Una risorsa NodeGroup Dataproc è un gruppo di nodi cluster Dataproc che eseguono un ruolo assegnato. Questa pagina descrive il
gruppo di nodi driver, ovvero un gruppo di VM Compute Engine a cui è assegnato il ruolo Driver allo scopo di eseguire i driver dei job sul cluster Dataproc.
Quando utilizzare i gruppi di nodi driver
- Utilizza i gruppi di nodi driver solo quando devi eseguire molti job simultanei su un cluster condiviso.
- Aumenta le risorse del nodo master prima di utilizzare i gruppi di nodi driver per evitare limitazioni dei gruppi di nodi driver.
In che modo i nodi driver ti aiutano a eseguire job simultanei
Dataproc avvia un processo di driver del job su un nodo master del cluster Dataproc per ogni job. Il processo del driver, a sua volta,
esegue un driver dell'applicazione, ad esempio spark-submit, come processo secondario.
Tuttavia, il numero di job simultanei in esecuzione sul master è limitato dalle risorse disponibili sul nodo master e, poiché i nodi master Dataproc non possono essere scalati, un job può non riuscire o essere limitato quando le risorse del nodo master non sono sufficienti per eseguire un job.
I gruppi di nodi driver sono gruppi di nodi speciali gestiti da YARN, quindi la concorrenza dei job non è limitata dalle risorse del nodo master. Nei cluster con un gruppo di nodi driver, i driver dell'applicazione vengono eseguiti sui nodi driver. Ogni nodo driver può eseguire più driver di applicazioni se il nodo dispone di risorse sufficienti.
Vantaggi
L'utilizzo di un cluster Dataproc con un gruppo di nodi driver ti consente di:
- Scalare orizzontalmente le risorse del driver del job per eseguire più job simultanei
- Scalare le risorse del driver separatamente da quelle del worker
- Ottieni una riduzione più rapida dei cluster di immagini Dataproc 2.0 e versioni successive. In questi cluster, il master dell'app viene eseguito all'interno di un driver Spark in un gruppo di nodi driver (
spark.yarn.unmanagedAM.enabledè impostato sutrueper impostazione predefinita). - Personalizza l'avvio del nodo del driver. Puoi aggiungere
{ROLE} == 'Driver'a uno script di inizializzazione per fare in modo che lo script esegua azioni per un gruppo di nodi driver nella selezione dei nodi.
Limitazioni
- I gruppi di nodi non sono supportati nei modelli di workflow Dataproc.
- I cluster di gruppi di nodi non possono essere arrestati, riavviati o scalati automaticamente.
- Il master dell'app MapReduce viene eseguito sui nodi worker. La fare lo scale down dei nodi worker può essere lenta se attivi il ritiro controllato.
- La concorrenza dei job è influenzata dalla
dataproc:agent.process.threads.job.maxproprietà del cluster. Ad esempio, con tre master e questa proprietà impostata sul valore predefinito di100, la concorrenza massima dei job a livello di cluster è300.
Gruppo di nodi del driver rispetto alla modalità cluster Spark
| Funzionalità | Modalità cluster Spark | Gruppo di nodi driver |
|---|---|---|
| Fare lo scale down dimensioni dei nodi worker | I driver di lunga durata vengono eseguiti sugli stessi nodi worker dei container di breve durata, il che rallenta la riduzione del numero di worker utilizzando il ritiro controllato. | I nodi worker fare lo scale down più rapidamente quando i driver vengono eseguiti sui gruppi di nodi. |
| Output del driver in streaming | Richiede la ricerca nei log YARN per trovare il nodo in cui è stato pianificato il driver. | L'output del driver viene trasmesso in streaming a Cloud Storage ed è visualizzabile
nella console Google Cloud e nell'output del comando gcloud dataproc jobs wait
al termine di un job. |
Autorizzazioni IAM del gruppo di nodi driver
Le seguenti autorizzazioni IAM sono associate alle azioni correlate al gruppo di nodi Dataproc.
| Autorizzazione | Azione |
|---|---|
dataproc.nodeGroups.create
|
Crea gruppi di nodi Dataproc. Se un utente dispone di
dataproc.clusters.create nel progetto, questa autorizzazione viene
concessa. |
dataproc.nodeGroups.get |
Visualizza i dettagli di un gruppo di nodi Dataproc. |
dataproc.nodeGroups.update |
Ridimensiona un gruppo di nodi Dataproc. |
Operazioni del gruppo di nodi del driver
Puoi utilizzare gcloud CLI e l'API Dataproc per creare, recuperare, ridimensionare, eliminare e inviare un job a un gruppo di nodi driver Dataproc.
