Dataflow
实时数据智能
充分发挥实时数据的潜力。Dataflow 是一个易于使用且可扩缩的全托管式流式处理平台,可帮助您加快实时决策制定速度并改善客户体验。
新客户可获得 $300 赠金,用于抵扣 Dataflow 的相关费用。

功能
使用流式 AI 和机器学习技术实时为生成式 AI 模型提供支持
实时数据可为 AI/机器学习模型提供最新信息,从而提高预测准确性。Dataflow 机器学习简化了完整机器学习流水线的部署和管理。我们提供现成可用的模式,可提供个性化推荐、欺诈检测、威胁防范等。您可以使用 Vertex AI、Gemini 模型和 Gemma 模型构建流式 AI,运行远程推理,并通过 MLTransform 简化数据处理。利用 Dataflow GPU 和合适功能来增强 MLOps 和机器学习作业效率。
实现企业级的高级流式传输用例
Dataflow 是一项全托管式服务,使用开源 Apache Beam SDK 实现企业级高级流式处理用例。它为状态和时间、转换以及 I/O 连接器提供了丰富的功能。Dataflow 可扩容至每项作业 4,000 个工作器,并定期处理 PB 级数据。它具有自动扩缩功能,可在批处理和流式流水线中实现最佳资源利用率。

利用模板和笔记本更快地实现价值
Dataflow 提供的工具可让您轻松上手。Dataflow 模板是预先设计的流处理和批处理蓝图,针对高效的 CDC 和 BigQuery 数据集成进行了优化。借助 Vertex AI 笔记本,使用最新的数据科学框架从零开始以迭代方式构建流水线,并使用 Dataflow 运行程序进行部署。 Dataflow 作业构建器是一个直观的界面,可用于在 Google Cloud 控制台中构建和运行 Dataflow 流水线,而无需编写代码。
使用智能诊断和监控工具节省时间
Dataflow 提供全面的诊断和监控工具。Straggler 检测会自动识别性能瓶颈,而数据采样则允许观察每个流水线步骤中的数据。Dataflow 数据分析提供作业改进建议。Dataflow 界面提供了丰富的监控工具,包括作业图、执行详情、指标、自动扩缩信息中心和日志记录。Dataflow 还具有作业费用监控界面,可让您轻松估算费用。
