Datastore での強整合性と結果整合性のバランス
一貫したユーザー エクスペリエンスの実現と結果整合性モデルを利用した大規模データセットへのスケール
このドキュメントでは、Datastore の結果整合性モデルを大量のデータやユーザーの処理に利用しながら、ユーザー エクスペリエンスを重視した強整合性を実現する方法について説明します。
このドキュメントは、Datastore でソリューションを構築するソフトウェア設計者やソフトウェア エンジニアを対象としています。Datastore のような非リレーショナル システムよりもリレーショナル データベースに慣れている読者のために、このドキュメントでは、リレーショナル データベースでの類似のコンセプトについても言及します。このドキュメントでは、Datastore の基本事項を理解していることを前提としています。最も簡単な開始方法は、Google App Engine でサポートされている言語をいずれかを使用することです。App Engine をまだ使用したことがない場合は、まず App Engine のスタートガイドと、サポートされている言語に対応するデータの保存のセクションをご覧ください。このドキュメントでは、コードの抜粋の例に Python を使用していますが、ここでの内容を理解するうえで Python に対する専門的な知識は必要ありません。
注: この記事のコードスニペットでは、推奨されなくなった Datastore 用 Python DB クライアント ライブラリを使用します。新しいアプリケーションを作成する際には、NDB クライアント ライブラリを使用することを強くおすすめします。このライブラリには、Memcache API によるエンティティの自動キャッシュなど、このクライアント ライブラリにはないメリットがあります。古い DB クライアント ライブラリを現在使用している場合は、DB から NDB への移行ガイドをお読みください。
目次
NoSQL と結果整合性
Datastore での結果整合性
祖先クエリとエンティティ グループ
エンティティ グループと祖先クエリの制限
祖先クエリに代わる方法
完全な整合性を実現する時間の短縮
まとめ
その他のリリース
NoSQL と結果整合性
NoSQL データベースとしても知られている非リレーショナル データベースは近年、リレーショナル データベースに代わるものとして注目されるようになりました。Datastore は、業界で最も広く使用されている非リレーショナル データベースの 1 つです。2013 年、Datastore では 1 か月あたり 4.5 兆件のトランザクションが処理されました(Google Cloud Platform のブログ投稿)。このプラットフォーム上でデベロッパーは、シンプルな方法でデータを保存し、データにアクセスできます。柔軟なスキーマをオブジェクト指向言語やスクリプト言語に自然に対応させることができます。また、Datastore には、リレーショナル データベースでは最適ではない機能(非常に大規模での高パフォーマンスや高い信頼性など)が多数用意されています。
リレーショナル データベースに親しんでいるデベロッパーは、非リレーショナル データベースの特性や使用方法に慣れない部分があるため、非リレーショナル データベースを使用するシステムの設計が難しく感じられるかもしれません。Datastore のプログラミング モデルはシンプルですが、こうした非リレーショナル データベースの特性を認識することが重要です。その特性の 1 つとして、結果整合性があります。このドキュメントでは、結果整合性のプログラミングについて主に説明します。
結果整合性とは
結果整合性とは、エンティティに対して新たな更新がない限り、最終的にそのエンティティのすべての読み取りに、最後に更新された値が返されることを理論的に保証するものです。インターネットのドメイン ネーム システム(DNS)は、結果整合性モデルを持つシステムのよく知られている例です。DNS サーバーには必ずしも最新の値が反映されず、値はインターネット上の多数のディレクトリでキャッシュされ、複製されます。DNS のすべてのクライアントとサーバーに変更された値が複製されるには、ある程度時間がかかります。それでも DNS は非常に成功しているシステムであり、インターネットの基盤の 1 つとなりました。可用性が高く、スケーラビリティに非常に優れていることが実証されており、インターネット全体で 1 億台を超えるデバイスの名前のルックアップが可能です。
図 1 に結果整合性によるレプリケーションの概念を示します。この図では、複製されたデータは常に読み取り可能ですが、ある時点での一部の複製データが、最初のノードでの最新の書き込みデータと一致していないことがあります。図では、ノード A が最初のノードであり、ノード B と C は複製です。
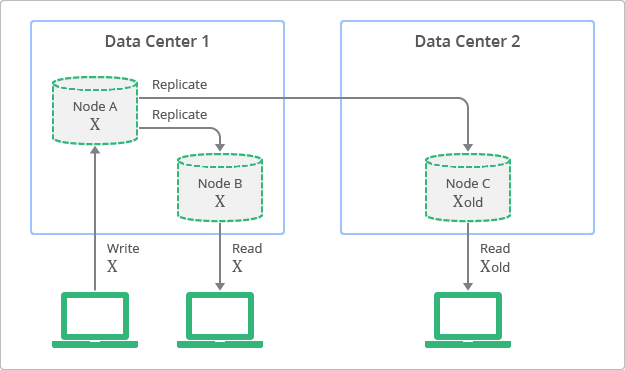
