Dataflow
Inteligência de dados em tempo real
Maximize o potencial dos seus dados em tempo real. O Dataflow é uma plataforma de streaming totalmente gerenciada, fácil de usar e escalonável para acelerar a tomada de decisões em tempo real e as experiências do cliente.
Novos clientes recebem US$ 300 em créditos para gastar no Dataflow.

Recursos
Use IA e ML de streaming para potencializar modelos de IA generativa em tempo real
Os dados em tempo real capacitam modelos de IA/ML com as informações mais recentes, melhorando a precisão das previsões. O Dataflow ML simplifica a implantação e o gerenciamento de pipelines completos de ML. Oferecemos padrões prontos para uso para recomendações personalizadas, detecção de fraudes, prevenção de ameaças e muito mais. Crie IA de streaming com a Vertex AI, modelos Gemini e modelos Gemma, execute inferência remota e simplifique o processamento de dados com o MLTransform. Melhore a eficiência dos jobs de MLOps e ML com a GPU do Dataflow e os recursos de ajuste correto.
Ative casos de uso avançados de streaming em escala empresarial
O Dataflow é um serviço totalmente gerenciado que usa o SDK do Apache Beam de código aberto para possibilitar casos de uso avançados de streaming em escala empresarial. Ele oferece recursos avançados de estado e hora, transformações e conectores de E/S. O Dataflow escalona até 4 mil workers por job e processa rotineiramente petabytes de dados. Ele conta com escalonamento automático para otimizar a utilização de recursos em pipelines de lote e streaming.

Implantar o processamento de dados multimodal para IA generativa
O Dataflow permite a ingestão e a transformação paralelas de dados multimodais, como imagens, texto e áudio. Ela aplica a extração de atributos especializados para cada modalidade e, em seguida, combina esses atributos em uma representação unificada. Isso fundiu os feeds de dados em modelos de IA generativa, capacitando-os a criar novos conteúdos a partir das diversas entradas. As equipes internas do Google usam o Dataflow e o FlumeJava para organizar e calcular previsões de modelos para um grande pool de dados de entrada disponíveis sem requisitos de latência.
Acelere o retorno do investimento com modelos e notebooks
O Dataflow tem ferramentas que facilitam os primeiros passos. Os modelos do Dataflow são blueprints predefinidos para processamento de stream e em lote e são otimizados para uma integração eficiente de dados do CDC e do BigQuery. Crie pipelines de maneira iterativa com os frameworks de ciência de dados mais recentes do zero com os notebooks da Vertex AI e implante com o executor do Dataflow.O criador de jobs é uma IU visual para criar e executar pipelines do Dataflow no console do Google Cloud, sem escrever códigos.
Economize tempo com ferramentas inteligentes de diagnóstico e monitoramento
O Dataflow oferece ferramentas abrangentes de diagnóstico e monitoramento. A detecção de dinamização identifica automaticamente os gargalos de desempenho, enquanto a amostragem de dados permite observar os dados em cada etapa do pipeline. Os insights do Dataflow oferecem recomendações para melhorias nos jobs. A interface do Dataflow tem ferramentas de monitoramento avançadas, incluindo gráficos de jobs, detalhes de execução, métricas, painéis de escalonamento automático e geração de registros. O Dataflow também tem uma interface de monitoramento de custos do job para facilitar a estimativa de custos.
Governança e segurança integradas
O Dataflow ajuda a proteger seus dados de várias maneiras: criptografando dados em uso com suporte confidencial de VM, com chaves de criptografia gerenciadas pelo cliente (CMEK), integração do VPC Service Controls e e desativando os IPs públicos. O registro de auditoria do Dataflow oferece à sua organização a visibilidade do uso do Dataflow e ajuda a responder à pergunta "Quem fez o quê, onde e quando?" para uma melhor governança.
Como funciona
O Dataflow é uma plataforma totalmente gerenciada para processamento de dados em lote e streaming. Ele permite pipelines ETL escalonáveis, análises de stream em tempo real, ML em tempo real e transformações de dados complexas usando o modelo unificado do Apache Beam, tudo na infraestrutura sem servidor do Google Cloud.