Crea un cluster di gruppi di nodi driver
Un gruppo di nodi driver è associato a un cluster Dataproc. Crea un gruppo di nodi durante la creazione di un cluster Dataproc. Puoi utilizzare gcloud CLI o l'API REST Dataproc per creare un cluster Dataproc con un gruppo di nodi driver.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Flag obbligatori:
- CLUSTER_NAME: il nome del cluster, che deve essere univoco all'interno di un progetto. Il nome deve iniziare con una lettera minuscola e può contenere fino a 51 lettere minuscole, numeri e trattini. Non può terminare con un trattino. Il nome di un cluster eliminato può essere riutilizzato.
- REGION: la regione in cui si troverà il cluster.
- SIZE: il numero di nodi driver nel gruppo di nodi. Il numero di nodi necessari dipende dal carico del job e dal tipo di macchina del pool di driver. Il numero di nodi del gruppo di driver minimo è uguale alla memoria totale o alle vCPU richieste dai driver del job diviso per la memoria o le vCPU di ogni pool di driver.
- NODE_GROUP_ID: facoltativo e consigliato. L'ID deve essere univoco all'interno del cluster. Utilizza questo ID per identificare il gruppo di driver nelle operazioni future, ad esempio il ridimensionamento del gruppo di nodi. Se non specificato, Dataproc genera l'ID del gruppo di nodi.
Flag consigliato:
--enable-component-gateway: aggiungi questo flag per attivare il gateway dei componenti di Dataproc, che fornisce l'accesso all'interfaccia web YARN. Le pagine Applicazione e Scheduler dell'interfaccia utente YARN mostrano lo stato del cluster e del job, la memoria della coda delle applicazioni, la capacità dei core e altre metriche.
Flag aggiuntivi:i seguenti flag driver-pool facoltativi possono essere aggiunti
al comando gcloud dataproc clusters create per personalizzare il gruppo di nodi.
| Flag | Valore predefinito |
|---|---|
--driver-pool-id |
Una stringa identificatore, generata dal servizio se non impostata dal flag. Questo ID può essere utilizzato per identificare il gruppo di nodi quando si eseguono operazioni future pool di nodi, ad esempio il ridimensionamento del gruppo di nodi. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
Nessun valore predefinito. Quando specifichi un acceleratore, il tipo di GPU è obbligatorio; il numero di GPU è facoltativo. |
--num-driver-pool-local-ssds |
Nessuno predefinito |
--driver-pool-local-ssd-interface |
Nessuno predefinito |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Completa un
AuxiliaryNodeGroup
nell'ambito di una richiesta
cluster.create
dell'API Dataproc.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: obbligatorio. ID progetto Google Cloud.
- REGION: obbligatorio. Regione del cluster Dataproc.
- CLUSTER_NAME: obbligatorio. Il nome del cluster, che deve essere univoco all'interno di un progetto. Il nome deve iniziare con una lettera minuscola e può contenere fino a 51 lettere minuscole, numeri e trattini. Non può terminare con un trattino. Il nome di un cluster eliminato può essere riutilizzato.
- SIZE: obbligatorio. Numero di nodi nel gruppo di nodi.
- NODE_GROUP_ID: Facoltativo e consigliato. L'ID deve essere univoco all'interno del cluster. Utilizza questo ID per identificare il gruppo di driver nelle operazioni future, ad esempio il ridimensionamento del gruppo di nodi. Se non specificato, Dataproc genera l'ID del gruppo di nodi.
Opzioni aggiuntive: vedi NodeGroup.
Metodo HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
Corpo JSON della richiesta:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Recupera i metadati del cluster del gruppo di nodi del driver
Puoi utilizzare il comando
gcloud dataproc node-groups describe
o l'API Dataproc per
ottenere i metadati del gruppo di nodi driver.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Flag obbligatori:
- NODE_GROUP_ID: Puoi eseguire
gcloud dataproc clusters describe CLUSTER_NAMEper elencare l'ID del gruppo di nodi. - CLUSTER_NAME: il nome del cluster.
