次の例では、Hadoop、YARN、HIVE リソースへのユーザーのアクセスを制御するために、Ranger および Solr コンポーネントとともに Kerberos 対応の Dataproc クラスタを作成して使用します。
注:
Ranger ウェブ UI には、コンポーネント ゲートウェイを介してアクセスできます。
Kerberos クラスタを備えた Ranger では、Dataproc は Kerberos ユーザーの領域とインスタンスを削除して、Kerberos ユーザーをシステム ユーザーにマッピングします。たとえば、Kerberos プリンシパル
user1/cluster-m@MY.REALMはシステムuser1にマッピングされており、Ranger ポリシーはuser1に対する権限を許可または却下するように定義されています。
クラスタを作成します。
- 次の
gcloudコマンドは、ローカル ターミナル ウィンドウまたはプロジェクトの Cloud Shell から実行できます。gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=SOLR,RANGER \ --enable-component-gateway \ --properties="dataproc:ranger.kms.key.uri=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key,dataproc:ranger.admin.password.uri=gs://bucket/admin-password.encrypted" \ --kerberos-root-principal-password-uri=gs://bucket/kerberos-root-principal-password.encrypted \ --kerberos-kms-key=projects/project-id/locations/global/keyRings/keyring/cryptoKeys/key
- 次の
クラスタの実行後、 Google Cloud コンソールで Dataproc の [クラスタ] ページに移動し、クラスタの名前を選択して [クラスタの詳細] ページを開きます。[ウェブ インターフェース] タブをクリックすると、クラスタにインストールされているデフォルト コンポーネントとオプション コンポーネントのウェブ インターフェースへのコンポーネント ゲートウェイ リンクのリストが表示されます。Ranger リンクをクリックします。

admin というユーザー名と Ranger の管理者パスワードを入力して、Ranger にログインします。
Ranger の管理 UI がローカル ブラウザで開きます。
YARN アクセス ポリシー
この例では、YARN root.default キューへのユーザー アクセスを許可および拒否する Ranger ポリシーを作成します。
Ranger 管理 UI から
yarn-dataprocを選択します。
[yarn-dataproc Policies] ページで、[Add New Policy] をクリックします。[Create Policy] ページで、次のフィールドに値を入力または選択します。
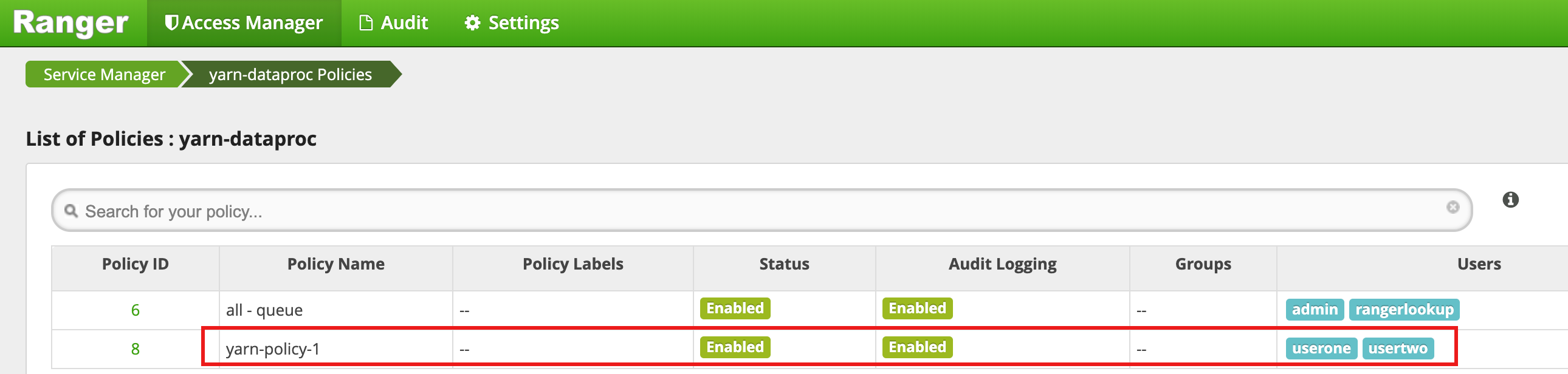
Policy Name: yarn-policy-1Queue: root.defaultAudit Logging: YesAllow Conditions:Select User: useronePermissions: すべての権限を付与するには [Select All]
