Dataflow
Intelligence des données en temps réel
Maximisez le potentiel de vos données en temps réel. Dataflow est une plate-forme de streaming entièrement gérée, facile à utiliser et évolutive, qui permet d'accélérer la prise de décision en temps réel et l'expérience client.
Les nouveaux clients bénéficient de 300 $ de crédits gratuits à dépenser sur Dataflow.

Fonctionnalités
Utilisez l'IA et le ML de flux pour faire fonctionner des modèles d'IA générative en temps réel
Les données en temps réel alimentent les modèles d'IA/de ML avec les informations les plus récentes, ce qui améliore la précision des prédictions. Dataflow ML simplifie le déploiement et la gestion de pipelines de ML complets. Nous proposons des modèles prêts à l'emploi pour des recommandations personnalisées, la détection des fraudes, la prévention des menaces et plus encore. Créez une IA par flux avec Gemini Enterprise Agent Platform, des modèles Gemini et des modèles Gemma, exécutez des inférences à distance et simplifiez le traitement des données avec MLTransform. Améliorez l'efficacité des jobs MLOps et ML grâce aux GPU Dataflow et aux fonctionnalités d'ajustement adapté.
Gérez des cas d'utilisation avancés des flux de données à l'échelle de l'entreprise
Dataflow est un service entièrement géré qui utilise le SDK Apache Beam Open Source pour permettre des cas d'utilisation avancés de flux de données à l'échelle de l'entreprise. Il offre des fonctionnalités avancées pour l'état et l'heure, les transformations et les connecteurs d'E/S. Dataflow peut évoluer jusqu'à 4 000 nœuds de calcul par job et traiter régulièrement des pétaoctets de données. Il intègre l'autoscaling pour une utilisation optimale des ressources dans les pipelines de traitement par lot et par flux.

Déployer le traitement multimodal des données pour l'IA générative
Dataflow permet l'ingestion et la transformation parallèles de données multimodales telles que des images, du texte et de l'audio. Il applique une extraction de caractéristiques spécialisée pour chaque modalité, puis fusionne ces caractéristiques dans une représentation unifiée. Ces données fusionnées alimentent les modèles d'IA générative, ce qui leur permet de créer des contenus à partir de différentes données. Les équipes internes de Google utilisent Dataflow et FlumeJava pour organiser et calculer les prédictions du modèle pour un vaste pool de données d'entrée disponibles sans aucune exigence en termes de latence.
Accélérez le retour sur investissement avec les modèles et les notebooks
Dataflow inclut des outils qui facilitent la prise en main. Les modèles Dataflow sont des plans prédéfinis pour le traitement en flux continu et par lot. Ils sont optimisés pour l'intégration efficace des données CDC et BigQuery. Créez des pipelines de manière itérative à partir de zéro avec les derniers frameworks de data science dans les notebooks Gemini Enterprise Agent Platform et déployez-les avec l'exécuteur Dataflow.Le générateur de jobs Dataflow est une interface utilisateur visuelle permettant de créer et d'exécuter des pipelines Dataflow dans la console Google Cloud, sans avoir à écrire de code.
Gagnez du temps grâce à des outils intelligents de diagnostic et de surveillance
Dataflow offre des outils complets de diagnostic et de surveillance. La détection des retardataires identifie automatiquement les goulots d'étranglement qui affectent les performances, tandis que l'échantillonnage des données permet d'observer les données à chaque étape du pipeline. Dataflow Insights propose des recommandations pour améliorer les jobs. L'interface utilisateur de Dataflow fournit des outils de surveillance complets, y compris des graphiques des tâches, des détails d'exécution, des métriques, des tableaux de bord d'autoscaling et la journalisation. Dataflow offre également une interface utilisateur de surveillance des coûts des jobs pour estimer facilement les coûts.
Sécurité et gouvernance intégrées
Dataflow vous aide à protéger vos données de plusieurs façons : en chiffrant les données utilisées grâce à la compatibilité avec les Confidential VM ; les clés de chiffrement gérées par le client (CMEK) ; l'intégration de VPC Service Controls, en désactivant les adresses IP publiques. Les journaux d'audit Dataflow offrent à votre organisation une visibilité sur l'utilisation de Dataflow et permettent de savoir qui a fait quoi, où et quand, pour une meilleure gouvernance.
Fonctionnement
Dataflow est une plate-forme entièrement gérée pour le traitement des données par lot et par flux. Il permet d'utiliser des pipelines ETL évolutifs, des analyses de flux en temps réel, du ML en temps réel et des transformations de données complexes à l'aide du modèle unifié Apache Beam, le tout sur une infrastructure Google Cloud sans serveur.
Dataflow est une plate-forme entièrement gérée pour le traitement des données par lot et par flux. Il permet d'utiliser des pipelines ETL évolutifs, des analyses de flux en temps réel, du ML en temps réel et des transformations de données complexes à l'aide du modèle unifié Apache Beam, le tout sur une infrastructure Google Cloud sans serveur.

Analyse en temps réel
Intégrez des flux de données pour l'analyse en temps réel et les pipelines opérationnels
Intégrez des flux de données pour l'analyse en temps réel et les pipelines opérationnels
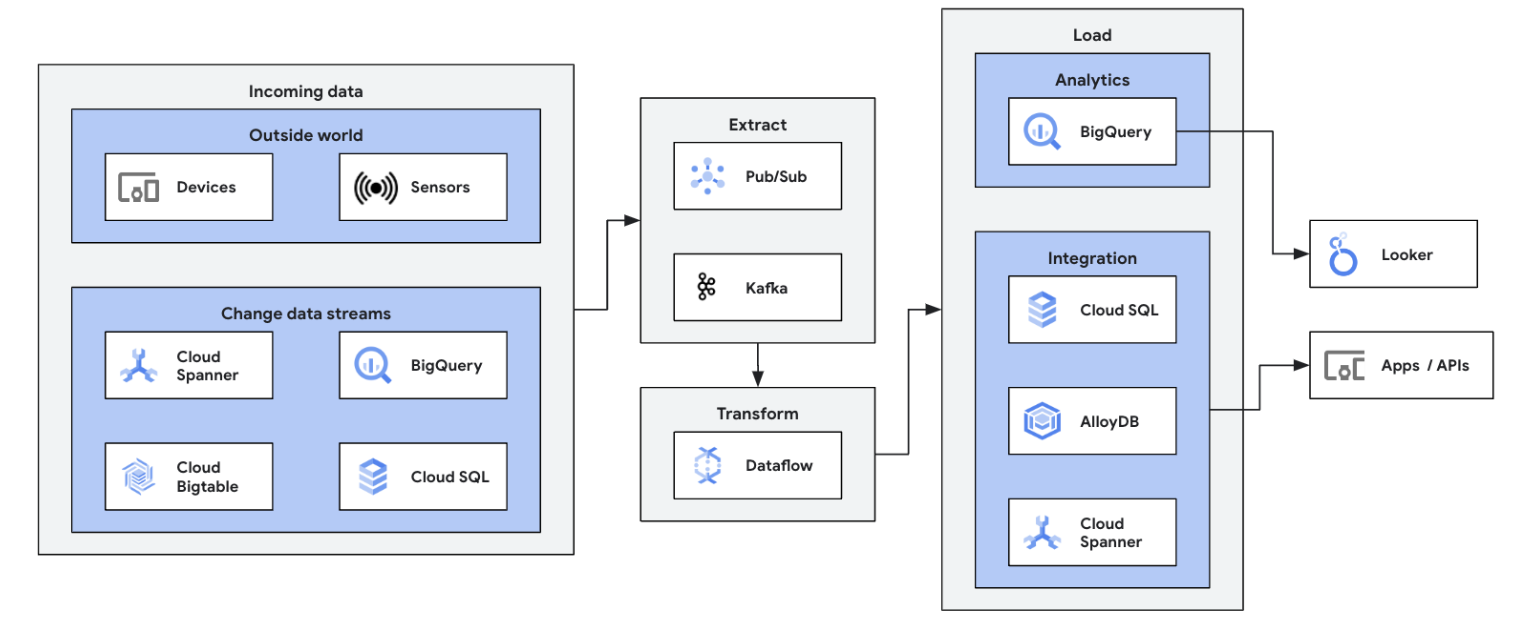
Pour commencer votre transition vers le streaming de données, intégrez vos sources de flux de données (Pub/Sub, Kafka, événements CDC, flux de clics utilisateur, journaux et données de capteurs) dans BigQuery, les lacs de données Google Cloud Storage, Spanner, Bigtable, les magasins SQL, Splunk, Datadog, etc. Explorez les modèles Dataflow optimisés pour configurer vos pipelines en quelques clics, sans code. Ajoutez une logique personnalisée à vos modèles de tâches grâce au compilateur UDF intégré ou créez des pipelines ETL personnalisés de A à Z, en profitant de la puissance des transformations Beam et de l'écosystème de connecteurs d'E/S. Dataflow est également couramment utilisé pour inverser les données traitées par ETL de BigQuery vers les magasins OLTP afin d'accélérer les recherches et de servir les utilisateurs finaux. Dataflow est un modèle courant d'écriture de flux de données dans plusieurs emplacements de stockage.

Lancez votre première tâche Dataflow et suivez notre formation autoguidée sur les principes de base de Dataflow.
Tutoriels, guides de démarrage rapide et ateliers
Intégrez des flux de données pour l'analyse en temps réel et les pipelines opérationnels
