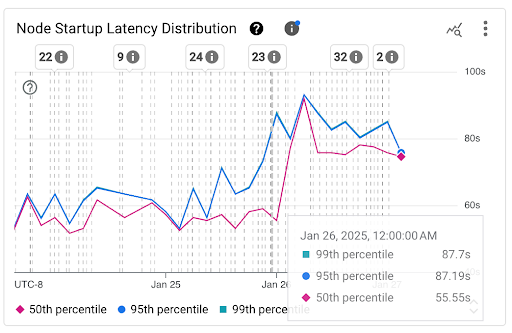
节点启动延迟时间分布图表:此图表显示节点启动延迟时间的百分位(第 50 百分位、第 95 百分位和第 99 百分位),这些百分位是根据在固定 3 小时时间间隔(例如午夜 12:00 至凌晨 3:00 和凌晨 3:00 至早上 6:00)内对节点启动事件的观察结果计算得出的。您可以将此图表用于以下用途:
- 了解基准节点启动延迟时间。
- 了解节点启动延迟时间随时间的变化情况。
- 将节点启动延迟时间的变化与近期事件(例如集群更新或节点池更新)相关联。您可以在信息中心顶部的注解列表中选择相应事件。
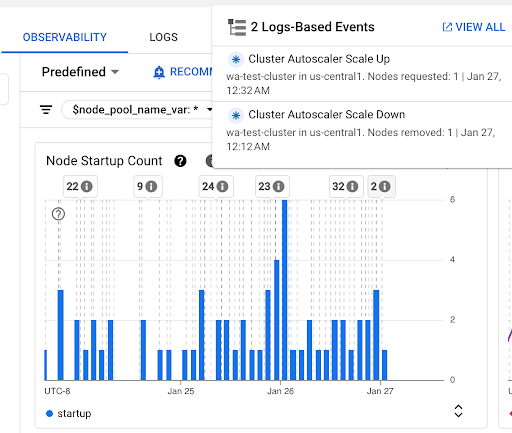
节点启动次数图表:此图表显示在所选时间间隔内启动的节点的数量。您可以将此图表用于以下用途:
- 了解用于针对给定时间间隔计算节点启动延迟时间分布情况百分位的节点样本规模。
- 了解节点启动的原因,例如节点池更新或集群自动扩缩器事件。您可以在信息中心顶部的注解列表中选择相应事件。
查看各个节点的启动延迟时间
在比较各个节点的延迟时间时,您可以测试各种节点配置对节点启动延迟时间的影响,并根据您的要求确定最佳配置。您可以在节点启动延迟时间时间轴图表和关联列表中查看各个节点的启动延迟时间。
使用节点启动延迟时间时间轴图表将各个节点启动与近期事件(例如集群更新或节点池更新)相关联。您可以确定与其他节点相比,启动延迟时间发生变化的潜在原因。您可以在信息中心顶部的注解列表中选择相应事件。
使用节点启动延迟时间列表确定启动时间最长或最短的各个节点。您可以按延迟时间列对列表进行排序。确定启动延迟时间最长的节点时,您可以将节点启动事件与其他近期事件相关联,从而排查延迟时间变长问题。
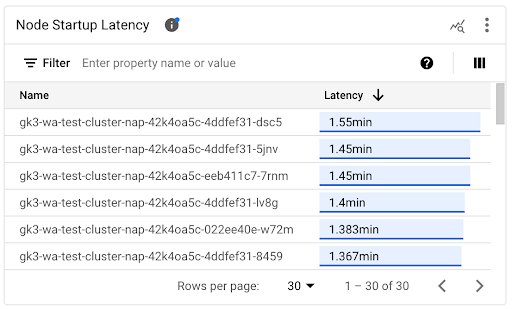
您可以通过查看相应节点创建事件中 protoPayload.metadata.creationTimestamp 字段的值,了解个别节点的创建时间。如需查看 protoPayload.metadata.creationTimestamp 字段,请在 Logs Explorer 中运行以下查询:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
查看节点池中的启动延迟时间
如果您的节点池具有不同的配置(例如用于运行不同的工作负载),您可能需要按节点池分别监控节点启动延迟时间。在跨节点池比较节点启动延迟时间时,您可以深入了解节点配置如何影响节点启动延迟时间,从而优化延迟时间。
默认情况下,节点启动延迟时间信息中心会显示集群中所有节点池的汇总启动延迟时间分布情况和各个节点启动延迟时间。如需查看特定节点池的节点启动延迟时间,请使用位于该信息中心顶部的 $node_pool_name_var 过滤条件来选择节点池的名称。
后续步骤
- 了解如何根据指标优化 Pod 自动扩缩。
- 详细了解在 GKE 上缩短冷启动延迟时间的方式。
- 了解如何使用映像流式传输缩短映像拉取延迟时间。
- 了解 Pod 横向自动扩缩调优带来的惊人经济效益。
- 使用自动应用监控来监控工作负载。