内置治理和安全机制
Dataflow 可通过多种方式帮助您保护数据:通过机密虚拟机支持加密使用中的数据;客户管理的加密密钥 (CMEK);VPC Service Controls 集成;关闭公共 IP。Dataflow 审核日志记录让您的组织能够了解 Dataflow 使用情况,并帮助回答“哪些用户何时在何处执行过哪些操作?”这一问题。以改善治理。

实时分析
为实时分析和运营流水线引入流式数据
为实时分析和运营流水线引入流式数据
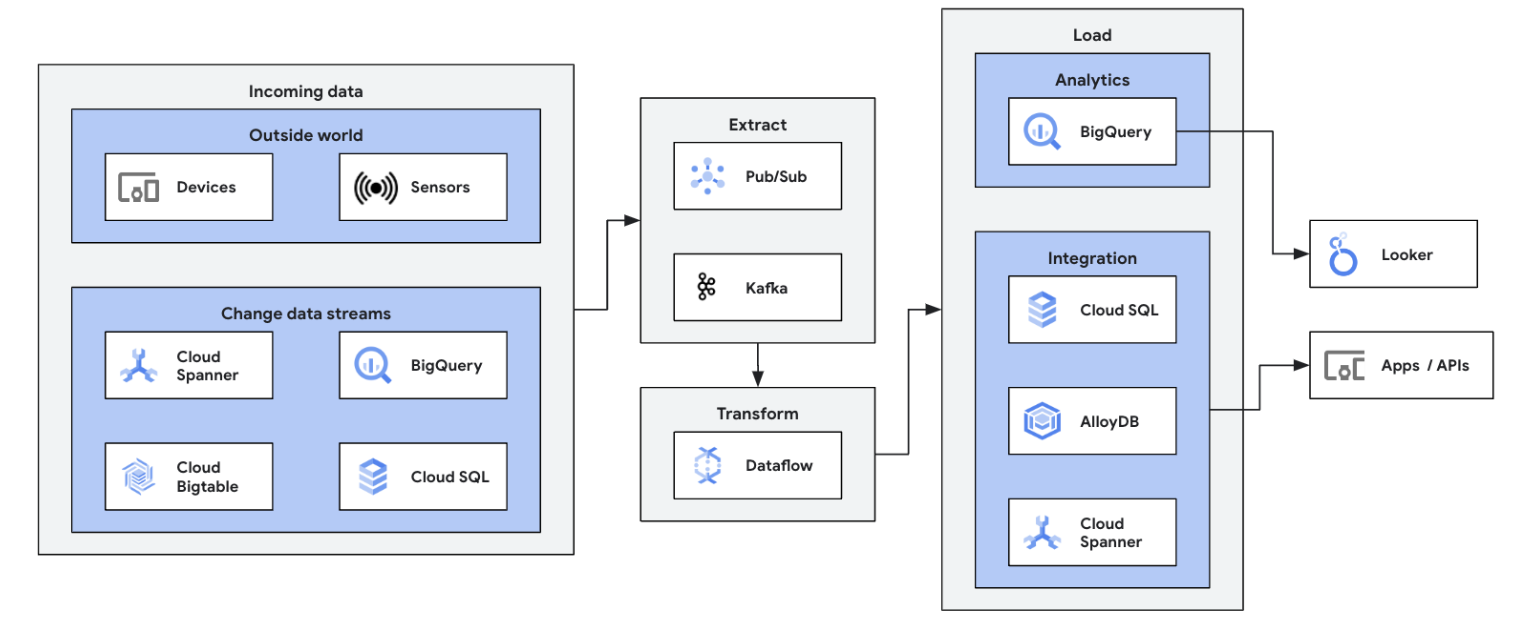
将您的流式数据源(Pub/Sub、Kafka、CDC 事件、用户点击流、日志和传感器数据)集成到 BigQuery、Google Cloud Storage 数据湖、Spanner、Bigtable、SQL 存储、Splunk、Datadog 等中,从而开启您的数据流式传输之旅。探索经过优化的数据流模板,只需点击几下即可设置流水线,无需编写代码。使用集成 UDF 构建器向模板作业添加自定义逻辑,或者充分利用 Beam 转换和 I/O 连接器生态系统的全部功能,从头开始创建自定义 ETL 流水线。Dataflow 还常用于将 ETL 处理过的数据从 BigQuery 反向加载到 OLTP 存储区,以便快速查询和服务最终用户。Dataflow 将流式数据写入多个存储位置是 Dataflow 的一种常见模式。

启动您的第一个 Dataflow 作业并学习 Dataflow 基础知识的自助式课程。
教程、快速入门和实验
为实时分析和运营流水线引入流式数据
为实时分析和运营流水线引入流式数据
将您的流式数据源(Pub/Sub、Kafka、CDC 事件、用户点击流、日志和传感器数据)集成到 BigQuery、Google Cloud Storage 数据湖、Spanner、Bigtable、SQL 存储、Splunk、Datadog 等中,从而开启您的数据流式传输之旅。探索经过优化的数据流模板,只需点击几下即可设置流水线,无需编写代码。使用集成 UDF 构建器向模板作业添加自定义逻辑,或者充分利用 Beam 转换和 I/O 连接器生态系统的全部功能,从头开始创建自定义 ETL 流水线。Dataflow 还常用于将 ETL 处理过的数据从 BigQuery 反向加载到 OLTP 存储区,以便快速查询和服务最终用户。Dataflow 将流式数据写入多个存储位置是 Dataflow 的一种常见模式。
启动您的第一个 Dataflow 作业并学习 Dataflow 基础知识的自助式课程。
实时 ETL 和数据集成
利用实时数据对数据平台进行现代化改造
利用实时数据对数据平台进行现代化改造
实时 ETL 和集成处理并立即写入数据,实现快速分析和决策。Dataflow 的无服务器架构和流式传输功能使其非常适合构建实时 ETL 流水线。Dataflow 的自动扩缩功能可确保效率和规模,而其对各种数据源和目的地的支持简化了集成。
学习此 Google Cloud Skills Boost 课程,帮助您掌握有关 Dataflow 上的批处理的基础知识。
教程、快速入门和实验
利用实时数据对数据平台进行现代化改造
利用实时数据对数据平台进行现代化改造
实时 ETL 和集成处理并立即写入数据,实现快速分析和决策。Dataflow 的无服务器架构和流式传输功能使其非常适合构建实时 ETL 流水线。Dataflow 的自动扩缩功能可确保效率和规模,而其对各种数据源和目的地的支持简化了集成。
学习此 Google Cloud Skills Boost 课程,帮助您掌握有关 Dataflow 上的批处理的基础知识。
实时机器学习和生成式 AI
利用流式机器学习/AI 实时采取行动
利用流式机器学习/AI 实时采取行动
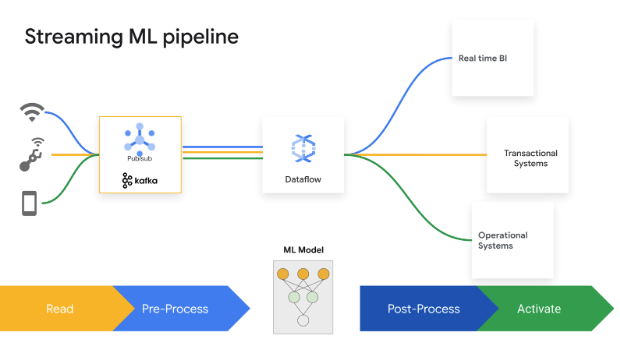
