Dataflow
Datenanalyse in Echtzeit
Maximieren Sie das Potenzial Ihrer Echtzeitdaten. Dataflow ist eine vollständig verwaltete Streamingplattform, die einfach zu bedienen und skalierbar ist, um die Entscheidungsfindung in Echtzeit und die Kundenerfahrung zu beschleunigen.
Neukunden erhalten ein Guthaben im Wert von 300 $ für Dataflow.

Features
KI- und ML-Streaming für generative KI-Modelle in Echtzeit nutzen
Echtzeitdaten versorgen KI-/ML-Modelle mit den neuesten Informationen und verbessern so die Genauigkeit von Vorhersagen. Dataflow ML vereinfacht die Bereitstellung und Verwaltung vollständiger ML-Pipelines. Wir bieten gebrauchsfertige Muster für personalisierte Empfehlungen, Betrugserkennung, Bedrohungsabwehr und mehr. Erstellen Sie eine Streaming-KI mit der Gemini Enterprise Agent Platform, Gemini- und Gemma-Modellen, führen Sie Remote-Inferenzen aus und optimieren Sie die Datenverarbeitung mit MLTransform. Mit Dataflow-GPUs und passenden Funktionen können Sie MLOps und die Effizienz von ML-Jobs verbessern.
Erweiterte Streaming-Anwendungsfälle für Unternehmen ermöglichen
Dataflow ist ein vollständig verwalteter Dienst, der das Open-Source-Apache Beam SDK verwendet, um erweiterte Streaming-Anwendungsfälle im Unternehmen zu ermöglichen. Es bietet umfassende Funktionen für Status und Zeit, Transformationen und E/A-Connectors. Dataflow lässt sich auf 4.000 Worker pro Job skalieren und verarbeitet regelmäßig Petabyte an Daten. Die Funktion bietet Autoscaling für eine optimale Ressourcennutzung in Batch- und Streamingpipelines.

Multimodale Datenverarbeitung für generative KI bereitstellen
Dataflow ermöglicht die parallele Aufnahme und Transformation multimodaler Daten, darunter Bilder, Texte und Audio. Dabei wird für jede Modalität eine spezielle Featureextraktion angewendet. Diese Features werden dann zu einer einheitlichen Darstellung zusammengeführt. Diese zusammengeführten Datenfeeds speisen generative KI-Modelle, um aus diversen Eingaben neue Inhalte zu erstellen. Interne Google-Teams nutzen Dataflow und FlumeJava, um Modellvorhersagen für einen großen Pool verfügbarer Eingabedaten ohne Latenzanforderungen zu organisieren und zu berechnen.
Mit Vorlagen und Notebooks die Wertschöpfung beschleunigen
Dataflow bietet Tools, die den Einstieg erleichtern. Dataflow-Vorlagen sind vordefinierte Blaupausen für die Stream- und Batchverarbeitung und für eine effiziente CDC- und BigQuery-Datenintegration optimiert. Mit Gemini Enterprise Agent Platform Notebooks können Sievon Grund auf Pipelines mit den neuesten Data-Science-Frameworks erstellen und sie mit dem Dataflow-Runner bereitstellen.Der Dataflow Job Builder ist eine visuelle Benutzeroberfläche zum Erstellen und Ausführen von Dataflow-Pipelines in der Google Cloud Console, ohne Code schreiben zu müssen.
Mit intelligenten Diagnose- und Überwachungstools Zeit sparen
Dataflow bietet umfassende Diagnose- und Monitoringtools. Die Straggler-Erkennung erkennt Leistungsengpässe automatisch, während die Stichprobenerhebung die Beobachtung von Daten bei jedem Pipelineschritt ermöglicht. Dataflow Insights bieten Empfehlungen für Jobverbesserungen. Die Dataflow-UI bietet umfangreiche Monitoringtools wie Jobdiagramme, Ausführungsdetails, Messwerte, Autoscaling-Dashboards und Logging. Dataflow bietet zur einfachen Kostenschätzung auch eine UI zur Überwachung der Jobkosten.
Integrierte Governance und Sicherheit
Mit Dataflow können Sie Ihre Daten auf verschiedene Arten schützen: Verschlüsselung aktiver Daten mit vertraulichem VM-Support; kundenverwaltete Verschlüsselungsschlüssel (CMEKs); Einbindung von VPC Service Controls; öffentliche IP-Adressen deaktivieren. Dataflow-Audit-Logging bietet Ihrer Organisation Einblick in die Dataflow-Nutzung und hilft bei der Beantwortung der Frage "Wer hat was, wo und wann getan?", für eine bessere Governance ermöglicht.
Funktionsweise
Dataflow ist eine vollständig verwaltete Plattform für die Verarbeitung von Batch- und Streamingdaten. Es ermöglicht skalierbare ETL-Pipelines, Streamanalysen in Echtzeit, ML in Echtzeit und komplexe Datentransformationen mit dem einheitlichen Modell von Apache Beam – alles auf einer serverlosen Google Cloud-Infrastruktur.
Dataflow ist eine vollständig verwaltete Plattform für die Verarbeitung von Batch- und Streamingdaten. Es ermöglicht skalierbare ETL-Pipelines, Streamanalysen in Echtzeit, ML in Echtzeit und komplexe Datentransformationen mit dem einheitlichen Modell von Apache Beam – alles auf einer serverlosen Google Cloud-Infrastruktur.

Echtzeitanalysen
Streamingdaten für Echtzeitanalysen und Betriebspipelines einbinden
Streamingdaten für Echtzeitanalysen und Betriebspipelines einbinden
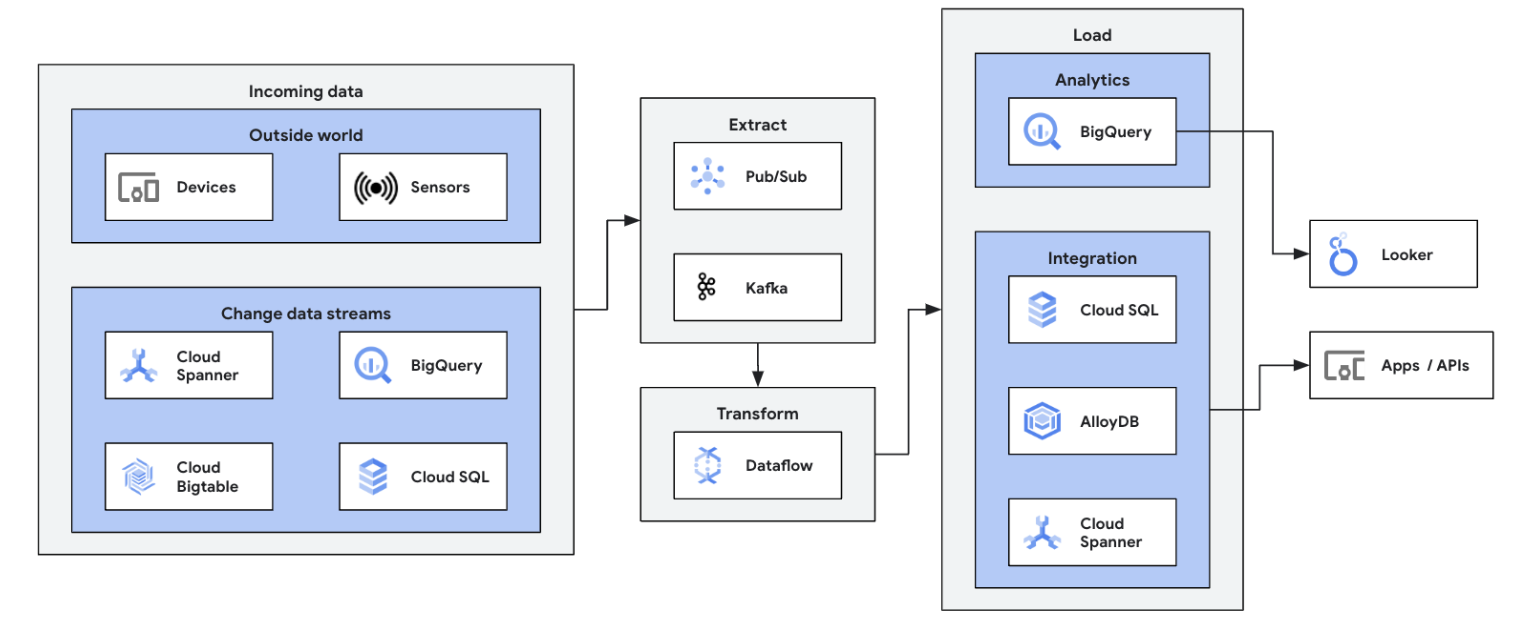
Machen Sie Ihre ersten Schritte in Sachen Datenstreaming, indem Sie Streaming-Datenquellen (Pub/Sub, Kafka, CDC-Ereignisse, Nutzer-Clickstreams, Logs und Sensordaten) in BigQuery, Google Cloud Storage Data Lakes, Spanner, Bigtable, SQL-Speicher, Splunk, Datadog und mehr einbinden. Nutzen Sie optimierte Dataflow-Vorlagen, um Pipelines mit wenigen Klicks und ohne Code einzurichten. Fügen Sie Ihren Vorlagenjobs mit dem integrierten UDF-Builder benutzerdefinierte Logik hinzu oder erstellen Sie benutzerdefinierte ETL-Pipelines von Grund auf mithilfe der Möglichkeiten von Beam-Transformationen und dem Ökosystem der E/A-Connectors. Dataflow wird auch häufig verwendet, um ETL-verarbeitete Daten von BigQuery zurück in OLTP-Speichern wiederherzustellen für schnelle Abfragen und die Bereitstellung für Endnutzer. Es ist ein gängiges Dataflow-Muster, Streamingdaten in mehrere Speicherorte zu schreiben.

