Cloud Monitoring collects metrics, events, and metadata from Google Cloud products. With Cloud Monitoring, you can also set up custom dashboards and usage alerts.
This document guides you through using metrics, learning about custom metrics dashboard, and setting alerts.
Monitored Resources
A monitored resource in Cloud Monitoring represents a logical or physical entity, such as a virtual machine, a database, or an application. Monitored resources contain a unique set of metrics that can be explored, reported through a dashboard, or used to create alerts. Each resource also has a set of resource labels, which are key-value pairs that hold additional information about the resource. Resource labels are available for all metrics associated with the resource.
Using the Cloud Monitoring API, Firestore in Datastore mode performance is monitored with the following resources:
| Resources | Description | Supported database mode |
firestore.googleapis.com/Database (recommended) | Monitored
resource type that provides breakdowns for project,
location* , and database_id . The
database_id label will be (default) for databases created
without a specific name. |
Applies to both modes. |
datastore_request | Monitored resource type for Datastore projects and does not provide breakdown for databases. |
Metrics
Firestore is available in two different modes, Firestore Native and Firestore in Datastore mode. For a feature comparison between these two modes, see Choose between database modes.
For a complete list of metrics for the Firestore in Datastore mode, see Firestore in Datastore metrics.
Service runtime metrics
The serviceruntime
metrics provide a high-level overview of a project's traffic. These metrics are
available for most Google Cloud APIs. The
consumed_api
monitored resource type contains these common metrics. These metrics are sampled
every 30 minutes resulting in data being smoothed out.
An important resource label for the serviceruntime metrics is method. This label
represents the underlying RPC method called. The SDK method that you call may
not necessarily be named the same as the underlying RPC method. The reason is
