Dataflow
Data intelligence real-time
Maksimalkan potensi data real-time Anda. Dataflow adalah platform streaming yang terkelola sepenuhnya, mudah digunakan, dan skalabel untuk membantu mempercepat pengambilan keputusan dan pengalaman pelanggan yang real-time.
Pelanggan baru akan mendapatkan kredit gratis senilai $300 untuk dibelanjakan di Dataflow.

Fitur
Menggunakan AI dan ML streaming untuk mendukung model AI generatif secara real time
Data real-time mendukung model AI/ML dengan informasi terbaru, sehingga dapat meningkatkan akurasi prediksi. Dataflow ML menyederhanakan deployment dan pengelolaan pipeline ML yang lengkap. Kami menawarkan pola siap pakai untuk rekomendasi yang dipersonalisasi, deteksi penipuan, pencegahan ancaman, dan lainnya. Bangun AI streaming dengan Gemini Enterprise Agent Platform, model Gemini, dan model Gemma, jalankan inferensi jarak jauh, serta sederhanakan pemrosesan data dengan MLTransform. Tingkatkan efisiensi tugas MLOps dan ML dengan GPU Dataflow serta kemampuan penyesuaian yang tepat.
Mendukung kasus penggunaan streaming lanjutan dalam skala perusahaan
Dataflow adalah layanan terkelola sepenuhnya yang menggunakan Apache Beam SDK open source untuk memungkinkan kasus penggunaan streaming lanjutan dalam skala perusahaan. Layanan ini menawarkan beragam kemampuan untuk status dan waktu, transformasi, serta konektor I/O. Dataflow diskalakan hingga 4K worker per tugas dan secara rutin memproses data berukuran petabyte. Layanan ini memiliki fitur penskalaan otomatis untuk pemanfaatan resource yang optimal di pipeline batch dan streaming.

Men-deploy pemrosesan data multimodal untuk AI generatif
Dataflow memungkinkan penyerapan dan transformasi paralel pada data multimodal seperti gambar, teks, dan audio. Layanan ini menerapkan ekstraksi fitur khusus untuk setiap modalitas, lalu menggabungkan fitur-fitur tersebut menjadi representasi terpadu. Gabungan data ini dimasukkan ke dalam model AI generatif, sehingga model tersebut dapat diberdayakan untuk membuat konten baru dari input yang beragam. Tim internal Google memanfaatkan Dataflow dan FlumeJava untuk mengatur dan menghitung prediksi model pada sekumpulan besar data input yang tersedia tanpa persyaratan latensi.
Mempercepat waktu untuk mendapatkan manfaat dengan template dan notebook
Dataflow memiliki alat yang memudahkan untuk memulai. Template Dataflow adalah blueprint yang telah dirancang sebelumnya untuk streaming dan batch processing serta dioptimalkan untuk integrasi data CDC dan BigQuery yang efisien. Bangun pipeline secara iteratif sejak awal dengan framework data science terbaru menggunakan Notebook Gemini Enterprise Agent Platform dan deploy dengan runner Dataflow.Builder tugasDataflow adalah UI visual untuk membangun dan menjalankan pipeline Dataflow di konsol Google Cloud, tanpa perlu menulis kode.
Menghemat waktu dengan alat diagnostik dan pemantauan cerdas
Dataflow menawarkan alat diagnostik dan pemantauan yang komprehensif. Deteksi Straggler secara otomatis mengidentifikasi bottleneck performa, sedangkan sampling data memungkinkan pengamatan data di setiap langkah pipeline. Insight Dataflow menawarkan rekomendasi untuk peningkatan tugas. UI Dataflow menyediakan alat pemantauan yang beragam, termasuk grafik tugas, detail eksekusi, metrik, dasbor penskalaan otomatis, dan logging. Dataflow juga menampilkan UI pemantauan biaya tugas untuk mempermudah estimasi biaya.