これに対して、従来のリレーショナル データベースは強整合性(即時整合性とも呼ばれます)の概念に基づいて設計されています。つまり、更新後にすぐに表示するデータは、そのエンティティのすべてのオブザーバーで一致します。この特性が、リレーショナル データベースを使用する多くのデベロッパーにとって、基本的な前提でした。しかし、強整合性を保つために、デベロッパーはアプリケーションのスケーラビリティやパフォーマンスの点で妥協する必要があります。簡単に言うと、更新やレプリケーションのプロセス中に、同じデータに対して他の更新処理がないことを保証するために、データをロックする必要があります。
強整合性でのデプロイ トポロジーとレプリケーション プロセスの概念図を図 2 に示します。複製データは常に最初のノードの値と一致しますが、更新が終わるまではアクセスできないことが、この図でわかります。
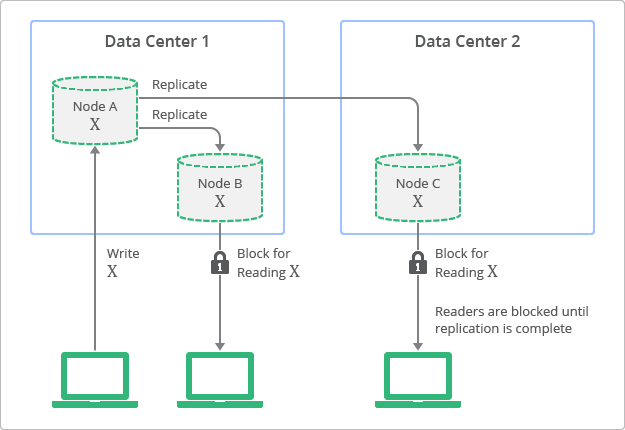
強整合性と結果整合性のバランス
非リレーショナル データベースは最近、高いスケーラビリティと高い可用性のパフォーマンスが必要となるウェブ アプリケーションで特によく使用されるようになりました。非リレーショナル データベースでは、デベロッパーがアプリケーションごとに、強整合性と結果整合性の間で最適なバランスを選択することができます。それによって、両方の世界のメリットを合わせることができます。たとえば、「ある時点でのオンラインの仲間リストのメンバー」や、「自分の投稿に +1 した人の数」についての情報の取得は、強整合性を必要としないユースケースです。こうしたユースケースでは、結果整合性を活用して、スケーラビリティとパフォーマンスを高めることができます。強整合性を必要とするユースケースには、「あるユーザーが課金手続きを完了したかどうか」や、「戦闘セッションでのゲーム プレーヤーの得点」などの情報の取得があります。
上記の例を総括すると、エンティティが非常に多数のユースケースでは、結果整合性が最良のモデルと言える場合が多くなります。クエリの結果の件数が非常に多い場合、特定のエンティティが含まれるかどうかがユーザー エクスペリエンスに影響を与える可能性は低いでしょう。一方、エンティティ数が少なく、限定されたコンテキストでのユースケースでは、強整合性が必要になると言えます。こうしたコンテキストでは、該当するエンティティと該当しないエンティティをユーザーが意識するために、整合性によってユーザー エクスペリエンスに差が生じます。
このため、Datastore の非リレーショナル特性をデベロッパーが理解していることが重要になります。以下のセクションでは、結果整合性と強整合性のモデルを組み合わせて、スケーラビリティ、可用性、パフォーマンスの高いアプリケーションを構築する方法について説明します。この方法では、ユーザー エクスペリエンスを重視した整合性の要件を満たすことができます。
Datastore での結果整合性
強整合性によるデータの表示が必要な場合、API を正しく選択する必要があります。Datastore のさまざまなクエリ API と対応する整合性モデルを表 1 に示します。
|
Datastore API |
エンティティ値の読み取り |
インデックスの読み取り |
|---|---|---|
|
結果整合性 |
結果整合性 |
|
|
なし |
結果整合性 |
|
|
強整合性 |
強整合性 |
|
|
キーによる検索(get()) |
強整合性 |
なし |
Datastore で祖先を指定しないクエリは、グローバル クエリと呼ばれ、結果整合性モデルで機能するように設計されています。このクエリでは、強整合性は保証されません。キーのみのグローバル クエリは、クエリに一致するエンティティのキーのみが返され、エンティティの属性値は返されないグローバル クエリです。祖先クエリは、祖先エンティティに基づいてクエリのスコープを指定します。それぞれの整合性について、以下のセクションで詳しく説明します。
エンティティ値の読み取り時の結果整合性
祖先クエリを例外とすると、更新されたエンティティ値はクエリの実行時にすぐには表示されないことがあります。エンティティ値の読み取り時での結果整合性による影響について説明するため、Player というエンティティが Score というプロパティを持つ状況を考えます。たとえば最初の Score 値が 100 であるとします。しばらくした後に、Score 値が 200 に更新されたとします。グローバル クエリが実行され、その結果にその Player エンティティが含まれる場合、返されるエンティティのプロパティ Score の値が 100 のまま変わらずに表示される可能性があります。
これは Datastore のサーバー間でのレプリケーションによって生じます。レプリケーションは、Datastore の基盤テクノロジーである Bigtable と Megastore で管理されます(Bigtable と Megastore の詳細については、その他のリソースをご覧ください)。レプリケーションは Paxos アルゴリズムで実行され、更新リクエストを複製の大多数が認識するまで、同期して待機します。しばらくしてからリクエストからのデータで複製が更新されます。この待機時間は通常短時間ですが、実際の長さについて何も保証されません。更新が終了する前にクエリが実行される場合、古いデータが読み取られることがあります。