Deny Conditions:Select User: usertwoPermissions: すべての権限を拒否する場合は [Select All]
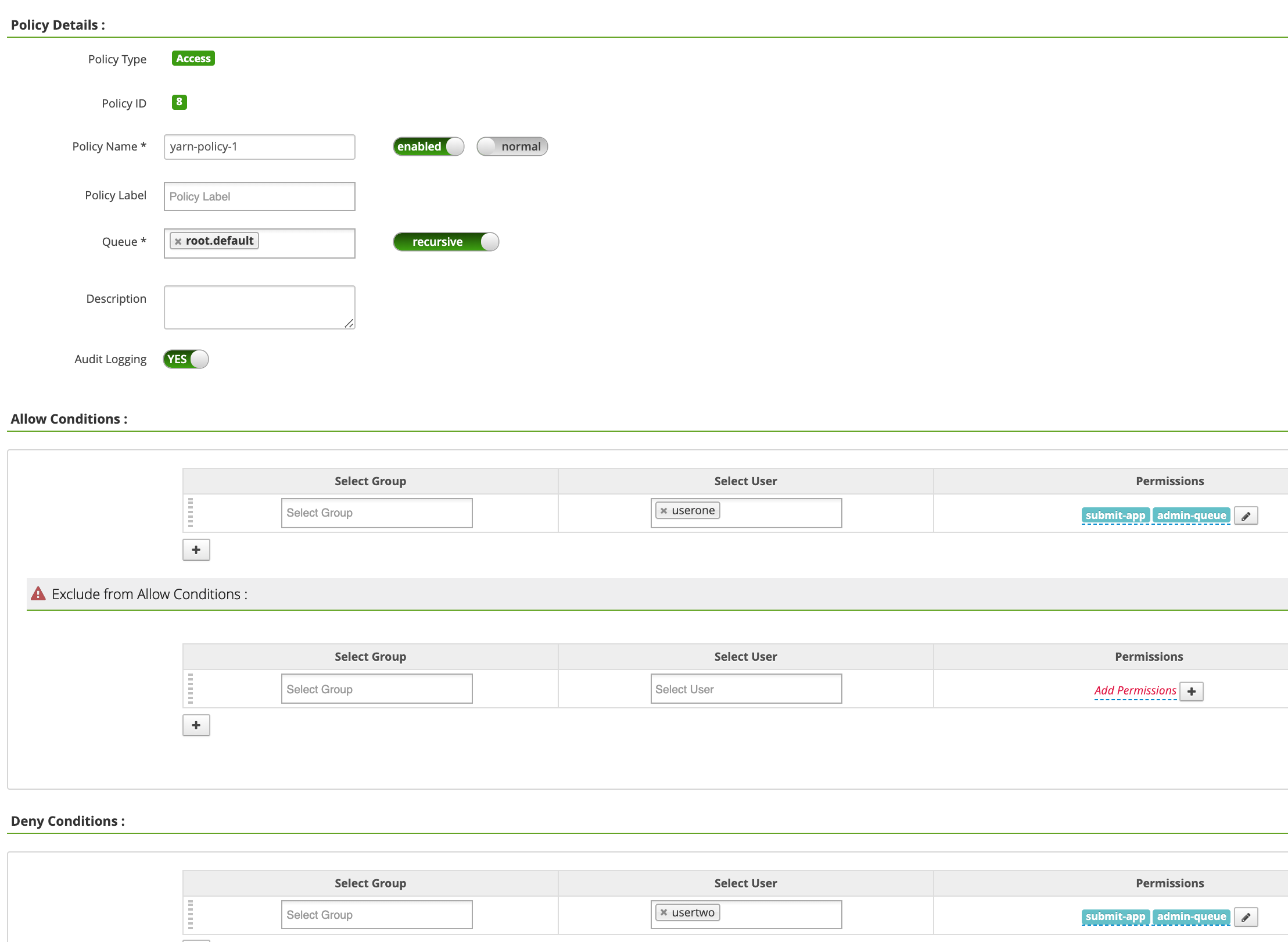
[Add] をクリックしてポリシーを保存します。このポリシーは、[yarn-dataproc Policies] ページに表示されます。
マスター SSH セッション ウィンドウで Hadoop の MapReduce ジョブを userone として実行します。
userone@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Ranger UI に、
useroneがジョブの送信を許可されたことが示されます。
- Ranger UI に、
VM マスター SSH セッション ウィンドウから Hadoop の MapReduce ジョブを
usertwoとして実行します。usertwo@example-cluster-m:~$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduced-examples. jar pi 5 10
- Ranger UI に、
usertwoがジョブの送信のためのアクセスが拒否されたことが示されます。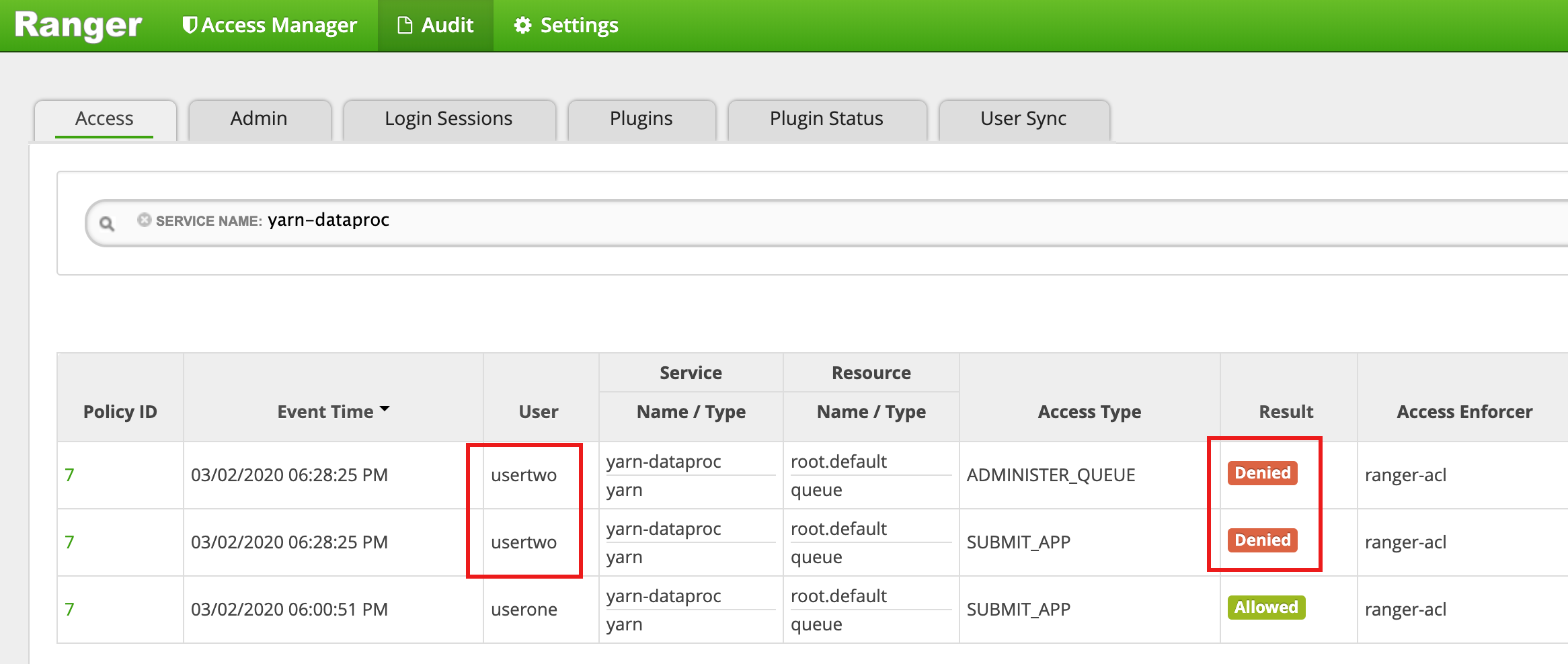
- Ranger UI に、
HDFS アクセス ポリシー
この例では、HDFS /tmp ディレクトリへのユーザー アクセスを許可および拒否する Ranger ポリシーを作成します。