O Dataflow é uma plataforma totalmente gerenciada para processamento de dados em lote e streaming. Ele permite pipelines ETL escalonáveis, análises de stream em tempo real, ML em tempo real e transformações de dados complexas usando o modelo unificado do Apache Beam, tudo na infraestrutura sem servidor do Google Cloud.

Usos comuns
Análise em tempo real
Use dados de streaming para análises em tempo real e pipelines operacionais
Use dados de streaming para análises em tempo real e pipelines operacionais
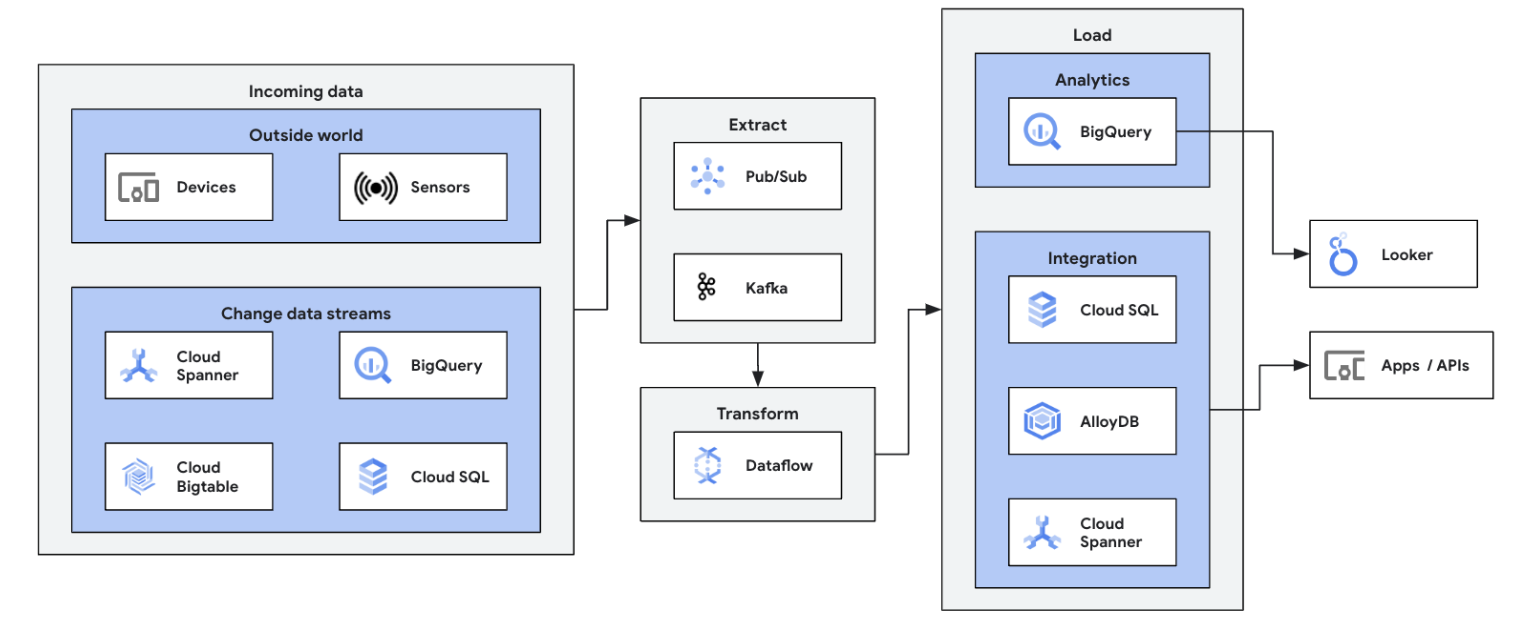
Comece sua jornada de streaming de dados integrando suas fontes de dados de streaming (Pub/Sub, Kafka, eventos de CDC, fluxo de cliques do usuário, registros e dados do sensor) no BigQuery, data lakes do Google Cloud Storage, Spanner, Bigtable, repositórios do SQL, Splunk, Datadog e muito mais. Conheça os modelos otimizados do Dataflow para configurar seus pipelines com apenas alguns cliques, sem código. Adicione lógica personalizada aos jobs de modelo com o builder UDF integrado ou crie pipelines ETL personalizados do zero usando toda a capacidade do ecossistema de transformações em Beam e conectores de E/S. O Dataflow também é usado com frequência para reverter dados processados de ETL do BigQuery para armazenamentos OLTP para pesquisas rápidas e atendimento aos usuários finais. É um padrão comum do Dataflow gravar dados de streaming em vários locais de armazenamento.