Starten Sie Ihren ersten Dataflow-Job und nehmen Sie an unserem interaktiven Kurs zu den Dataflow-Grundlagen teil.
Tutorials, Kurzanleitungen und Labs
Streamingdaten für Echtzeitanalysen und Betriebspipelines einbinden
Streamingdaten für Echtzeitanalysen und Betriebspipelines einbinden
Machen Sie Ihre ersten Schritte in Sachen Datenstreaming, indem Sie Streaming-Datenquellen (Pub/Sub, Kafka, CDC-Ereignisse, Nutzer-Clickstreams, Logs und Sensordaten) in BigQuery, Google Cloud Storage Data Lakes, Spanner, Bigtable, SQL-Speicher, Splunk, Datadog und mehr einbinden. Nutzen Sie optimierte Dataflow-Vorlagen, um Pipelines mit wenigen Klicks und ohne Code einzurichten. Fügen Sie Ihren Vorlagenjobs mit dem integrierten UDF-Builder benutzerdefinierte Logik hinzu oder erstellen Sie benutzerdefinierte ETL-Pipelines von Grund auf mithilfe der Möglichkeiten von Beam-Transformationen und dem Ökosystem der E/A-Connectors. Dataflow wird auch häufig verwendet, um ETL-verarbeitete Daten von BigQuery zurück in OLTP-Speichern wiederherzustellen für schnelle Abfragen und die Bereitstellung für Endnutzer. Es ist ein gängiges Dataflow-Muster, Streamingdaten in mehrere Speicherorte zu schreiben.
Starten Sie Ihren ersten Dataflow-Job und nehmen Sie an unserem interaktiven Kurs zu den Dataflow-Grundlagen teil.
ETL in Echtzeit und Datenintegration
Datenplattform mit Echtzeitdaten modernisieren
Datenplattform mit Echtzeitdaten modernisieren
ETL- und Integrationsprozess in Echtzeit und sofortiges Schreiben von Daten, was eine schnelle Analyse und Entscheidungsfindung ermöglicht. Die serverlose Architektur und die Streamingfunktionen von Dataflow machen es ideal zum Erstellen von ETL-Pipelines in Echtzeit. Die Autoscaling-Funktion von Dataflow sorgt für Effizienz und Skalierung, während die Einbindung verschiedener Datenquellen und -ziele vereinfacht wird.