Ranger 管理 UI から
hadoop-dataprocを選択します。
[hadoop-dataproc Policies] ページで、[Add New Policy] をクリックします。[Create Policy] ページで、次のフィールドに値を入力または選択します。
Policy Name: hadoop-policy-1Resource Path: /tmpAudit Logging: YesAllow Conditions:Select User: useronePermissions: すべての権限を付与するには [Select All]
Deny Conditions:Select User: usertwoPermissions: すべての権限を拒否する場合は [Select All]
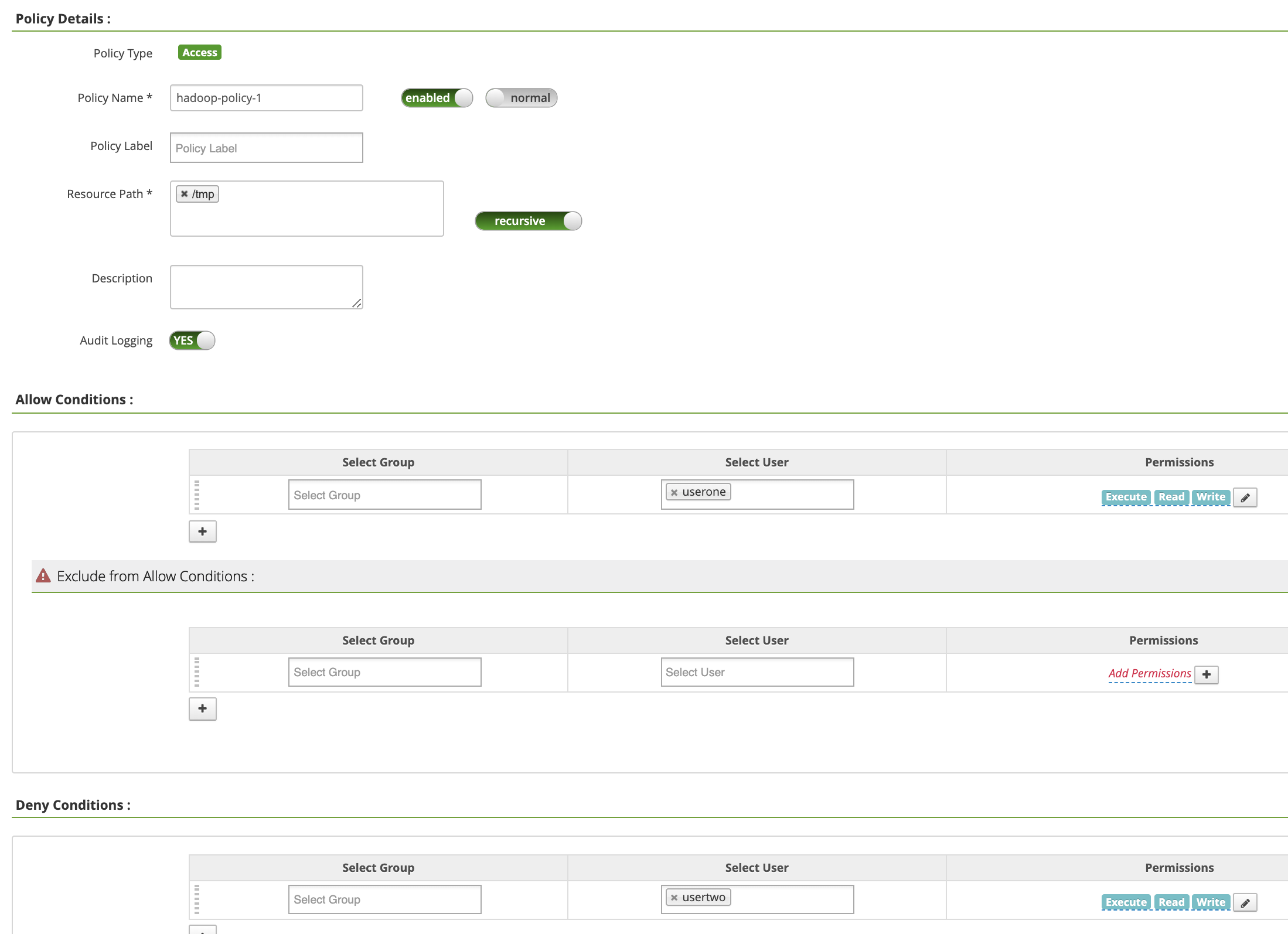
[Add] をクリックしてポリシーを保存します。このポリシーは、[hadoop-dataproc Policies] ページに表示されます。
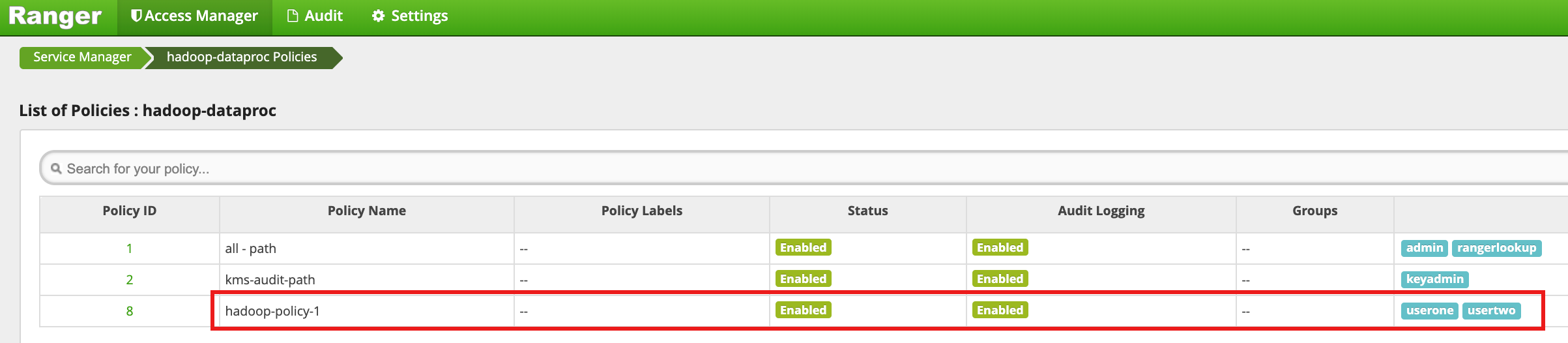
userone として HDFS
/tmpディレクトリにアクセスします。userone@example-cluster-m:~$ hadoop fs -ls /tmp
- Ranger UI に、
useroneによる HDFS /tmp ディレクトリへのアクセスが許可されたことが示されます。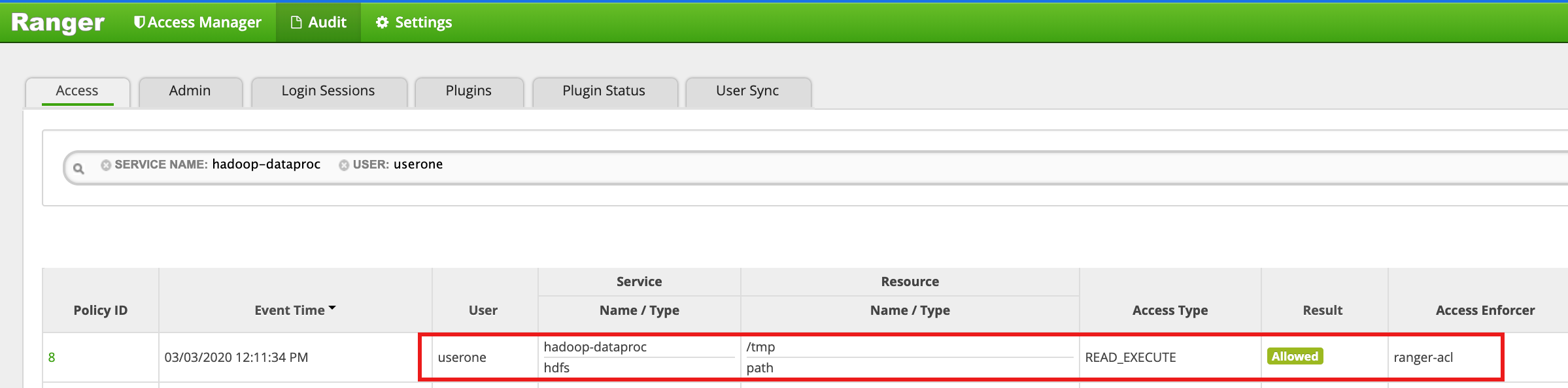
- Ranger UI に、
HDFS
/tmpディレクトリにusertwoとしてアクセスします。usertwo@example-cluster-m:~$ hadoop fs -ls /tmp
