本页介绍了如何在 Cloud Data Fusion 中将转换执行到 BigQuery(而不是 Spark)。
如需了解详情,请参阅将转换推送到 BigQuery。
准备工作
转换推送在 6.5.0 及更高版本中可用。如果您的流水线在较早的环境中运行,则可以将实例升级到最新版本。
在流水线上启用转换推送功能
控制台
如需在已部署的流水线上启用转换推送功能,请执行以下操作:
前往您的实例:
在 Google Cloud 控制台中,前往 Cloud Data Fusion 页面。
如需在 Cloud Data Fusion Studio 中打开实例,请点击实例,然后点击查看实例。
依次点击 菜单 > 列表。
系统会打开“已部署的流水线”标签页。
点击所需的已部署流水线,以在 Pipeline Studio 中将其打开。
依次点击配置 > 转换推送。
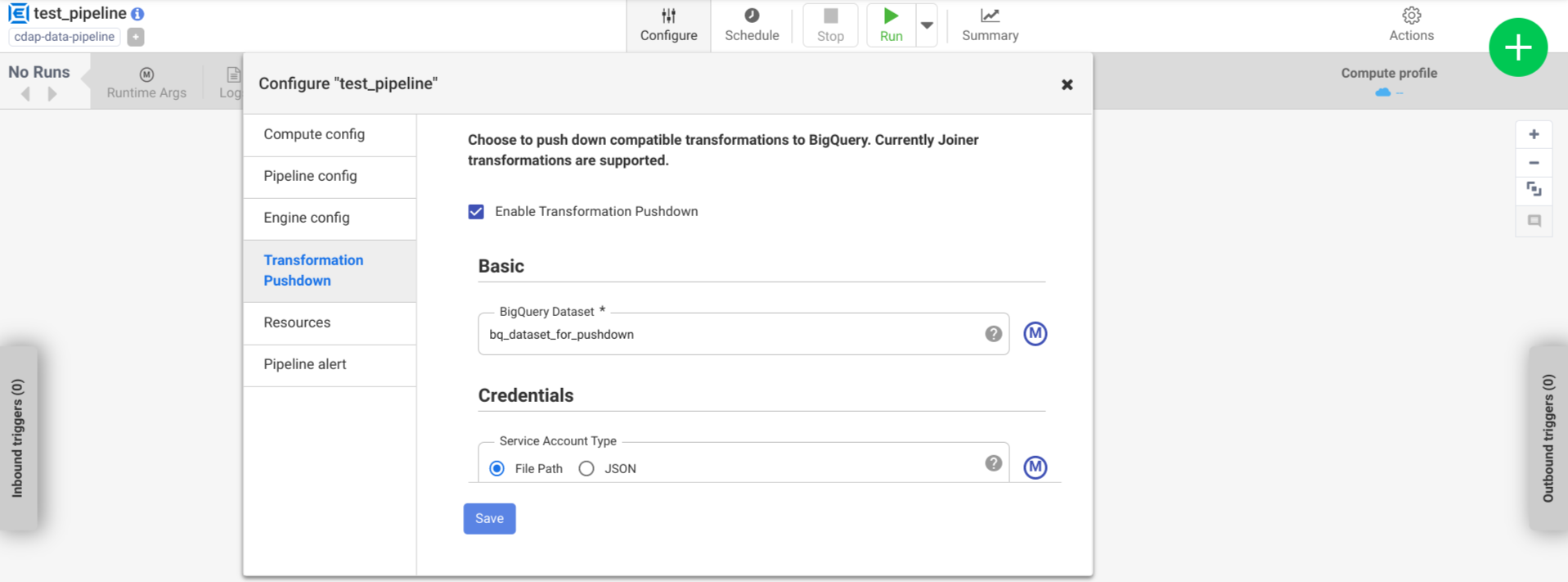
点击启用转换推送功能。
在 Dataset(数据集)字段中,输入 BigQuery 数据集名称。
可选:如需使用宏,请点击 M。如需了解详情,请参阅数据集。
可选:根据需要配置选项。
点击保存。
可选配置
.| 属性 | 支持宏 | 支持的 Cloud Data Fusion 版本 | 说明 |
|---|---|---|---|
| 使用连接 | 否 | 6.7.0 及更高版本 | 是否使用现有连接。 |
| 连接 | 是 | 6.7.0 及更高版本 | 连接的名称。此连接会提供项目和服务账号信息。 可选:使用宏函数 ${conn(connection_name)}。 |
| 数据集项目 ID | 是 | 6.5.0 | 如果数据集位于与运行 BigQuery 作业的项目不同的项目中,请输入数据集的项目 ID。如果未指定任何值,则默认使用运行作业的项目 ID。 |
| 项目 ID | 是 | 6.5.0 | Google Cloud 项目 ID。 |
| 服务账号类型 | 是 | 6.5.0 | 从下列选项中选择一项:
|
| 服务账号文件路径 | 是 | 6.5.0 | 用于授权的服务账号密钥在本地文件系统中的路径。在 Dataproc 集群上运行时,该参数会设置为 auto-detect。在其他集群上运行时,该文件必须存在于集群中的每个节点上。默认值为 auto-detect。 |
| 服务账号 JSON | 是 | 6.5.0 | 服务账号 JSON 文件的内容。 |
| 临时存储分区名称 | 是 | 6.5.0 | 用于存储临时数据的 Cloud Storage 存储分区。 如果该配置文件不存在,则系统会自动创建,但不会自动删除。Cloud Storage 数据加载到 BigQuery 后将被删除。如果未提供此值,系统会创建唯一存储分区,然后在流水线运行完成后将其删除。该服务账号必须有权在配置的项目中创建存储分区。 |
| 位置 | 是 | 6.5.0 | BigQuery 数据集的创建位置。
如果数据集或临时存储分区已存在,则系统会忽略此值。默认值为 US 多区域。 |