多くの場合、すべての複製が迅速に更新されます。ただし、複数の要因が重なって、整合性が実現されるまでの時間が増加することがあります。こうした要因には、データセンター間で多数のサーバーにわたって切り替えが必要になるようなデータセンター全体での障害などがあります。こうした要因はさまざまなので、整合性を完全に確立するための時間要件ははっきり規定することはできません。
クエリに最新の値を返すために必要な時間は、通常は非常に短時間です。ただし、レプリケーションの待ち時間が増大するような、まれに発生する状況では、この時間が大幅に長くなる可能性があります。Datastore のグローバル クエリを使用するアプリケーションでは、こうしたケースを適切に処理するように注意して設計する必要があります。
エンティティ値の読み取りでの結果整合性は、キーのみのクエリ、祖先クエリ、キーによる検索(get() メソッド)のいずれかを使用して避けることもできます。以下では、これらのさまざまな種類のクエリについて詳しく説明します。
インデックスの読み取りでの結果整合性
グローバル クエリの実行時に、インデックスは更新されていないことがあります。つまり、エンティティの最新のプロパティ値が読み取れたとしても、クエリの結果に含まれる「エンティティのリスト」は古いインデックス値に基づいてフィルタリングされている可能性があります。
結果整合性によるインデックスの読み取りへの影響について説明するため、新しいエンティティ Player を Datastore に挿入する状況を考えてみます。このエンティティのプロパティ Score は、初期値が 300 であるとします。挿入の直後に、キーのみのクエリを実行して、Score の値が 0 より大きいすべてのエンティティを取得するとします。この場合、挿入したばかりの Player エンティティもクエリ結果に表示されると予想されます。しかし、おそらく予想に反して、この Player エンティティは結果に表示されません。クエリの実行時には、Score プロパティのインデックス テーブルが新しく挿入された値を含めるように更新されていないために、こうした結果になることがあります。
Datastore のクエリはすべてインデックス テーブルに対して行われますが、インデックス テーブルの更新は非同期的である点に注意してください。エンティティの更新は必ず、実質的に 2 つのフェーズで行われます。最初のフェーズである commit フェーズでは、トランザクション ログへの書き込みが行われます。2 番目のフェーズでは、データが書き込まれ、インデックスが更新されます。commit フェーズが正常に行われると、書き込みフェーズは、すぐに行われない場合もありますが、正常に行われることが保証されます。インデックスが更新される前にそのエンティティについてクエリを行うと、まだ整合性がとれていないデータが表示される可能性があります。
2 つのフェーズによるプロセスの結果として、エンティティへの最新の更新がグローバル クエリに表示される前に遅延が生じます。エンティティ値の結果整合性と同様に、この遅延は一般に短時間ですが、長くなることもあります(例外的な状況では数分以上になることもあります)。
更新後も同様の状況が発生する可能性があります。たとえば、既存のエンティティ Player を、Score プロパティの値を 0 にするように更新し、その直後に同じクエリを実行したとします。このエンティティは、Score の値を 0 にしたので除外され、クエリの結果には表示されないと予想されます。しかし、インデックスの更新の同じ非同期動作により、このエンティティが結果にまだ含まれる可能性があります。
インデックスの読み取りでの結果整合性は、祖先クエリまたはキーによる検索方法でのみ避けることができます。キーのみのクエリではこの動作を避けることはできません。
エンティティ値とインデックスの読み取りでの強整合性
Datastore でエンティティ値とインデックスの読み取りについて強整合性を提供するのは(1)キーによる検索のメソッドと(2)祖先クエリの 2 つの API のみです。アプリケーションのロジックで強整合性が必要な場合、デベロッパーは Datastore からエンティティを読み取るためにこれらの方法のいずれかを使用する必要があります。
Datastore はこれらの API で強整合性を提供するように特別に設計されています。このいずれかが呼び出されると、Datastore は複製およびインデックス テーブルのいずれかで保留中の更新をすべて実行してから、検索または祖先クエリを実行します。このようにして、更新されたインデックス テーブルに基づく最新のエンティティ値が、最新の更新に基づく値とともに常に返されます。
キーによる検索の呼び出しでは、クエリとは異なり、キーまたはキーのセットによって指定された 1 つのエンティティまたはエンティティのセットしか返されません。つまり、Datastore で強整合性の要件とフィルタリングの要件をともに満たす方法は、祖先クエリしかありません。ただし、祖先クエリはエンティティ グループを指定しないと機能しません。