- Ranger UI に、
usertwoによる HDFS /tmp ディレクトリへのアクセスが拒否されたことが示されます。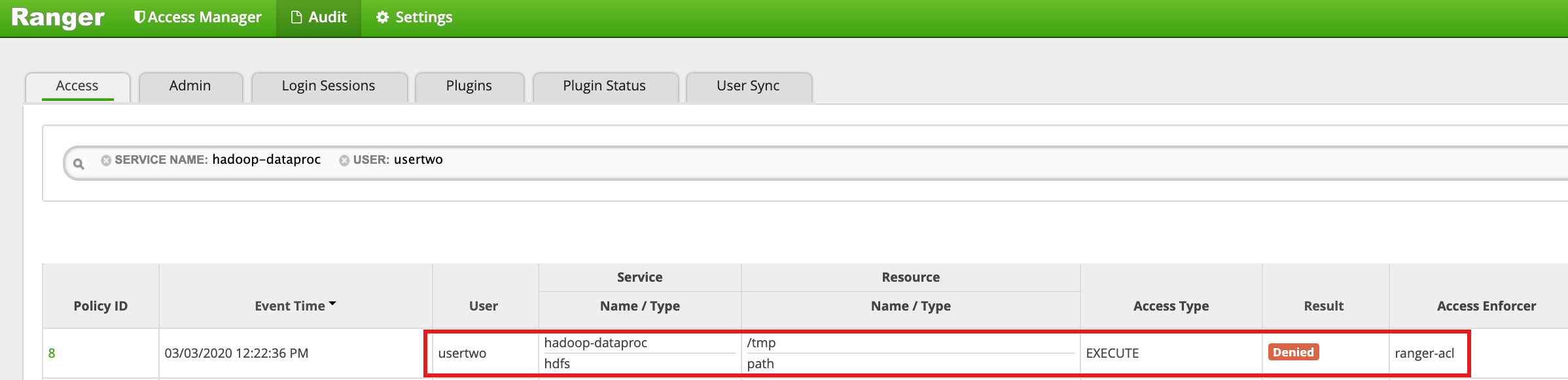
- Ranger UI に、
Hive のアクセス ポリシー
この例では、Hive テーブルへのユーザー アクセスを許可または拒否する Ranger ポリシーを作成します。
マスター インスタンスの hive CLI を使用して、小さな
employeeテーブルを作成します。hive> CREATE TABLE IF NOT EXISTS employee (eid int, name String); INSERT INTO employee VALUES (1 , 'bob') , (2 , 'alice'), (3 , 'john');
Ranger 管理 UI から
hive-dataprocを選択します。
[hive-dataproc Policies] ページで、[Add New Policy] をクリックします。[Create Policy] ページで、次のフィールドに値を入力または選択します。
Policy Name: hive-policy-1database: defaulttable: employeeHive Column: *Audit Logging: YesAllow Conditions:Select User: useronePermissions: すべての権限を付与するには [Select All]
Deny Conditions:Select User: usertwoPermissions: すべての権限を拒否する場合は [Select All]