Inicie seu primeiro job do Dataflow e faça nosso curso autoguiado sobre Fundamentos do Dataflow.
Tutoriais, guias de início rápido e laboratórios
Use dados de streaming para análises em tempo real e pipelines operacionais
Use dados de streaming para análises em tempo real e pipelines operacionais
Comece sua jornada de streaming de dados integrando suas fontes de dados de streaming (Pub/Sub, Kafka, eventos de CDC, fluxo de cliques do usuário, registros e dados do sensor) no BigQuery, data lakes do Google Cloud Storage, Spanner, Bigtable, repositórios do SQL, Splunk, Datadog e muito mais. Conheça os modelos otimizados do Dataflow para configurar seus pipelines com apenas alguns cliques, sem código. Adicione lógica personalizada aos jobs de modelo com o builder UDF integrado ou crie pipelines ETL personalizados do zero usando toda a capacidade do ecossistema de transformações em Beam e conectores de E/S. O Dataflow também é usado com frequência para reverter dados processados de ETL do BigQuery para armazenamentos OLTP para pesquisas rápidas e atendimento aos usuários finais. É um padrão comum do Dataflow gravar dados de streaming em vários locais de armazenamento.
Inicie seu primeiro job do Dataflow e faça nosso curso autoguiado sobre Fundamentos do Dataflow.
ETL em tempo real e integração de dados
Modernize sua plataforma de dados com dados em tempo real
Modernize sua plataforma de dados com dados em tempo real
ETL e integração em tempo real processam e gravam dados imediatamente, permitindo análises e tomadas de decisões rápidas. A arquitetura sem servidor e os recursos de streaming do Dataflow o tornam ideal para criar pipelines de ETL em tempo real. A capacidade de escalonamento automático do Dataflow garante eficiência e escalonamento. Já o suporte a várias origens e destinos de dados simplifica a integração.
Desenvolva os conceitos básicos com o processamento em lote no Dataflow com este curso do Google Cloud Ensina.
Tutoriais, guias de início rápido e laboratórios
Modernize sua plataforma de dados com dados em tempo real
Modernize sua plataforma de dados com dados em tempo real
ETL e integração em tempo real processam e gravam dados imediatamente, permitindo análises e tomadas de decisões rápidas. A arquitetura sem servidor e os recursos de streaming do Dataflow o tornam ideal para criar pipelines de ETL em tempo real. A capacidade de escalonamento automático do Dataflow garante eficiência e escalonamento. Já o suporte a várias origens e destinos de dados simplifica a integração.
Desenvolva os conceitos básicos com o processamento em lote no Dataflow com este curso do Google Cloud Ensina.
ML em tempo real e IA generativa
Aja em tempo real com streaming de ML / IA
Aja em tempo real com streaming de ML / IA
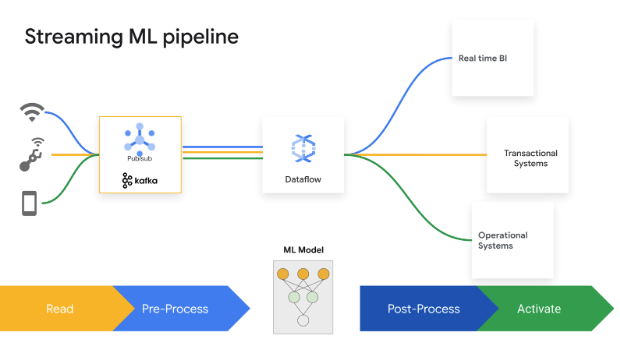
Decisões de divisão de segundos geram valor comercial. O Dataflow Streaming AI e ML permite que os clientes implementem previsões e inferências de baixa latência, personalização em tempo real, detecção de ameaças, prevenção de fraudes e muitos outros casos de uso em que a inteligência em tempo real é importante. Pré-processar dados com o MLTransform, que permite se concentrar na transformação dos dados, sem escrever códigos complexos ou gerenciar bibliotecas. Faça previsões para o modelo de IA generativa usando o RunInference.