祖先クエリとエンティティ グループ
このドキュメントの最初に説明したように、Datastore の利点の 1 つは、強整合性と結果整合性の最適なバランスをデベロッパーが見つけられることです。Datastore でのエンティティ グループとは、強整合性、トランザクション性、ローカル性を持つユニットです。エンティティ グループを使用すると、デベロッパーはアプリケーションのエンティティ間で、強整合性を持つスコープを定義できます。これによって、アプリケーションはエンティティ グループ内での整合性を維持する一方で、同時に高いスケーラビリティ、可用性、パフォーマンスを持つ完全なシステムを実現できます。
エンティティ グループは、1 つのルート エンティティと、その子エンティティやそれを継承するエンティティから構成される階層です。[1]エンティティ グループを作成するには、デベロッパーは祖先パス、つまり子キーの前に一連の親キーをつなげて指定します。エンティティ グループの概念を図 3 に示します。この図では、キー「ateam」を持つルート エンティティには、キー「ateam/098745」とキー「ateam/098746」を持つ 2 つの子エンティティがあります。

エンティティ グループ内では、次の特性が保証されます。
-
強整合性
- エンティティ グループに対する祖先クエリでは、強整合性の結果が返されます。この場合、インデックスが最新の状態でフィルタリングされた最新のエンティティ値が反映されます。
-
トランザクション性
- プログラムでトランザクションを切り分けることで、エンティティ グループではトランザクションでの ACID 特性(原始性、整合性、独立性、永続性)を実現できます。
-
ローカル性
- 1 つのエンティティ グループ内のエンティティは、Datastore サーバー上の物理的に近い場所に格納されます。すべてのエンティティはキーの辞書順で並べ替えられ、格納されるからです。これによって、祖先クエリは最小限の入出力でエンティティ グループを迅速にスキャンできます。
祖先クエリはクエリの特別な形式であり、指定されたエンティティ グループに対してのみ実行されます。この場合、強整合性が維持されます。これを可能にするために、クエリの実行前に保留中のレプリケーションとインデックスの更新がすべて行われることを Datastore が保証しています。
祖先クエリの例
このセクションでは、エンティティ グループと祖先クエリを実際に使用する方法について説明します。次の例では、人物のデータレコードを管理する問題について考えます。特定の種類のエンティティを追加したすぐ後に、その種類のクエリを行うようにコーディングしたとします。Python コードでのこの例を下に示します。
# Define the Person entity
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
organization = db.StringProperty()
# Add a person and retrieve the list of all people
class MainPage(webapp2.RequestHandler):
def post(self):
person = Person(given_name='GI', surname='Joe', organization='ATeam')
person.put()
q = db.GqlQuery("SELECT * FROM Person")
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname,
'organization': p.organization})
このコードの問題は、ほとんどの場合、クエリにはすぐ上の文で追加されたエンティティが返されないことです。挿入した直後の行にクエリがあるため、クエリの実行時にインデックスは更新されていません。ただし、このユースケースの妥当性についても問題があります。まったくコンテキストを指定せずにすべての人物のリストを 1 ページに返す必要は本当にあるでしょうか。もし 100 万人いたとしたらどうでしょうか。ページを返すには長すぎる可能性があります。
ユースケースの性質上、クエリを絞り込むなんらかのコンテキストを指定することが必要と考えられます。この例では、使用するコンテキストを組織とします。この場合、その組織をエンティティ グループとして使用し、祖先クエリを実行できます。これで整合性の問題が解決します。Python コードでのこの例を下に示します。
class Organization(db.Model):
name = db.StringProperty()
class Person(db.Model):
given_name = db.StringProperty()
surname = db.StringProperty()
class MainPage(webapp2.RequestHandler):
def post(self):
org = Organization.get_or_insert('ateam', name='ATeam')