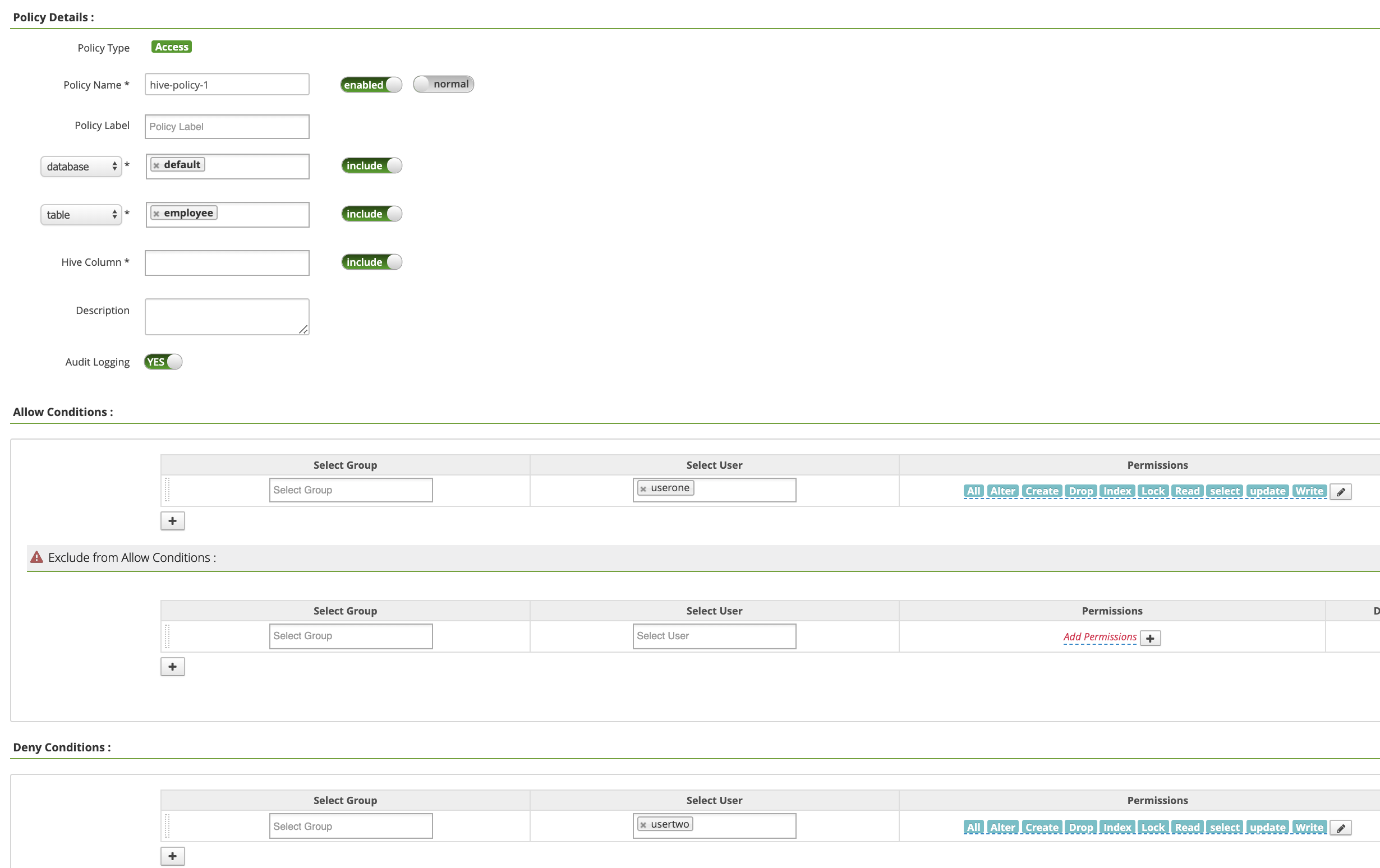
[Add] をクリックしてポリシーを保存します。このポリシーは、[hive-dataproc Policies] ページに表示されます。
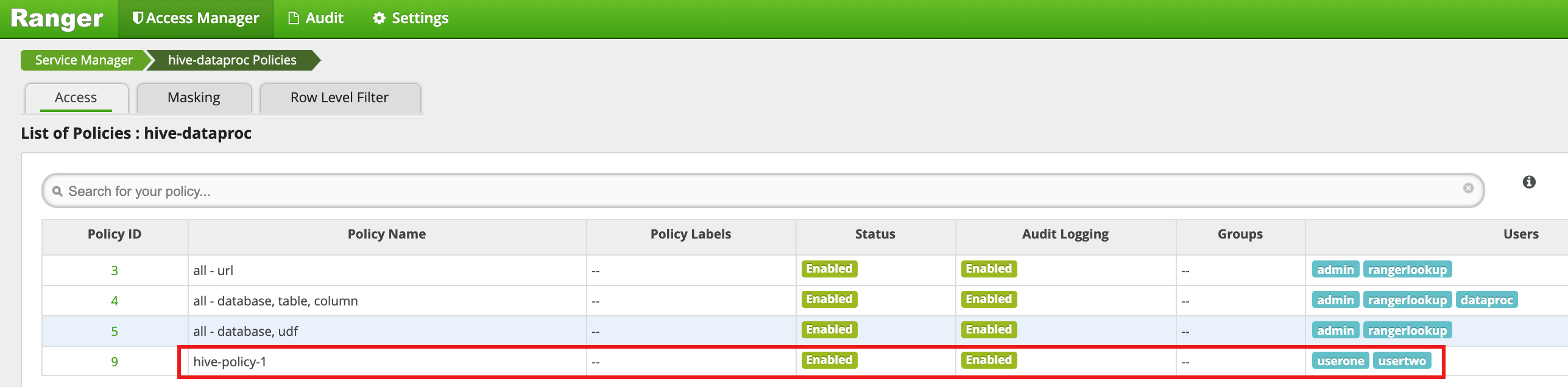
userone として、VM マスター SSH セッションから Hive の従業員テーブルに対してクエリを実行します。
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- userone クエリは、次のように成功します。
Connected to: Apache Hive (version 2.3.6) Driver: Hive JDBC (version 2.3.6) Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 1 | bob | | 2 | alice | | 3 | john | +---------------+----------------+ 3 rows selected (2.033 seconds)
- userone クエリは、次のように成功します。
usertwo として、VM マスター SSH セッションから Hive の従業員テーブルに対してクエリを実行します。
usertwo@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- usertwo はテーブルへのアクセスを拒否されます。
Error: Could not open client transport with JDBC Uri: ... Permission denied: user=usertwo, access=EXECUTE, inode="/tmp/hive"