分秒必争的决策带来了业务价值。借助 Dataflow 流式 AI 和机器学习,客户可以实现低延迟预测和推断、实时个性化、威胁检测、欺诈防范,以及实时智能至关重要的许多其他用例。使用 MLTransform 预处理数据,使您可以专注于转换数据,而无需编写复杂的代码或管理底层库。使用 RunInference 对生成式 AI 模型做出预测。
教程、快速入门和实验
利用流式机器学习/AI 实时采取行动
利用流式机器学习/AI 实时采取行动
分秒必争的决策带来了业务价值。借助 Dataflow 流式 AI 和机器学习,客户可以实现低延迟预测和推断、实时个性化、威胁检测、欺诈防范,以及实时智能至关重要的许多其他用例。使用 MLTransform 预处理数据,使您可以专注于转换数据,而无需编写复杂的代码或管理底层库。使用 RunInference 对生成式 AI 模型做出预测。
营销智能
利用实时数据分析,实现营销转型
利用实时数据分析,实现营销转型
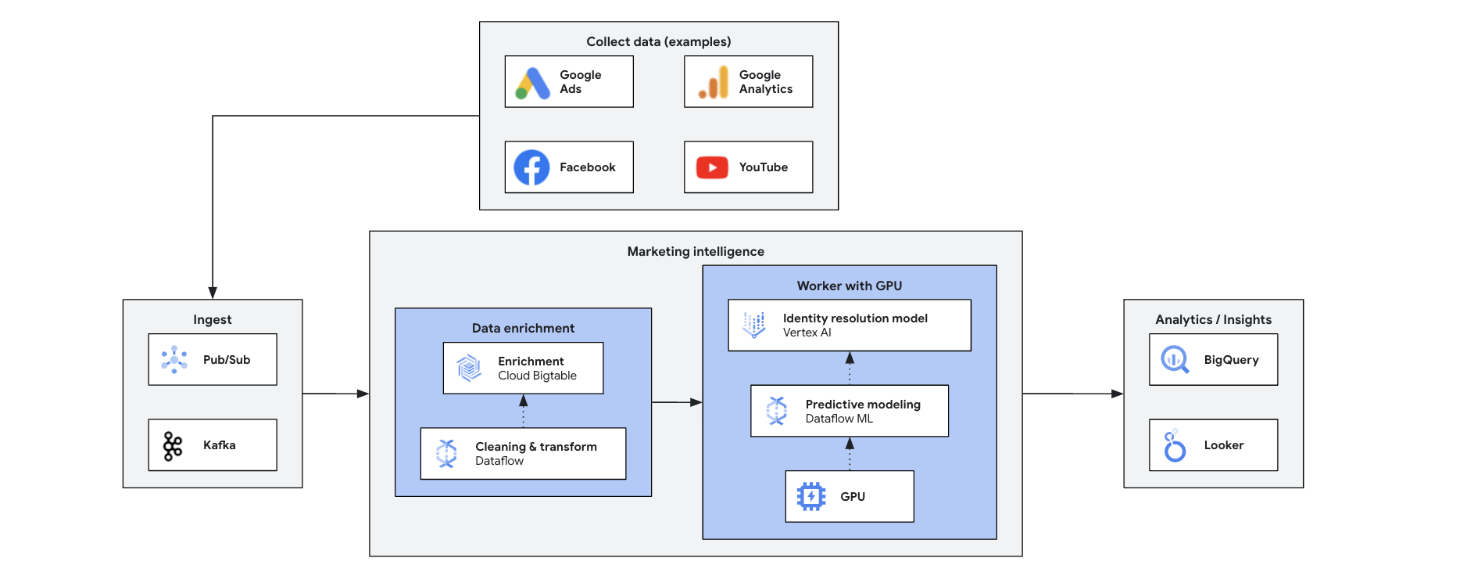
实时营销智能可分析当前市场、客户和竞争对手的数据,以快速做出明智的决策。它支持敏捷地响应趋势、行为和竞争行为,从而转变营销方式。演示项目具有以下优势:
- 使用个性化产品/服务实时开展全渠道营销
- 通过个性化互动更好地管理客户关系
- 敏捷营销组合优化
- 动态用户细分
- 竞争智能助您保持领先地位
- 在社交媒体上主动进行危机管理
教程、快速入门和实验
利用实时数据分析,实现营销转型
利用实时数据分析,实现营销转型
实时营销智能可分析当前市场、客户和竞争对手的数据,以快速做出明智的决策。它支持敏捷地响应趋势、行为和竞争行为,从而转变营销方式。演示项目具有以下优势:
- 使用个性化产品/服务实时开展全渠道营销
- 通过个性化互动更好地管理客户关系
- 敏捷营销组合优化
- 动态用户细分
- 竞争智能助您保持领先地位
- 在社交媒体上主动进行危机管理
点击流分析
优化网站和应用体验并实现个性化
优化网站和应用体验并实现个性化