person = Person(parent=org)
person.given_name='GI'
person.surname='Joe'
person.put()
q = db.GqlQuery("SELECT * FROM Person WHERE ANCESTOR IS :1 ", org)
people = []
for p in q.run():
people.append({'given_name': p.given_name,
'surname': p.surname})
今度は、祖先の組織を GqlQuery で指定したので、クエリには挿入したばかりのエンティティが返されます。この例では、クエリの一部としてその祖先を持つ個人の名前をクエリで指定することで、各個人までドリルダウンするように拡張できます。または、エンティティ キーを保存して、キーによる検索でそのキーを使用してドリルダウンすることもできます。
Memcache と Datastore 間の整合性の維持
エンティティ グループは、Memcache のエントリと Datastore のエンティティ間での整合性を維持するためのユニットとして使用することもできます。たとえば、各チーム内の人数を数えて、そのデータを Memcache に格納する状況を考えます。キャッシュされたデータと Datastore の最新の値の整合性をとるために、エンティティ グループのメタデータを使用できます。メタデータは、指定されたエンティティ グループの最新のバージョン番号を返します。このバージョン番号を Memcache に保存されている番号と比較することができます。この方法を利用すると、グループ内の個々のエンティティをすべてスキャンしなくても、メタデータのセットを 1 つ読み取ることで、エンティティ グループ内のいずれかのエンティティに変更があったかどうかを検出できます。
エンティティ グループと祖先クエリの制限
エンティティ グループと祖先クエリを使用する方法は、魔法の解決策ではありません。実際には以下に挙げるように、このテクニックを広く適用するには 2 つの問題があります。
- 各エンティティ グループの書き込みは、1 秒間に 1 回の更新という上限があります。
- エンティティの作成後にエンティティ グループの関係を変更できません。
書き込みの制限
重要な問題の 1 つは、各エンティティ グループに更新(またはトランザクション)の回数を保管するようにシステムを設計する必要があることです。サポートされる上限は、エンティティ グループごとに 1 秒間に 1 回の更新です。[2]更新の回数がこの上限を超える必要がある場合、そのエンティティ グループはパフォーマンスのボトルネックとなるおそれがあります。
上記の例では、各組織内のどの人のレコードも更新が必要になる可能性があります。「ateam」内に 1,000 人含まれていて、それぞれの人物のいずれかのプロパティを 1 秒間に 1 回更新する可能性があるとします。その結果、このエンティティ グループでは 1 秒間に最大 1,000 回の更新がありえますが、これは更新の上限により実現できません。これにより、パフォーマンス要件を考慮した適切なエンティティ グループの設計の選択が重要であることがわかります。これは、結果整合性と強整合性の最適なバランスを求める際の課題の 1 つです。
エンティティ グループの関係の不変性
2 つ目の問題は、エンティティ グループの関係の不変性です。エンティティ グループの関係はキーの名前の指定に基づき静的に構成されます。エンティティの作成後には、変更できません。関係を変更するために唯一可能な方法は、エンティティ グループ内のそのエンティティを削除して、作成し直すことです。この制限により、エンティティ グループを使用して整合性やトランザクション性のために一時的なスコープを動的に定義することはできません。整合性とトランザクション性のスコープは、設計時に定義される静的なエンティティ グループに拘束されます。
たとえば、2 つの銀行口座間での電子送金を実装する状況を考えます。このビジネス シナリオでは、強整合性とトランザクション性が求められます。しかし、処理する直前に 2 つの口座を 1 つのエンティティ グループにまとめたり、1 つのグローバルな親の子として設定したりすることはできません。1 つのエンティティ グループにまとめた場合、システム全体のボトルネックとなり、他の電子送金の実行を妨げるおそれがあります。したがって、エンティティ グループをこのために使用することはできません。
高いスケーラビリティと可用性を備えた電子送金を実装するための別の方法があります。すべての口座を 1 つのエンティティ グループにまとめる代わりに、口座ごとにエンティティ グループを作成できます。そこでトランザクションを使用することにより、両方の銀行口座に対して確実に ACID 更新が行われるようにすることができます。Datastore に備わっている機能の 1 つであるトランザクションを使用すると、最大 25 個のエンティティ グループ用に ACID 特性を持つ一連のオペレーションを作成できます。トランザクション内では、キーによるルックアップや祖先クエリなど、強整合性のクエリを使用する必要があります。トランザクションの制限事項について詳しくは、トランザクションとエンティティ グループをご覧ください。