that the SDK provides high-level API abstraction. However, when trying to
understand how your application interacts with Firestore, it is
important to understand the metrics based on the name of the RPC method.
If you need to know what the underlying RPC method is for a given SDK method, see the API documentation.
api/request_count
This metric provides the count of completed requests, across protocol(request protocol, such as http, gRPC, etc.),
response code (HTTP response code), response_code_class (response code class, such as 2xx, 4xx,etc.), and grpc_status_code (numeric gRPC response code). Use this metric to
observe the overall API request and calculate the error rate.
In figure 1, requests that return a 2xx code grouped by service and method can be seen. 2xx codes are HTTP status codes that indicate the request was successful.
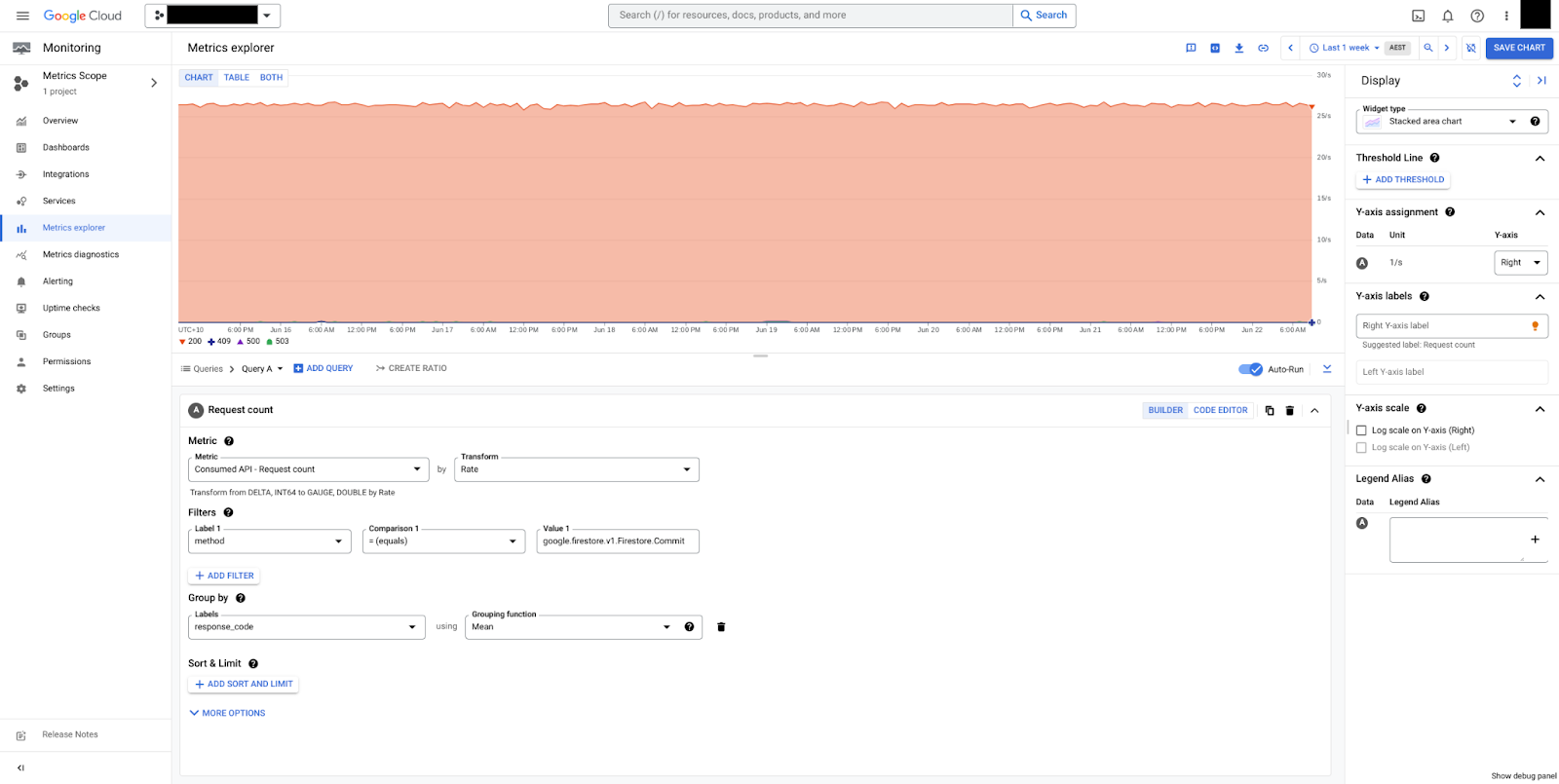
In figure 2, commits grouped by response_code can be seen. In this example, we only see HTTP 200 responses which implies that the database is healthy.
Use the following service runtime metrics to monitor your database.
api/request_count in datastore_request resource type
The api/request_count metric is also available under the datastore_request
resource type with api_method and response_code breakdowns. Use this metric
instead to take advantage of the finer sampling period, which helps catch
spikes.
api/request_latencies
The api/request_latencies metric provides latency distributions across all completed requests.
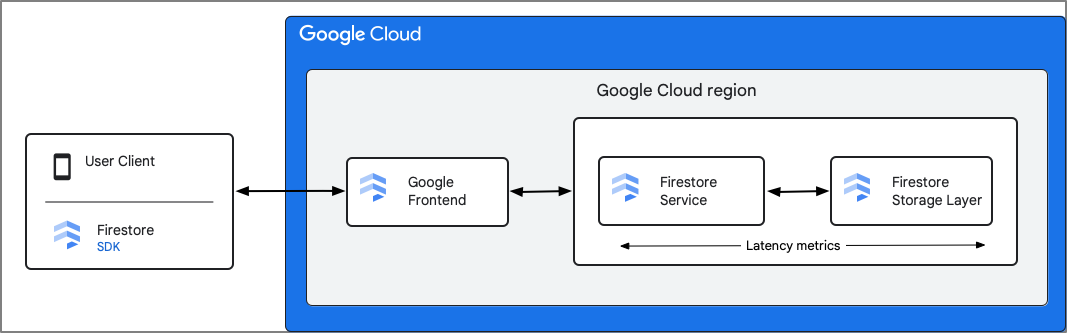
Firestore records metrics from the Firestore Service component. Latency metrics include the time that Firestore receives the request to the time that Firestore finishes sending the response, including interactions with the storage layer. Due to this, round-trip latency (rtt) between the client and the Firestore service is not included in these metrics.
api/request_sizes and api/response_sizes
The api/request_sizes and api/response_sizes metrics respectively provide
insights into payload sizes (in bytes). These can be useful for understanding
write workloads that send large amounts of data or queries that are too broad,
and return large payloads.
