您可以通过以下方式将作业提交到现有 Dataproc 集群:通过 Dataproc API jobs.submit HTTP 或程序化请求,在本地终端窗口或 Cloud Shell 中使用 Google Cloud CLI gcloud 命令行工具,或通过在本地浏览器中打开的 Google Cloud 控制台。您还可以通过 SSH 连接到集群中的主实例,然后无需使用 Dataproc 服务,直接从实例运行作业。
如何提交作业
控制台
在浏览器中通过 Google Cloud 控制台打开 Dataproc 提交作业页面。
Spark 作业示例
如需提交示例 Spark 作业,请在提交作业页面上填写以下字段:
- 从集群列表中选择集群名称。
- 将作业类型设置为
Spark。 - 将主类或 jar 设置为
org.apache.spark.examples.SparkPi。 - 将参数设置为单个参数
1000。 - 将
file:///usr/lib/spark/examples/jars/spark-examples.jar添加到 Jar 文件:file:///表示 Hadoop LocalFileSystem 方案。在创建集群时,Dataproc 在集群主节点上安装了/usr/lib/spark/examples/jars/spark-examples.jar。- 或者,您可以为其中一个 jar 指定 Cloud Storage 路径 (
gs://your-bucket/your-jarfile.jar) 或 Hadoop 分布式文件系统路径 (hdfs://path-to-jar.jar)。
点击提交以启动作业。作业启动后,就会添加到作业列表中。
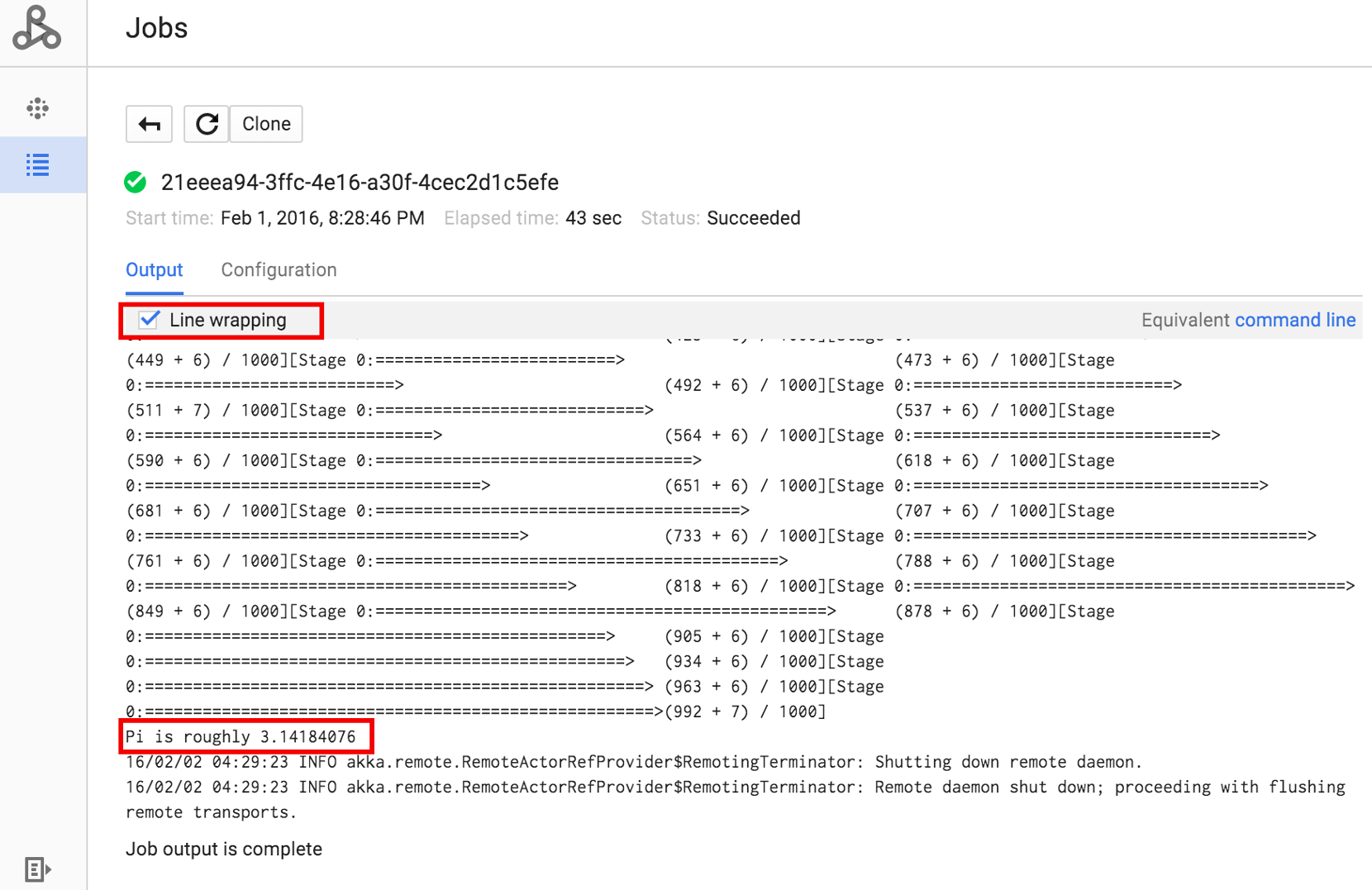
点击“作业 ID”以打开作业页面,您可以在该页面中查看作业的驱动程序输出。 由于此作业生成的输出行过长,超出浏览器窗口宽度,您可以勾选换行框,将所有输出文本显示在视图内,从而展示 pi 的计算结果。
您可以使用如下所示的 gcloud dataproc jobs wait 命令,从命令行查看作业的驱动程序输出(如需了解详情,请参阅查看作业的输出–GCLOUD 命令)。将项目 ID 复制并粘贴为 --project 标志的值,并将作业 ID(显示在“作业”列表中)作为最终参数。
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
以下为上述提交的示例 SparkPi 作业的驱动程序输出的片段:
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
如需将作业提交到 Dataproc 集群,请在本地终端窗口或 Cloud Shell 中运行 gcloud CLI gcloud dataproc jobs submit 命令。
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-args
- 列出位于 Cloud Storage 中的可公开访问的
hello-world.py。gcloud storage cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- 将 Pyspark 作业提交到 Dataproc。
