Dataflow
Data intelligence in tempo reale
Massimizza il potenziale dei tuoi dati in tempo reale. Dataflow è una piattaforma di streaming di dati completamente gestita, facile da usare e scalabile per contribuire ad accelerare il processo decisionale in tempo reale e le esperienze dei clienti.
I nuovi clienti ricevono 300 $ di crediti gratuiti da spendere su Dataflow.

Funzionalità
Utilizza l'IA e l'ML per i flussi di dati per potenziare i modelli di IA generativa in tempo reale
I dati in tempo reale mettono a disposizione dei modelli IA/ML le informazioni più recenti, migliorando l'accuratezza delle previsioni. Dataflow ML semplifica il deployment e la gestione di pipeline ML complete. Offriamo pattern pronti all'uso per suggerimenti personalizzati, rilevamento di attività fraudolente, prevenzione delle minacce e altro ancora. Crea l'IA di flusso con i modelli Vertex AI, Gemini e Gemma, esegui l'inferenza remota e semplifica l'elaborazione dati con MLTransform. Migliora l'efficienza dei job MLOps e ML con le funzionalità GPU Dataflow e adattamento ottimale.
Abilita casi d'uso avanzati per i flussi di dati su scala aziendale
Dataflow è un servizio completamente gestito che utilizza il sistema open source SDK Apache Beam per attivare casi d'uso avanzati per i flussi di dati su scala aziendale. Offre funzionalità avanzate per stato e data/ora, trasformazioni e connettori I/O. Dataflow adegua fino a 4000 worker per job ed elabora regolarmente petabyte di dati. È dotato di scalabilità automatica per un utilizzo ottimale delle risorse nelle pipeline in modalità batch e flusso.

Esegui il deployment del trattamento dati multimodale per l'IA generativa
Dataflow consente in contemporanea l'importazione e la trasformazione di dati multimodali come immagini, testo e audio. Applica l'estrazione specializzata delle caratteristiche per ogni modalità e fonde queste caratteristiche in una rappresentazione unificata. Questo ha integrato i feed di dati in modelli di IA generativa, consentendo loro di creare nuovi contenuti a partire dai diversi input. I team interni di Google sfruttano Dataflow e FlumeJava per organizzare e calcolare le previsioni dei modelli per un ampio pool di dati di ingresso disponibili senza requisiti di latenza.
Accelera il time to value con modelli e blocchi note
Dataflow dispone di strumenti che aiutano a muovere i primi passi. I modelli Dataflow sono progetti predefiniti per l'elaborazione in modalità flusso e batch e sono ottimizzati per un'integrazione efficiente dei dati CDC e BigQuery. Crea in modo iterativo pipeline con i più recenti framework di data science partendo da zero, grazie ai blocchi note Vertex AI ed esegui il deployment con il runner Dataflow. Dataflow job Builder è una UI visiva per la creazione e l'esecuzione di pipeline Dataflow nella console Google Cloud, senza scrivere codice.
Risparmia tempo con gli strumenti mart di diagnostica e monitoraggio
Dataflow offre strumenti completi di diagnostica e monitoraggio. Il rilevamento dei problemi identifica automaticamente i colli di bottiglia delle prestazioni, mentre il campionamento dei dati consente di osservare i dati in ogni passaggio della pipeline. Dataflow Insights offre suggerimenti per migliorare il job. La UI di Dataflow offre strumenti di monitoraggio avanzati, tra cui grafici dei job, dettagli di esecuzione, metriche, dashboard con scalabilità automatica e logging. Dataflow presenta anche un'interfaccia utente per il monitoraggio dei costi del job per una facile stima dei costi.
Governance e sicurezza integrate
Dataflow ti aiuta a proteggere i tuoi dati con diversi modi: criptando i dati in uso con il supporto di Confidential VM; con chiavi di crittografia gestite dal cliente (CMEK); l'integrazione dei Controlli di servizio VPC; la disattivazione degli IP pubblici. L'audit logging di Dataflow offre alla tua organizzazione la visibilità sull'utilizzo di Dataflow e, per una migliore governance, aiuta a rispondere alla domanda "Chi ha fatto cosa, dove e quando?".
Come funziona
Dataflow è una piattaforma completamente gestita per il trattamento dati in modalità flusso e batch. Consente pipeline ETL potenziabili, analisi dei flussi in tempo reale, ML in tempo reale e trasformazioni di dati complesse utilizzando il modello unificato di Apache Beam, il tutto sull'infrastruttura serverless di Google Cloud.
Dataflow è una piattaforma completamente gestita per il trattamento dati in modalità flusso e batch. Consente pipeline ETL potenziabili, analisi dei flussi in tempo reale, ML in tempo reale e trasformazioni di dati complesse utilizzando il modello unificato di Apache Beam, il tutto sull'infrastruttura serverless di Google Cloud.

Analisi in tempo reale
Acquisisci dati in modalità flusso per l'analisi in tempo reale e le pipeline operative
Acquisisci dati in modalità flusso per l'analisi in tempo reale e le pipeline operative
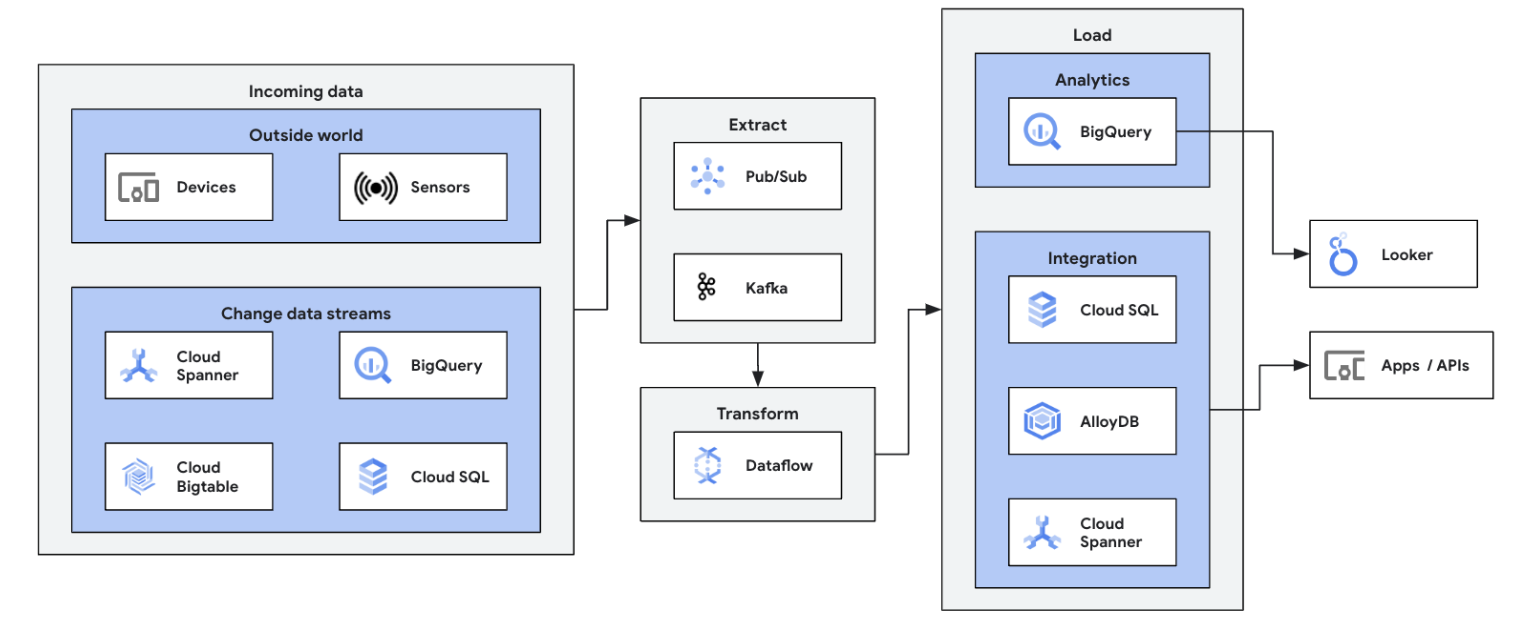
Inizia il tuo percorso di elaborazione dei flussi di dati integrando le tue origini di dati in esecuzione (Pub/Sub, Kafka, eventi CDC, clickstream utente, log e dati dei sensori) in BigQuery, nei data lake di Google Cloud Storage, in Spanner, Bigtable, nei repository SQL, in Splunk, Datadog e altro ancora. Esplora i modelli Dataflow ottimizzati per configurare le pipeline in pochi clic e senza codici. Aggiungi logica personalizzata ai job dei modelli con il generatore di Funzioni definite dall'utente integrato o crea pipeline ETL personalizzate da zero utilizzando tutta la potenza dell'ecosistema delle trasformazioni Beam e dei connettori I/O. Dataflow viene comunemente utilizzato anche per invertire i dati elaborati ETL da BigQuery agli archivi OLTP per ricerche rapide e servizi dedicati agli utenti finali. È un pattern comune per Dataflow per scrivere flussi di dati in più posizioni dello spazio di archiviazione.

Avvia il tuo primo job Dataflow e segui il nostro corso autoguidato sulle Nozioni di base di Dataflow.
Tutorial, guide rapide e lab
Acquisisci dati in modalità flusso per l'analisi in tempo reale e le pipeline operative
Acquisisci dati in modalità flusso per l'analisi in tempo reale e le pipeline operative
Inizia il tuo percorso di elaborazione dei flussi di dati integrando le tue origini di dati in esecuzione (Pub/Sub, Kafka, eventi CDC, clickstream utente, log e dati dei sensori) in BigQuery, nei data lake di Google Cloud Storage, in Spanner, Bigtable, nei repository SQL, in Splunk, Datadog e altro ancora. Esplora i modelli Dataflow ottimizzati per configurare le pipeline in pochi clic e senza codici. Aggiungi logica personalizzata ai job dei modelli con il generatore di Funzioni definite dall'utente integrato o crea pipeline ETL personalizzate da zero utilizzando tutta la potenza dell'ecosistema delle trasformazioni Beam e dei connettori I/O. Dataflow viene comunemente utilizzato anche per invertire i dati elaborati ETL da BigQuery agli archivi OLTP per ricerche rapide e servizi dedicati agli utenti finali. È un pattern comune per Dataflow per scrivere flussi di dati in più posizioni dello spazio di archiviazione.
Avvia il tuo primo job Dataflow e segui il nostro corso autoguidato sulle Nozioni di base di Dataflow.
ETL e integrazione dei dati in tempo reale
Modernizza la piattaforma con i tuoi dati in tempo reale
Modernizza la piattaforma con i tuoi dati in tempo reale
L'ETL in tempo reale e il processo di integrazione e scrittura immediata dei dati consentono di velocizzare l'analisi e il processo decisionale. L'architettura serverless e le funzionalità di elaborazione in modalità flusso di Dataflow lo rendono ideale per la creazione di pipeline ETL in tempo reale. La capacità di Dataflow di scalare automaticamente garantisce efficienza e scalabilità, mentre il suo supporto per varie origini dati e destinazioni ne semplifica l'integrazione.
Costruisci le tue basi nell'elaborazione batch su Dataflow con questo corso Google Cloud Skills Boost.
Tutorial, guide rapide e lab
Modernizza la piattaforma con i tuoi dati in tempo reale
Modernizza la piattaforma con i tuoi dati in tempo reale
L'ETL in tempo reale e il processo di integrazione e scrittura immediata dei dati consentono di velocizzare l'analisi e il processo decisionale. L'architettura serverless e le funzionalità di elaborazione in modalità flusso di Dataflow lo rendono ideale per la creazione di pipeline ETL in tempo reale. La capacità di Dataflow di scalare automaticamente garantisce efficienza e scalabilità, mentre il suo supporto per varie origini dati e destinazioni ne semplifica l'integrazione.
Costruisci le tue basi nell'elaborazione batch su Dataflow con questo corso Google Cloud Skills Boost.
ML e IA generativa in tempo reale
Agisci in tempo reale con ML/IA in streaming
Agisci in tempo reale con ML/IA in streaming
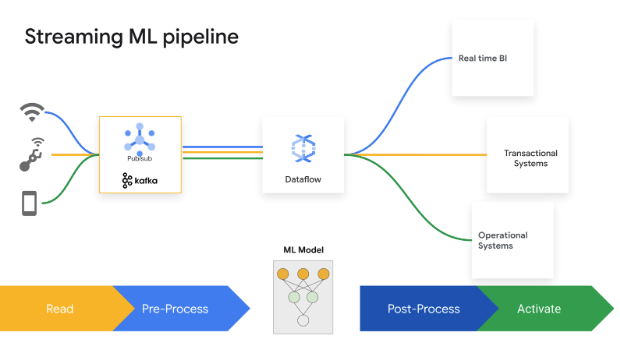
Le decisioni di suddivisione dei secondi generano valore aziendale. L'IA e il ML di Dataflow Streaming consentono ai clienti l'implementazione di previsioni e inferenze a bassa latenza, la personalizzazione in tempo reale, il rilevamento delle minacce, la prevenzione delle frodi e molti altri casi d'uso in cui l'intelligence in tempo reale risulta importante. Pre-elabora i dati con MLTransform, che ti consente di concentrarti sulla trasformazione dei dati senza dover scrivere codici complessi o gestire le librerie sottostanti. Fai previsioni sul tuo modello di IA generativa utilizzando RunInference.
Tutorial, guide rapide e lab
Agisci in tempo reale con ML/IA in streaming
Agisci in tempo reale con ML/IA in streaming
Le decisioni di suddivisione dei secondi generano valore aziendale. L'IA e il ML di Dataflow Streaming consentono ai clienti l'implementazione di previsioni e inferenze a bassa latenza, la personalizzazione in tempo reale, il rilevamento delle minacce, la prevenzione delle frodi e molti altri casi d'uso in cui l'intelligence in tempo reale risulta importante. Pre-elabora i dati con MLTransform, che ti consente di concentrarti sulla trasformazione dei dati senza dover scrivere codici complessi o gestire le librerie sottostanti. Fai previsioni sul tuo modello di IA generativa utilizzando RunInference.
Marketing Intelligence
Trasforma il tuo marketing con informazioni in tempo reale
Trasforma il tuo marketing con informazioni in tempo reale
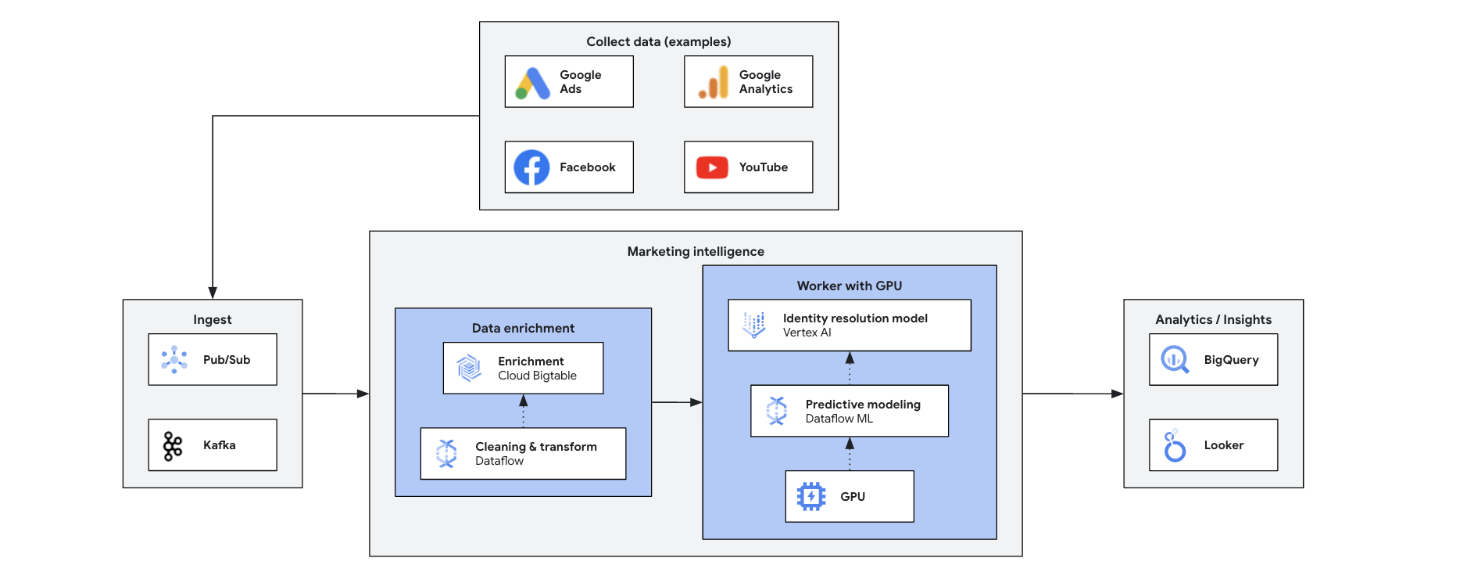
Il Marketing Intelligence in tempo reale analizza gli attuali dati di mercato, clienti e concorrenti per prendere decisioni rapide e consapevoli. Consente risposte agili a tendenze, comportamenti e azioni della concorrenza, trasformando il modo di fare marketing. Ecco alcuni dei vantaggi di Meet:
- Marketing omnicanale in tempo reale con offerte personalizzate
- Miglioramento della gestione dei rapporti con i clienti attraverso interazioni personalizzate
- Ottimizzazione del marketing mix agile
- Segmentazione dinamica degli utenti
- Informazioni competitive per stare al passo con i tempi
- Gestione proattiva dei problemi sui social media
Tutorial, guide rapide e lab
Trasforma il tuo marketing con informazioni in tempo reale
Trasforma il tuo marketing con informazioni in tempo reale
Il Marketing Intelligence in tempo reale analizza gli attuali dati di mercato, clienti e concorrenti per prendere decisioni rapide e consapevoli. Consente risposte agili a tendenze, comportamenti e azioni della concorrenza, trasformando il modo di fare marketing. Ecco alcuni dei vantaggi di Meet:
- Marketing omnicanale in tempo reale con offerte personalizzate
- Miglioramento della gestione dei rapporti con i clienti attraverso interazioni personalizzate
- Ottimizzazione del marketing mix agile
- Segmentazione dinamica degli utenti
- Informazioni competitive per stare al passo con i tempi
- Gestione proattiva dei problemi sui social media
Analisi del clickstream
Ottimizza e personalizza le esperienze su web e app
Ottimizza e personalizza le esperienze su web e app
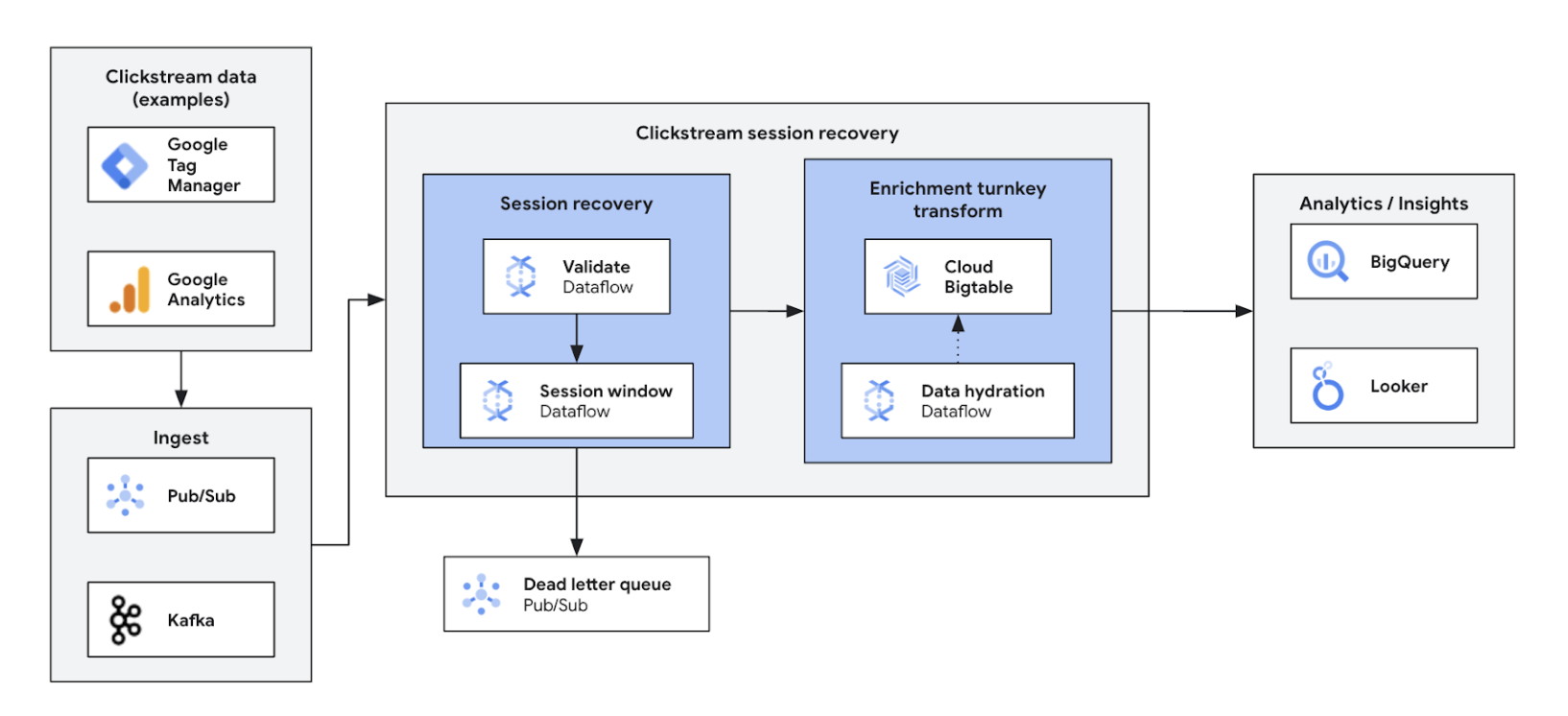
L'analisi dei flussi di clic in tempo reale consente alle aziende di analizzare all'istante le interazioni degli utenti su siti web e app. Questo permette di sbloccare la personalizzazione in tempo reale, i test A/B e l'ottimizzazione della canalizzazione, con un conseguente aumento del coinvolgimento, uno sviluppo dei prodotti più rapido, una riduzione del tasso di abbandono e un'assistenza avanzata per i prodotti. Inoltre, garantisce un'esperienza utente di livello superiore e favorisce la crescita dell'attività attraverso prezzi dinamici e consigli personalizzati.
Tutorial, guide rapide e lab
Ottimizza e personalizza le esperienze su web e app
Ottimizza e personalizza le esperienze su web e app
L'analisi dei flussi di clic in tempo reale consente alle aziende di analizzare all'istante le interazioni degli utenti su siti web e app. Questo permette di sbloccare la personalizzazione in tempo reale, i test A/B e l'ottimizzazione della canalizzazione, con un conseguente aumento del coinvolgimento, uno sviluppo dei prodotti più rapido, una riduzione del tasso di abbandono e un'assistenza avanzata per i prodotti. Inoltre, garantisce un'esperienza utente di livello superiore e favorisce la crescita dell'attività attraverso prezzi dinamici e consigli personalizzati.
Replica e analisi dei log in tempo reale
Gestione e analisi dei log centralizzati
Gestione e analisi dei log centralizzati
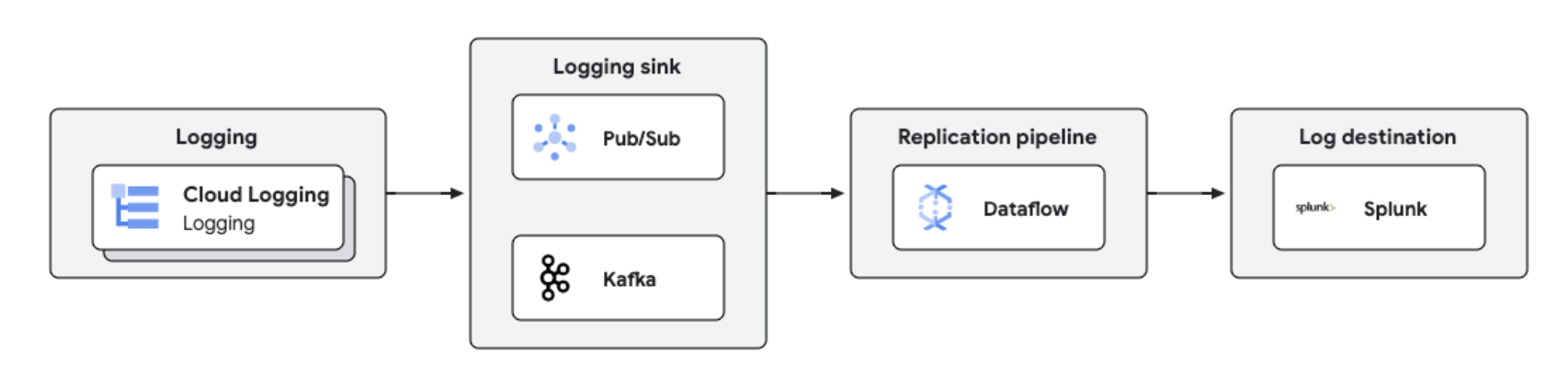
I log di Google Cloud possono essere replicati su piattaforme di terze parti come Splunk utilizzando Dataflow per l'elaborazione e l'analisi dei log quasi in tempo reale. Questa soluzione offre funzionalità centralizzate di gestione dei log, conformità, controllo e analisi, riducendo i costi e migliorando le prestazioni.
Tutorial, guide rapide e lab
Gestione e analisi dei log centralizzati
Gestione e analisi dei log centralizzati
I log di Google Cloud possono essere replicati su piattaforme di terze parti come Splunk utilizzando Dataflow per l'elaborazione e l'analisi dei log quasi in tempo reale. Questa soluzione offre funzionalità centralizzate di gestione dei log, conformità, controllo e analisi, riducendo i costi e migliorando le prestazioni.
Prezzi
| Come funzionano i prezzi di Dataflow | Esplora il modello di fatturazione e risorse per Dataflow. | |
|---|---|---|
| Servizi e utilizzo | Descrizione | Prezzi |
Risorse delle computing di Dataflow | La fatturazione di Dataflow per le risorse di computing include: | Scopri i prezzi nel dettaglio nella nostra pagina dei prezzi |
Altre risorse Dataflow | Scopri i prezzi nel dettaglio nella nostra pagina dei prezzi | |
Sconti per impegno di utilizzo (CUD) Dataflow | Gli sconti per impegno di utilizzo (CUD) di Dataflow possono essere di due tipi, a seconda della durata dell'impegno:
| Scopri di più sugli sconti per impegno di utilizzo (CUD) di Dataflow |
Scopri di più sui prezzi di Dataflow Visualizza tutti i dettagli sui prezzi
Come funzionano i prezzi di Dataflow
Esplora il modello di fatturazione e risorse per Dataflow.
Risorse delle computing di Dataflow
La fatturazione di Dataflow per le risorse di computing include:
Scopri i prezzi nel dettaglio nella nostra pagina dei prezzi
Altre risorse Dataflow
Scopri i prezzi nel dettaglio nella nostra pagina dei prezzi
Sconti per impegno di utilizzo (CUD) Dataflow
Gli sconti per impegno di utilizzo (CUD) di Dataflow possono essere di due tipi, a seconda della durata dell'impegno:
- lo sconto per impegno di utilizzo (CUD) di un anno ti offre una riduzione del 20% sulla tariffa on demand
- lo sconto per impegno di utilizzo (CUD) di tre anni ti offre una riduzione del 40% sulla tariffa on demand
Scopri di più sugli sconti per impegno di utilizzo (CUD) di Dataflow
Scopri di più sui prezzi di Dataflow Visualizza tutti i dettagli sui prezzi
Business case
Scopri perché i principali clienti scelgono Dataflow
Namitha Vijaya Kumar, Product Owner, SRE Google Cloud presso ANZ Bank
"Dataflow aiuta sia l'elaborazione batch che l'elaborazione dati in tempo reale, garantendo così la puntualità dei dati nel data lake aziendale. Questo a sua volta favorisce l'utilizzo dei dati a valle per l'analisi, la decisione e l'invio di notifiche in tempo reale per i nostri clienti retail."
Contenuti correlati
Google è stata riconosciuta nel settore per essere la scelta preferita dei clienti per l'elaborazione dei flussi di eventi
Scarica il report
Portare la potenza del machine learning nel mondo dei dati di streaming con Spotify
Guarda il video
Yahoo confronta Dataflow con Apache Flink autogestito per due casi d'uso dello streaming
Leggi il blog
Vantaggi di Dataflow
Flusso ML semplificato
Funzionalità pronte all'uso per portare i flussi in AI/ML: RunInference per l'inferenza, MLTransform per la pre-elaborazione dell'addestramento del modello. Enrichment per le ricerche nel Feature Store e il supporto dinamico delle GPU offrono tutti sforzi ridotti, senza sprechi di risorse GPU.
Rapporto prezzo/prestazioni ottimale con strumenti affidabili
Dataflow offre flussi di dati convenienti con ottimizzazione automatica per ottenere il massimo rendimento e l'utilizzo delle risorse. Si può potenziare facilmente per gestire qualsiasi carico di lavoro ed è dotato di riparazione automatica basata sull'IA. Strumenti efficaci ne favoriscono le operazioni e la comprensione.
Aperto, portabile ed estensibile
Dataflow è realizzato per il sistema open sourceApache Beam con supporto unificato per batch e flussi, in modo che i tuoi carichi di lavoro siano portabili tra cloud, on-premise e dispositivi periferici.
Partner e integrazione




Dataflow partners
I partner di Google Cloud hanno sviluppato integrazioni con Dataflow che consentono di eseguire in modo rapido e semplice attività avanzate di elaborazione dati di qualsiasi dimensione. Visualizza i partner per iniziare oggi stesso il tuo percorso verso lo streaming.