Tata kelola dan keamanan bawaan
Dataflow membantu Anda melindungi data dengan beberapa cara: mengenkripsi data aktif dengan dukungan confidential VM; kunci enkripsi yang dikelola pelanggan (CMEK); Integrasi Kontrol Layanan VPC; dan menonaktifkan IP publik. Logging audit Dataflow memberikan visibilitas terkait penggunaan Dataflow kepada Organisasi Anda dan membantu menjawab pertanyaan “Siapa yang melakukan apa, di mana, dan kapan?” untuk tata kelola yang lebih baik.
Cara Kerjanya
Dataflow adalah platform yang terkelola sepenuhnya untuk pemrosesan data batch dan streaming. Platform ini memungkinkan pipeline ETL yang skalabel, analisis streaming real-time, ML real-time, dan transformasi data yang kompleks menggunakan model terpadu Apache Beam, semuanya tersedia di infrastruktur Google Cloud serverless.
Dataflow adalah platform yang terkelola sepenuhnya untuk pemrosesan data batch dan streaming. Platform ini memungkinkan pipeline ETL yang skalabel, analisis streaming real-time, ML real-time, dan transformasi data yang kompleks menggunakan model terpadu Apache Beam, semuanya tersedia di infrastruktur Google Cloud serverless.

Analisis real-time
Hadirkan data streaming untuk analisis real-time dan pipeline operasional
Hadirkan data streaming untuk analisis real-time dan pipeline operasional
Mulai perjalanan streaming data Anda dengan mengintegrasikan sumber data streaming (Pub/Sub, Kafka, peristiwa CDC, clickstream pengguna, log, dan data sensor) ke dalam BigQuery, data lake Google Cloud Storage, Spanner, Bigtable, penyimpanan SQL, Splunk, Datadog, dan lainnya. Pelajari template Dataflow yang dioptimalkan untuk menyiapkan pipeline Anda dalam beberapa klik saja, tanpa kode. Tambahkan logika kustom ke tugas template Anda menggunakan builder UDF terintegrasi atau buat pipeline ETL kustom dari awal dengan kecanggihan ekosistem transformasi Beam dan konektor I/O. Dataflow juga umum digunakan untuk membalik data yang diproses oleh ETL dari BigQuery ke penyimpanan OLTP, sehingga mempercepat pencarian dan menginferensi pengguna akhir. Ini merupakan pola umum bagi Dataflow untuk menulis data streaming ke beberapa lokasi penyimpanan.

Luncurkan tugas Dataflow pertama Anda dan ikuti kursus mandiri kami tentang dasar-dasar Dataflow.
Tutorial, panduan memulai, dan lab
Hadirkan data streaming untuk analisis real-time dan pipeline operasional
Hadirkan data streaming untuk analisis real-time dan pipeline operasional
Mulai perjalanan streaming data Anda dengan mengintegrasikan sumber data streaming (Pub/Sub, Kafka, peristiwa CDC, clickstream pengguna, log, dan data sensor) ke dalam BigQuery, data lake Google Cloud Storage, Spanner, Bigtable, penyimpanan SQL, Splunk, Datadog, dan lainnya. Pelajari template Dataflow yang dioptimalkan untuk menyiapkan pipeline Anda dalam beberapa klik saja, tanpa kode. Tambahkan logika kustom ke tugas template Anda menggunakan builder UDF terintegrasi atau buat pipeline ETL kustom dari awal dengan kecanggihan ekosistem transformasi Beam dan konektor I/O. Dataflow juga umum digunakan untuk membalik data yang diproses oleh ETL dari BigQuery ke penyimpanan OLTP, sehingga mempercepat pencarian dan menginferensi pengguna akhir. Ini merupakan pola umum bagi Dataflow untuk menulis data streaming ke beberapa lokasi penyimpanan.
Luncurkan tugas Dataflow pertama Anda dan ikuti kursus mandiri kami tentang dasar-dasar Dataflow.
ETL dan integrasi data real-time
Memodernisasi platform data dengan data real-time
Memodernisasi platform data dengan data real-time
ETL dan proses integrasi real-time serta langsung menulis data, sehingga memungkinkan analisis dan pengambilan keputusan yang cepat. Arsitektur serverless dan kemampuan streaming Dataflow membuatnya cocok untuk membangun pipeline ETL real-time. Kemampuan Dataflow untuk melakukan penskalaan otomatis memastikan efisiensi dan penskalaan, sementara dukungannya untuk berbagai sumber data dan tujuan dapat menyederhanakan integrasi.
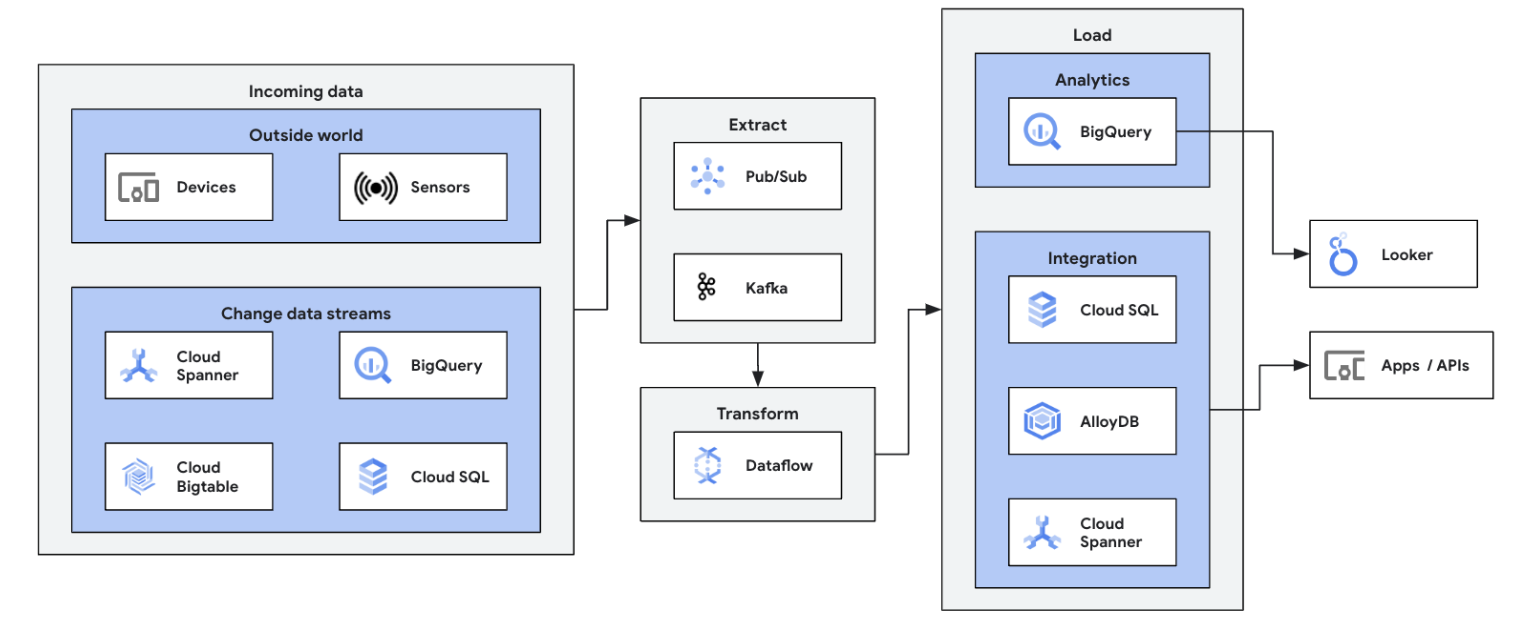
Bangun kemampuan dasar Anda dalam menggunakan batch processing di Dataflow dengan mengikuti kursus Google Cloud Skills Boost ini.
Tutorial, panduan memulai, dan lab
Memodernisasi platform data dengan data real-time
Memodernisasi platform data dengan data real-time
ETL dan proses integrasi real-time serta langsung menulis data, sehingga memungkinkan analisis dan pengambilan keputusan yang cepat. Arsitektur serverless dan kemampuan streaming Dataflow membuatnya cocok untuk membangun pipeline ETL real-time. Kemampuan Dataflow untuk melakukan penskalaan otomatis memastikan efisiensi dan penskalaan, sementara dukungannya untuk berbagai sumber data dan tujuan dapat menyederhanakan integrasi.
Bangun kemampuan dasar Anda dalam menggunakan batch processing di Dataflow dengan mengikuti kursus Google Cloud Skills Boost ini.
ML dan AI generatif real-time
Bertindak secara real time dengan streaming ML/AI
Bertindak secara real time dengan streaming ML/AI
Mengambil keputusan dengan cepat dapat meningkatkan nilai bisnis. Dataflow Streaming AI dan ML memungkinkan pelanggan untuk menerapkan prediksi dan inferensi berlatensi rendah, personalisasi real-time, deteksi ancaman, pencegahan penipuan, dan banyak kasus penggunaan lainnya yang membutuhkan kecerdasan real-time. Melakukan prapemrosesan data dengan MLTransform, yang memungkinkan Anda berfokus pada transformasi data dan tidak perlu menulis kode yang kompleks atau mengelola library yang mendasarinya. Membuat prediksi ke model AI generatif menggunakan RunInference.
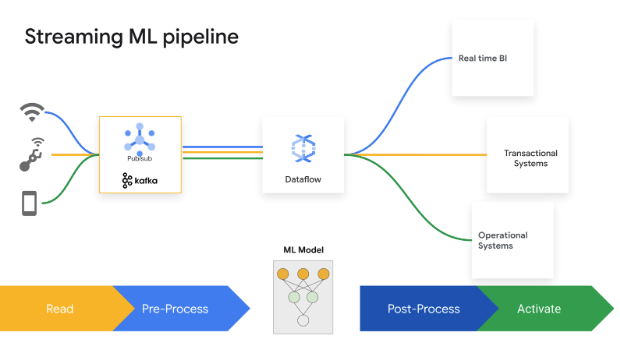
Tutorial, panduan memulai, dan lab
Bertindak secara real time dengan streaming ML/AI
Bertindak secara real time dengan streaming ML/AI
Mengambil keputusan dengan cepat dapat meningkatkan nilai bisnis. Dataflow Streaming AI dan ML memungkinkan pelanggan untuk menerapkan prediksi dan inferensi berlatensi rendah, personalisasi real-time, deteksi ancaman, pencegahan penipuan, dan banyak kasus penggunaan lainnya yang membutuhkan kecerdasan real-time. Melakukan prapemrosesan data dengan MLTransform, yang memungkinkan Anda berfokus pada transformasi data dan tidak perlu menulis kode yang kompleks atau mengelola library yang mendasarinya. Membuat prediksi ke model AI generatif menggunakan RunInference.
Kecerdasan pemasaran
Mentransformasi pemasaran Anda dengan insight real-time
Mentransformasi pemasaran Anda dengan insight real-time
Kecerdasan pemasaran real-time menganalisis data pasar, pelanggan, dan kompetitor saat ini, sehingga keputusan dapat diambil dengan cepat dan tepat. Layanan ini memungkinkan respons yang tangkas terhadap tren, perilaku, dan tindakan kompetitif, sehingga dapat mewujudkan transformasi pemasaran. Manfaatnya meliputi:
- Pemasaran omnichannel real-time dengan penawaran yang dipersonalisasi
- Peningkatan pengelolaan hubungan pelanggan melalui interaksi yang dipersonalisasi
- Pengoptimalan marketing mix yang fleksibel
- Segmentasi pengguna yang dinamis
- Kecerdasan kompetitif untuk tetap terdepan
- Pengelolaan krisis proaktif di media sosial
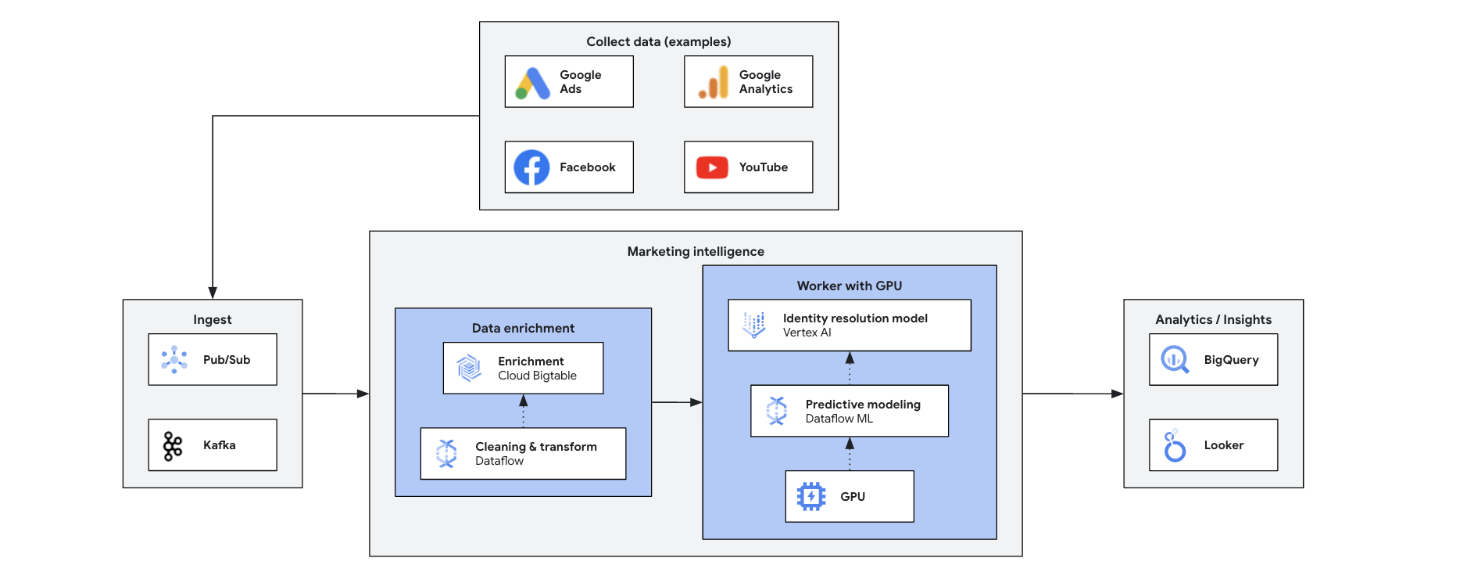
Tutorial, panduan memulai, dan lab
Mentransformasi pemasaran Anda dengan insight real-time
Mentransformasi pemasaran Anda dengan insight real-time
Kecerdasan pemasaran real-time menganalisis data pasar, pelanggan, dan kompetitor saat ini, sehingga keputusan dapat diambil dengan cepat dan tepat. Layanan ini memungkinkan respons yang tangkas terhadap tren, perilaku, dan tindakan kompetitif, sehingga dapat mewujudkan transformasi pemasaran. Manfaatnya meliputi:
- Pemasaran omnichannel real-time dengan penawaran yang dipersonalisasi
- Peningkatan pengelolaan hubungan pelanggan melalui interaksi yang dipersonalisasi
- Pengoptimalan marketing mix yang fleksibel
- Segmentasi pengguna yang dinamis
- Kecerdasan kompetitif untuk tetap terdepan
- Pengelolaan krisis proaktif di media sosial
Analisis clickstream
Mengoptimalkan serta mempersonalisasi pengalaman web dan aplikasi
Mengoptimalkan serta mempersonalisasi pengalaman web dan aplikasi
Analisis clickstream real-time memberdayakan bisnis untuk menganalisis interaksi pengguna di situs dan aplikasi secara langsung. Solusi ini memberikan personalisasi real-time, pengujian A/B, dan pengoptimalan funnel, sehingga dapat meningkatkan interaksi, mempercepat pengembangan produk, mengurangi churn, dan memberikan dukungan produk yang lebih baik. Pada akhirnya, solusi ini memberikan pengalaman pengguna yang istimewa dan mendorong pertumbuhan bisnis melalui harga yang dinamis dan rekomendasi yang dipersonalisasi.
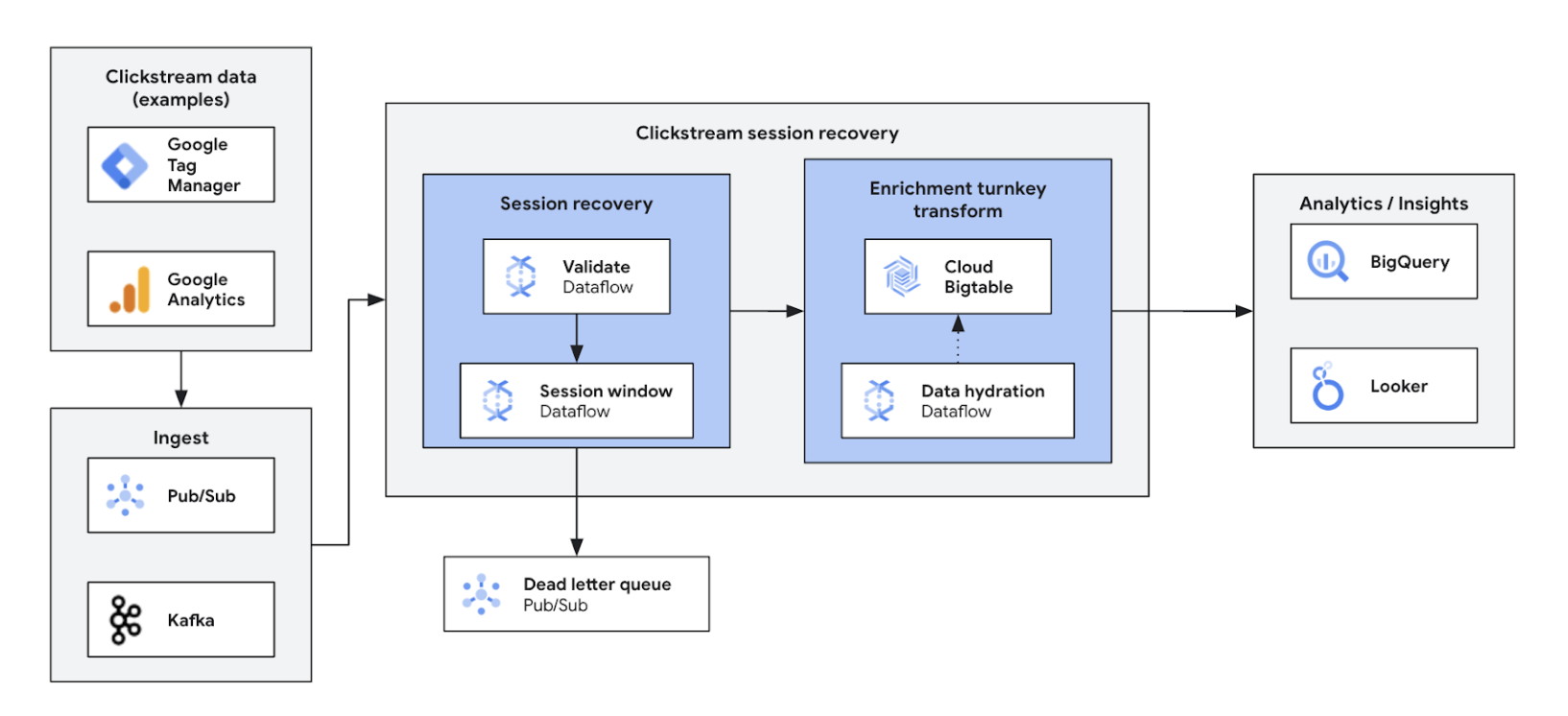
Tutorial, panduan memulai, dan lab
Mengoptimalkan serta mempersonalisasi pengalaman web dan aplikasi
Mengoptimalkan serta mempersonalisasi pengalaman web dan aplikasi
Analisis clickstream real-time memberdayakan bisnis untuk menganalisis interaksi pengguna di situs dan aplikasi secara langsung. Solusi ini memberikan personalisasi real-time, pengujian A/B, dan pengoptimalan funnel, sehingga dapat meningkatkan interaksi, mempercepat pengembangan produk, mengurangi churn, dan memberikan dukungan produk yang lebih baik. Pada akhirnya, solusi ini memberikan pengalaman pengguna yang istimewa dan mendorong pertumbuhan bisnis melalui harga yang dinamis dan rekomendasi yang dipersonalisasi.
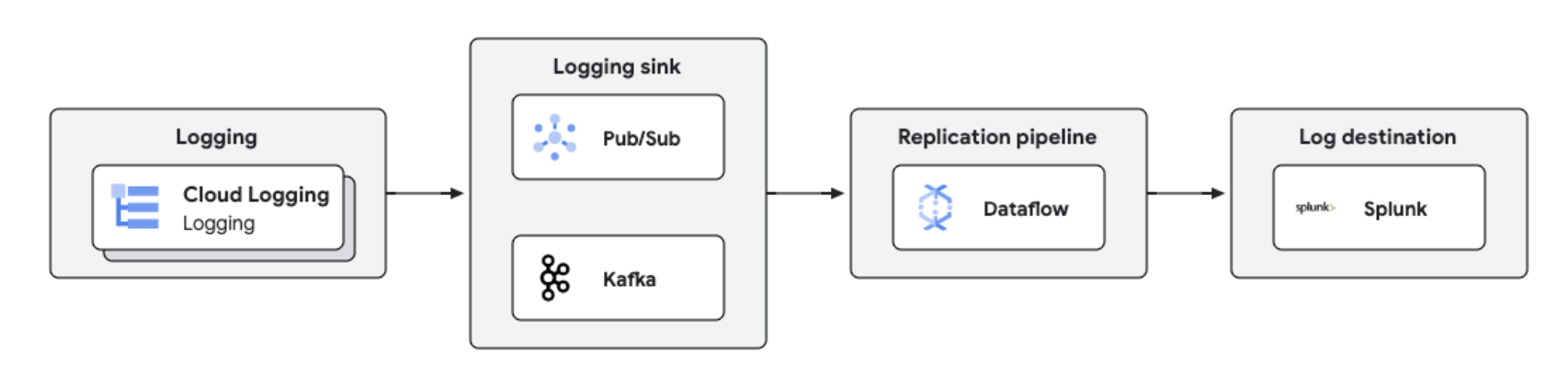
Replikasi dan analisis log secara real-time
Analisis dan pengelolaan log terpusat
Analisis dan pengelolaan log terpusat
Log Google Cloud dapat direplikasi ke platform pihak ketiga seperti Splunk menggunakan Dataflow untuk pemrosesan dan analisis log yang mendekati real-time. Solusi ini menyediakan kemampuan pengelolaan log, kepatuhan, pengauditan, dan analisis terpusat sekaligus mengurangi biaya dan meningkatkan performa.
Tutorial, panduan memulai, dan lab
Analisis dan pengelolaan log terpusat
Analisis dan pengelolaan log terpusat
Log Google Cloud dapat direplikasi ke platform pihak ketiga seperti Splunk menggunakan Dataflow untuk pemrosesan dan analisis log yang mendekati real-time. Solusi ini menyediakan kemampuan pengelolaan log, kepatuhan, pengauditan, dan analisis terpusat sekaligus mengurangi biaya dan meningkatkan performa.
Harga
| Cara kerja penetapan harga Dataflow | Pelajari model penagihan dan resource untuk Dataflow. | |
|---|---|---|
| Layanan dan penggunaan | Deskripsi | Harga |
Resource komputasi Dataflow | Penagihan Dataflow untuk resource komputasi mencakup: | Pelajari lebih lanjut di halaman harga mendetail kami |
Referensi Dataflow lainnya | Resource Dataflow lain yang dikenai biaya untuk semua tugas mencakup Persistent Disk, GPU, dan snapshot. | Pelajari lebih lanjut di halaman harga mendetail kami |
Diskon abonemen (CUD) Dataflow | CUD Dataflow menawarkan dua tingkat diskon, bergantung pada periode komitmen:
| Pelajari CUD Dataflow lebih lanjut |
Pelajari harga Dataflow lebih lanjut. Lihat semua detail penetapan harga.
Cara kerja penetapan harga Dataflow
Pelajari model penagihan dan resource untuk Dataflow.
Resource komputasi Dataflow
Penagihan Dataflow untuk resource komputasi mencakup:
Pelajari lebih lanjut di halaman harga mendetail kami
Referensi Dataflow lainnya
Resource Dataflow lain yang dikenai biaya untuk semua tugas mencakup Persistent Disk, GPU, dan snapshot.
Pelajari lebih lanjut di halaman harga mendetail kami
Diskon abonemen (CUD) Dataflow
CUD Dataflow menawarkan dua tingkat diskon, bergantung pada periode komitmen:
- CUD selama satu tahun memberikan diskon sebesar 20% dari tarif on-demand
- CUD selama tiga tahun memberikan diskon sebesar 40% dari tarif on-demand
Pelajari CUD Dataflow lebih lanjut
Pelajari harga Dataflow lebih lanjut. Lihat semua detail penetapan harga.
Kasus Bisnis
Lihat alasan pelanggan terkemuka memilih Dataflow
Namitha Vijaya Kumar, Product Owner, Google Cloud SRE di ANZ Bank
“Dataflow membantu batch processing dan pemrosesan data real-time kami sehingga menjaga ketepatan waktu data di data lake perusahaan. Hal ini pada akhirnya membantu penggunaan data downstream untuk analisis/pengambilan keputusan dan pengiriman notifikasi real-time bagi pelanggan retail kami.”
Manfaat Dataflow
Streaming ML menjadi mudah
Kemampuan siap pakai untuk menghadirkan streaming ke AI/ML: RunInference untuk inferensi, MLTransform untuk prapemrosesan pelatihan model, Pengayaan untuk pencarian feature store, dan dukungan GPU dinamis, semuanya mengurangi toil tanpa perlu menghabiskan banyak biaya untuk resource GPU yang terbatas.
Performa harga yang optimal dengan alat yang tangguh
Dataflow menawarkan streaming hemat biaya dengan pengoptimalan otomatis guna memaksimalkan performa dan penggunaan resource. Layanan ini dapat diskalakan dengan mudah untuk menangani workload apa pun dan dilengkapi dengan pemulihan mandiri yang didukung oleh teknologi AI. Alat yang tangguh membantu pengoperasian dan pemahaman.
Terbuka, portabel, dan dapat diperluas
Dataflow dibuat untuk Apache Beam open source dengan dukungan streaming dan batch terpadu, sehingga membuat workload Anda menjadi portabel di antara cloud, infrastruktur lokal, atau ke perangkat edge.
Partner & Integrasi




Partner Dataflow
Partner Google Cloud telah mengembangkan integrasi dengan Dataflow untuk menjalankan tugas pemrosesan data dalam berbagai ukuran secara cepat dan mudah. Lihat semua partner untuk memulai perjalanan streaming Anda sekarang.


