Vertiefen Sie Ihre Grundlagen mit der Batchverarbeitung in Dataflow in diesem Google Cloud Skills Boost-Kurs.
Tutorials, Kurzanleitungen und Labs
Datenplattform mit Echtzeitdaten modernisieren
Datenplattform mit Echtzeitdaten modernisieren
ETL- und Integrationsprozess in Echtzeit und sofortiges Schreiben von Daten, was eine schnelle Analyse und Entscheidungsfindung ermöglicht. Die serverlose Architektur und die Streamingfunktionen von Dataflow machen es ideal zum Erstellen von ETL-Pipelines in Echtzeit. Die Autoscaling-Funktion von Dataflow sorgt für Effizienz und Skalierung, während die Einbindung verschiedener Datenquellen und -ziele vereinfacht wird.
Vertiefen Sie Ihre Grundlagen mit der Batchverarbeitung in Dataflow in diesem Google Cloud Skills Boost-Kurs.
ML und generative KI in Echtzeit
Mit gestreamtem ML/KI in Echtzeit reagieren
Mit gestreamtem ML/KI in Echtzeit reagieren
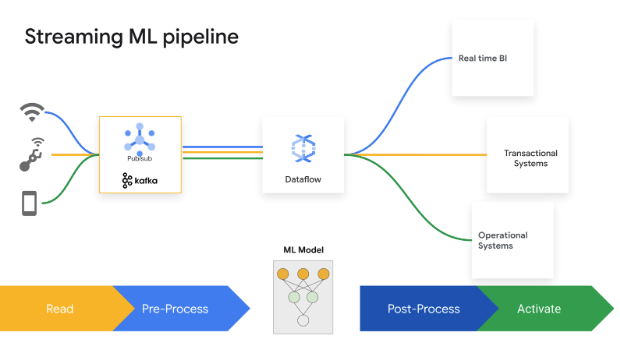
Durch Split-Second-Entscheidungen Mehrwerte erzielen. Mit Dataflow Streaming AI und ML können Kunden Vorhersagen und Inferenzen mit niedriger Latenz, Personalisierung in Echtzeit, Bedrohungserkennung, Betrugsprävention und viele weitere Anwendungsfälle implementieren, bei denen Echtzeitinformationen wichtig sind. Durch die Vorverarbeitung von Daten mit MLTransform können Sie sich auf die Transformation Ihrer Daten konzentrieren und müssen weder komplexen Code schreiben noch zugrunde liegende Bibliotheken verwalten. Mit RunInference können Sie Vorhersagen für Ihr Generative-AI-Modell treffen.
Tutorials, Kurzanleitungen und Labs
Mit gestreamtem ML/KI in Echtzeit reagieren
Mit gestreamtem ML/KI in Echtzeit reagieren
Durch Split-Second-Entscheidungen Mehrwerte erzielen. Mit Dataflow Streaming AI und ML können Kunden Vorhersagen und Inferenzen mit niedriger Latenz, Personalisierung in Echtzeit, Bedrohungserkennung, Betrugsprävention und viele weitere Anwendungsfälle implementieren, bei denen Echtzeitinformationen wichtig sind. Durch die Vorverarbeitung von Daten mit MLTransform können Sie sich auf die Transformation Ihrer Daten konzentrieren und müssen weder komplexen Code schreiben noch zugrunde liegende Bibliotheken verwalten. Mit RunInference können Sie Vorhersagen für Ihr Generative-AI-Modell treffen.