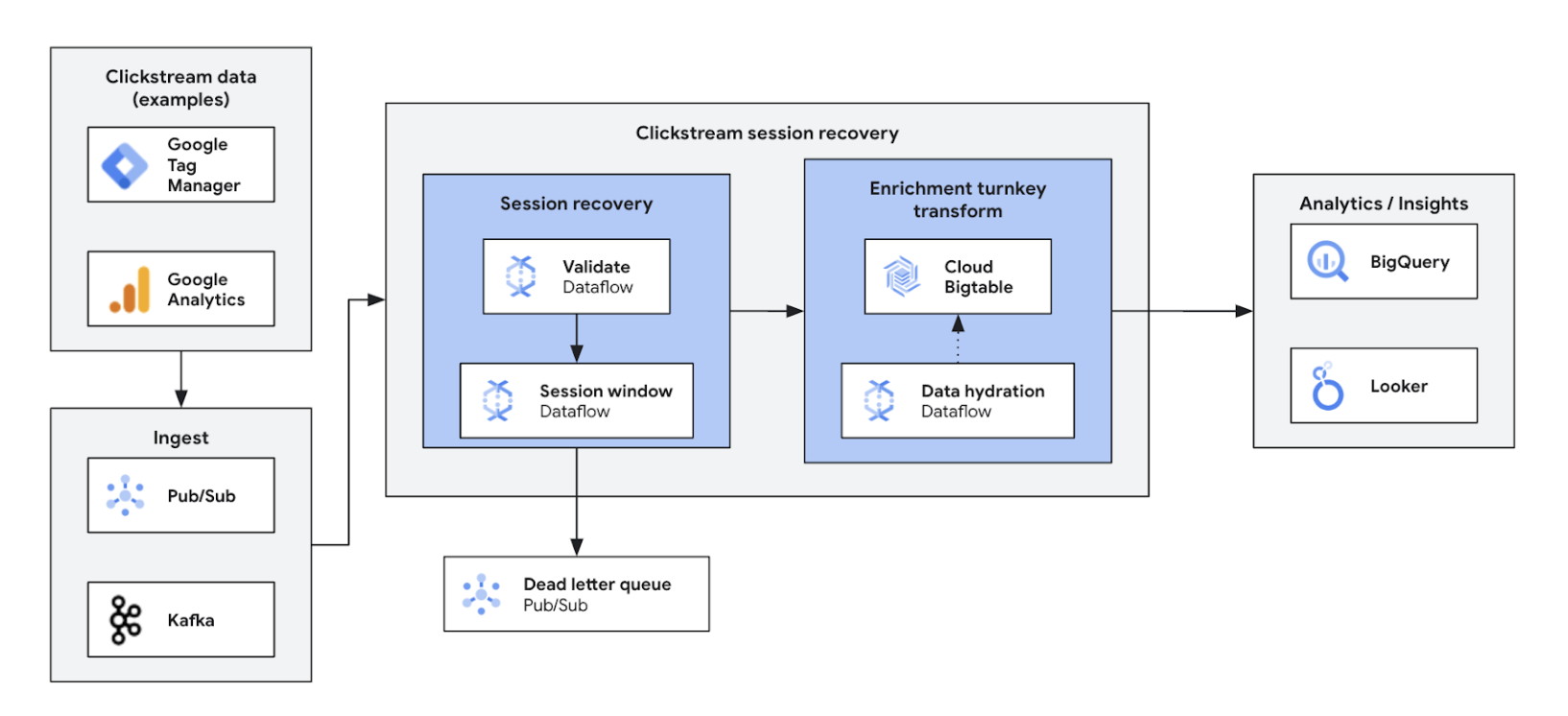
借助实时点击流分析,企业能够即时分析用户在网站和应用中的互动情况。这样可以实现实时个性化、A/B 测试和漏斗优化,从而提高互动度、加快产品开发速度、减少用户流失并增强产品支持。最终,它可以提供卓越的用户体验,并通过动态定价和个性化建议推动业务增长。
教程、快速入门和实验
优化网站和应用体验并实现个性化
优化网站和应用体验并实现个性化
借助实时点击流分析,企业能够即时分析用户在网站和应用中的互动情况。这样可以实现实时个性化、A/B 测试和漏斗优化,从而提高互动度、加快产品开发速度、减少用户流失并增强产品支持。最终,它可以提供卓越的用户体验,并通过动态定价和个性化建议推动业务增长。
实时日志复制和分析
集中式日志管理和分析
集中式日志管理和分析
您可以使用 Dataflow 将 Google Cloud 日志复制到 Splunk 等第三方平台,以实现近乎实时的日志处理和分析。此解决方案提供集中式日志管理、合规性、审核和分析功能,同时降低成本并提高性能。
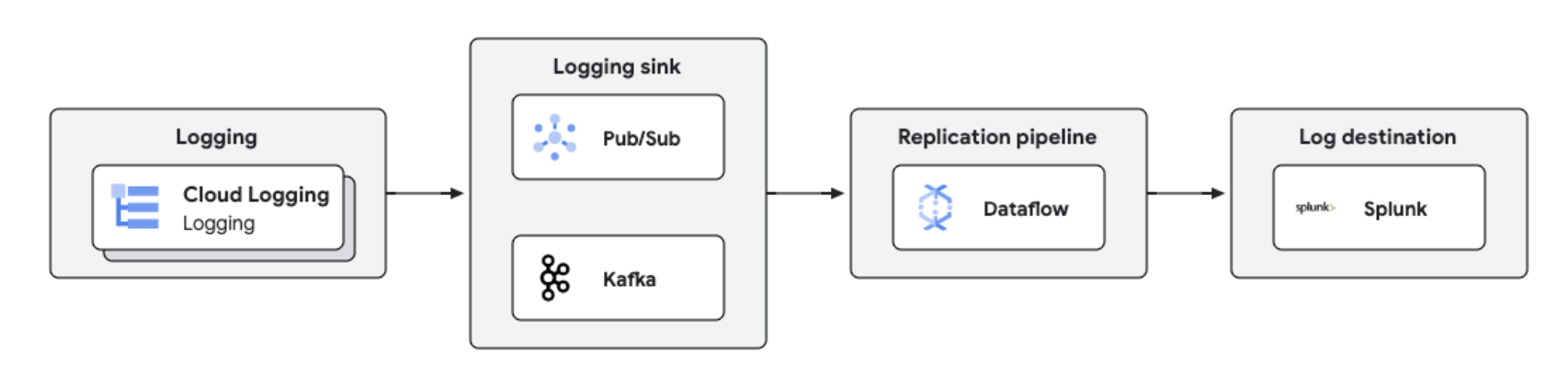
教程、快速入门和实验
集中式日志管理和分析
集中式日志管理和分析
您可以使用 Dataflow 将 Google Cloud 日志复制到 Splunk 等第三方平台,以实现近乎实时的日志处理和分析。此解决方案提供集中式日志管理、合规性、审核和分析功能,同时降低成本并提高性能。
价格
| Dataflow 定价方式 | 探索 Dataflow 的结算和资源模型。 | |
|---|---|---|
| 服务和用量 | 说明 | 价格 |
Dataflow 计算资源 | 针对计算资源的 Dataflow 结算包括: | 如需了解详情,请访问我们详细的价格页面 |
其他 Dataflow 资源 | 如需了解详情,请访问我们详细的价格页面 | |
Dataflow 承诺使用折扣 (CUD) | Dataflow CUD 提供两种级别的折扣,具体取决于承诺期:
| 详细了解 Dataflow CUD |
详细了解 Dataflow 价格。查看所有价格详情。
Dataflow 定价方式
探索 Dataflow 的结算和资源模型。
Dataflow 承诺使用折扣 (CUD)
Dataflow CUD 提供两种级别的折扣,具体取决于承诺期:
- 一年期 CUD 提供按需费率 20% 的折扣
- 三年期 CUD 提供按需费率 40% 的折扣
详细了解 Dataflow CUD
详细了解 Dataflow 价格。查看所有价格详情。
业务用例
了解领先客户选择 Dataflow 的原因
Namitha Vijaya Kumar,ANZ Bank 的 Google Cloud SRE 产品负责人
“Dataflow 同时帮助我们进行批处理和实时数据处理,从而确保在企业数据湖中保持数据的及时性。这反过来又有助于在下游使用数据,为零售客户进行分析/决策和发送实时通知。”
Dataflow 的好处
流式机器学习轻松进行
将流式处理引入 AI/机器学习的一站式功能:用于推理的 RunInference、用于模型训练预处理的 MLTransform、用于特征存储区查询的 Enrichment 以及动态 GPU 支持,这些都减少了重复劳动,同时在有限的 GPU 资源上不会浪费支出。
借助强大的工具实现最佳性价比
Dataflow 提供具有成本效益的流式传输,并可自动优化,从而最大限度地提高性能和资源利用率。它可以轻松扩容以处理任何工作负载,并具有 AI 赋能的自我修复功能。强大的工具有助于操作和理解。
开源、可移植和可扩展
Dataflow 专为开源 Apache Beam 而构建,具有统一的批处理和流式处理支持,使您的工作负载可在云端、本地或边缘设备之间移植。
合作伙伴与集成




Dataflow 合作伙伴
Google Cloud 合作伙伴开发了很多与 Dataflow 集成的方案,提供强大的处理功能,让您可以轻松快捷地完成任何规模的数据处理任务。查看所有合作伙伴,立即开始您的流式传输之旅。


