| 加密密钥名称 | 是 | 6.5.1/0.18.1 | 客户管理的加密密钥 (CMEK),用于加密写入由插件创建的任何存储分区、数据集或表的数据。如果存储分区、数据集或表已存在,系统会忽略此值。 |
| 在完成后保留 BigQuery 表 | 是 | 6.5.0 | 是否保留流水线运行期间创建的所有 BigQuery 临时表,以用于调试和验证。默认值为 No。 |
| 临时表 TTL(以小时为单位) | 是 | 6.5.0 | 为 BigQuery 临时表设置表 TTL(以小时为单位)。在流水线取消且清理过程中断时(例如,在执行集群突然关闭时),可将其用作故障安全机制。将此值设置为 0 会停用表 TTL。默认值为 72(3 天)。 |
| 作业优先级 | 是 | 6.5.0 | 用于执行 BigQuery 作业的优先级。从下列选项中选择一项:
|
| 强制推送的阶段 | 是 | 6.7.0 | 始终在 BigQuery 中执行的支持的阶段。 每个阶段名称都必须单独列为一行。 |
| 要跳过推送的阶段 | 是 | 6.7.0 | 永远不会在 BigQuery 中执行的支持的阶段。每个阶段名称都必须单独列为一行。 |
| 使用 BigQuery Storage Read API | 是 | 6.7.0 | 在流水线执行期间从 BigQuery 中提取记录时,是否使用 BigQuery Storage Read API。此选项可以提高转换下推的性能,但会产生额外费用。这需要在执行环境中安装 Scala 2.12。 |
在日志中监控性能变化
流水线运行时日志包含显示 BigQuery 中运行的 SQL 查询的消息。您可以监控流水线中的哪些阶段会被推送到 BigQuery。
以下示例显示了流水线执行开始时的日志条目。这些日志表明流水线中的 JOIN 操作已推送到 BigQuery 以执行:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
以下示例展示了将为推送执行中涉及的每个数据集分配的表名称:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
随着执行操作的持续,日志会显示推送阶段的完成情况,并最终执行 JOIN 操作。例如:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
所有阶段完成后,系统会显示一条消息,指示 Pull 操作已完成。这表示 BigQuery 导出过程已触发,并且在此导出作业开始后,记录将开始读取到流水线中。例如:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
如果流水线执行遇到错误,日志中会说明这些错误。
如需详细了解 BigQuery JOIN 操作的执行情况(例如资源利用率、执行时间和错误原因),您可以使用作业日志中显示的作业 ID 查看 BigQuery 作业数据。
查看流水线指标
如需详细了解 Cloud Data Fusion 为在 BigQuery 中执行的流水线部分提供的指标,请参阅 BigQuery 推送式流水线指标。
后续步骤
- 详细了解 Cloud Data Fusion 中的转换推送功能。