Marketing Intelligence
Marketing mit Echtzeitinformationen transformieren
Marketing mit Echtzeitinformationen transformieren
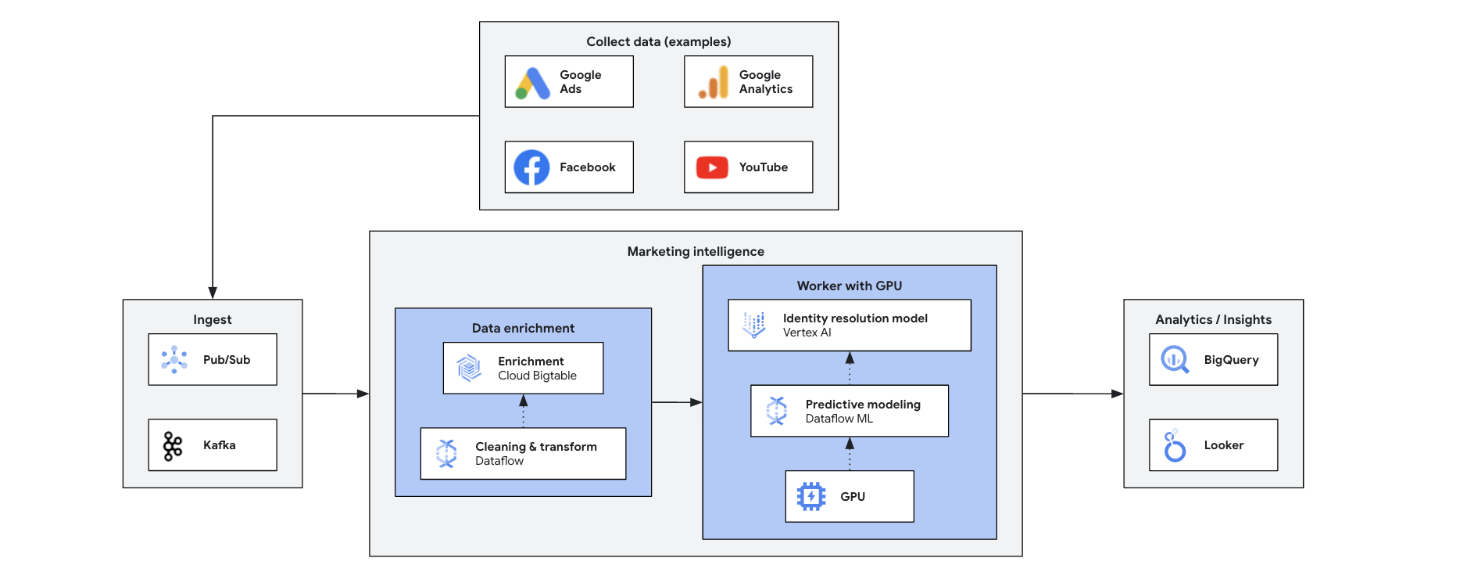
Marketing Intelligence in Echtzeit analysiert aktuelle Markt-, Kunden- und Mitbewerberdaten, um schnelle, fundierte Entscheidungen zu ermöglichen. Sie ermöglicht agile Reaktionen auf Trends, Verhaltensweisen und Wettbewerbsaktionen und transformiert das Marketing. Dies sind die wichtigsten Vorteile:
- Omni-Channel-Marketing in Echtzeit mit personalisierten Angeboten
- Verbessertes Customer-Relationship-Management durch personalisierte Interaktionen
- Agile Optimierung des Marketing-Mix
- Dynamische Nutzersegmentierung
- Wettbewerbsanalyse, um den Vorsprung zu halten
- Proaktives Krisenmanagement in den sozialen Medien
Tutorials, Kurzanleitungen und Labs
Marketing mit Echtzeitinformationen transformieren
Marketing mit Echtzeitinformationen transformieren
Marketing Intelligence in Echtzeit analysiert aktuelle Markt-, Kunden- und Mitbewerberdaten, um schnelle, fundierte Entscheidungen zu ermöglichen. Sie ermöglicht agile Reaktionen auf Trends, Verhaltensweisen und Wettbewerbsaktionen und transformiert das Marketing. Dies sind die wichtigsten Vorteile:
- Omni-Channel-Marketing in Echtzeit mit personalisierten Angeboten
- Verbessertes Customer-Relationship-Management durch personalisierte Interaktionen
- Agile Optimierung des Marketing-Mix
- Dynamische Nutzersegmentierung
- Wettbewerbsanalyse, um den Vorsprung zu halten
- Proaktives Krisenmanagement in den sozialen Medien
Clickstream-Analyse
Web- und App-Nutzung optimieren und personalisieren
Web- und App-Nutzung optimieren und personalisieren
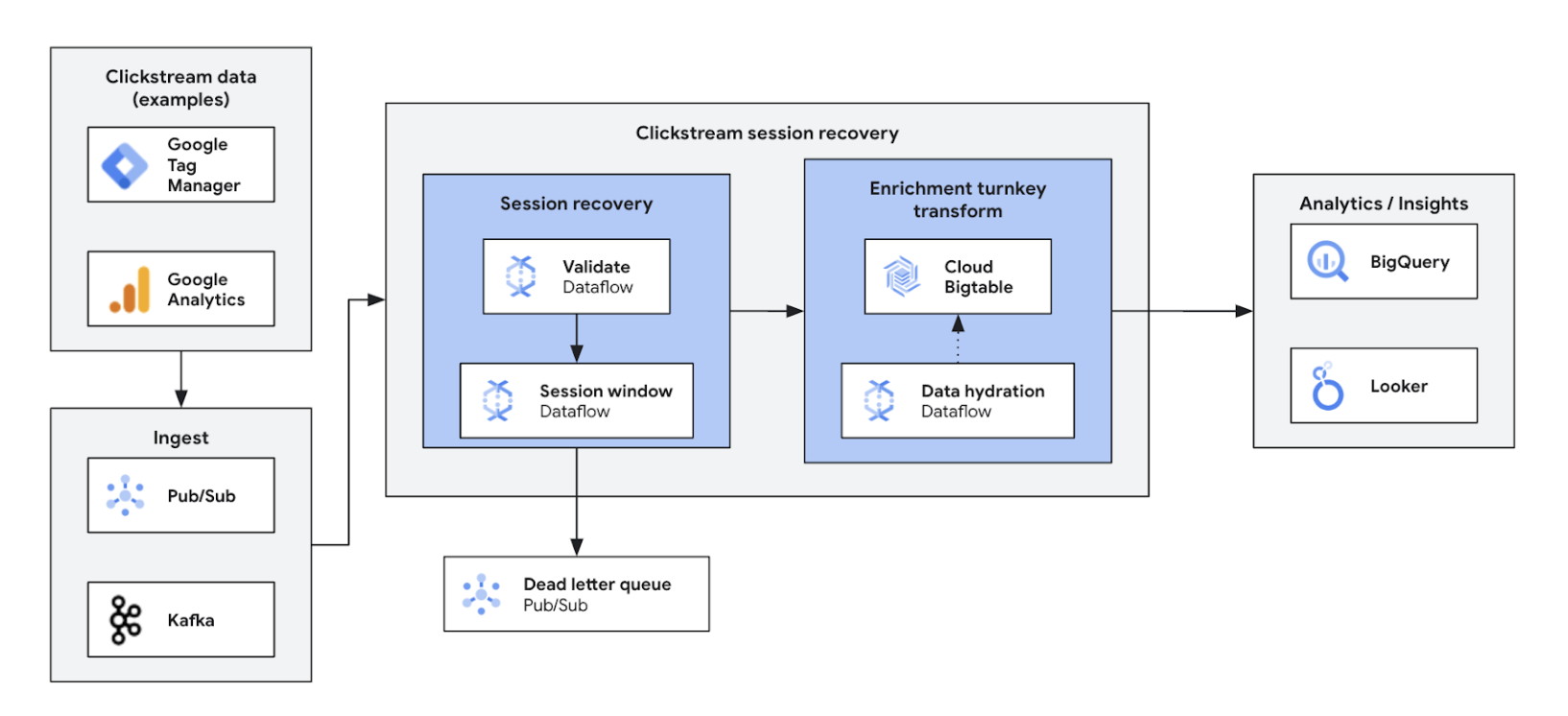
Clickstream-Analysen in Echtzeit ermöglichen es Unternehmen, Nutzerinteraktionen auf Websites und in Apps sofort zu analysieren. Personalisierung in Echtzeit, A/B-Tests und Trichteroptimierung, was zu mehr Interaktionen, einer schnelleren Produktentwicklung, einer geringeren Abwanderung und einem verbesserten Produktsupport führt. Letztendlich ermöglicht es eine hervorragende Nutzererfahrung und fördert das Unternehmenswachstum durch dynamische Preisgestaltung und personalisierte Empfehlungen.