- usertwo はテーブルへのアクセスを拒否されます。
きめ細かい Hive アクセス
Ranger は、Hive のマスキングと行レベルのフィルタをサポートしています。この例では、マスクポリシーとフィルタ ポリシーを追加して、前述の hive-policy-1 の上にビルドしています。
Ranger の管理 UI から [
hive-dataproc] を選択し、[Masking] タブを選択して [Add New Policy] をクリックします。
[Create Policy] ページで、次のフィールドに値を入力または選択して、従業員名の列をマスクする(無効にする)ポリシーを作成します。
Policy Name: hive-masking policydatabase: defaulttable: employeeHive Column: nameAudit Logging: YesMask Conditions:Select User: useroneAccess Types: select(権限の追加 / 編集)Select Masking Option: nullify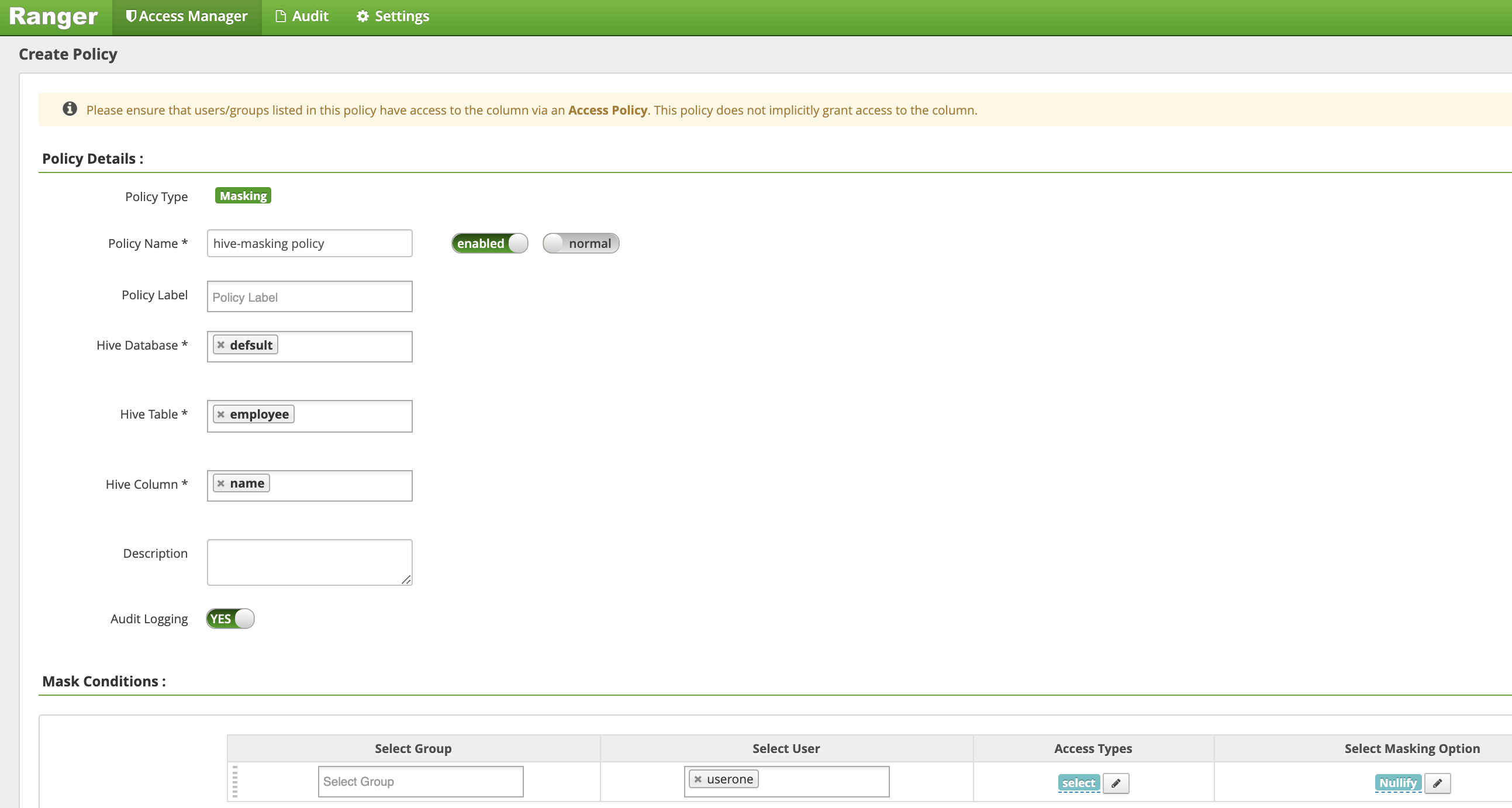
[Add] をクリックしてポリシーを保存します。
Ranger の管理 UI から
hive-dataprocを選択し、[Row Level Filter] タブを選択して [Add New Policy] をクリックします。
[Create Policy] ページで、次のフィールドに値を入力または選択して、