祖先クエリに代わる方法
Datastore に多数のエンティティを格納している既存のアプリケーションでは、リファクタリングを実施するために後からエンティティ グループを組み込むのは難しい場合があります。エンティティをすべて削除して、エンティティ グループ内に追加し直す必要が生じます。そのため Datastore でのデータ モデリングでは、アプリケーション設計の早い段階でエンティティ グループについて決定することが重要です。あらかじめ考慮していないと、ある程度の整合性を実現するためのリファクタリングは、他の方法(キーのみのクエリとその後のキーによる検索、Memcahce の使用など)に限定されるおそれがあります。
キーのみのグローバル クエリとその後のキーによる検索
キーのみのクエリは、特別なグローバル クエリで、エンティティのプロパティ値は返されず、キーのみが返されます。返される値がキーのみなので、整合性の問題となるおそれのあるエンティティ値はクエリの結果に含まれません。キーのみのグローバル クエリを検索方法と組み合わせると、最新のエンティティ値を読み取ることができます。ただし、キーのみのグローバル クエリでは、クエリ時にインデックスの整合性がまだとれていない可能性を除外できず、エンティティをまったく取得できないことがあるので注意が必要です。この場合のクエリの結果は、古いインデックス値のフィルタリングに基づいて生成されているおそれがあります。以上をまとめると、アプリケーションの要件でクエリ時にインデックス値の整合性がとれていないことが許される場合のみ、デベロッパーはキーのみのグローバル クエリとその後でのキーによる検索を使用することができます。
Memcache の使用方法
Memcache サービスには永続性はありませんが、強整合性があります。そのため、Memcache 検索と Datastore クエリを組み合わせて、ほとんどの場合に整合性の問題を最小限に抑えるシステムを構築できます。
たとえば、Score 値が 0 より大きい Player エンティティのリストを管理するゲーム アプリケーションについて考えます。
- 挿入や更新のリクエストの場合、Memcache と Datastore の両方の Player エンティティ リストにリクエストを適用します。
- クエリ リクエストの場合、Memcache の Player エンティティのリストを読み取り、Memcache にリストがないときには、Datastore に対してキーのみのクエリを実行します。
Memcache にキャッシュされたリストがある場合は常に、返されるそのリストに整合性があります。リストがキャッシュにない場合や、Memcache サービスが一時的に使用できない場合、システムは Datastore のクエリから値を読み取る必要がありますが、この場合は整合性のない結果が返される可能性があります。この手法は、小規模な不整合は許容できるアプリケーションに適用できます。
Memcache を Datastore のキャッシュ レイヤとして使用する際のベスト プラクティスは次のとおりです。
- Memcache の例外やエラーをキャッチして、Memcache の値と Datastore の値の間で整合性を維持します。Memcache でのエントリの更新時に例外が発生したら、必ず Memcache の古いエントリを無効にします。無効にしないと、エンティティに異なる複数の値(Memcache 内の古い値と Datastore 内の新しい値)が存在するおそれが生じます。
- Memcache のエントリに有効期限を設定します。各エントリの期限を短期間に設定して、Memcache の例外の場合での不整合の可能性を最小限に抑えることをおすすめします。
- 同時実行制御でエントリを更新する際には、比較して設定機能を使用します。これにより、同じエントリに対する同時更新が互いに干渉しないようすることができます。
エンティティ グループへの段階的移行
前のセクションで提案した方法は、不整合の可能性を小さくするだけにすぎません。強整合性が必要な場合は、エンティティ グループと祖先クエリを基礎にしてアプリケーションを設計することが最良の方法です。しかし、既存のアプリケーションを移行するには、既存のデータモデルとアプリケーション ロジックをグローバル クエリから祖先クエリに変更することが必要な場合があり、実現しにくくなります。この場合、実現方法の 1 つとして、次のような段階的な移行プロセスがあります。
- 強整合性が必要なアプリケーションの機能を特定し、機能に優先順位を付けます。
- 既存のロジックを置き換えるのではなく、追加として、エンティティ グループを使用する insert() 関数や update() 関数の新しいロジックをコーディングします。これにより、新たな挿入や更新を新しいエンティティ グループと古いエンティティの両方に対して、適切な関数で処理できます。
