Auf dieser Seite wird beschrieben, wie Sie mit der Quelle Multi Table mehrere Tabellen aus einer Microsoft SQL Server-Datenbank auslesen können. Verwenden Sie die Quelle für mehrere Tabellen, wenn Ihre Pipeline aus mehreren Tabellen lesen soll. Informationen zum Lesen der Pipeline aus einer einzelnen Tabelle finden Sie unter Aus einer SQL Server-Tabelle lesen.
Die Quelle „Multi-Table“ gibt Daten mit mehreren Schemas aus und enthält ein Tabellennamenfeld, das die Tabelle angibt, aus der die Daten stammen. Verwenden Sie bei Verwendung der Quelle „Multi-Table“ eine der Multi-Table-Senken, BigQuery Multi Table oder GCS Multi File.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Cloud Data Fusion, Cloud Storage, BigQuery, and Dataproc APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. - Erstellen Sie eine Cloud Data Fusion-Instanz.
- Prüfen Sie, ob Ihre SQL Server-Datenbank Verbindungen von Cloud Data Fusion akzeptieren kann. Daher empfehlen wir Ihnen, eine private Cloud Data Fusion-Instanz zu erstellen.
Rufen Sie in der Google Cloud Console die Seite „Cloud Data Fusion“ auf.
Wenn Sie die Instanz in Cloud Data Fusion Studio öffnen möchten, klicken Sie auf Instanzen und dann auf Instanz anzeigen.
Cloud Data Fusion-Instanz ansehen
Bei Verwendung von Cloud Data Fusion verwenden Sie sowohl die Google Cloud Console als auch die separate Cloud Data Fusion-UI. In der Google Cloud -Konsole können Sie ein Google Cloud -Projekt erstellen sowie Cloud Data Fusion-Instanzen erstellen und löschen. In der Benutzeroberfläche von Cloud Data Fusion können Sie die verschiedenen Seiten wie Studio oder Wrangler nutzen, um Features von Cloud Data Fusion zu nutzen.
SQL Server-Passwort als sicheren Schlüssel speichern
Fügen Sie Ihr SQL Server-Passwort als sicheren Schlüssel hinzu, um Ihre Cloud Data Fusion-Instanz zu verschlüsseln. Später in diesem Leitfaden sorgen Sie dafür, dass Ihr Passwort mit Cloud KMS abgerufen wird.
Klicken Sie rechts oben auf einer beliebigen Seite von Cloud Data Fusion auf Systemadministrator.
Klicken Sie auf den Tab Configuration (Konfiguration).
Klicken Sie auf HTTP-Aufrufe ausführen.

Wählen Sie im Drop-down-Menü PUT aus.
Geben Sie im Feld Pfad
namespaces/NAMESPACE_ID/securekeys/PASSWORDein.Geben Sie im Feld Body den Wert
{"data":"SQL_SERVER_PASSWORD"}ein.Klicken Sie auf Senden.
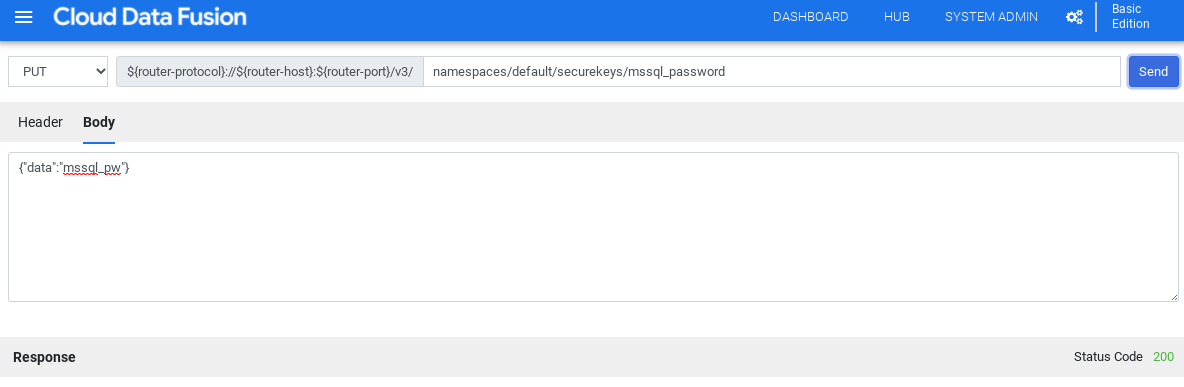
Achten Sie darauf, dass die Antwort, die Sie erhalten, der Statuscode 200 ist.
