目標
このチュートリアルでは、次の方法について説明します。
- Dataproc クラスタを作成し、クラスタに Apache HBase と Apache ZooKeeper をインストールする
- Dataproc クラスタのマスターノードで実行されている HBase シェルを使用して HBase テーブルを作成する
- Cloud Shell を使用して、Java または PySpark Spark ジョブを Dataproc サービスに送信して HBase テーブルへのデータの書き込みと読み取りを行う
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
Google Cloud Platform プロジェクトをまだ作成していない場合は、作成します。
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Cloud Shell セッション ターミナルで次のコマンドを実行して、以下の操作を行います。
- HBase コンポーネントと ZooKeeper コンポーネントをインストールする
- 3 つのワーカーノードをプロビジョニングする(このチュートリアルのコードを実行するには、3~5 つのワーカーをおすすめします)
- コンポーネント ゲートウェイを有効にする
- イメージ バージョン 2.0 を使用する
--propertiesフラグを使用して、Spark ドライバとエグゼキュータのクラスパスに HBase 構成と HBase ライブラリを追加する
Google Cloud コンソールまたは Cloud Shell セッション ターミナルから、Dataproc クラスタ マスターノードに SSH で接続します。
マスターノードで Apache HBase Spark コネクタのインストールを確認します。
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
SSH セッション ターミナルを開いたままにして、以下の操作を行います。
- HBase テーブルを作成する
- (Java ユーザー): クラスタのマスターノードでコマンドを実行して、クラスタにインストールされているコンポーネントのバージョンを確認する
- コードを実行した後、Hbase テーブルをスキャンする
HBase シェルを開きます。
hbase shell
「cf」列ファミリーを持つ HBase の「my-table」を作成します。
create 'my_table','cf'
- テーブルの作成を確認するには、 Google Cloud コンソールで、Google Cloud コンソール コンポーネント ゲートウェイのリンクの [HBase] をクリックし、Apache HBase UI を開きます。
my-tableは、[ホーム] ページの [テーブル] セクションに表示されます。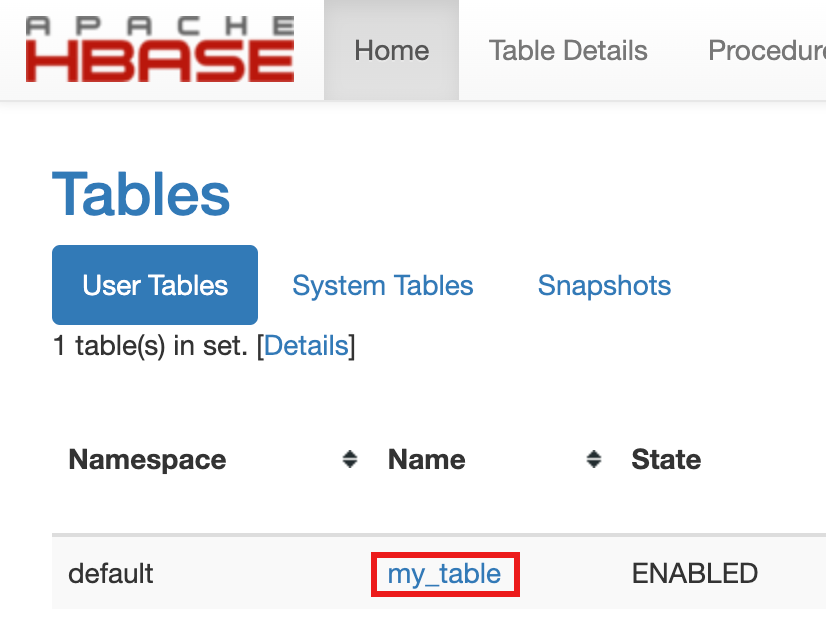
- テーブルの作成を確認するには、 Google Cloud コンソールで、Google Cloud コンソール コンポーネント ゲートウェイのリンクの [HBase] をクリックし、Apache HBase UI を開きます。
Cloud Shell セッション ターミナルを開きます。
Cloud Shell セッション ターミナルに GitHub の GoogleCloudDataproc/cloud-dataproc リポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