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- 运行预安装在 Dataproc 集群主节点上的 SparkPi 示例。
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
本部分介绍如何使用 Dataproc jobs.submit API 提交 Spark 作业以计算 pi 的近似值。
在使用任何请求数据之前,请先进行以下替换:
- project-id: Google Cloud 项目 ID
- region:集群地区
- clusterName:集群名称
HTTP 方法和网址:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
请求 JSON 正文:
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
Python
Go
Node.js
在集群上直接提交作业
如果您想不使用 Dataproc 服务而在集群上直接运行作业,请通过 SSH 连接到集群的主节点,然后在主节点上运行作业。
建立与虚拟机主实例的 SSH 连接后,在终端窗口中集群的主节点上运行命令,以执行以下操作:
- 打开 Spark shell。
- 运行一个简单的 Spark 作业,用于计算可公开访问的 Cloud Storage 文件中的 Python“hello-world”文件(七行)的行数。
退出 shell。
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
在 Dataproc 上运行 bash 作业
您可能希望将 bash 脚本作为 Dataproc 作业运行,因为不支持将您使用的引擎用作顶级 Dataproc 作业类型,或者因为您需要在使用脚本中的 hadoop 或 spark-submit 启动作业之前先进行其他设置或计算参数。
Pig 示例
假设您已将 hello.sh bash 脚本复制到 Cloud Storage:
gcloud storage cp hello.sh gs://${BUCKET}/hello.sh由于 pig fs 命令使用 Hadoop 路径,因此请将脚本从 Cloud Storage 复制到指定为 file:/// 的目的地,以确保它位于本地文件系统而非 HDFS 上。后续 sh 命令会自动引用本地文件系统,并且不需要 file:/// 前缀。
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'或者,由于 Dataproc 作业提交 --jars 参数将文件暂存到为作业生命周期创建的临时目录中,因此您可以将 Cloud Storage shell 脚本指定为 --jars 参数:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'请注意,--jars 参数还可以引用本地脚本:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'