このチュートリアルでは、Cloud Storage からデータを読み取り、データ品質検査を実行して、Cloud Storage に書き込む再利用可能なパイプラインを構築する方法を説明します。
再利用可能なパイプラインには正規のパイプライン構造がありますが、各パイプライン ノードの構成は、HTTP サーバーによって提供される構成に基づいて変更できます。たとえば、静的パイプラインはデータを Cloud Storage から読み取り、変換を適用して、BigQuery 出力テーブルに書き込みます。パイプラインが読み取る Cloud Storage ファイルに基づいて変換と BigQuery 出力テーブルを変更する場合は、再利用可能なパイプラインを作成します。
目標
- Cloud Storage Argument Setter プラグインを使用して、パイプラインが実行ごとに異なる入力を読み取ることができるようにします。
- Cloud Storage Argument Setter プラグインを使用して、パイプラインが実行ごとに異なる品質検査を実行できるようにします。
- 実行ごとの出力データを Cloud Storage に書き込みます。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
- Cloud Data Fusion
- Cloud Storage
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, BigQuery, and Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Cloud Data Fusion インスタンスを作成します。
Google Cloud コンソールで、[インスタンス] ページを開きます。
インスタンスの [操作] 列で、[インスタンスの表示] リンクをクリックします。Cloud Data Fusion のウェブ インターフェースが新しいブラウザタブで開きます。
Cloud Data Fusion ウェブ インターフェースに移動する
Cloud Data Fusion を使用する際は、 Google Cloud コンソールと個別の Cloud Data Fusion ウェブ インターフェースの両方を使用します。 Google Cloud コンソールでは、 Google Cloud コンソール プロジェクトを作成し、Cloud Data Fusion インスタンスを作成および削除できます。Cloud Data Fusion ウェブ インターフェースでは、[Pipeline Studio] や [Wrangler] などのさまざまなページで Cloud Data Fusion の機能を使用できます。