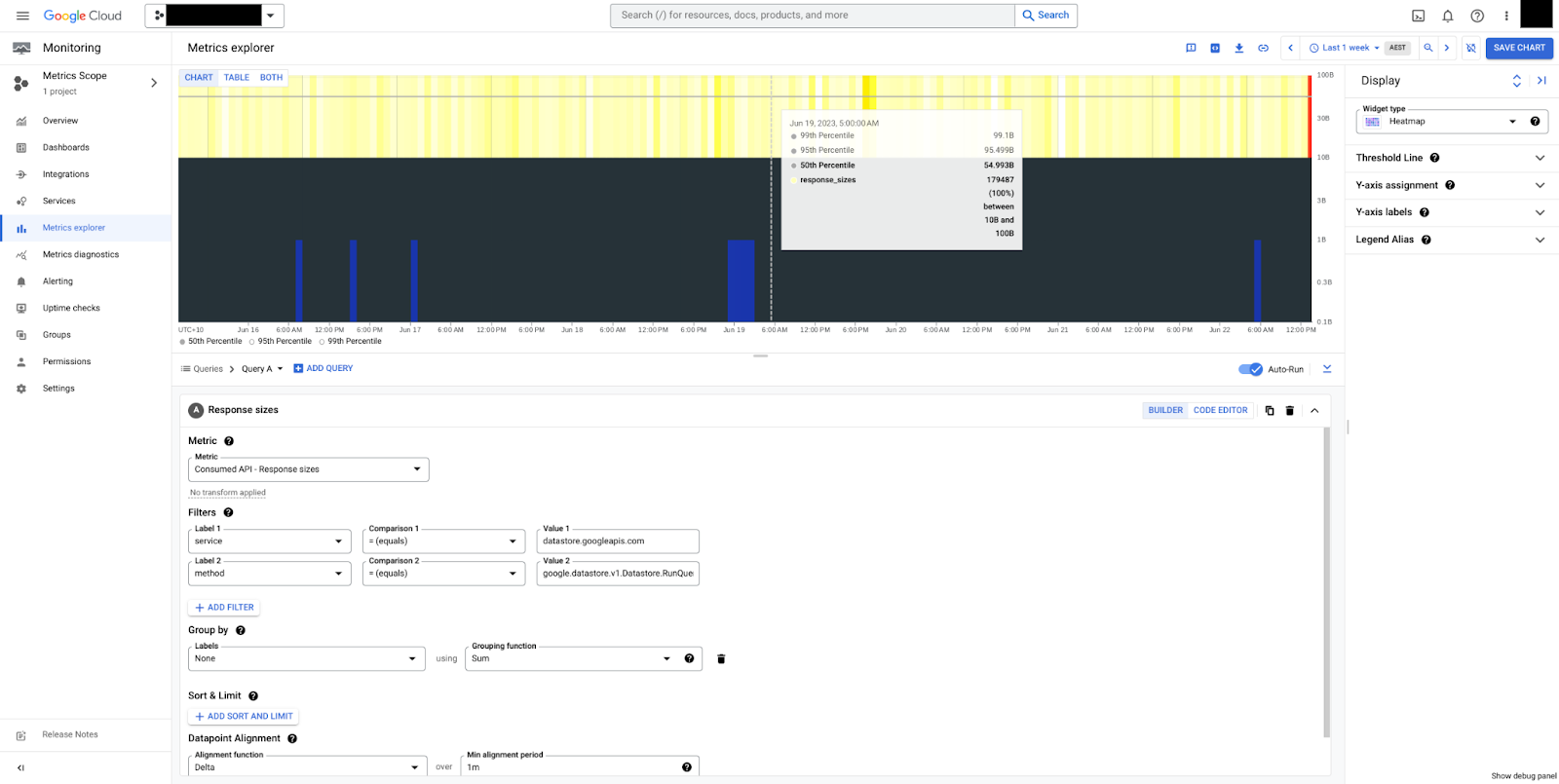
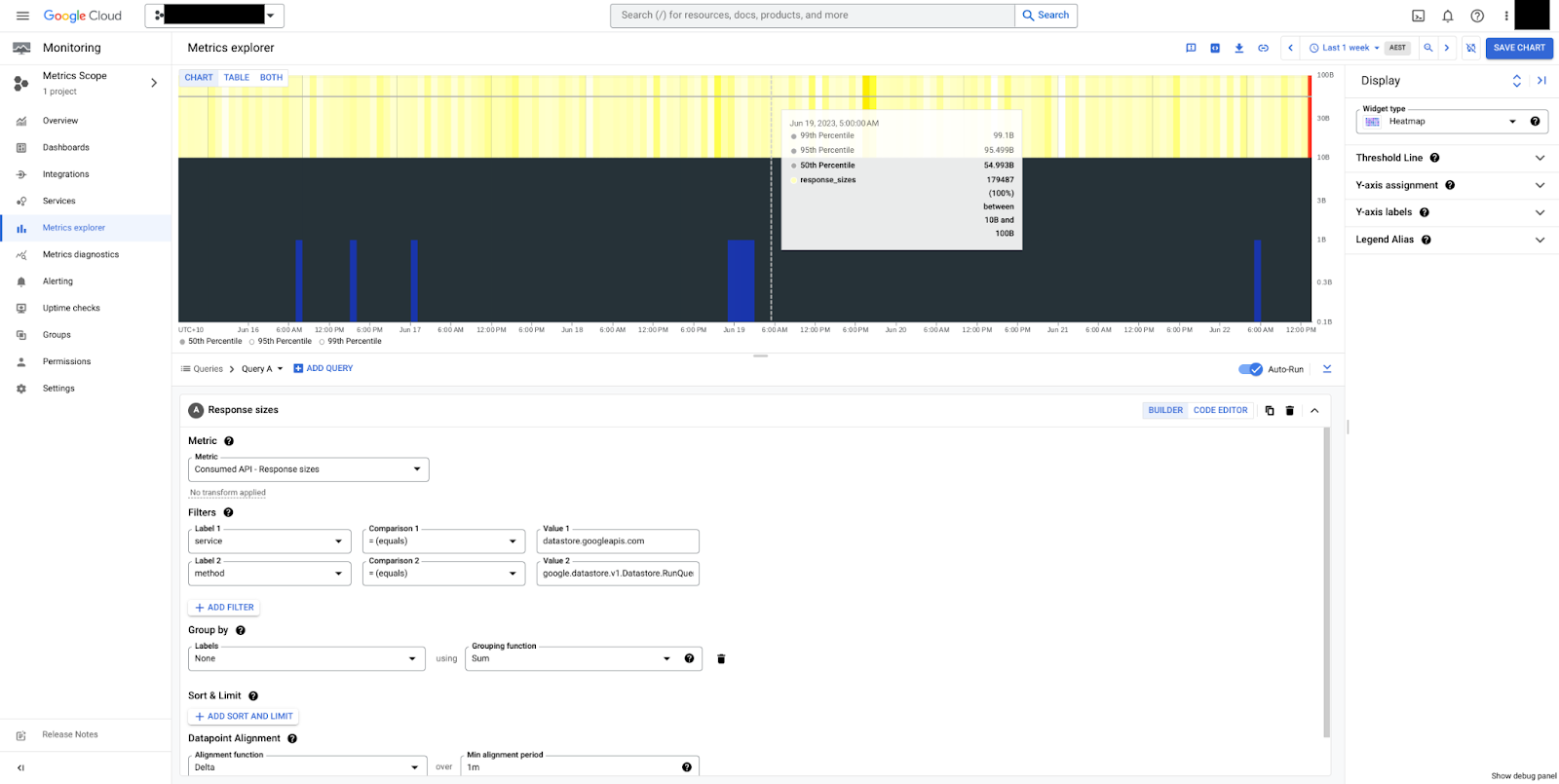
In figure 5, a heatmap for response sizes for the RunQuery method can be seen.
We can see that sizes are steady, 50 bytes median, and overall between 10 bytes
and 100 bytes. Note that payload sizes are always measured in uncompressed
bytes, exclusive of transmission control overheads.
Entity operation metrics
These metrics provide distributions in bytes of payload sizes for reads (lookups
and queries) and writes to a Firestore database. The values represent
the total size of the payload. For example, any results returned by a query.
These metrics are similar to the api/request_sizes and api/response_sizes metrics
with the main difference being the entity operation metrics provide more
granular sampling, but less granular breakdowns.
For example, the entity operation metrics use the datastore_request monitored
resource so there is no service or method breakdown.
entity/read_sizes: Distribution of sizes of read entities, grouped by type.entity/write_sizes: Distribution of sizes of written entities, grouped by operations.
Index metrics
Index write rates can be contrasted with the document/write_ops_count metric
to understand the index fanout
ratio.
index/write_count: Count of index writes.

In figure 7, you can see how index write rate can be contrasted with document write rate. In this example, for every document write, there are approximately 6 index writes, which is a relatively small index fanout rate.
TTL Metrics
The TTL metrics are available for both Firestore Native and Firestore in Datastore mode databases. Use these metrics to monitor the effect of the TTL policy enforced.
entity/ttl_deletion_count: Total count of entities deleted by TTL services.entity/ttl_expiration_to_deletion_delays: Time elapsed between when an entity with a TTL expired, and when it was actually deleted.If you see that the TTL deletion delays are taking longer than 24 hours, contact support.
What' next
- Learn about using the Cloud Monitoring dashboard to view metrics.