Tutorials, Kurzanleitungen und Labs
Web- und App-Nutzung optimieren und personalisieren
Web- und App-Nutzung optimieren und personalisieren
Clickstream-Analysen in Echtzeit ermöglichen es Unternehmen, Nutzerinteraktionen auf Websites und in Apps sofort zu analysieren. Personalisierung in Echtzeit, A/B-Tests und Trichteroptimierung, was zu mehr Interaktionen, einer schnelleren Produktentwicklung, einer geringeren Abwanderung und einem verbesserten Produktsupport führt. Letztendlich ermöglicht es eine hervorragende Nutzererfahrung und fördert das Unternehmenswachstum durch dynamische Preisgestaltung und personalisierte Empfehlungen.
Log-Replikation und -Analyse in Echtzeit
Zentrale Logverwaltung und -analyse
Zentrale Logverwaltung und -analyse
Google Cloud-Logs können mit Dataflow für die Protokollverarbeitung und -analyse in nahezu Echtzeit auf Drittanbieterplattformen wie Splunk repliziert werden. Diese Lösung bietet zentrale Funktionen für die Protokollverwaltung, Compliance, Audits und Analyse, senkt die Kosten und verbessert die Leistung.
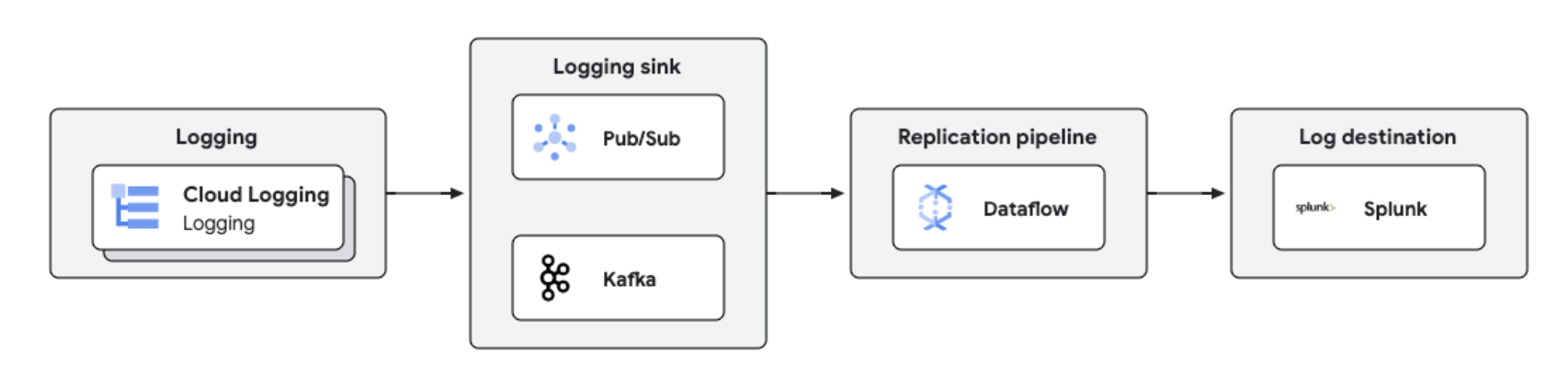
Tutorials, Kurzanleitungen und Labs
Zentrale Logverwaltung und -analyse
Zentrale Logverwaltung und -analyse
Google Cloud-Logs können mit Dataflow für die Protokollverarbeitung und -analyse in nahezu Echtzeit auf Drittanbieterplattformen wie Splunk repliziert werden. Diese Lösung bietet zentrale Funktionen für die Protokollverwaltung, Compliance, Audits und Analyse, senkt die Kosten und verbessert die Leistung.