- REGION: la regione del cluster.
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: obbligatorio. ID progetto Google Cloud.
- REGION: obbligatorio. La regione del cluster.
- CLUSTER_NAME: obbligatorio. Il nome del cluster.
- NODE_GROUP_ID: obbligatorio. Puoi eseguire
gcloud dataproc clusters describe CLUSTER_NAMEper elencare l'ID del gruppo di nodi.
Metodo HTTP e URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Ridimensiona un gruppo di nodi driver
Puoi utilizzare il comando
gcloud dataproc node-groups resize
o l'API Dataproc
per aggiungere o rimuovere nodi driver da un gruppo di nodi driver del cluster.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Flag obbligatori:
- NODE_GROUP_ID: Puoi eseguire
gcloud dataproc clusters describe CLUSTER_NAMEper elencare l'ID del gruppo di nodi. - CLUSTER_NAME: il nome del cluster.
- REGION: la regione del cluster.
- SIZE: specifica il nuovo numero di nodi driver nel gruppo di nodi.
Flag facoltativo:
--graceful-decommission-timeout=TIMEOUT_DURATION: Quando riduci le dimensioni di un gruppo di nodi, puoi aggiungere questo flag per specificare un ritiro controllato TIMEOUT_DURATION per evitare l'interruzione immediata dei driver di job. Consiglio:imposta una durata del timeout almeno pari alla durata del job più lungo in esecuzione nel gruppo di nodi (il recupero dei driver non riusciti non è supportato).
Esempio: comando di scalabilità verticale NodeGroup di gcloud CLI:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Esempio: comando di fare lo scale down NodeGroup di gcloud CLI:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: obbligatorio. ID progetto Google Cloud.
- REGION: obbligatorio. La regione del cluster.
- NODE_GROUP_ID: obbligatorio. Puoi eseguire
gcloud dataproc clusters describe CLUSTER_NAMEper elencare l'ID del gruppo di nodi. - SIZE: obbligatorio. Nuovo numero di nodi nel gruppo di nodi.
- TIMEOUT_DURATION: (Facoltativo) Quando ridimensioni un gruppo di nodi,
puoi aggiungere un
gracefulDecommissionTimeoutal corpo della richiesta per evitare la chiusura immediata dei driver di job. Suggerimento:imposta una durata del timeout almeno pari alla durata del job più lungo in esecuzione nel gruppo di nodi (il recupero dei driver non riusciti non è supportato).Esempio:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
Metodo HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
Corpo JSON della richiesta:
{
"size": SIZE,
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Elimina un cluster di gruppi di nodi driver
Quando elimini un cluster Dataproc, vengono eliminati anche i gruppi di nodi associati al cluster.
Invia un job
Puoi utilizzare il comando gcloud dataproc jobs submit o l'API Dataproc per inviare un job a un cluster con un gruppo di nodi driver.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Flag obbligatori:
- JOB_COMMAND: specifica il comando del job.
- CLUSTER_NAME: il nome del cluster.
- DRIVER_MEMORY: quantità di memoria dei driver del job in MB necessaria per eseguire un job (vedi Controlli della memoria Yarn).
- DRIVER_VCORES: il numero di vCPU necessarie per eseguire un job.
Flag aggiuntivi:
- DATAPROC_FLAGS: aggiungi eventuali flag gcloud dataproc jobs submit aggiuntivi correlati al tipo di job.
- JOB_ARGS: aggiungi eventuali argomenti (dopo
--) da passare al job.
Esempi: puoi eseguire gli esempi seguenti da una sessione del terminale SSH su un cluster di gruppi di nodi driver Dataproc.
Job Spark per stimare il valore di
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job Spark wordcount:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
Job PySpark per stimare il valore di
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Job MapReduce Hadoop TeraGen:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT_ID: obbligatorio. ID progetto Google Cloud.
- REGION: obbligatorio. Regione del cluster Dataproc
- CLUSTER_NAME: obbligatorio. Il nome del cluster, che deve essere univoco all'interno di un progetto. Il nome deve iniziare con una lettera minuscola e può contenere fino a 51 lettere minuscole, numeri e trattini. Non può terminare con un trattino. Il nome di un cluster eliminato può essere riutilizzato.