cloud-dataproc/spark-hbaseディレクトリに変更します。cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Dataproc ジョブを送信します。
pom.xmlファイルでコンポーネントのバージョンを設定します。- Dataproc 2.0.x リリース バージョンのページには、イメージ 2.0 の最新および直前の 4 つのサブマイナー バージョンにインストールされている Scala、Spark、HBase コンポーネントのバージョンが記載されています。
- 2.0 イメージ バージョンのクラスタのサブマイナー バージョンを確認するには、Google Cloud コンソールの [クラスタ] ページでクラスタ名をクリックして、[クラスタの詳細] ページを開きます。クラスタのイメージ バージョンが一覧表示されます。
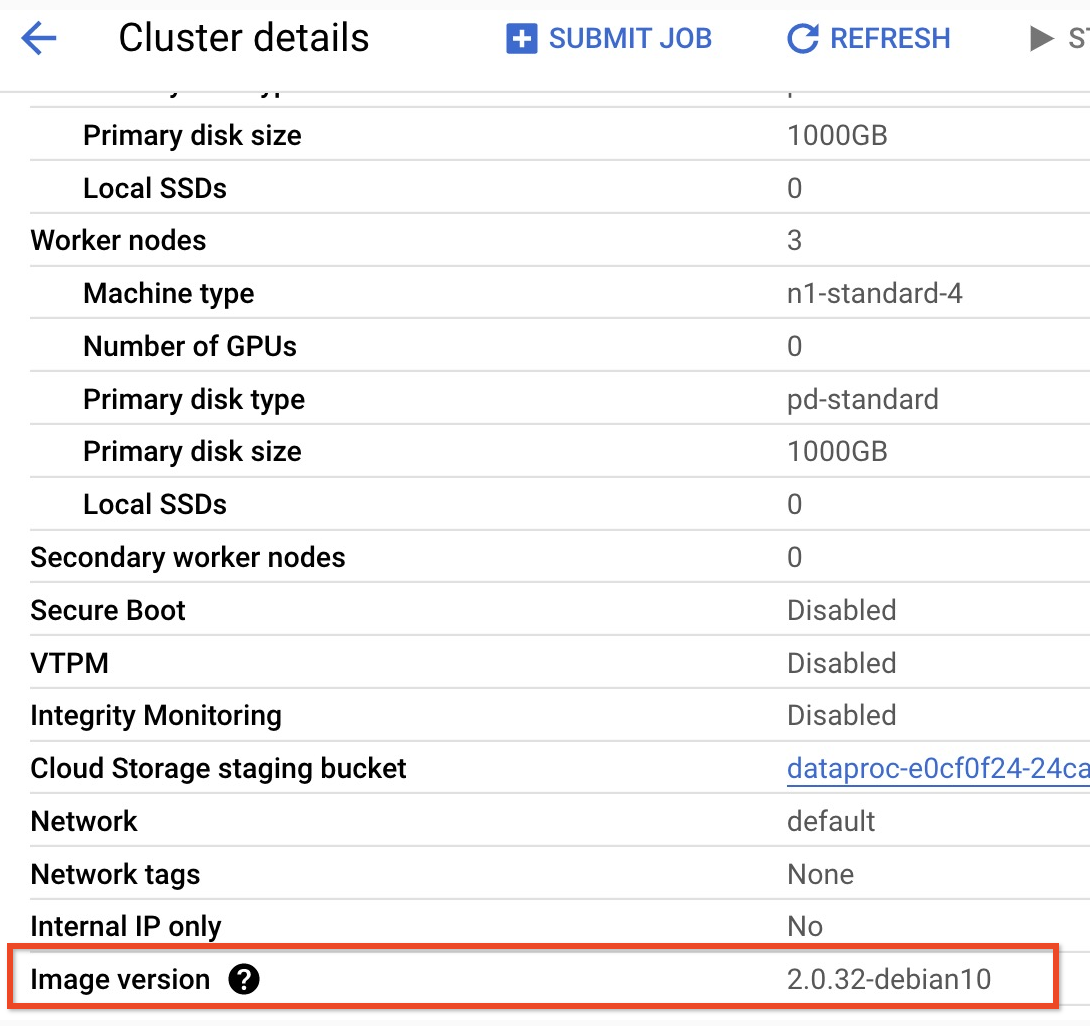
- 2.0 イメージ バージョンのクラスタのサブマイナー バージョンを確認するには、Google Cloud コンソールの [クラスタ] ページでクラスタ名をクリックして、[クラスタの詳細] ページを開きます。クラスタのイメージ バージョンが一覧表示されます。
- または、クラスタのマスターノードから SSH セッション ターミナルで次のコマンドを実行して、コンポーネントのバージョンを確認することもできます。
- Scala のバージョンを確認します。
scala -version
- Spark のバージョンを確認します(Ctrl+D キーを押して終了します)。
spark-shell
- HBase のバージョンを確認します。
hbase version
- Maven の
pom.xmlで、Spark、Scala、HBase のバージョン依存関係を特定します。<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versionは現在の Spark HBase コネクタのバージョンです。このバージョン番号は変更しないでください。
- Scala のバージョンを確認します。
- Cloud Shell エディタで
pom.xmlファイルを編集し、正しい Scala、Spark、HBase のバージョン番号を挿入します。編集が完了したら、[ターミナルを開く] をクリックして Cloud Shell ターミナル コマンドラインに戻ります。cloudshell edit .
- Cloud Shell で Java 8 に切り替えます。コードをビルドするには、この JDK バージョンが必要です(プラグインの警告メッセージは無視してかまいません)。
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Java 8 のインストールを確認します。
java -version
openjdk version "1.8..."
- Dataproc 2.0.x リリース バージョンのページには、イメージ 2.0 の最新および直前の 4 つのサブマイナー バージョンにインストールされている Scala、Spark、HBase コンポーネントのバージョンが記載されています。
jarファイルをビルドします。mvn clean package
.jarファイルは/targetサブディレクトリに配置されます(例:target/spark-hbase-1.0-SNAPSHOT.jar)。ジョブを送信します。
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars:.jarファイルの名前を「target/」の後、「.jar」の前に挿入します。- クラスタを作成したときに Spark ドライバとエグゼキュータの HBase クラスパスを設定しなかった場合、ジョブ送信コマンドで次の
‑‑propertiesフラグを指定して、ジョブ送信ごとにクラスパスを設定する必要があります。--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Cloud Shell セッション ターミナルの出力で HBase テーブルの出力を確認します。
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
ジョブを送信します。
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- クラスタを作成したときに Spark ドライバとエグゼキュータの HBase クラスパスを設定しなかった場合、ジョブ送信コマンドで次の
‑‑propertiesフラグを指定して、ジョブ送信ごとにクラスパスを設定する必要があります。--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- クラスタを作成したときに Spark ドライバとエグゼキュータの HBase クラスパスを設定しなかった場合、ジョブ送信コマンドで次の
Cloud Shell セッション ターミナルの出力で HBase テーブルの出力を確認します。
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
- HBase シェルを開きます。
hbase shell
- 「my-table」をスキャンします。
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
クリーンアップ
チュートリアルが終了したら、作成したリソースをクリーンアップして、割り当ての使用を停止し、課金されないようにできます。次のセクションで、リソースを削除または無効にする方法を説明します。
プロジェクトの削除
課金されないようにする最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
クラスタを削除する
- クラスタを削除するには:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Dataproc クラスタを作成する
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
コネクタのインストールを確認する
HBase テーブルを作成する
前の手順で開いたマスターノードの SSH セッション ターミナルで、このセクションに記載されているコマンドを実行します。
Spark コードを表示する
Java
Python
コードを実行する
Java
Python
HBase テーブルをスキャンする
HBase テーブルのコンテンツをスキャンするには、コネクタのインストールを確認するで開いたマスターノードの SSH セッション ターミナルで次のコマンドを実行します。