Tutoriais, guias de início rápido e laboratórios
Aja em tempo real com streaming de ML / IA
Aja em tempo real com streaming de ML / IA
Decisões de divisão de segundos geram valor comercial. O Dataflow Streaming AI e ML permite que os clientes implementem previsões e inferências de baixa latência, personalização em tempo real, detecção de ameaças, prevenção de fraudes e muitos outros casos de uso em que a inteligência em tempo real é importante. Pré-processar dados com o MLTransform, que permite se concentrar na transformação dos dados, sem escrever códigos complexos ou gerenciar bibliotecas. Faça previsões para o modelo de IA generativa usando o RunInference.
Marketing Intelligence
Transforme seu marketing com insights em tempo real
Transforme seu marketing com insights em tempo real
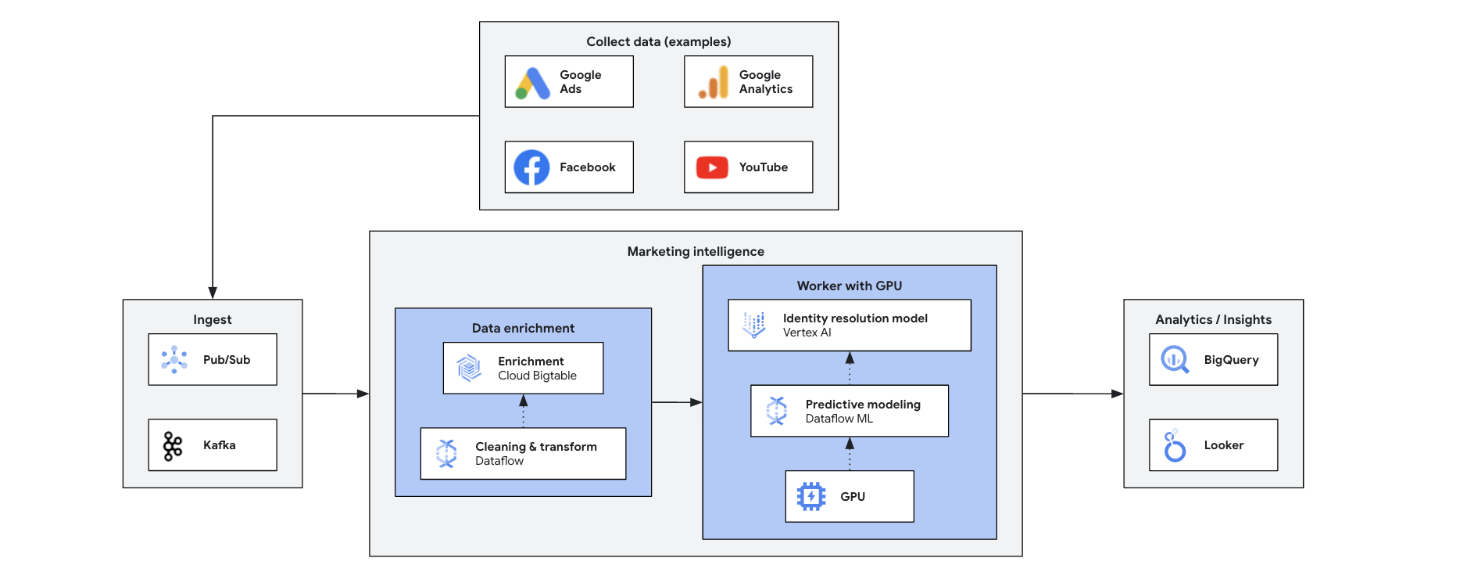
O Marketing Intelligence em tempo real analisa dados atuais de mercado, clientes e concorrentes para tomar decisões rápidas e bem informadas. Ele permite respostas ágeis a tendências, comportamentos e ações competitivas, transformando o marketing. Alguns dos benefícios são:
- Marketing omnichannel em tempo real com ofertas personalizadas
- Melhoria na gestão do relacionamento com o cliente por meio de interações personalizadas
- Otimização do mix de marketing ágil
- Segmentação dinâmica de usuários
- Inteligência competitiva para se manter à frente
- Gerenciamento proativo de crises em mídias sociais