- DRIVER_MEMORY: obbligatorio. Quantità di memoria dei driver del job in MB necessaria per eseguire un job (vedi Controlli della memoria YARN).
- DRIVER_VCORES: obbligatorio. Il numero di vCPU necessarie per eseguire un job.
pi).
Metodo HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON della richiesta:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- Installa la libreria client
- Configurare le credenziali predefinite dell'applicazione
- Esegui il codice
- Job Spark per stimare il valore di pi greco:
- Job PySpark per stampare "hello world":
Visualizza i log dei job
Per visualizzare lo stato del job e risolvere i problemi relativi ai job, puoi visualizzare i log dei driver utilizzando gcloud CLI o la console Google Cloud .
gcloud
I log del driver del job vengono trasmessi in streaming all'output di gcloud CLI o alla consoleGoogle Cloud durante l'esecuzione del job. I log del driver vengono conservati in un bucket di staging del cluster Dataproc in Cloud Storage.
Esegui questo comando gcloud CLI per elencare la posizione dei log dei driver in Cloud Storage:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
La posizione Cloud Storage dei log dei driver è elencata come
driverOutputResourceUri nell'output comandoo nel seguente formato:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Console
Per visualizzare i log del cluster del gruppo di nodi:
Per trovare i log, puoi utilizzare il seguente formato di query di Esplora log:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud ID progetto.
- CLUSTER_NAME: il nome del cluster.
- LOG_TYPE:
- Log utente di Yarn:
yarn-userlogs - Log di Yarn Resource Manager:
hadoop-yarn-resourcemanager - Log di Yarn Node Manager:
hadoop-yarn-nodemanager
- Log utente di Yarn:
Monitorare le metriche
I driver dei job del gruppo di nodi Dataproc vengono eseguiti in una
coda secondaria dataproc-driverpool-driver-queue in una partizione dataproc-driverpool.
Metriche del gruppo di nodi driver
La tabella seguente elenca le metriche del driver del gruppo di nodi associato, che vengono raccolte per impostazione predefinita per i gruppi di nodi driver.
| Metrica del gruppo di nodi driver | Descrizione |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
La quantità di memoria disponibile in mebibyte in
dataproc-driverpool-driver-queue nella partizione
dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
Il numero di container in attesa (in coda) in
dataproc-driverpool-driver-queue nella partizione
dataproc-driverpool. |
Metriche coda secondaria
La tabella seguente elenca le metriche della coda secondaria. Le metriche vengono raccolte per impostazione predefinita per i gruppi di nodi driver e possono essere abilitate per la raccolta su qualsiasi cluster Dataproc.
| Metrica coda secondaria | Descrizione |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
La quantità di memoria disponibile in mebibyte in questa coda nella partizione predefinita. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Numero di contenitori in attesa (in coda) in questa coda nella partizione predefinita. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
Il numero di job con un runtime compreso tra 0 e 60 minuti
in questa coda in tutte le partizioni. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
Il numero di job con un runtime compreso tra 60 e 300 minuti
in questa coda in tutte le partizioni. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
Il numero di job con un runtime compreso tra 300 e 1440 minuti
in questa coda in tutte le partizioni. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
Il numero di job con una durata maggiore di 1440 minuti
in questa coda in tutte le partizioni. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
Numero di applicazioni inviate a questa coda in tutte le partizioni. |
Per visualizzare YARN ChildQueueMetrics e DriverPoolsQueueMetrics nella consoleGoogle Cloud :
Seleziona le risorse Istanza VM → Personalizzata in Metrics Explorer.