- リクエストに対して新しいエンティティ グループが存在する場合、先に祖先クエリを実行するように読み取り関数やクエリ関数の既存のロジックを変更します。エンティティ グループが存在しない場合は、既存のグローバル クエリをフォールバック ロジックとして実行します。
この戦略では、既存のデータモデルから、エンティティ グループに基づく新しいデータモデルへの段階的移行が可能になり、結果整合性によって発生する問題のリスクを最小限にすることができます。ただし、この方法の実践は、実際のシステムでのアプリケーションの個々のユースケースと要件に左右されます。
デグレード モードへのフォールバック
現在のところ、アプリケーションで整合性が低下した状況をプログラムで検出するのは困難です。ただし、他の手段によって偶発的にアプリケーションの整合性が低下していると判断できる場合、デグレード モードを有効 / 無効にできるように実装して、強整合性が必要なアプリケーション ロジックの一部を無効にすることもできます。たとえば、請求レポートの画面で不整合のあるクエリ結果を表示するのではなく、その画面にメンテナンス メッセージを表示することもできます。この方法では、アプリケーションの他のサービスは続行できるので、ユーザー エクスペリエンスへの影響は小さくなります。
完全な整合性を実現する時間の短縮
何百万人ものユーザーや、数テラバイトの Datastore エンティティを持つ大規模アプリケーションでは、Datastore の不適切な利用が整合性の低下につながる可能性があります。不適切な利用には以下があります。
- エンティティ キーの連続番号
- 多すぎるインデックス
小規模なアプリケーションはこのような方法の影響は受けません。しかし、アプリケーションが非常に大きくなると、不適切な方法によって、整合性をとるのに必要な時間が長くなる可能性が増します。そのため、アプリケーションの設計の早い段階でこうした状況を避けることをおすすめします。
不適切な方法 1: 連続番号のエンティティ キー
App Engine SDK 1.8.1 のリリース前は通常、連続した小さい番号の ID を自動生成のキー名のデフォルトとして Datastore で使用していました。一部のドキュメントではこれを、アプリケーションがキー名を指定せずにエンティティを作成した場合の「従来のポリシー」と呼んでいます。この従来のポリシーでは、たとえば 1000、1001、1002 のような連続番号をエンティティ キーの名前として生成していました。しかし、前述のとおり Datastore はエンティティを辞書順で保存しているので、これらのエンティティは同じ Datastore サーバーに保存される可能性が高くなります。トラフィックが大量になるアプリケーションでは、この連続番号は特定のサーバーへのオペレーションの集中につながり、整合性をとるための待ち時間が長くなるおそれがあります。
App Engine SDK 1.8.1 で Datastore は新しい ID の番号付け方法として、ID を分散させるデフォルト ポリシーを導入しました(参考をご覧ください)。このデフォルト ポリシーでは、最大 16 文字のランダムな ID が生成され、ほぼ均一に分散されます。このポリシーを使用すると、大規模なアプリケーションのトラフィックは Datastore サーバー間に広く分散されるので、整合性をとるための時間が短縮されます。従来のポリシーとの互換性が特に必要ない限り、このデフォルト ポリシーをおすすめします。
エンティティのキー名を明示的に設定する場合は、キーの名前空間上に均一に分散したエンティティにアクセスするように命名方法を設計する必要があります。つまり、エンティティがキー名の辞書順に並べられたときに、特定の範囲にアクセスが集中しないようにします。集中させると、連続番号の場合と同じ問題が発生する可能性があります。
キー空間への偏ったアクセスについて説明するために、次のコードに示すような連続したキー名を持つようにエンティティを作成する例について考えます。
p1 = Person(key_name='0001') p2 = Person(key_name='0002') p3 = Person(key_name='0003') ...
アプリケーションのアクセス パターンによっては、キー名の特定の範囲に「ホットスポット」が発生します。たとえば、最近作成された Person エンティティにアクセスが集中することがあります。この場合、頻繁にアクセスするキーは、すべて値の大きい ID になります。そのため特定の Datastore サーバーに負荷が集中するおそれがあります。
一方、キー空間への均一の分散を説明するために、キー名に長いランダムな文字列を使用する場合を考えます。これを次の例で示します。
p1 = Person(key_name='t9P776g5kAecChuKW4JKCnh44uRvBDhU') p2 = Person(key_name='hCdVjL2jCzLqRnPdNNcPCAN8Rinug9kq') p3 = Person(key_name='PaV9fsXCdra7zCMkt7UX3THvFmu6xsUd') ...