eidが1ではない行をフィルタリング(返す)ポリシーを作成します。Policy Name: hive-filter policyHive Database: defaultHive Table: employeeAudit Logging: YesMask Conditions:Select User: useroneAccess Types: select(権限の追加 / 編集)Row Level Filter: eid != 1(フィルタ式)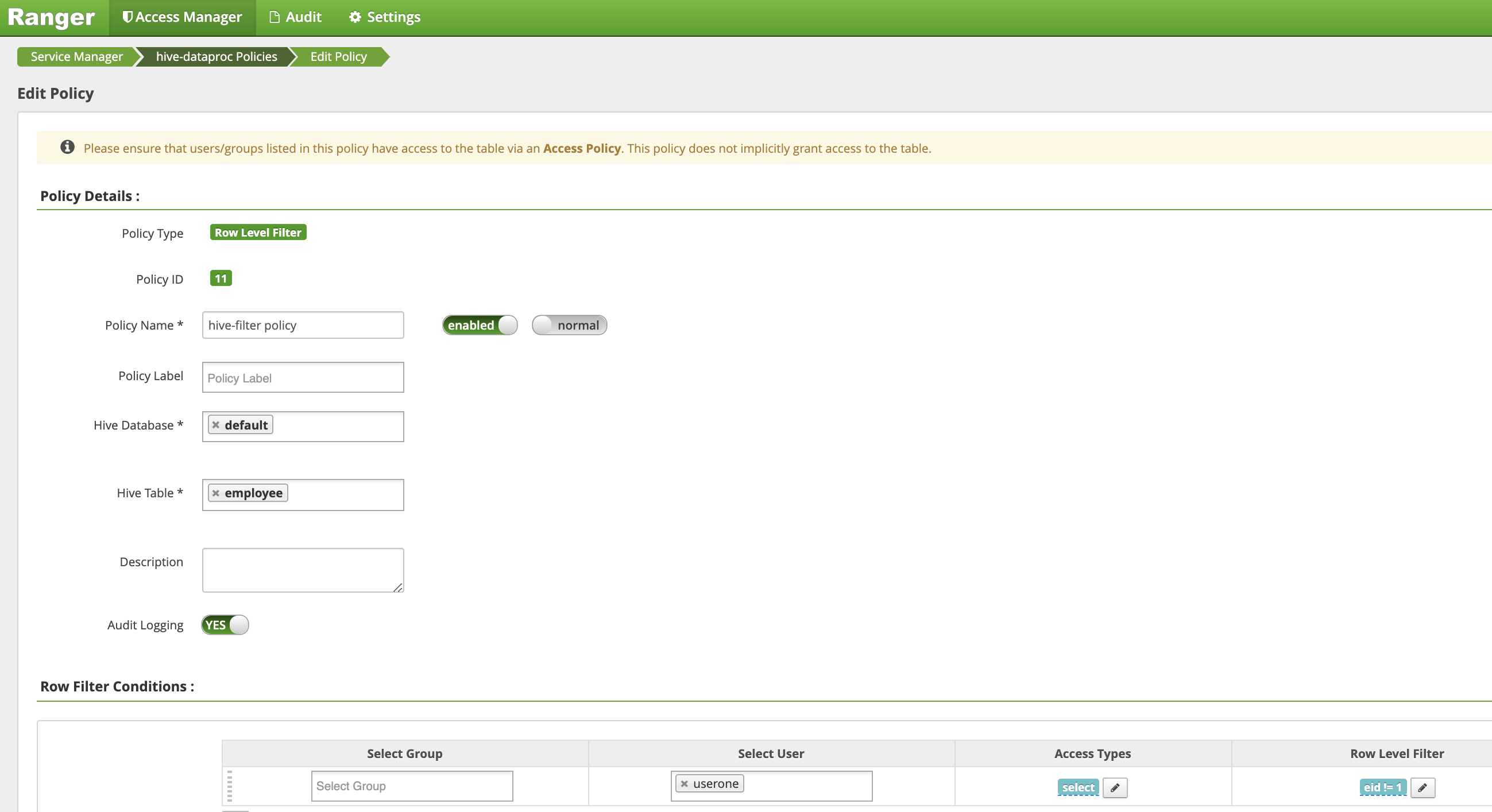
[Add] をクリックしてポリシーを保存します。
userone として、VM マスター SSH セッションから Hive 従業員テーブルに対して前のクエリを繰り返します。
userone@example-cluster-m:~$ beeline -u "jdbc:hive2://$(hostname -f):10000/default;principal=hive/$(hostname -f)@REALM" -e "select * from employee;"
- クエリは、名前列をマスクして返し、bob(eid=1)を結果から除外します。
Transaction isolation: TRANSACTION_REPEATABLE_READ +---------------+----------------+ | employee.eid | employee.name | +---------------+----------------+ | 2 | NULL | | 3 | NULL | +---------------+----------------+ 2 rows selected (0.47 seconds)
- クエリは、名前列をマスクして返し、bob(eid=1)を結果から除外します。