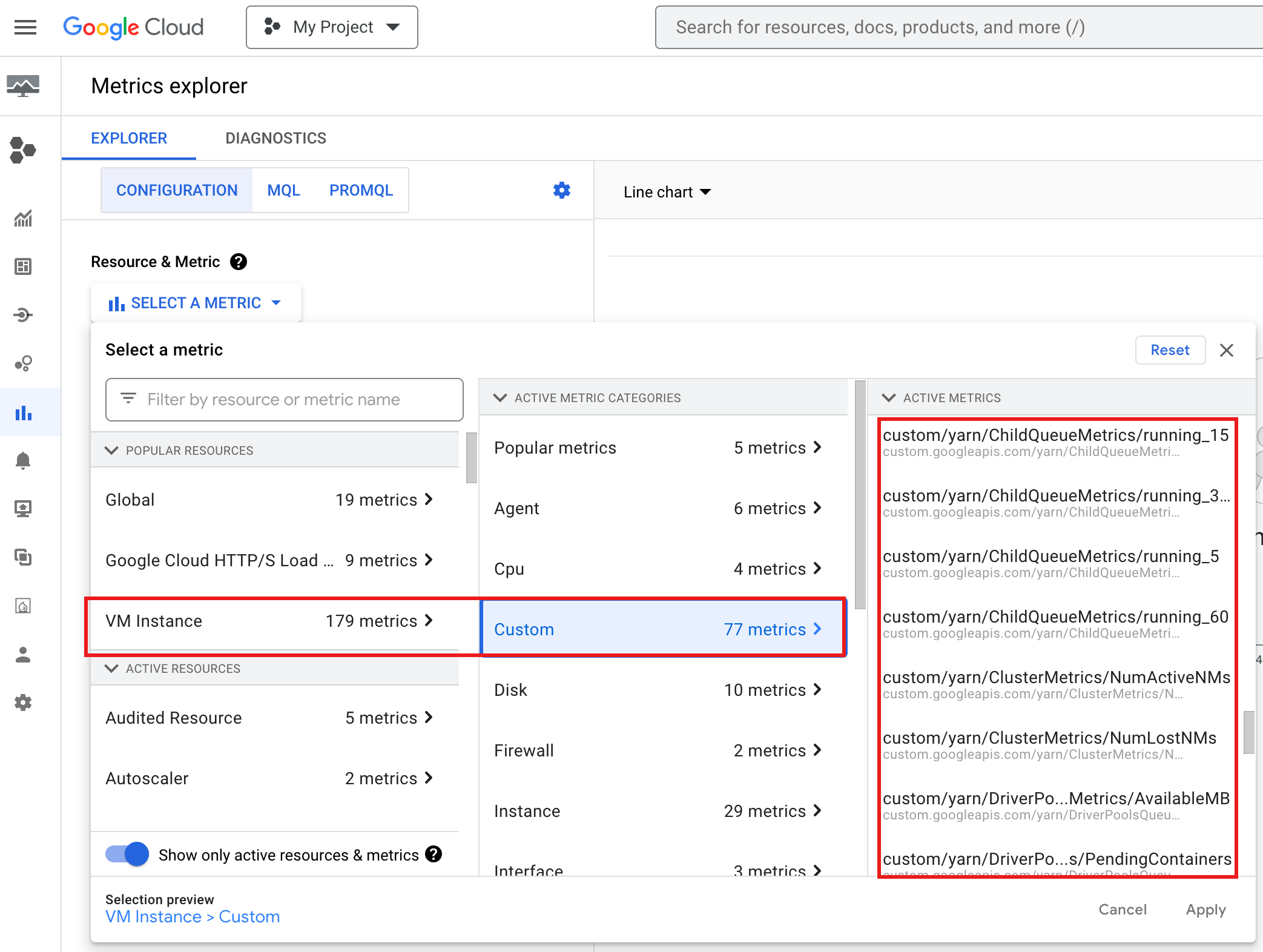
Esegui il debug del driver job del gruppo di nodi
Questa sezione fornisce condizioni ed errori del gruppo di nodi del driver con consigli per correggere la condizione o l'errore.
Condizioni
Condizione:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBsi sta avvicinando a0. Ciò indica che le code dei pool di driver del cluster stanno esaurendo la memoria.Consiglio: aumenta le dimensioni del pool di autisti.
Condizione:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersè maggiore di 0. Ciò può indicare che le code dei pool di driver del cluster stanno esaurendo la memoria e YARN sta mettendo in coda i job.Consiglio: aumenta le dimensioni del pool di autisti.
Errori
Errore:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Consiglio:imposta
driver-required-memory-mbedriver-required-vcorescon numeri positivi.Errore:
Container exited with a non-zero exit code 137.Consiglio: aumenta
driver-required-memory-mbper l'utilizzo della memoria del job.