この場合、最近作成された Person エンティティは、キー空間上に、そして複数のサーバーに分散します。これは、Person エンティティ数が十分に多いことを前提とします。
不適切な方法 2: 多すぎるインデックス
Datastore では、1 つのエンティティへの 1 回の更新が、そのエンティティの種類に対して定義されたすべてのインデックスの更新につながります。アプリケーションがカスタム インデックスを多数使用している場合、1 回の更新によってインデックス テーブル上で数十回、数百回、数千回もの更新が発生する可能性があります。大規模なアプリケーションでカスタム インデックスを多く使いすぎると、サーバー上での負荷が増大し、整合性を実現するための待ち時間が長くなるおそれがあります。
カスタム インデックスはほとんどの場合、カスタマー サポート、トラブルシューティング、データ分析などの作業要件をサポートするために追加されます。BigQuery は非常にスケーラビリティの高いクエリエンジンであり、事前にインデックスを作成せずに大規模データセットに対してアドホック クエリを実行できます。複雑なクエリが必要になるカスタマー サポート、トラブルシューティング、データ分析などのユースケースには Datastore よりも BigQuery のほうが適しています。
Datastore と BigQuery を組み合わせる方法の 1 つとして、それぞれ異なるビジネス要件のために利用する方法があります。アプリケーションの主要なロジックに必要なオンライン トランザクション処理(OLTP)に Datastore を使用し、バックエンド業務のオンライン分析処理(OLAP)に BigQuery を使用します。クエリに必要なデータを移行するために、Datastore から BigQuery に連続してデータをエクスポートするフローを実装する必要が生じることがあります。
カスタム インデックスの代わりを実装する以外に、おすすめの方法としては、インデックスに登録しないプロパティを明示する方法があります(プロパティと値の型をご覧ください)。Datastore はデフォルトで、エンティティの各種類のインデックス可能なプロパティごとに異なるインデックス テーブルを作成します。あるエンティティの種類に 100 のプロパティがある場合、その種類では 100 のインデックス テーブルが作成され、1 つのエンティティが更新されるたびに、100 回の更新が新たに発生します。この場合のベスト プラクティスは、クエリの条件に必要のないプロパティは、可能な限りインデックスに登録しないように設定することです。
このようにインデックスを最適化すると、整合性のために処理時間が増大する可能性を削減するだけでなく、インデックスを大量に使用する大規模なアプリケーションでの Datastore のストレージ コストを大幅に削減できる場合があります。
まとめ
結果整合性は非リレーショナル データベースに不可欠な要素であり、デベロッパーはスケーラビリティ、パフォーマンス、整合性の間で最適なバランスをとることができます。結果整合性と強整合性の間でバランスをとり、アプリケーションに最適なデータモデルを設計する方法を理解することが重要です。Datastore では、エンティティ グループと祖先クエリを使用することが、エンティティの特定のスコープで強整合性を保証する最良の方法です。前述のような制限のために、エンティティ グループを組み込めないアプリケーションでは、キーのみのクエリや Memcache のような他の方法を検討することをおすすめします。大規模アプリケーションの場合、ID の分散やインデックス登録の削減のようなベスト プラクティスを適用して、整合性を得るための時間を短縮します。Datastore を BigQuery と組み合わせて、複雑なクエリのビジネス要件を遂行し、できる限り Datastore のインデックスの使用を減らすことも重要です。
その他のリソース
このドキュメントで説明したトピックについて詳しくは、以下のリソースをご覧ください。
- Google App Engine: データの格納
- Datastore の概要
- Google Cloud Platform ブログ
- Cloud SQL
- Cloud SQL を使った Python App Engine の使用
- Bigtable: 構造化データ用分散ストレージ システム
- App Engine 1.5.2 SDK のリリース
- Megastore: スケーラビリティと可用性に優れたインタラクティブ サービスのためにストレージの提供
[1] エンティティ グループは、ルートまたは親のエンティティのキーを 1 つ指定するだけで作成できます。ルートや親の実際のエンティティを格納する必要はありません。エンティティ グループの機能は、複数のキーの関係に基づいてすべて実装されます。
[2] サポートされている上限は、エンティティ グループごとに 1 秒間に 1 回の更新(トランザクション以外)、またはエンティティ グループごとに 1 秒間に 1 回のトランザクションです。複数の更新を 1 つのトランザクションにまとめる場合は、トランザクションの最大サイズ 10 MB と Datastore サーバーの最大書き込み速度によって制限されます。