Cloud Storage 引数セッター プラグインをデプロイする
Cloud Data Fusion ウェブ インターフェースで、[Studio] ページに移動します。
[アクション] メニューで [GCS 引数設定ツール] をクリックします。
Cloud Storage からの読み取り
- Cloud Data Fusion ウェブ インターフェースで、[Studio] ページに移動します。
- arrow_drop_down [Source] をクリックし、[Cloud Storage] を選択します。Cloud Storage ソースのノードがパイプラインに表示されます。
[Cloud Storage] ノードで、[プロパティ] をクリックします。
[Reference name] フィールドに名前を入力します。
[Path] フィールドに「
${input.path}」と入力します。このマクロは、異なるパイプラインの実行で使用する Cloud Storage 入力パスを制御します。右側の [Output Schema] パネルで、オフセット フィールド行のゴミ箱アイコンをクリックして、出力スキーマの [offset] フィールドを削除します。
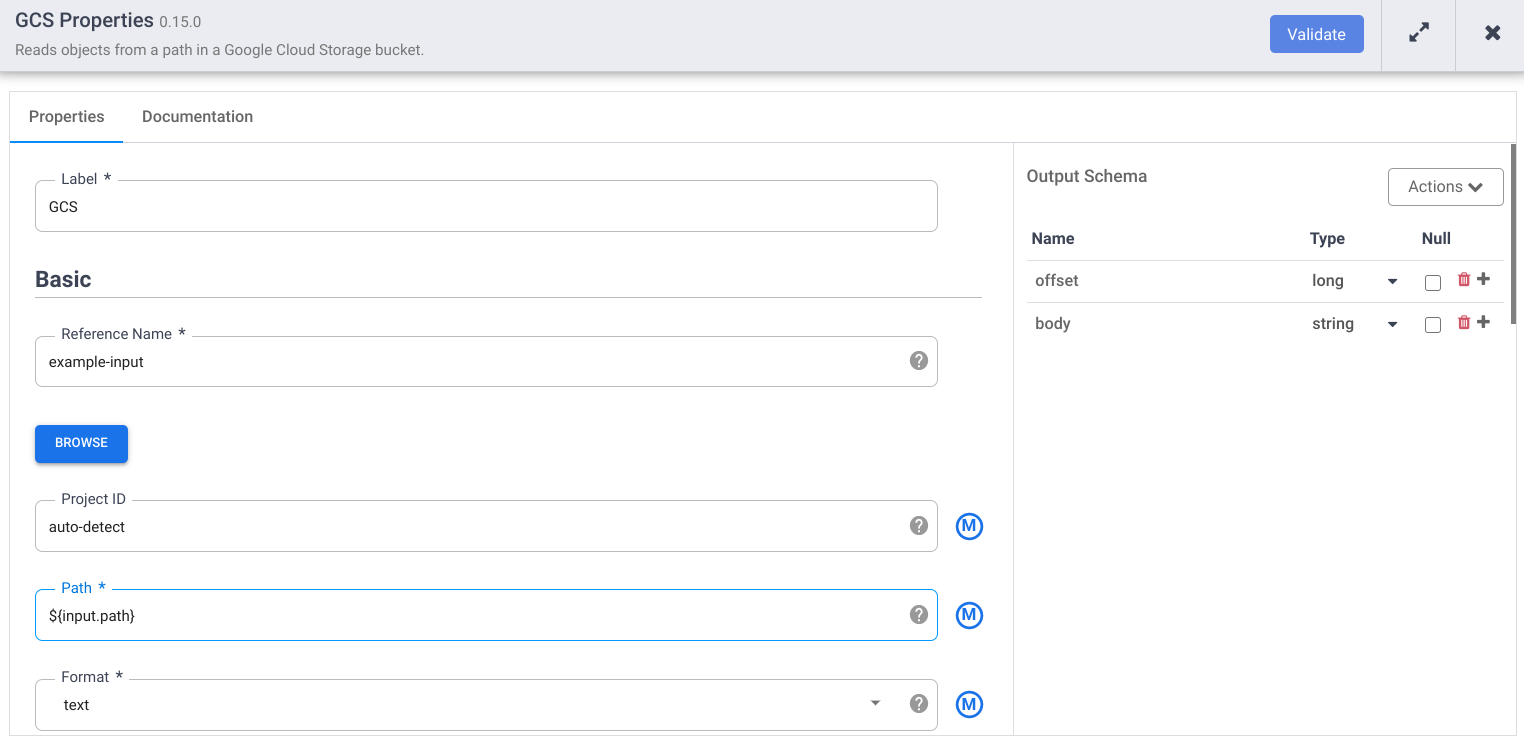
[Validate] をクリックして、エラーに対処します。
[] をクリックして、[Properties] ダイアログを終了します。
データを変換する
- Cloud Data Fusion ウェブ インターフェースで、[Studio] ページのデータ パイプラインに移動します。
- [Transform] プルダウン メニュー arrow_drop_down で、[Wrangler] を選択します。
- Pipeline Studio キャンバスで、Cloud Storage ノードから Wrangler ノードに矢印をドラッグします。

- パイプラインの Wrangler ノードに移動し、[プロパティ] をクリックします。
- [Input field name] に「
body」と入力します。 - [Recipe] フィールドに「
${directives}」と入力します。このマクロは、異なるパイプラインの実行で使用する変換ロジックを制御します。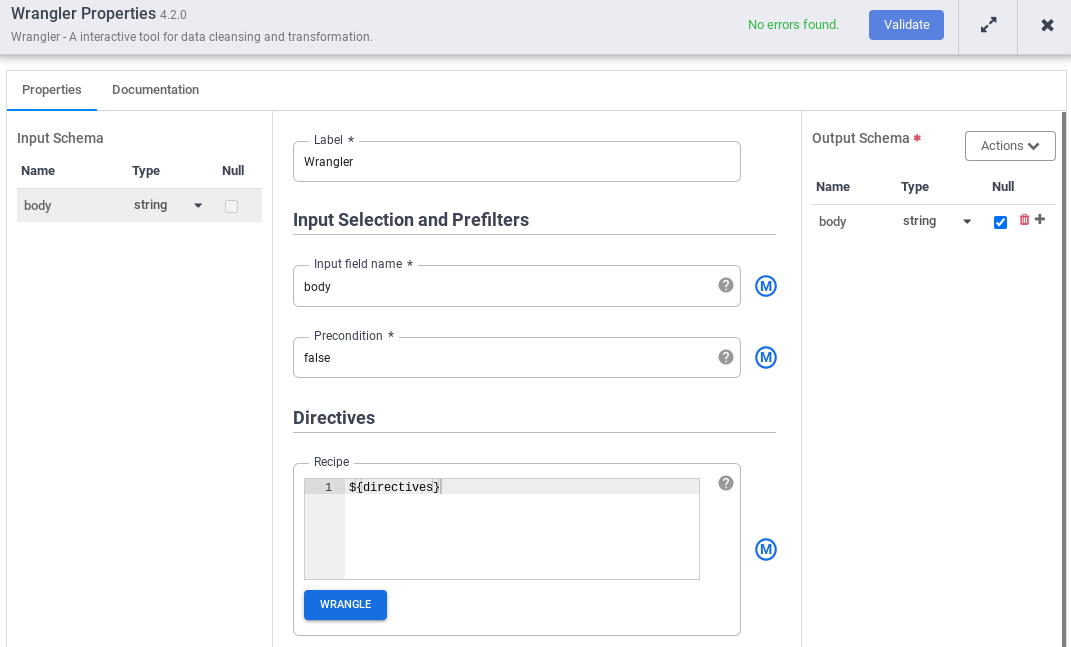
- [Validate] をクリックして、エラーに対処します。