Intégrez des flux de données pour l'analyse en temps réel et les pipelines opérationnels
Pour commencer votre transition vers le streaming de données, intégrez vos sources de flux de données (Pub/Sub, Kafka, événements CDC, flux de clics utilisateur, journaux et données de capteurs) dans BigQuery, les lacs de données Google Cloud Storage, Spanner, Bigtable, les magasins SQL, Splunk, Datadog, etc. Explorez les modèles Dataflow optimisés pour configurer vos pipelines en quelques clics, sans code. Ajoutez une logique personnalisée à vos modèles de tâches grâce au compilateur UDF intégré ou créez des pipelines ETL personnalisés de A à Z, en profitant de la puissance des transformations Beam et de l'écosystème de connecteurs d'E/S. Dataflow est également couramment utilisé pour inverser les données traitées par ETL de BigQuery vers les magasins OLTP afin d'accélérer les recherches et de servir les utilisateurs finaux. Dataflow est un modèle courant d'écriture de flux de données dans plusieurs emplacements de stockage.
Lancez votre première tâche Dataflow et suivez notre formation autoguidée sur les principes de base de Dataflow.
ETL en temps réel et intégration de données
Modernisez votre plate-forme de données avec des données en temps réel
Modernisez votre plate-forme de données avec des données en temps réel
Processus d'ETL et d'intégration en temps réel et écriture immédiate des données, permettant une analyse et une prise de décision rapides. L'architecture sans serveur et les fonctionnalités de traitement de flux de Dataflow en font un outil idéal pour créer des pipelines ETL en temps réel. La fonctionnalité d'autoscaling de Dataflow garantit l'efficacité et le scaling, tandis que sa compatibilité avec diverses sources et destinations de données simplifie l'intégration.
Familiarisez-vous avec le traitement par lot sur Dataflow en suivant ce cours Google Cloud Skills Boost.
Tutoriels, guides de démarrage rapide et ateliers
Modernisez votre plate-forme de données avec des données en temps réel
Modernisez votre plate-forme de données avec des données en temps réel
Processus d'ETL et d'intégration en temps réel et écriture immédiate des données, permettant une analyse et une prise de décision rapides. L'architecture sans serveur et les fonctionnalités de traitement de flux de Dataflow en font un outil idéal pour créer des pipelines ETL en temps réel. La fonctionnalité d'autoscaling de Dataflow garantit l'efficacité et le scaling, tandis que sa compatibilité avec diverses sources et destinations de données simplifie l'intégration.
Familiarisez-vous avec le traitement par lot sur Dataflow en suivant ce cours Google Cloud Skills Boost.
ML et IA générative en temps réel
Agissez en temps réel avec des flux de ML/IA
Agissez en temps réel avec des flux de ML/IA
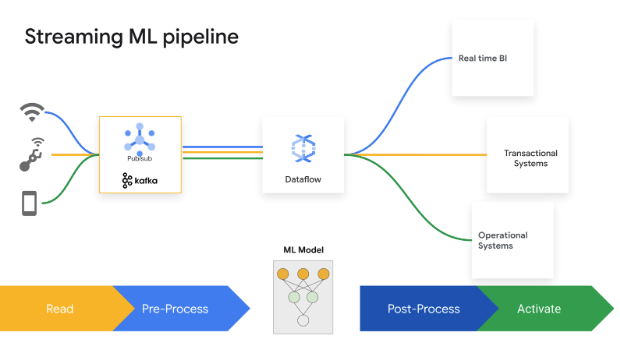
Les décisions de partage de secondes génèrent de la valeur commerciale. Dataflow Streaming AI et ML permettent aux clients d'implémenter des prédictions et des inférences à faible latence, une personnalisation en temps réel, la détection des menaces, la prévention des fraudes et bien d'autres cas d'utilisation où la Threat Intelligence est essentielle. Prétraiter des données avec MLTransform, qui vous permet de vous concentrer sur la transformation de vos données sans avoir à écrire du code complexe ou à gérer les bibliothèques sous-jacentes. Effectuez des prédictions sur votre modèle d'IA générative à l'aide de RunInference.
Tutoriels, guides de démarrage rapide et ateliers
Agissez en temps réel avec des flux de ML/IA
Agissez en temps réel avec des flux de ML/IA
Les décisions de partage de secondes génèrent de la valeur commerciale. Dataflow Streaming AI et ML permettent aux clients d'implémenter des prédictions et des inférences à faible latence, une personnalisation en temps réel, la détection des menaces, la prévention des fraudes et bien d'autres cas d'utilisation où la Threat Intelligence est essentielle. Prétraiter des données avec MLTransform, qui vous permet de vous concentrer sur la transformation de vos données sans avoir à écrire du code complexe ou à gérer les bibliothèques sous-jacentes. Effectuez des prédictions sur votre modèle d'IA générative à l'aide de RunInference.
Marketing Intelligence
Transformez votre stratégie marketing grâce à des insights en temps réel
Transformez votre stratégie marketing grâce à des insights en temps réel
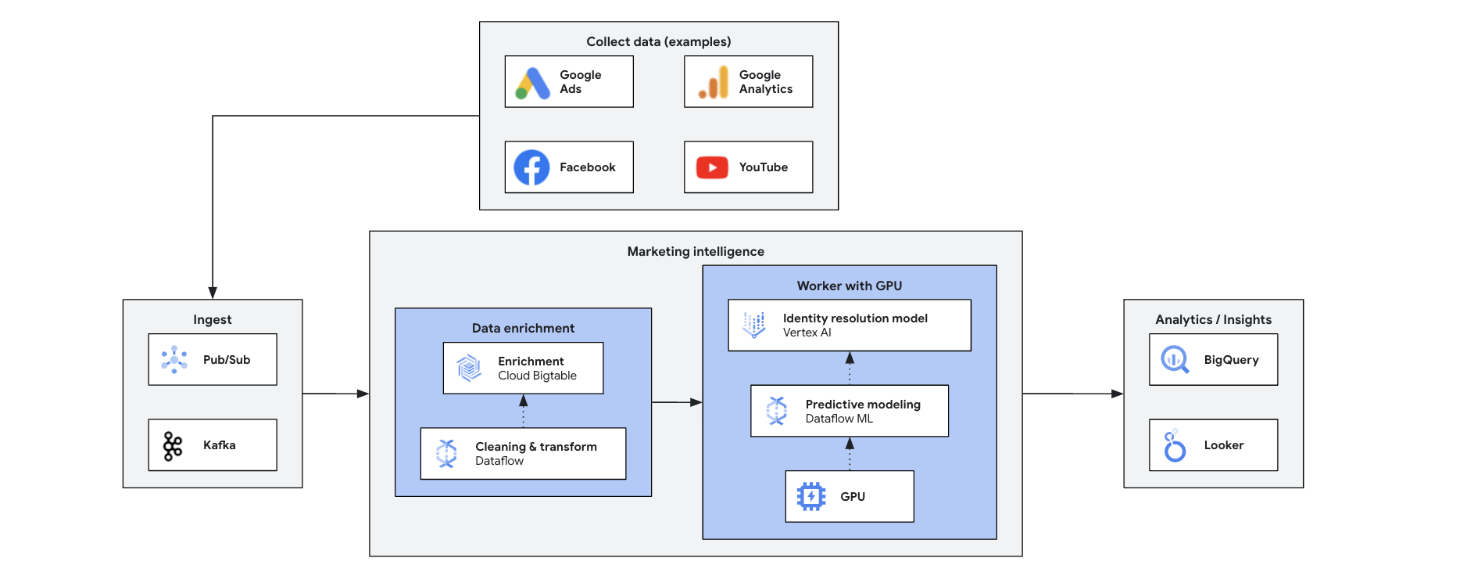
La Marketing Intelligence en temps réel analyse les données actuelles du marché, des clients et des concurrents afin de prendre des décisions rapides et éclairées. Elle permet de répondre avec agilité aux tendances, aux comportements et aux actions concurrentielles, transformant le marketing. Voici quelques-uns de ses avantages :
- Marketing omnicanal en temps réel avec des offres personnalisées
- Amélioration de la gestion de la relation client grâce à des interactions personnalisées
- Optimisation du mix marketing agile
- Segmentation dynamique des utilisateurs
- Intelligence concurrentielle pour garder une longueur d'avance
- Gestion de crise proactive sur les réseaux sociaux
Tutoriels, guides de démarrage rapide et ateliers
Transformez votre stratégie marketing grâce à des insights en temps réel
Transformez votre stratégie marketing grâce à des insights en temps réel
La Marketing Intelligence en temps réel analyse les données actuelles du marché, des clients et des concurrents afin de prendre des décisions rapides et éclairées. Elle permet de répondre avec agilité aux tendances, aux comportements et aux actions concurrentielles, transformant le marketing. Voici quelques-uns de ses avantages :
- Marketing omnicanal en temps réel avec des offres personnalisées
- Amélioration de la gestion de la relation client grâce à des interactions personnalisées
- Optimisation du mix marketing agile
- Segmentation dynamique des utilisateurs
- Intelligence concurrentielle pour garder une longueur d'avance
- Gestion de crise proactive sur les réseaux sociaux
Analyse de flux de clics
Optimiser et personnaliser les expériences sur le Web et dans les applications
Optimiser et personnaliser les expériences sur le Web et dans les applications
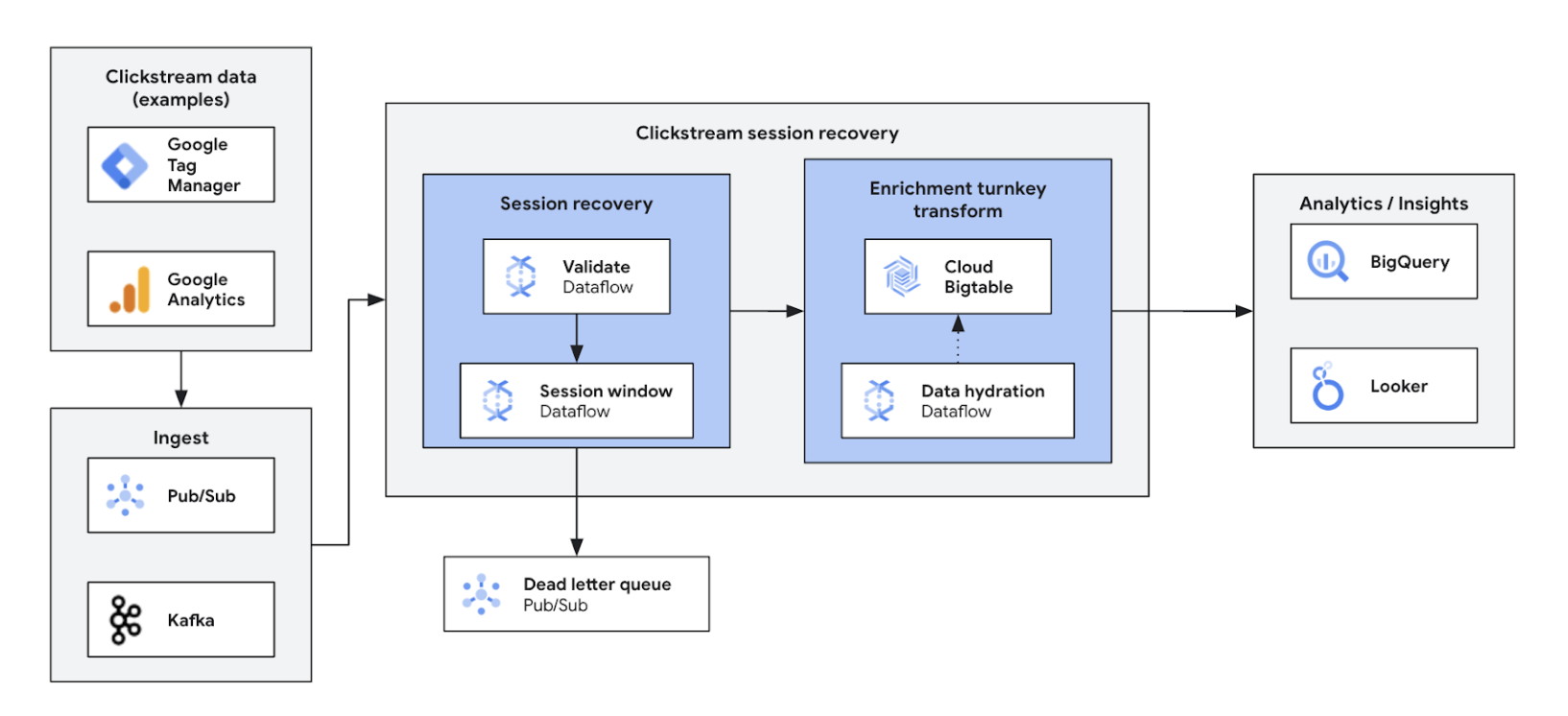
Grâce à l'analyse des flux de clics en temps réel, les entreprises peuvent analyser instantanément les interactions des utilisateurs sur les sites Web et les applications. Vous bénéficiez ainsi de la personnalisation en temps réel, des tests A/B et de l'optimisation de l'entonnoir, ce qui permet d'accroître l'engagement, d'accélérer le développement de produits, de réduire la perte d'utilisateurs et d'améliorer l'assistance produit. En fin de compte, elle offre une expérience utilisateur de qualité supérieure et stimule la croissance de l'activité grâce à une tarification dynamique et à des recommandations personnalisées.
Tutoriels, guides de démarrage rapide et ateliers
Optimiser et personnaliser les expériences sur le Web et dans les applications
Optimiser et personnaliser les expériences sur le Web et dans les applications
Grâce à l'analyse des flux de clics en temps réel, les entreprises peuvent analyser instantanément les interactions des utilisateurs sur les sites Web et les applications. Vous bénéficiez ainsi de la personnalisation en temps réel, des tests A/B et de l'optimisation de l'entonnoir, ce qui permet d'accroître l'engagement, d'accélérer le développement de produits, de réduire la perte d'utilisateurs et d'améliorer l'assistance produit. En fin de compte, elle offre une expérience utilisateur de qualité supérieure et stimule la croissance de l'activité grâce à une tarification dynamique et à des recommandations personnalisées.
Réplication et analyse des journaux en temps réel
Gestion et analyse centralisées des journaux
Gestion et analyse centralisées des journaux
Les journaux Google Cloud peuvent être répliqués vers des plates-formes tierces comme Splunk à l'aide de Dataflow, pour un traitement et une analyse des journaux en temps quasi réel. Cette solution offre des fonctionnalités centralisées de gestion des journaux, de conformité, d'audit et d'analyse, tout en réduisant les coûts et en améliorant les performances.
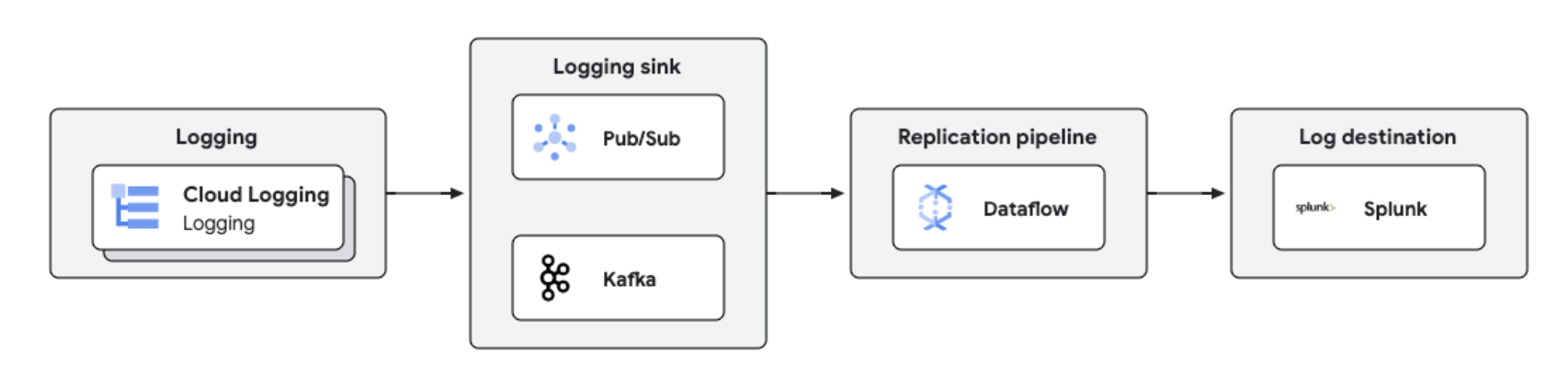
Tutoriels, guides de démarrage rapide et ateliers
Gestion et analyse centralisées des journaux
Gestion et analyse centralisées des journaux
Les journaux Google Cloud peuvent être répliqués vers des plates-formes tierces comme Splunk à l'aide de Dataflow, pour un traitement et une analyse des journaux en temps quasi réel. Cette solution offre des fonctionnalités centralisées de gestion des journaux, de conformité, d'audit et d'analyse, tout en réduisant les coûts et en améliorant les performances.
Tarification
| Fonctionnement des tarifs de Dataflow | Explorer le modèle de facturation et de ressources de Dataflow | |
|---|---|---|
| Services et utilisation | Description | Tarification |
Ressources de calcul Dataflow | La facturation Dataflow pour les ressources de calcul inclut les éléments suivants : | Pour en savoir plus, consultez la page des tarifs détaillée. |
Autres ressources Dataflow | Les autres ressources Dataflow facturées pour l'ensemble des jobs incluent les disques persistants, les GPU et les instantanés. | Pour en savoir plus, consultez la page des tarifs détaillée. |
Remises sur engagement d'utilisation Dataflow | Les remises sur engagement d'utilisation Dataflow offrent deux niveaux de remises, en fonction de la période d'engagement :
| En savoir plus sur les remise sur engagement d'utilisation de Dataflow |
En savoir plus sur les tarifs de Dataflow. Afficher le détail des tarifs
Fonctionnement des tarifs de Dataflow
Explorer le modèle de facturation et de ressources de Dataflow
Ressources de calcul Dataflow
La facturation Dataflow pour les ressources de calcul inclut les éléments suivants :
Pour en savoir plus, consultez la page des tarifs détaillée.
Autres ressources Dataflow
Les autres ressources Dataflow facturées pour l'ensemble des jobs incluent les disques persistants, les GPU et les instantanés.
Pour en savoir plus, consultez la page des tarifs détaillée.
Remises sur engagement d'utilisation Dataflow
Les remises sur engagement d'utilisation Dataflow offrent deux niveaux de remises, en fonction de la période d'engagement :
- Une remise sur engagement d'utilisation d'un an vous permet de bénéficier d'une remise de 20 % par rapport au tarif à la demande
- Une remise sur engagement d'utilisation de trois ans vous permet de bénéficier d'une remise de 40 % par rapport au tarif à la demande
En savoir plus sur les remise sur engagement d'utilisation de Dataflow
En savoir plus sur les tarifs de Dataflow. Afficher le détail des tarifs
Cas d'utilisation métier
Découvrez pourquoi les principaux clients choisissent Dataflow
Namitha Vijaya Kumar, Product Owner, ingénierie SRE Google Cloud chez ANZ Bank
"Dataflow facilite le traitement par lot et le traitement des données en temps réel, garantissant ainsi la disponibilité en temps opportun des données dans le lac de données d'entreprise. Cela facilite l'utilisation des données en aval pour l'analyse/la prise de décision et l'envoi de notifications en temps réel à nos clients retail."
Contenu associé
Google a été reconnu par les pairs comme choix du client pour le traitement par flux d'événements
Télécharger le rapport
Exploiter la puissance du ML pour les flux de données avec Spotify
Regarder la vidéo
Yahoo compare Dataflow à l'outil Apache Flink autogéré pour deux cas d'utilisation de flux de données
Lire l'article
Avantages de Dataflow
Le streaming de ML en toute simplicité
Les fonctionnalités clé en main qui permettent d'intégrer les flux de données à l'IA et au ML : RunInference pour l'inférence, MLTransform pour le prétraitement de l'entraînement de modèle, l'enrichissement pour la recherche dans les magasins de caractéristiques et la compatibilité dynamique avec les GPU, autant d'éléments qui réduisent les tâches répétitives et évitent les dépenses inutiles pour des ressources GPU limitées.
Rapport prix/performances optimal et outils robustes
Dataflow offre des flux économiques avec optimisation automatisée pour maximiser les performances et l'utilisation des ressources. Il évolue facilement pour gérer n'importe quelle charge de travail et dispose d'une autoréparation basée sur l'IA. Des outils robustes facilitent les opérations et facilitent la compréhension.
Ouvert, portable et extensible
Conçu pour la solution Open Source Apache Beam, Dataflow offre une compatibilité unifiée avec les traitements par lot et par flux, ce qui permet de transférer vos charges de travail entre des clouds, des environnements sur site ou des appareils de périphérie.
Partenaires et intégration




Partenaires Dataflow
Les partenaires Google Cloud ont mis au point des intégrations à Dataflow pour vous permettre d'exécuter rapidement et facilement de puissantes tâches de traitement de données complexes de n'importe quelle taille. Découvrez tous les partenaires pour commencer à diffuser des contenus en streaming dès aujourd'hui.


