Tutoriais, guias de início rápido e laboratórios
Transforme seu marketing com insights em tempo real
Transforme seu marketing com insights em tempo real
O Marketing Intelligence em tempo real analisa dados atuais de mercado, clientes e concorrentes para tomar decisões rápidas e bem informadas. Ele permite respostas ágeis a tendências, comportamentos e ações competitivas, transformando o marketing. Alguns dos benefícios são:
- Marketing omnichannel em tempo real com ofertas personalizadas
- Melhoria na gestão do relacionamento com o cliente por meio de interações personalizadas
- Otimização do mix de marketing ágil
- Segmentação dinâmica de usuários
- Inteligência competitiva para se manter à frente
- Gerenciamento proativo de crises em mídias sociais
Análise cliquestream
Otimize e personalize experiências na Web e em apps
Otimize e personalize experiências na Web e em apps
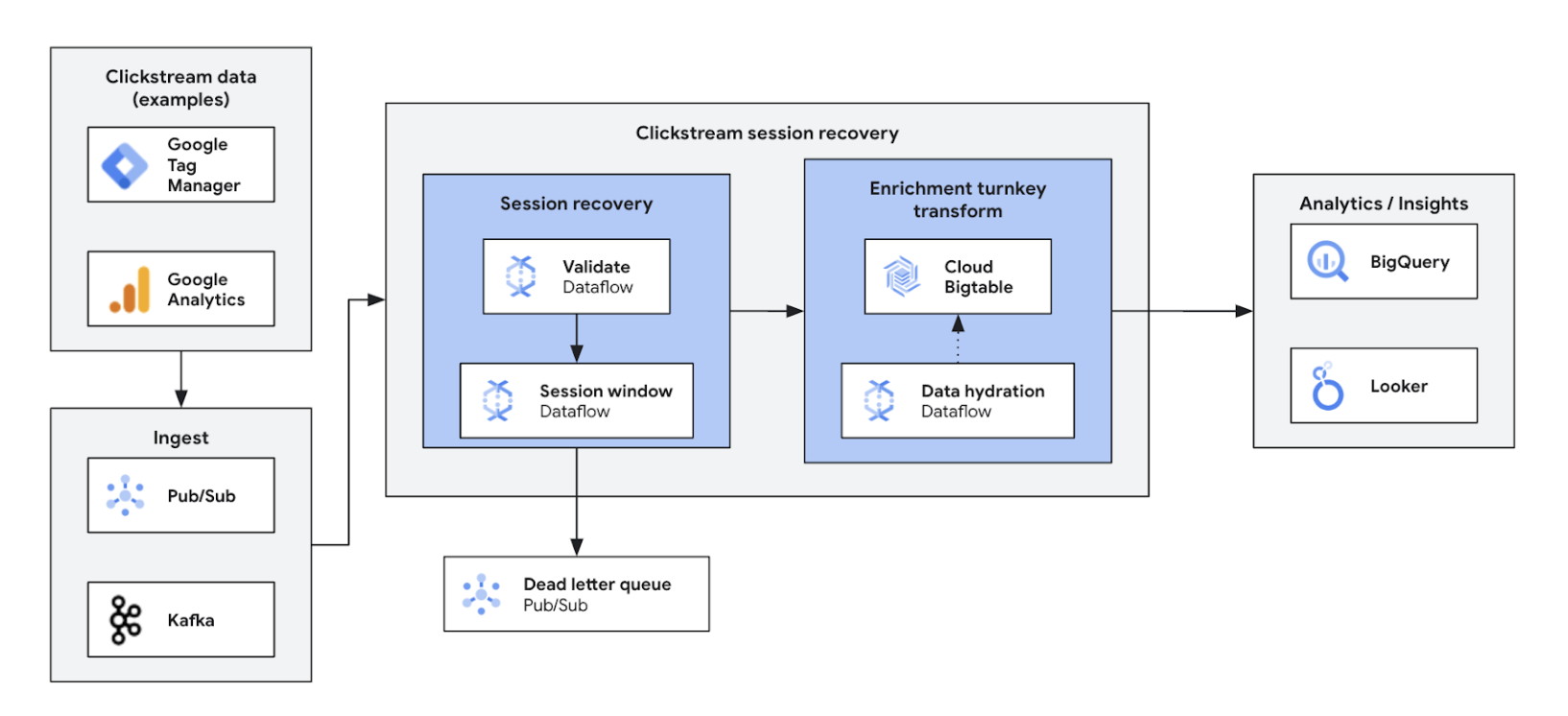
Com a análise da sequência de cliques em tempo real, as empresas podem analisar instantaneamente as interações dos usuários em sites e aplicativos. Isso permite personalização em tempo real, testes A/B e otimização de funil, o que aumenta o engajamento, acelera o desenvolvimento de produtos, reduz o desligamento de usuários e aprimora o suporte aos produtos. Por fim, ele oferece uma experiência de usuário superior e impulsiona o crescimento dos negócios com preços dinâmicos e recomendações personalizadas.
Tutoriais, guias de início rápido e laboratórios
Otimize e personalize experiências na Web e em apps
Otimize e personalize experiências na Web e em apps
Com a análise da sequência de cliques em tempo real, as empresas podem analisar instantaneamente as interações dos usuários em sites e aplicativos. Isso permite personalização em tempo real, testes A/B e otimização de funil, o que aumenta o engajamento, acelera o desenvolvimento de produtos, reduz o desligamento de usuários e aprimora o suporte aos produtos. Por fim, ele oferece uma experiência de usuário superior e impulsiona o crescimento dos negócios com preços dinâmicos e recomendações personalizadas.
Análise e replicação de registros em tempo real
Gerenciamento e análise de registros centralizados
Gerenciamento e análise de registros centralizados
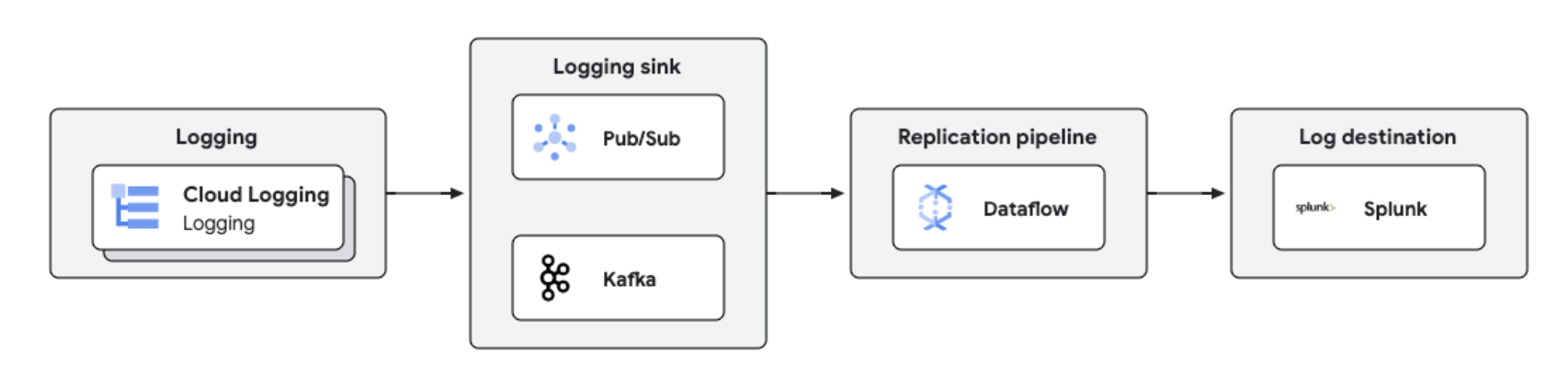
Os registros do Google Cloud podem ser replicados para plataformas de terceiros, como o Splunk, usando o Dataflow para processamento e análise de registros quase em tempo real. Essa solução oferece gerenciamento centralizado de registros, conformidade, auditoria e recursos de análise, além de reduzir custos e melhorar o desempenho.
Tutoriais, guias de início rápido e laboratórios
Gerenciamento e análise de registros centralizados
Gerenciamento e análise de registros centralizados
Os registros do Google Cloud podem ser replicados para plataformas de terceiros, como o Splunk, usando o Dataflow para processamento e análise de registros quase em tempo real. Essa solução oferece gerenciamento centralizado de registros, conformidade, auditoria e recursos de análise, além de reduzir custos e melhorar o desempenho.
Preços
| Como funcionam os preços do Dataflow | Conhecer o modelo de faturamento e de recursos do Dataflow. | |
|---|---|---|
| Serviços e uso | Descrição | Preços |
Recursos de computação do Dataflow | O faturamento do Dataflow para recursos de computação inclui: | Saiba mais na nossa página de preços detalhada |
Outros recursos do Dataflow | Outros recursos do Dataflow faturados para todos os jobs incluem disco permanente, GPUs e snapshots. | Saiba mais na nossa página de preços detalhada |
Descontos por compromisso de uso (CUDs) do Dataflow | Os CUDs do Dataflow oferecem dois níveis de descontos, dependendo do período de compromisso:
| Saiba mais sobre os CUDs do Dataflow. |
Saiba mais sobre preços do Dataflow. Confira todos os detalhes de preços.
Como funcionam os preços do Dataflow
Conhecer o modelo de faturamento e de recursos do Dataflow.
Recursos de computação do Dataflow
O faturamento do Dataflow para recursos de computação inclui:
Saiba mais na nossa página de preços detalhada
Outros recursos do Dataflow
Outros recursos do Dataflow faturados para todos os jobs incluem disco permanente, GPUs e snapshots.
Saiba mais na nossa página de preços detalhada
Descontos por compromisso de uso (CUDs) do Dataflow
Os CUDs do Dataflow oferecem dois níveis de descontos, dependendo do período de compromisso:
- Um CUD de um ano oferece 20% de desconto na taxa sob demanda
- Um CUD de três anos oferece um desconto de 40% sobre a taxa sob demanda
Saiba mais sobre os CUDs do Dataflow.
Saiba mais sobre preços do Dataflow. Confira todos os detalhes de preços.
Calculadora de preços
Cota personalizada
Comece sua prova de conceito
Clientes novos ganham US $300 para testar o Dataflow
Tem um projeto grande?
Como usar o Dataflow
Modelos pré-criados do Dataflow
Procurar exemplos de código do Dataflow
Caso de negócios
Veja por que os principais clientes escolhem o Dataflow
Namitha Vijaya Kumar, proprietária do produto, SRE do Google Cloud no ANZ Bank
"O Dataflow ajuda no processamento de dados em lote e em tempo real, garantindo assim a pontualidade dos dados no data lake corporativo. Isso, por sua vez, ajuda no uso downstream de dados para análise/tomada de decisão e envio de notificações em tempo real para nossos clientes de varejo."
Leia a Forrester WaveConteúdo relacionado
O Google foi reconhecido por colegas como Escolha do cliente para o processamento de stream de eventos
Acesse o relatório
Como o Spotify usa o ML para melhorar o streaming de dados
Assista ao vídeo
O Yahoo compara o Dataflow com o Apache Flink autogerenciado em dois casos de uso de streaming
Leia a postagem do blog
Benefícios do Dataflow
ML de streaming facilitada
Recursos prontos para levar streaming à IA/ML: RunInference para inferência, MLTransform para pré-processamento de treinamento de modelo, aprimoramento para pesquisas de Feature Store e suporte dinâmico a GPU trazem menos trabalho, sem desperdício com recursos limitados da GPU.
Custo-benefício ideal com ferramentas robustas
O Dataflow oferece streaming econômico com otimização automatizada para máximo desempenho e uso de recursos. Ele escalona sem esforço para lidar com qualquer carga de trabalho e tem autocorreção com tecnologia de IA. Ferramentas robustas ajudam nas operações e no entendimento.
Aberto, portátil e extensível
O Dataflow foi criado para o Apache Beam de código aberto, com suporte unificado para lote e streaming, o que torna as cargas de trabalho portáteis entre nuvens, locais ou dispositivos de borda.
Parceiros e integração




Parceiros do Dataflow
Os parceiros do Google Cloud desenvolveram integrações com o Dataflow para viabilizar de maneira rápida e fácil tarefas avançadas de processamento de dados de qualquer tamanho. Confira todos os parceiros para começar sua jornada de streaming hoje mesmo.