- [] をクリックして、[Properties] ダイアログを終了します。
Cloud Storage への書き込み
- Cloud Data Fusion ウェブ インターフェースで、[Studio] ページのデータ パイプラインに移動します。
- [Sink] プルダウン メニュー arrow_drop_down で、[Cloud Storage] を選択します。
- Pipeline Studio キャンバスで、Wrangler ノードから先ほど追加した Cloud Storage ノードに矢印をドラッグします。

- パイプラインの Cloud Storage シンクノードに移動し、[Properties] をクリックします。
- [Reference name] フィールドに名前を入力します。
- [Path] フィールドに、パイプラインが出力ファイルを書き込むことができる、プロジェクトの Cloud Storage バケットのパスを入力します。Cloud Storage バケットがない場合は、1 つ作成します。

- [Validate] をクリックして、エラーに対処します。
- [] をクリックして、[Properties] ダイアログを終了します。
マクロ引数を設定する
- Cloud Data Fusion ウェブ インターフェースで、[Studio] ページのデータ パイプラインに移動します。
- arrow_drop_down [条件とアクション] プルダウン メニューで、[GCS 引数セッター] をクリックします。
- Pipeline Studio キャンバスで、Cloud Storage Argument Setter ノードから Cloud Storage ソースノードに矢印をドラッグします。
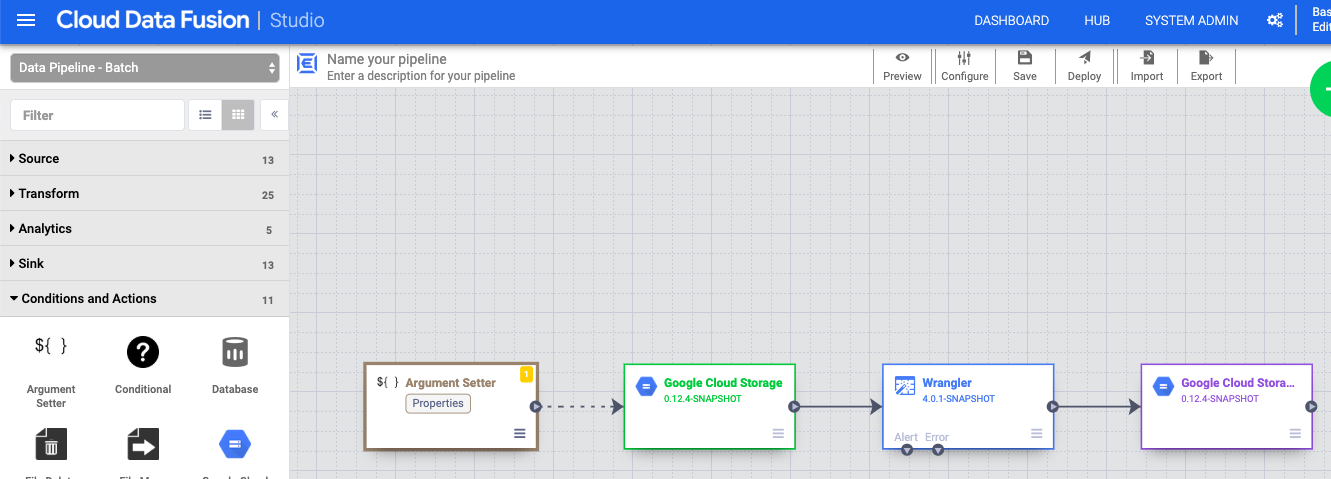
- パイプラインの Cloud Storage Argument Setter ノードに移動し、[プロパティ] をクリックします。
[URL] フィールドに、次のように入力します。
gs://reusable-pipeline-tutorial/args.jsonこの URL は、Cloud Storage 内の一般公開オブジェクトを示しており、次のコンテンツを含みます。
{ "arguments" : [ { "name": "input.path", "value": "gs://reusable-pipeline-tutorial/user-emails.txt" }, { "name": "directives", "value": "send-to-error !dq:isEmail(body)" } ] }2 つある引数のうち最初の引数は
input.pathの値です。パスgs://reusable-pipeline-tutorial/user-emails.txtは、Cloud Storage の一般公開オブジェクトで、これには次のテストデータが含まれています。alice@example.com bob@example.com craig@invalid@example.com2 番目の引数は
directivesの値です。値send-to-error !dq:isEmail(body)は、有効なメールアドレスではない行を除外するように Wrangler を設定します。たとえば、craig@invalid@example.comは除外されます。[検証] をクリックして、エラーがないことを確認します。
[] をクリックして、[Properties] ダイアログを終了します。
パイプラインをデプロイして実行する
[Pipeline Studio] ページの上部バーから [Name your pipeline] をクリックします。 パイプラインに名前を付け、[保存] をクリックします。
[デプロイ] をクリックします。
ランタイム引数マクロ(ランタイム)を表示する
input.pathおよびdirectives引数を開くには、arrow_drop_downの横にあるプルダウン実行をクリックします。値フィールドを空白のままにすると、パイプライン内の Cloud Storage Argument Sette ノードがランタイム中にこれらの引数の値を設定することを Cloud Data Fusion に通知します。

[実行] をクリックします。
クリーンアップ
このチュートリアルで使用したリソースについて、Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
チュートリアルが終了したら、Google Cloud で作成したリソースをクリーンアップして、割り当てを使い果たしたり、今後料金が発生しないようにします。次のセクションで、このようなリソースを削除または無効にする方法を説明します。
Cloud Data Fusion インスタンスを削除する
Cloud Data Fusion インスタンスを削除する手順に従います。
プロジェクトを削除する
課金されないようにする最も簡単な方法は、チュートリアル用に作成したプロジェクトを削除することです。
プロジェクトを削除するには:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.