Trino (antes Presto) es un motor de consulta en SQL distribuido diseñado para consultar grandes conjuntos de datos distribuidos en una o más fuentes de datos heterogéneas. Trino puede consultar Hive, MySQL, Kafka y otras fuentes de datos a través de conectores. En este instructivo, se muestra cómo hacer lo siguiente:
- Instala el servicio de Trino en un clúster de Dataproc
- Consultar datos públicos de un cliente de Trino instalado en tu máquina local que se comunique con un servicio de Trino en tu clúster
- Ejecutar consultas desde una aplicación Java que se comunique con el servicio Trino en tu clúster a través del controlador JDBC de Java de Trino
Objetivos
- Extraer los datos de BigQuery
- Cargar los datos en Cloud Storage como archivos CSV
- Transformar los datos:
- Exponer los datos como una tabla externa de Hive para que Trino pueda consultarlos
- Convertir los datos del formato CSV al formato Parquet para que las consultas sean más rápidas
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
Si aún no lo hiciste, crea un Google Cloud proyecto y un bucket de Cloud Storage para conservar los datos que se usan en este instructivo. 1. Configura tu proyecto- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init - In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
- Configura las variables de entorno:
- PROJECT: El ID de tu proyecto
- BUCKET_NAME: El nombre del depósito de Cloud Storage que creaste en la sección Antes de comenzar
- REGION: La región donde se creará el clúster que se usa en este instructivo, por ejemplo, "us-west1"
- WORKERS: Se recomienda usar entre 3 y 5 trabajadores para las actividades de este instructivo.
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Ejecuta Google Cloud CLI en tu máquina local para crear el clúster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway - Ejecuta el siguiente comando en tu máquina local para importar los datos de taxis de BigQuery como archivos CSV sin encabezados al depósito de Cloud Storage que creaste en la sección Antes de comenzar.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Crea tablas externas de Hive que estén respaldadas por los archivos CSV y Parquet de tu depósito de Cloud Storage.
- Crea la tabla externa de Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Verifica la creación de la tabla externa de Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Crea otro
chicago_taxi_trips_parquetde tabla externa de Hive con las mismas columnas, pero con datos almacenados en formato Parquet para mejorar el rendimiento de las consultas.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Carga los datos de la tabla CSV de Hive en la tabla de Parquet de Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Verifica que los datos se hayan cargado correctamente.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Crea la tabla externa de Hive
- Ejecuta el siguiente comando en tu máquina local para establecer una conexión SSH al nodo principal del clúster. La terminal local dejará de responder durante la ejecución del comando.
gcloud compute ssh trino-cluster-m
- En la ventana de la terminal de SSH del nodo principal de tu clúster, ejecuta la CLI de Trino, que se conecta al servidor de Trino que se ejecuta en el nodo principal.
trino --catalog hive --schema default
- Cuando aparezca el mensaje
trino:default, verifica que Trino pueda encontrar las tablas de Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Ejecuta consultas desde el mensaje
trino:defaulty compara el rendimiento de las consultas de datos Parquet y las consultas de datos CSV.- Consulta de datos Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Consulta de datos CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Consulta de datos Parquet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Para borrar tu clúster, realiza los siguientes pasos:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION} - Para borrar el depósito de Cloud Storage que creaste en la sección Antes de comenzar, incluidos los archivos de datos almacenados en el depósito, ejecuta lo siguiente:
gcloud storage rm gs://${BUCKET_NAME} --recursive
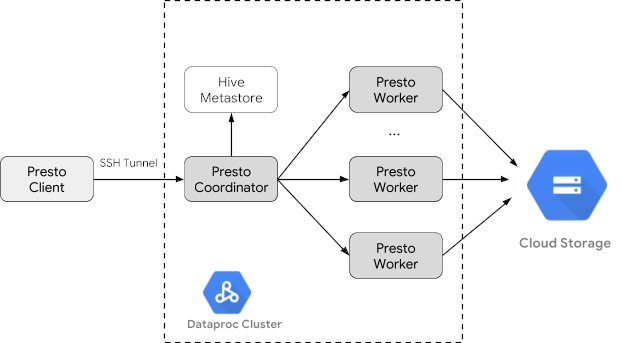
Crea un clúster de Dataproc
Crea un clúster de Dataproc con la marca optional-components (disponible en la versión de imagen 2.1 y posteriores) para instalar el componente opcional de Trino en el clúster y la marca enable-component-gateway para habilitar la puerta de enlace de componentes y permitirte acceder a la IU web de Trino desde la consola de Google Cloud .
Preparar los datos
Exporta el conjunto de datos chicago_taxi_trips de bigquery-public-data a Cloud Storage como archivos CSV y, luego, crea una tabla externa de Hive para hacer referencia a los datos.
Ejecuta consultas
Puedes ejecutar consultas de forma local desde la CLI de Trino o desde una aplicación.
Consultas de la CLI de Trino
En esta sección, se muestra cómo consultar el conjunto de datos de taxis de Parquet de Hive con la CLI de Trino.
Consultas de aplicaciones Java
Para ejecutar consultas desde una aplicación Java a través del controlador JDBC de Java de Trino, sigue estos pasos:
1. Descarga el controlador JDBC de Java de Trino.
1. Agrega una dependencia trino-jdbc en Maven pom.xml.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}Registro y supervisión
Logging
Los registros de Trino se encuentran en /var/log/trino/, en los nodos principales y trabajadores del clúster.
IU web
Consulta Visualiza las URLs de la puerta de enlace de componentes y accede a ellas para abrir la IU web de Trino que se ejecuta en el nodo principal del clúster en tu navegador local.
Supervisión
Trino expone la información de tiempo de ejecución del clúster a través de tablas de tiempo de ejecución.
En una sesión de Trino (desde trino:default), ejecuta la siguiente consulta para ver los datos de la tabla del entorno de ejecución:
select * FROM system.runtime.nodes;
Limpia
Una vez que completes el instructivo, puedes limpiar los recursos que creaste para que dejen de usar la cuota y generar cargos. En las siguientes secciones, se describe cómo borrar o desactivar estos recursos.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
Para borrar el proyecto, sigue estos pasos: