Obiettivi
Questo tutorial mostra come:
- Crea un cluster Dataproc, installando Apache HBase e Apache ZooKeeper sul cluster
- Crea una tabella HBase utilizzando la shell HBase in esecuzione sul nodo master del cluster Dataproc
- Utilizza Cloud Shell per inviare un job Spark Java o PySpark al servizio Dataproc che scrive i dati nella tabella HBase e poi li legge.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
Se non l'hai ancora fatto, crea un progetto Google Cloud Platform.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Esegui questo comando in un terminale di sessione di Cloud Shell per:
- Installa i componenti HBase e ZooKeeper
- Esegui il provisioning di tre nodi worker (consigliamo da tre a cinque worker per eseguire il codice in questo tutorial)
- Attiva il gateway dei componenti
- Utilizzare la versione immagine 2.0
- Utilizza il flag
--propertiesper aggiungere la configurazione e la libreria HBase ai classpath del driver e dell'esecutore Spark.
Dalla console Google Cloud o da un terminale di sessione Cloud Shell, esegui SSH nel nodo master del cluster Dataproc.
Verifica l'installazione del connettore Apache HBase Spark sul nodo master:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Tieni aperto il terminale della sessione SSH per:
- Creare una tabella HBase
- (Utenti Java): esegui comandi sul nodo master del cluster per determinare le versioni dei componenti installati sul cluster
- Scansiona la tabella Hbase dopo aver eseguito il codice
Apri la shell HBase:
hbase shell
Crea una tabella HBase "my-table" con una famiglia di colonne "cf":
create 'my_table','cf'
- Per confermare la creazione della tabella, nella console Google Cloud , fai clic su HBase nei link Google Cloud Component Gateway della console per aprire la UI di Apache HBase.
my-tableè elencato nella sezione Tabelle della pagina Home.
- Per confermare la creazione della tabella, nella console Google Cloud , fai clic su HBase nei link Google Cloud Component Gateway della console per aprire la UI di Apache HBase.
Apri un terminale di sessione Cloud Shell.
Clona il repository GitHub GoogleCloudDataproc/cloud-dataproc nel terminale della sessione Cloud Shell:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Passa alla directory
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Invia il job Dataproc.
- Imposta le versioni dei componenti nel file
pom.xml.- La pagina
Versioni di rilascio 2.0.x
di Dataproc elenca le versioni dei componenti Scala, Spark e HBase installate
con le quattro versioni secondarie più recenti e precedenti dell'immagine 2.0.
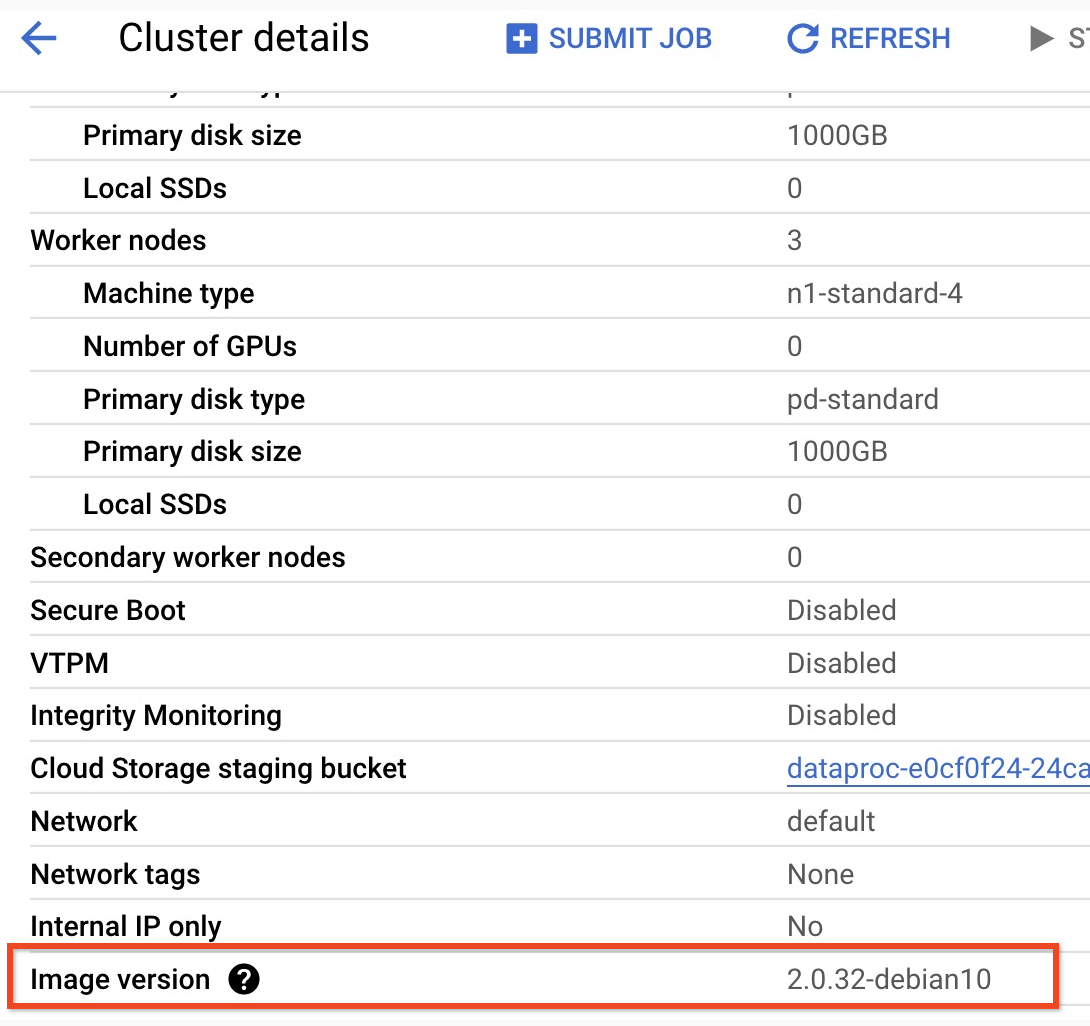
- Per trovare la versione secondaria del cluster della versione dell'immagine 2.0,
fai clic sul nome del cluster nella pagina
Cluster nella
consoleGoogle Cloud per aprire la pagina Dettagli cluster, in cui è elencata la
versione dell'immagine del cluster.
- Per trovare la versione secondaria del cluster della versione dell'immagine 2.0,
fai clic sul nome del cluster nella pagina
Cluster nella
consoleGoogle Cloud per aprire la pagina Dettagli cluster, in cui è elencata la
versione dell'immagine del cluster.
- In alternativa, puoi eseguire i seguenti comandi in un
terminale della sessione SSH
dal nodo master del cluster per determinare le versioni dei componenti:
- Controlla la versione di Scala:
scala -version
- Controlla la versione di Spark (CTRL+D per uscire):
spark-shell
- Controlla la versione di HBase:
hbase version
- Identifica le dipendenze delle versioni di Spark, Scala e HBase
in Maven
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versionè la versione corrente del connettore Spark HBase; lascia invariato questo numero di versione.
- Controlla la versione di Scala:
- Modifica il file
pom.xmlnell'editor di Cloud Shell per inserire i numeri di versione corretti di Scala, Spark e HBase. Al termine della modifica, fai clic su Apri terminale per tornare alla riga di comando del terminale Cloud Shell.cloudshell edit .
- Passa a Java 8 in Cloud Shell. Questa versione di JDK è necessaria per
compilare il codice (puoi ignorare eventuali messaggi di avviso del plug-in):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Verifica l'installazione di Java 8:
java -version
openjdk version "1.8..."
- La pagina
Versioni di rilascio 2.0.x
di Dataproc elenca le versioni dei componenti Scala, Spark e HBase installate
con le quattro versioni secondarie più recenti e precedenti dell'immagine 2.0.
- Crea il file
jar:mvn clean package
.jarviene inserito nella sottodirectory/target(ad esempio,target/spark-hbase-1.0-SNAPSHOT.jar. Invia il job.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: inserisci il nome del file.jardopo "target/" e prima di ".jar".- Se non hai impostato i classpath HBase del driver e dell'executor Spark quando hai
creato il cluster,
devi impostarli a ogni invio del job includendo il
seguente flag
‑‑propertiesnel comando di invio del job:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Visualizza l'output della tabella HBase nell'output del terminale della sessione Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Invia il job.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Se non hai impostato i classpath HBase del driver e dell'executor Spark quando hai
creato il cluster,
devi impostarli a ogni invio del job includendo il
seguente flag
‑‑propertiesnel comando di invio del job:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Se non hai impostato i classpath HBase del driver e dell'executor Spark quando hai
creato il cluster,
devi impostarli a ogni invio del job includendo il
seguente flag
Visualizza l'output della tabella HBase nell'output del terminale della sessione Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
- Apri la shell HBase:
hbase shell
- Scansiona "my-table":
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Esegui la pulizia
Al termine del tutorial, puoi eliminare le risorse che hai creato in modo che non utilizzino più la quota generando addebiti. Le seguenti sezioni descrivono come eliminare o disattivare queste risorse.
Elimina il progetto
Il modo più semplice per eliminare la fatturazione è eliminare il progetto creato per il tutorial.
Per eliminare il progetto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Elimina il cluster
- Per eliminare il cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Crea un cluster Dataproc
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Verificare l'installazione del connettore
Crea una tabella HBase
Esegui i comandi elencati in questa sezione nel terminale della sessione SSH del nodo master che hai aperto nel passaggio precedente.
Visualizza il codice Spark
Java
Python
Esegui il codice
Java
Python
Scansiona la tabella HBase
Puoi scansionare i contenuti della tabella HBase eseguendo i seguenti comandi nel terminale della sessione SSH del nodo master che hai aperto in Verifica l'installazione del connettore: