Dataflow
Real-time data intelligence
Maximize the potential of your real-time data. Dataflow is a fully managed streaming platform that is easy-to-use and scalable to help accelerate real-time decision making and customer experiences.
New customers get $300 in free credits to spend on Dataflow.

Features
Use streaming AI and ML to power gen AI models in real time
Real-time data empowers AI/ML models with the latest information, enhancing prediction accuracy. Dataflow ML simplifies deployment and management of complete ML pipelines. We offer ready-to-use patterns for personalized recommendations, fraud detection, threat prevention, and more. Build streaming AI with Gemini Enterprise Agent Platform, Gemini models, and Gemma models, run remote inference, and streamline data processing with MLTransform. Enhance MLOps and ML job efficiency with Dataflow GPU and right-fitting capabilities.
Enable advanced streaming use cases at enterprise scale
Dataflow is a fully managed service that uses open source Apache Beam SDK to enable advanced streaming use cases at enterprise scale. It offers rich capabilities for state and time, transformations, and I/O connectors. Dataflow scales to 4K workers per job and routinely processes petabytes of data. It features autoscaling for optimal resource utilization in both batch and streaming pipelines.

Deploy multimodal data processing for gen AI
Dataflow enables parallel ingestion and transformation of multimodal data like images, text, and audio. It applies specialized feature extraction for each modality, then fuses these features into a unified representation. This fused data feeds into generative AI models, empowering them to create new content from the diverse inputs. Internal Google teams leverage Dataflow and FlumeJava to organize and compute model predictions for a large pool of available input data with no latency requirements.
Accelerate time to value with templates and notebooks
Dataflow has tools that make it easy to get started. Dataflow templates are pre-designed blueprints for stream and batch processing and are optimized for efficient CDC and BigQuery data integration. Iteratively build pipelines with the latest data science frameworks from the ground up with Gemini Enterprise Agent Platform Notebooks and deploy with the Dataflow runner. Dataflow job builder is a visual UI for building and running Dataflow pipelines in the Google Cloud console, without writing code.
Save time with smart diagnostics and monitoring tools
Dataflow offers comprehensive diagnostics and monitoring tools. Straggler detection automatically identifies performance bottlenecks, while data sampling allows observing data at each pipeline step. Dataflow Insights offer recommendations for job improvements. The Dataflow UI provides rich monitoring tools, including job graphs, execution details, metrics, autoscaling dashboards, and logging. Dataflow also features a job cost monitoring UI for easy cost estimation.
Built-in governance and security
Dataflow helps you protect your data in a number of ways: encrypting data in use with confidential VM support; customer managed encryption keys (CMEK); VPC Service Controls integration; turning off public IPs. Dataflow audit logging gives your organization the visibility into Dataflow usage and helps answer the question “Who did what, where, and when?" for better governance.
How It Works
Dataflow is a fully managed platform for batch and streaming data processing. It enables scalable ETL pipelines, real-time stream analytics, real-time ML, and complex data transformations using Apache Beam's unified model, all on serverless Google Cloud infrastructure.
Dataflow is a fully managed platform for batch and streaming data processing. It enables scalable ETL pipelines, real-time stream analytics, real-time ML, and complex data transformations using Apache Beam's unified model, all on serverless Google Cloud infrastructure.

Real-time analytics
Bring in streaming data for real-time analytics and operational pipelines
Bring in streaming data for real-time analytics and operational pipelines
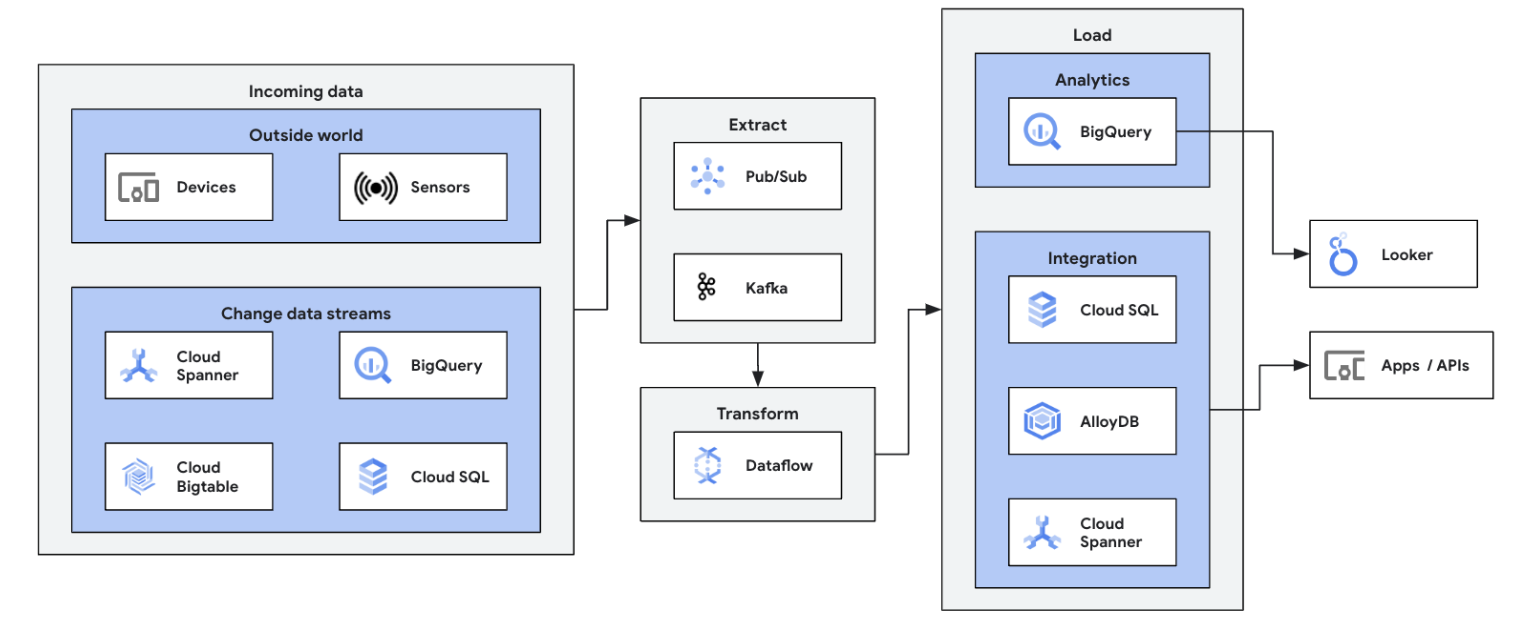
Start your data streaming journey by integrating your streaming data sources (Pub/Sub, Kafka, CDC events, user clickstream, logs, and sensor data) into BigQuery, Google Cloud Storage data lakes, Spanner, Bigtable, SQL stores, Splunk, Datadog, and more. Explore optimized Dataflow templates to set up your pipelines in a few clicks, no code. Add custom logic to your template jobs with integrated UDF builder or create custom ETL pipelines from scratch using the full power of Beam transforms and I/O connectors ecosystem. Dataflow is also commonly used to reverse ETL processed data from BigQuery to OLTP stores for fast lookups and serving end users. It is a common pattern for Dataflow to write streaming data to multiple storage locations.

Launch your first Dataflow job and take our self-guided course on Dataflow foundations.
Tutorials, quickstarts, & labs
Bring in streaming data for real-time analytics and operational pipelines
Bring in streaming data for real-time analytics and operational pipelines
Start your data streaming journey by integrating your streaming data sources (Pub/Sub, Kafka, CDC events, user clickstream, logs, and sensor data) into BigQuery, Google Cloud Storage data lakes, Spanner, Bigtable, SQL stores, Splunk, Datadog, and more. Explore optimized Dataflow templates to set up your pipelines in a few clicks, no code. Add custom logic to your template jobs with integrated UDF builder or create custom ETL pipelines from scratch using the full power of Beam transforms and I/O connectors ecosystem. Dataflow is also commonly used to reverse ETL processed data from BigQuery to OLTP stores for fast lookups and serving end users. It is a common pattern for Dataflow to write streaming data to multiple storage locations.
Launch your first Dataflow job and take our self-guided course on Dataflow foundations.
Real-time ETL and data integration
Modernize your data platform with real-time data
Modernize your data platform with real-time data
Real-time ETL and integration process and write data immediately, enabling rapid analysis and decision-making. Dataflow's serverless architecture and streaming capabilities make it ideal for building real-time ETL pipelines. Dataflow's ability to autoscale ensures efficiency and scale, while its support for various data sources and destinations simplifies integration.
Build your fundamentals with batch processing on Dataflow with this Google Cloud Skills Boost course.
Tutorials, quickstarts, & labs
Modernize your data platform with real-time data
Modernize your data platform with real-time data
Real-time ETL and integration process and write data immediately, enabling rapid analysis and decision-making. Dataflow's serverless architecture and streaming capabilities make it ideal for building real-time ETL pipelines. Dataflow's ability to autoscale ensures efficiency and scale, while its support for various data sources and destinations simplifies integration.
Build your fundamentals with batch processing on Dataflow with this Google Cloud Skills Boost course.
Real-time ML and gen AI
Act in real time with streaming ML / AI
Act in real time with streaming ML / AI
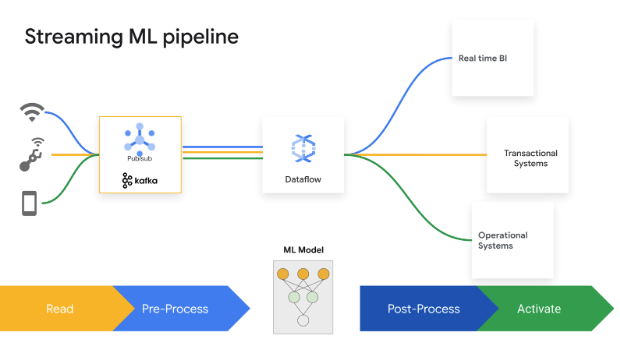
Split second decisions drive business value. Dataflow Streaming AI and ML enable customers to implement low latency predictions and inferences, real-time personalization, threat detection, fraud prevention, and many more use cases where real-time intelligence matters. Preprocess data with MLTransform, which allows you to focus on transforming your data and away from writing complex code or managing underlying libraries. Make predictions to your generative AI model using RunInference.
Tutorials, quickstarts, & labs
Act in real time with streaming ML / AI
Act in real time with streaming ML / AI
Split second decisions drive business value. Dataflow Streaming AI and ML enable customers to implement low latency predictions and inferences, real-time personalization, threat detection, fraud prevention, and many more use cases where real-time intelligence matters. Preprocess data with MLTransform, which allows you to focus on transforming your data and away from writing complex code or managing underlying libraries. Make predictions to your generative AI model using RunInference.
Marketing intelligence
Transform your marketing with real-time insights
Transform your marketing with real-time insights
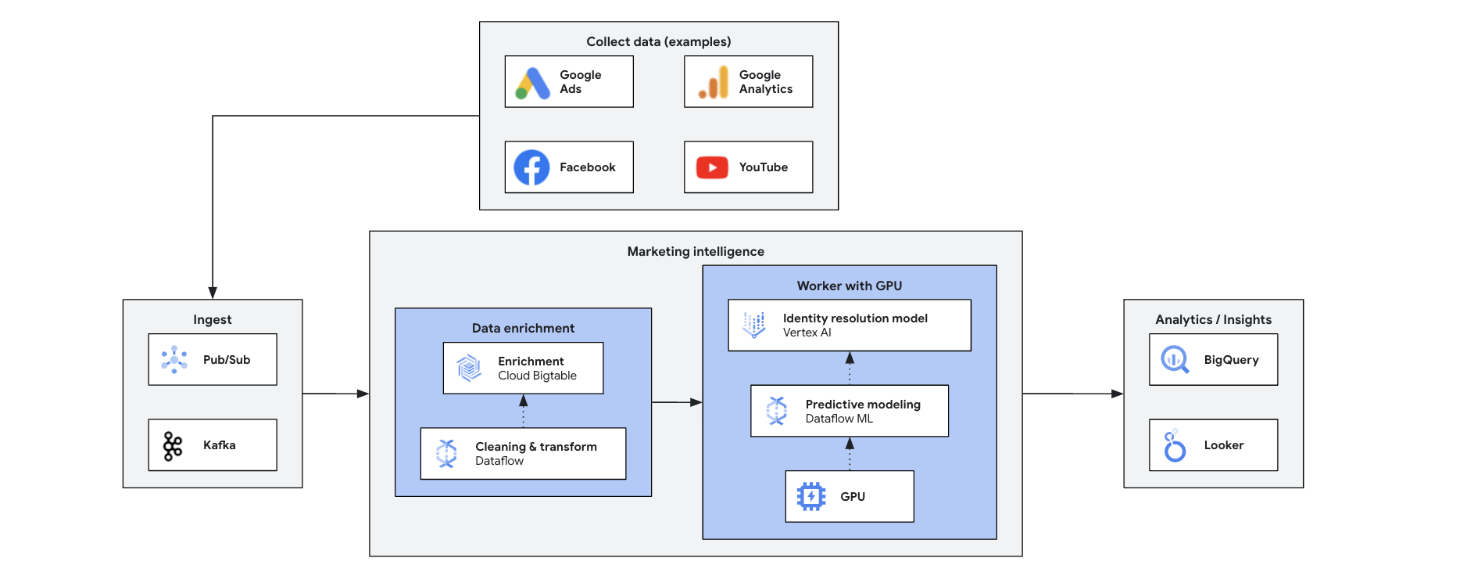
Real-time marketing intelligence analyzes current market, customer, and competitor data for quick, informed decisions. It enables agile responses to trends, behaviors, and competitive actions, transforming marketing. Benefits include:
- Real-time omnichannel marketing with personalized offers
- Improved customer relationship management through personalized interactions
- Agile marketing mix optimization
- Dynamic user segmentation
- Competitive intelligence for staying ahead
- Proactive crisis management on social media
Tutorials, quickstarts, & labs
Transform your marketing with real-time insights
Transform your marketing with real-time insights
Real-time marketing intelligence analyzes current market, customer, and competitor data for quick, informed decisions. It enables agile responses to trends, behaviors, and competitive actions, transforming marketing. Benefits include:
- Real-time omnichannel marketing with personalized offers
- Improved customer relationship management through personalized interactions
- Agile marketing mix optimization
- Dynamic user segmentation
- Competitive intelligence for staying ahead
- Proactive crisis management on social media
Clickstream analytics
Optimize and personalize web and app experiences
Optimize and personalize web and app experiences
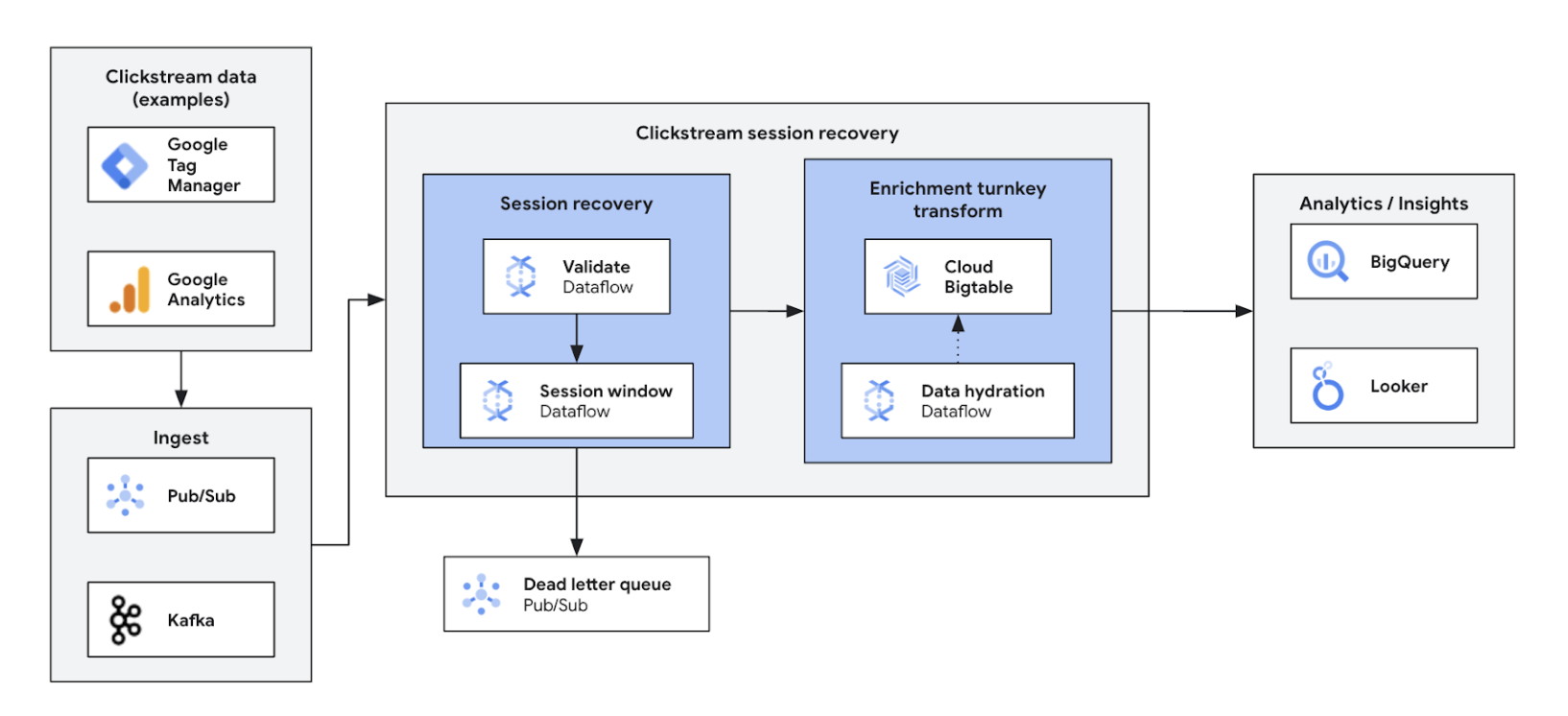
Real-time clickstream analytics empower businesses to analyze user interactions on websites and apps instantly. This unlocks real-time personalization, A/B testing, and funnel optimization, leading to increased engagement, faster product development, reduced churn, and enhanced product support. Ultimately, it enables a superior user experience and drives business growth through dynamic pricing and personalized recommendations.
Tutorials, quickstarts, & labs
Optimize and personalize web and app experiences
Optimize and personalize web and app experiences
Real-time clickstream analytics empower businesses to analyze user interactions on websites and apps instantly. This unlocks real-time personalization, A/B testing, and funnel optimization, leading to increased engagement, faster product development, reduced churn, and enhanced product support. Ultimately, it enables a superior user experience and drives business growth through dynamic pricing and personalized recommendations.
Real-time log replication and analytics
Centralized log management and analytics
Centralized log management and analytics
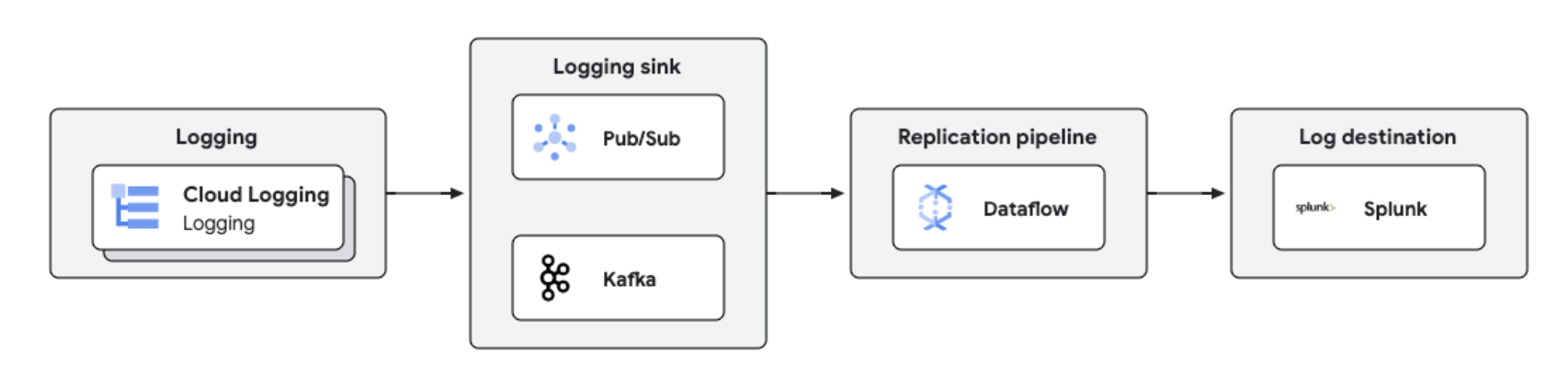
Google Cloud logs can be replicated to third-party platforms like Splunk using Dataflow for near real-time log processing and analytics. This solution provides centralized log management, compliance, auditing, and analytics capabilities while reducing cost and improving performance.
Tutorials, quickstarts, & labs
Centralized log management and analytics
Centralized log management and analytics
Google Cloud logs can be replicated to third-party platforms like Splunk using Dataflow for near real-time log processing and analytics. This solution provides centralized log management, compliance, auditing, and analytics capabilities while reducing cost and improving performance.
Pricing
| How Dataflow pricing works | Explore the billing and resource model for Dataflow. | |
|---|---|---|
| Services and usage | Description | Pricing |
Dataflow compute resources | Dataflow billing for compute resources includes: | Learn more on our detailed pricing page |
Other Dataflow resources | Learn more on our detailed pricing page | |
Dataflow committed use discounts (CUDs) | Dataflow CUDs offer two levels of discounts, depending on the commitment period:
| Learn more about Dataflow CUDs |
Learn more about Dataflow pricing. View all pricing details.
How Dataflow pricing works
Explore the billing and resource model for Dataflow.
Dataflow compute resources
Dataflow billing for compute resources includes:
Learn more on our detailed pricing page
Dataflow committed use discounts (CUDs)
Dataflow CUDs offer two levels of discounts, depending on the commitment period:
- A one-year CUD gives you a 20% discount from the on-demand rate
- A three-year CUD gives you a 40% discount from the on-demand rate
Learn more about Dataflow CUDs
Learn more about Dataflow pricing. View all pricing details.
Business Case
See why leading customers choose Dataflow
Namitha Vijaya Kumar, Product Owner, Google Cloud SRE at ANZ Bank
“Dataflow is helping both our batch process and real-time data processing, thereby ensuring timeliness of data is maintained in the enterprise data lake. This in turn helps downstream usage of data for analytics/decisioning and delivery of real-time notifications for our retail customers.”
Dataflow benefits
Streaming ML made easy
Turnkey capabilities to bring streaming to AI/ML: RunInference for inference, MLTransform for model training pre-processing, Enrichment for feature store lookups, and dynamic GPU support all bring reduced toil with no wasted spend for limited GPU resources.
Optimal price-performance with robust tooling
Dataflow offers cost-effective streaming with automated optimization for maximum performance and resource usage. It scales effortlessly to handle any workload and features AI-powered self-healing. Robust tooling helps with operations and understanding.
Open, portable, and extensible
Dataflow is built for open source Apache Beam with unified batch and streaming support, making your workloads portable between clouds, on-premises, or to edge devices.
Partners & Integration




Dataflow partners
Google Cloud partners have developed integrations with Dataflow to quickly and easily enable powerful data processing tasks of any size. See all partners to start your streaming journey today.


