JDBC-Treiber für SQL Server abrufen
Hub verwenden
Klicken Sie in der Cloud Data Fusion-UI auf Hub.
Geben Sie in der Suchleiste
Microsoft SQL Server JDBC Driverein.Klicken Sie auf Microsoft SQL Server JDBC-Treiber.
Klicken Sie auf Herunterladen. Führen Sie die angezeigten Schritte aus.
Klicken Sie auf Bereitstellen. Laden Sie die JAR-Datei aus dem vorherigen Schritt hoch.
Klicken Sie auf Beenden.
In Studio
Rufen Sie Microsoft.com auf.
Wählen Sie einen Download aus und klicken Sie auf Herunterladen.
Klicken Sie in der Cloud Data Fusion-UI auf Menü und rufen Sie die Seite Studio auf.
Klicken Sie auf Hinzufügen.
Klicken Sie unter Treiber auf Hochladen.
Laden Sie die in Schritt 2 heruntergeladene JAR-Datei hoch.
Klicken Sie auf Weiter.
Konfigurieren Sie den Treiber. Geben Sie einen Namen ein.
Geben Sie im Feld Klassenname
com.microsoft.sqlserver.jdbc.SQLServerDriverein.Klicken Sie auf Beenden.
Multiple Table-Plug-ins bereitstellen
Klicken Sie in der Web-UI von Cloud Data Fusion auf Hub.
Geben Sie in der Suchleiste
Multiple table pluginsein.Klicken Sie auf Multiple Table-Plug-ins.
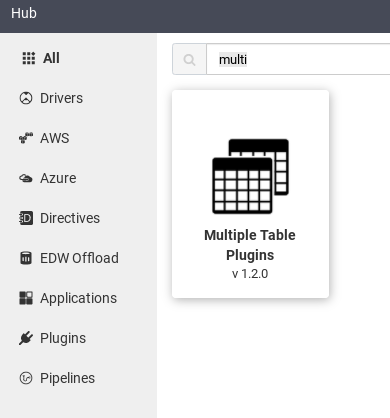
Klicken Sie auf Deploy.
Klicken Sie auf Beenden.
Klicken Sie auf Pipeline erstellen.
Mit SQL Server verbinden
Klicken Sie in der Cloud Data Fusion-UI auf Menü und rufen Sie die Seite Studio auf.
Maximieren Sie in Studio das Menü Quelle.
Klicken Sie auf Multiple Database Tables.
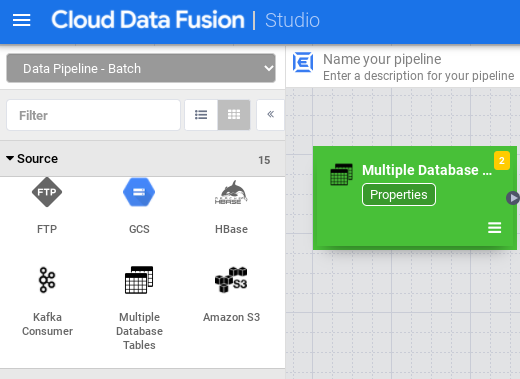
Bewegen Sie den Mauszeiger auf den Knoten Multiple Database Tables und klicken Sie auf Properties.
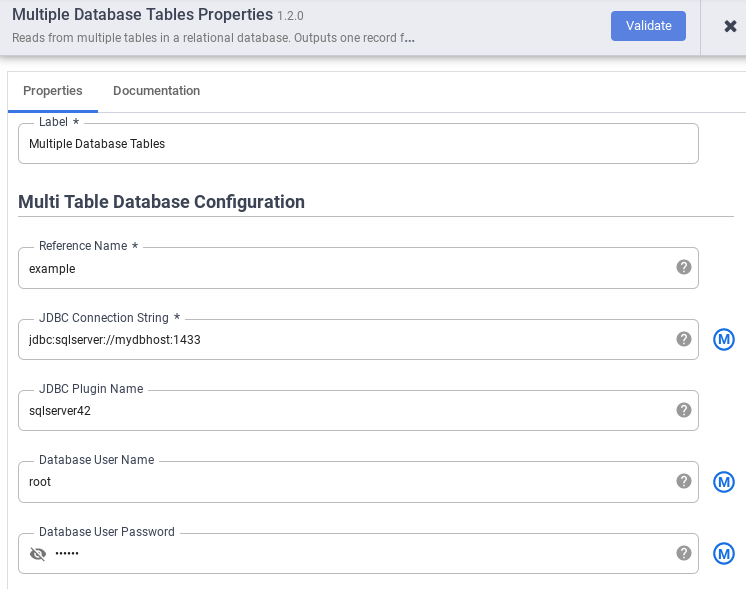
Geben Sie im Feld Referenzname einen Referenznamen an, der zur Identifizierung Ihrer SQL Server-Quelle verwendet wird.
Geben Sie im Feld JDBC Connection String den JDBC-Verbindungsstring ein. Beispiel:
jdbc:sqlserver://mydbhost:1433Weitere Informationen finden Sie unter Verbindungs-URL erstellen.Geben Sie den Name des JDBC-Plug-ins, den Datenbanknutzername und das Datenbanknutzerpasswort ein.
Klicke auf Validieren.
Klicken Sie auf Schließen.
Mit BigQuery oder Cloud Storage verbinden
Klicken Sie in der Cloud Data Fusion-UI auf Menü und rufen Sie die Seite Studio auf.
Maximieren Sie Sink.
Klicken Sie auf BigQuery Multi Table oder GCS Multi File.
Verbinden Sie den Knoten Multiple Database Tables (Mehrere Datenbanktabellen) mit BigQuery Multi Table (BigQuery-Multitabelle) oder GCS Multi File (GCS-Multidatei).
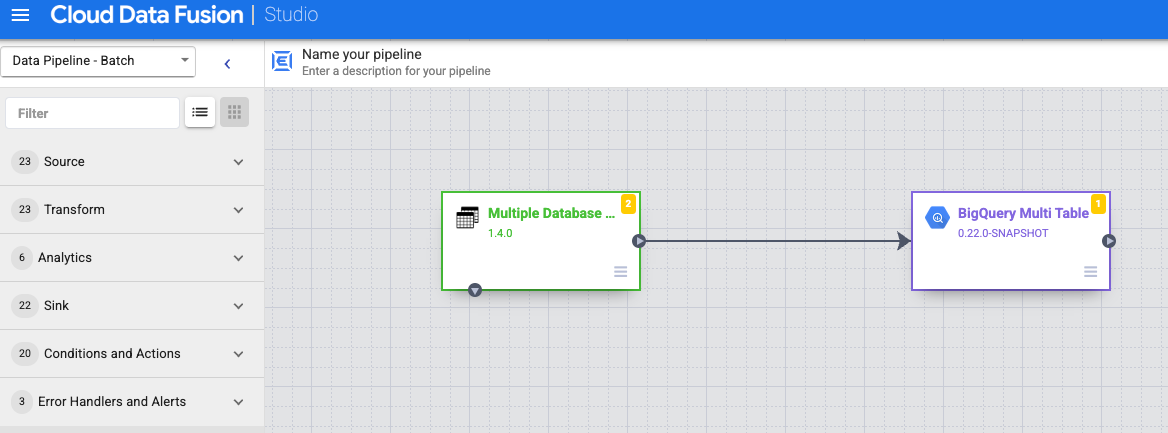
Halten Sie den Mauszeiger auf den Knoten BigQuery Multi Table oder GCS Multi File, klicken Sie auf Properties und konfigurieren Sie die Senke.
Weitere Informationen finden Sie unter Google BigQuery Multi Table Sink und Google Cloud Storage Multi File Sink.
Klicke auf Validieren.
Klicken Sie auf Schließen.
Vorschau der Pipeline ausführen
Klicken Sie in der Cloud Data Fusion-UI auf Menü und rufen Sie die Seite Studio auf.
Klicken Sie auf Vorschau.
Klicken Sie auf Ausführen. Warten Sie, bis die Vorschau erfolgreich abgeschlossen ist.
Stellen Sie die Pipeline bereit.
Klicken Sie in der Cloud Data Fusion-UI auf Menü und rufen Sie die Seite Studio auf.
Klicken Sie auf Bereitstellen.
Pipeline ausführen
Klicken Sie in der Cloud Data Fusion-UI auf Menü.
Klicken Sie auf Liste.
Klicken Sie auf die Pipeline.
Klicken Sie auf der Seite mit den Pipelinedetails auf Ausführen.
Nächste Schritte
- Weitere Informationen zu Cloud Data Fusion
- Folgen Sie einer der Anleitungen.