Preise
| Funktionsweise von Dataflow-Preisen | Sehen Sie sich das Abrechnungs- und Ressourcenmodell für Dataflow an. | |
|---|---|---|
| Dienste und Nutzung | Beschreibung | Preise |
Dataflow-Rechenressourcen | Die Dataflow-Abrechnung für Rechenressourcen beinhaltet: | Weitere Informationen finden Sie in unserer detaillierten Preisübersicht. |
Weitere Dataflow-Ressourcen | Weitere Dataflow-Ressourcen, die für alle Jobs in Rechnung gestellt werden, umfassen nichtflüchtige Speicher, GPUs und Snapshots. | Weitere Informationen finden Sie in unserer detaillierten Preisübersicht. |
Dataflow-Rabatte für zugesicherte Nutzung (CUDs) | Dataflow-Rabatte für zugesicherte Nutzung bieten je nach Zusicherungszeitraum zwei Rabattstufen:
| Weitere Informationen zu Dataflow-Rabatten für zugesicherte Nutzung |
Weitere Informationen zu Dataflow-Preisen. Vollständige Preisinformationen
Funktionsweise von Dataflow-Preisen
Sehen Sie sich das Abrechnungs- und Ressourcenmodell für Dataflow an.
Dataflow-Rechenressourcen
Die Dataflow-Abrechnung für Rechenressourcen beinhaltet:
Weitere Informationen finden Sie in unserer detaillierten Preisübersicht.
Weitere Dataflow-Ressourcen
Weitere Dataflow-Ressourcen, die für alle Jobs in Rechnung gestellt werden, umfassen nichtflüchtige Speicher, GPUs und Snapshots.
Weitere Informationen finden Sie in unserer detaillierten Preisübersicht.
Dataflow-Rabatte für zugesicherte Nutzung (CUDs)
Dataflow-Rabatte für zugesicherte Nutzung bieten je nach Zusicherungszeitraum zwei Rabattstufen:
- Mit einem einjährigen Rabatt für zugesicherte Nutzung erhalten Sie 20 % Rabatt auf den On-Demand-Preis.
- Mit einem 3‐jährigen Rabatt für zugesicherte Nutzung erhalten Sie 40 % Rabatt auf den On-Demand-Preis
Weitere Informationen zu Dataflow-Rabatten für zugesicherte Nutzung
Weitere Informationen zu Dataflow-Preisen. Vollständige Preisinformationen
Anwendungsszenario
Warum sich führende Kunden für Dataflow entscheiden
Namitha Vijaya Kumar, Product Owner, Google Cloud SRE bei ANZ Bank
„Dataflow unterstützt sowohl unsere Batchverarbeitung als auch die Datenverarbeitung in Echtzeit und sorgt so dafür, dass die Aktualität der Daten im Data Lake des Unternehmens sichergestellt ist. Dies wiederum unterstützt die nachgelagerte Nutzung von Daten für Analysen/Entscheidungen und die Zustellung von Echtzeitbenachrichtigungen für unsere Einzelhandelskunden.“
Weitere Informationen
Vorteile von Dataflow
Streaming ML leicht gemacht
Sofort einsatzbereite Funktionen für das Streaming in KI/ML: RunInference für Inferenz, MLTransform für die Vorverarbeitung des Modelltrainings, optimierte Feature Store-Suchen und dynamische GPU-Unterstützung sorgen für weniger Aufwand, ohne dass Gelder für begrenzte GPU-Ressourcen verschwendet werden.
Optimales Preis-Leistungs-Verhältnis mit robusten Tools
Dataflow bietet kostengünstiges Streaming mit automatischer Optimierung für maximale Leistung und Ressourcennutzung. Es lässt sich mühelos skalieren und kann jede Arbeitslast bewältigen. Außerdem bietet es eine KI-gestützte Selbstreparatur. Robuste Tools unterstützen Abläufe und Informationen.
Offen, übertragbar und erweiterbar
Dataflow wurde für Open-Source-Apache Beam mit einheitlicher Batch- und Streaming-Unterstützung entwickelt. Dadurch können Ihre Arbeitslasten zwischen Clouds, lokalen Systemen und Edge-Geräten übergeben werden.
Partner und Integration




Dataflow-Partner
Google Cloud-Partner haben Lösungen für Dataflow entwickelt, mit denen Sie schnell und einfach leistungsstarke Datenverarbeitungsaufgaben jeder Größenordnung ausführen können. Sehen Sie sich alle Partner an und starten Sie noch heute Ihren Weg zum Streaming.


















